数据流支持Spark JDBC下推
概述
数据流 ETL 算子运行时一般使用 Spark 算力,当输入节点为数据库输入并开启 Spark JDBC 下推后,ETL 部分运算逻辑自动下推到数据库运行。
操作步骤
进入数据流,开启 Spark JDBC 下推,计算节点、筛选数据、选择列、分组聚合等算子逻辑会下推至数据库,以往根据数据库输入 SQL 查询获取的数据量会大量减少,因为筛选数据、分组聚合等逻辑下推到数据库,获取的是过滤或者聚合后的数据。
