Dataflow Supports Spark JDBC Pushdown
Overview
ETL operators in a Dataflow Node typically run on Spark compute. When the input node is Database Input and Spark JDBC Pushdown is enabled, part of the ETL logic is automatically pushed down to the database for execution.
Procedure
In the dataflow editor, enable Spark JDBC Pushdown. Logic in operators such as calculation nodes, Filter Data Rows, Select Columns, and Group Aggregate is then pushed down to the database. Compared with the previous approach of retrieving large amounts of data through the database input SQL query, the amount of data fetched can be reduced significantly because filtering and aggregation are performed in the database first.
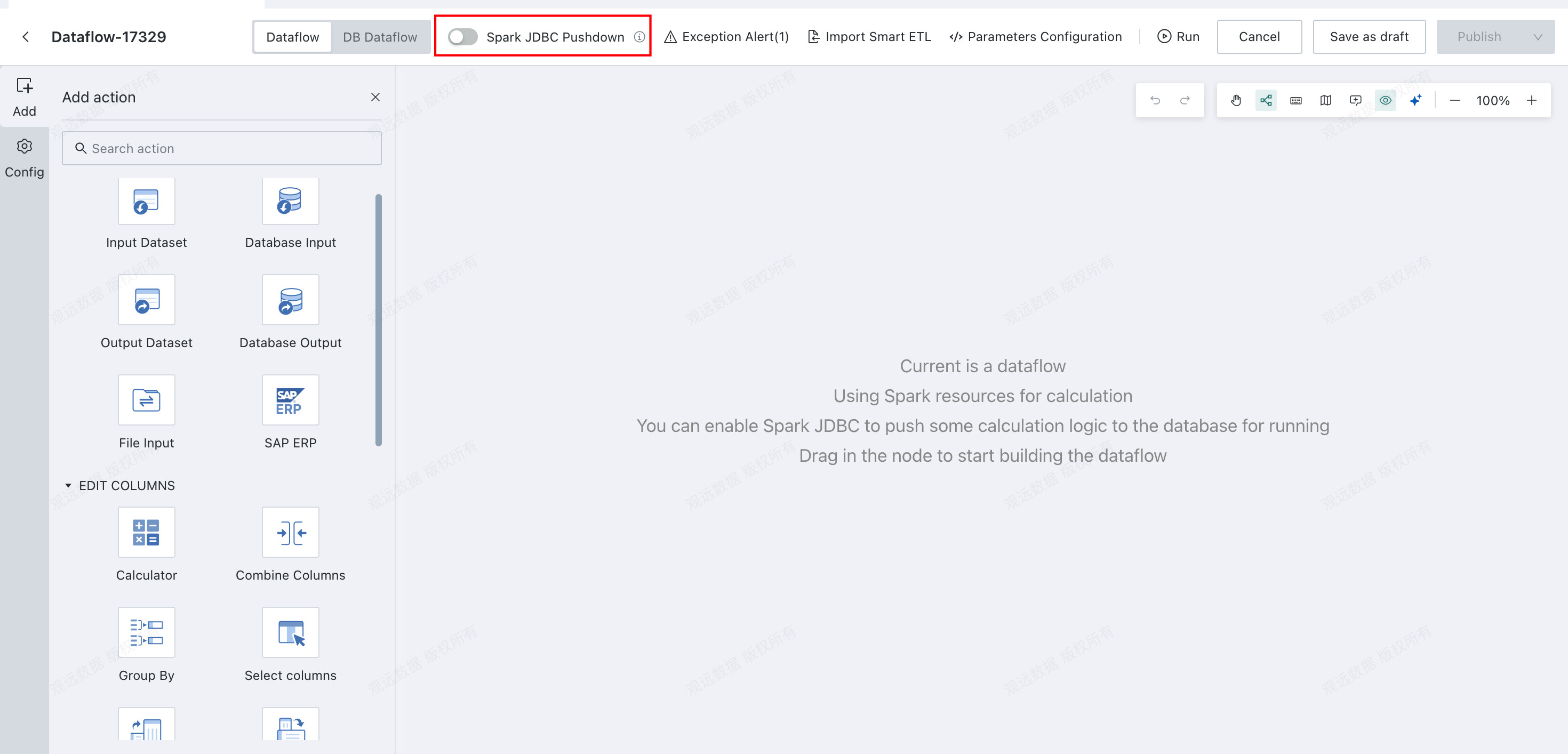
Notes
Spark JDBC Pushdown currently supports only databases driven by PostgreSQL.