Dataset Node
Overview
On the Offline Dev task editing page, you can drag the Dataset node from the left panel onto the canvas and configure it.
This section describes the configuration options of the Dataset Node.
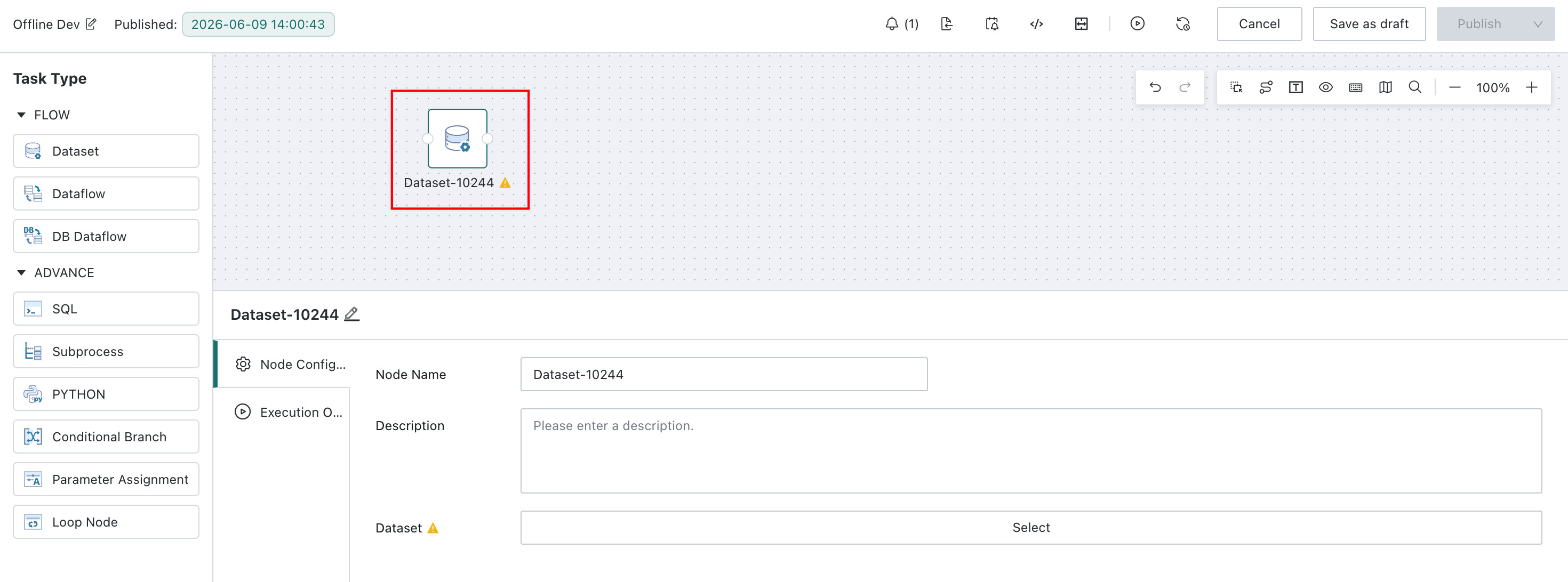
- Dataset: Select a dataset from the dataset list.
- After a dataset is selected, you can view or replace the dataset used by the node.
-
View dataset: Click the dataset name to go to the dataset overview page.
-
Replace dataset: Click
Replaceto the right ofDatasetto assign another dataset as the scheduled object of the workflow.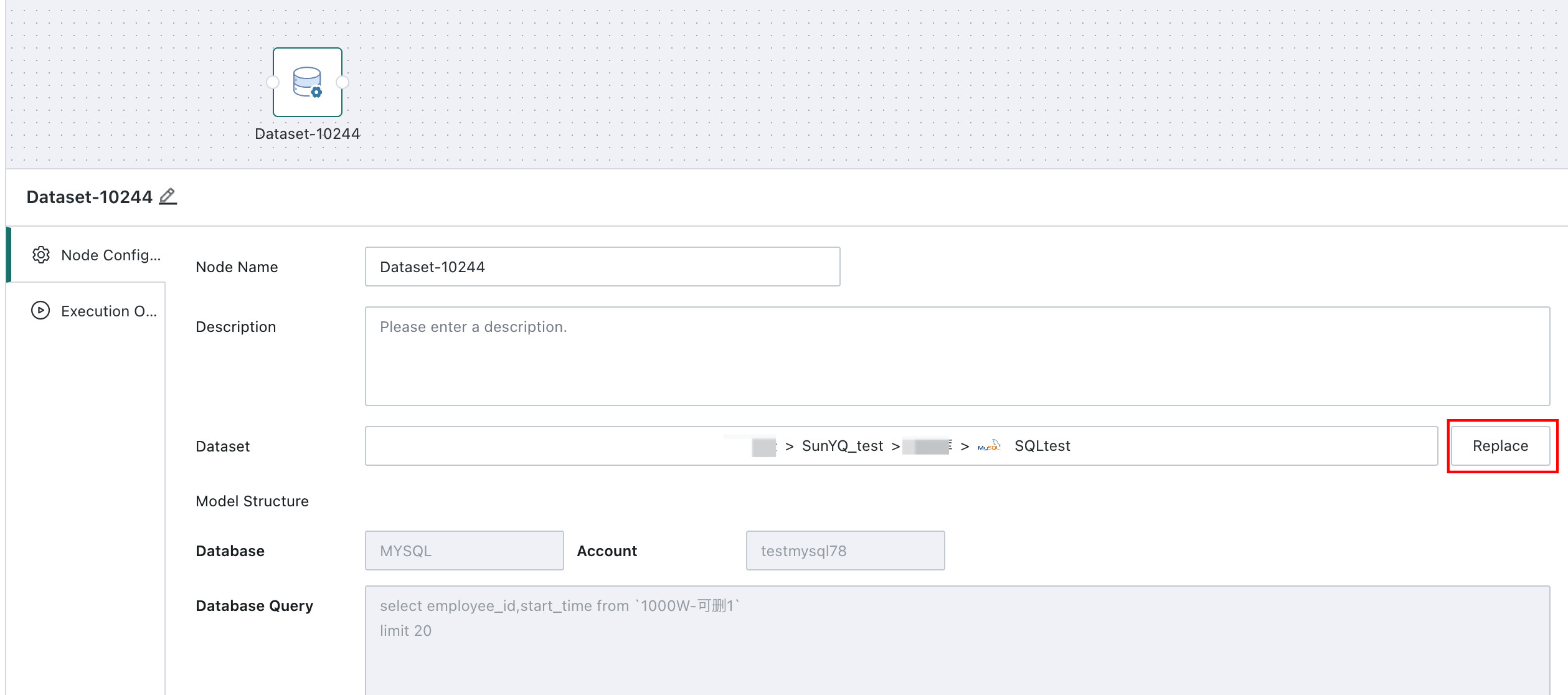
-
Notes
-
The workflow owner must have owner permission on the target dataset, and the target dataset must not be referenced by another workflow before it can be selected or replaced.
-
After the
Dataset Nodeis configured, you can arrange its execution order by connecting nodes. Success, failure, and sequential scheduling are all supported. -
When the workflow runs, if the prerequisite conditions of the
Datasetnode are met, or if no prerequisites exist, the node runs and triggers an update for the referenced dataset. The update logic is the same as URL-triggered updates.- If incremental update is enabled, the system performs pre-cleanup and appends data according to the pre-cleanup rules and incremental update SQL.
- If incremental update is not enabled, the system performs a full update according to the model structure SQL.
-
After a dataset is referenced and the workflow is saved, the dataset’s original update strategy becomes invalid automatically and changes to
Follow Workflow Update.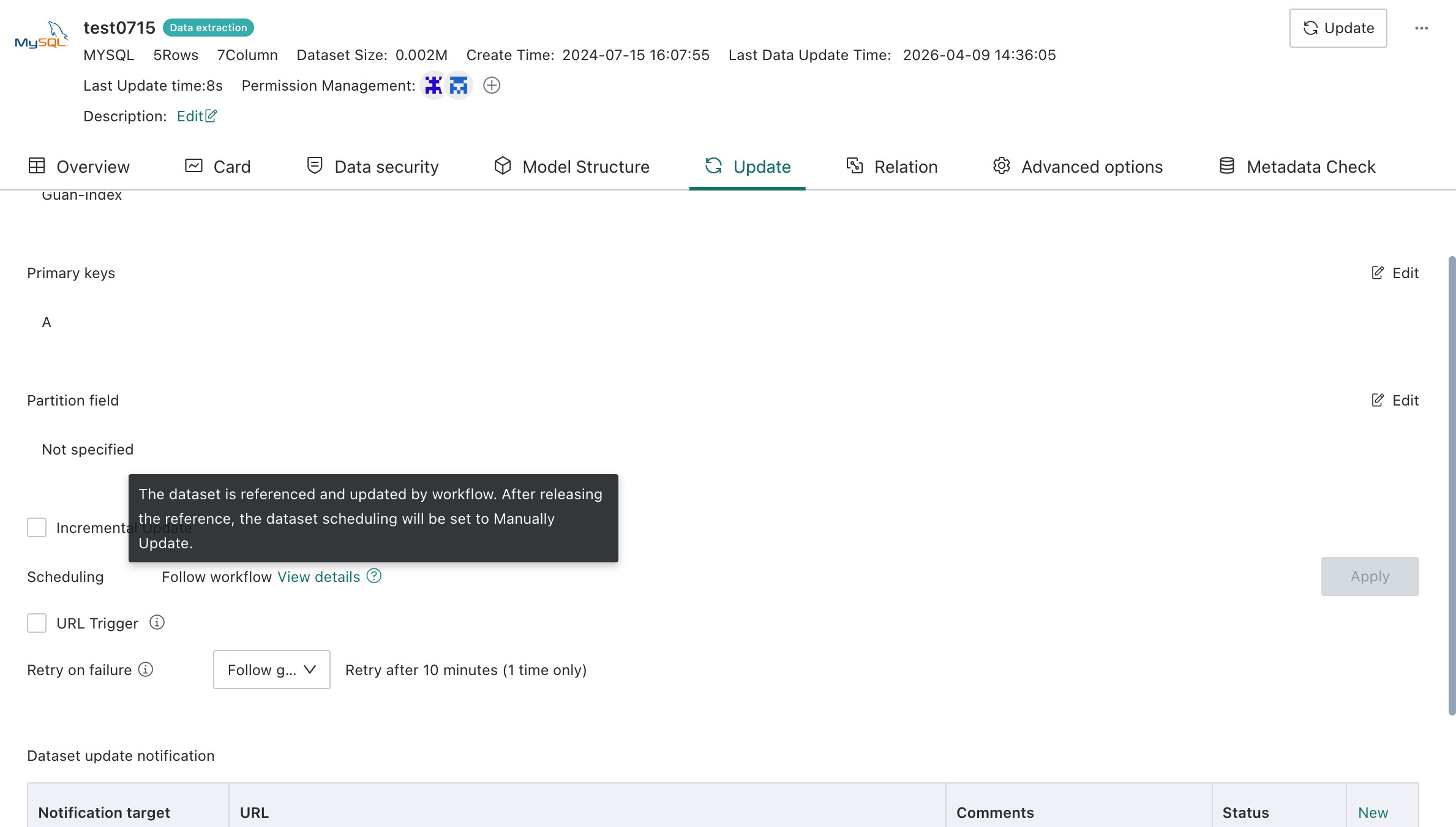
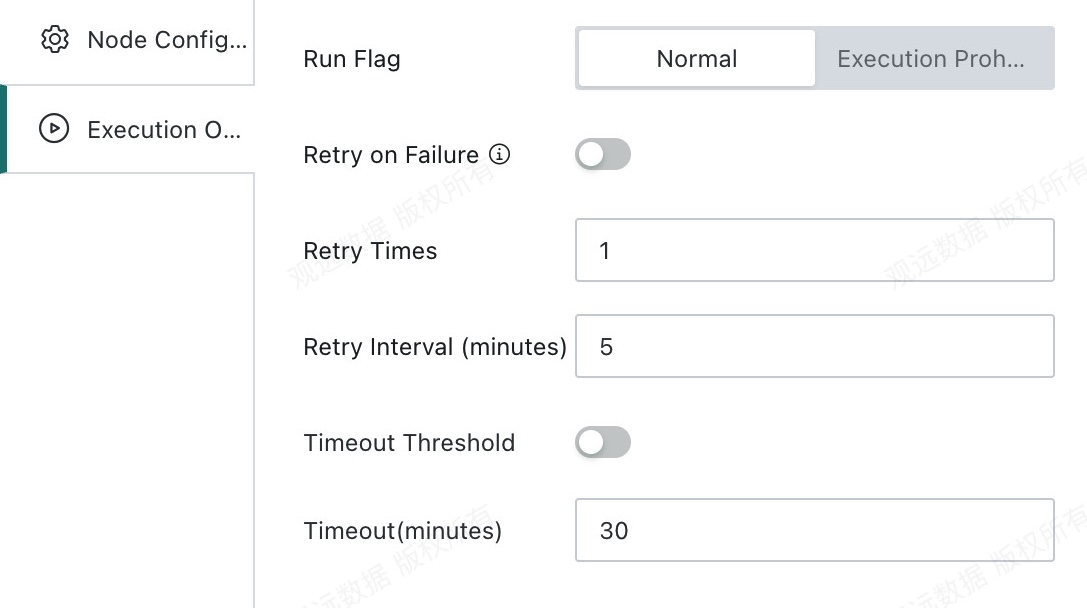
Runtime Options
- Run status
Do Not Execute: When the workflow reaches this node, execution is skipped directly. This is commonly used for temporary data troubleshooting and partial task execution control.Normal: The node runs according to the existing scheduling strategy. This is the default run status.
- Retry on failure
- Retry count: The number of automatic retries after node failure. The default is
1. - Retry interval: The interval before each retry is triggered. The default is
5minutes.
- Retry count: The number of automatic retries after node failure. The default is
- Timeout limit
- Timeout duration: The timeout limit for a single node. The node fails automatically if the limit is exceeded.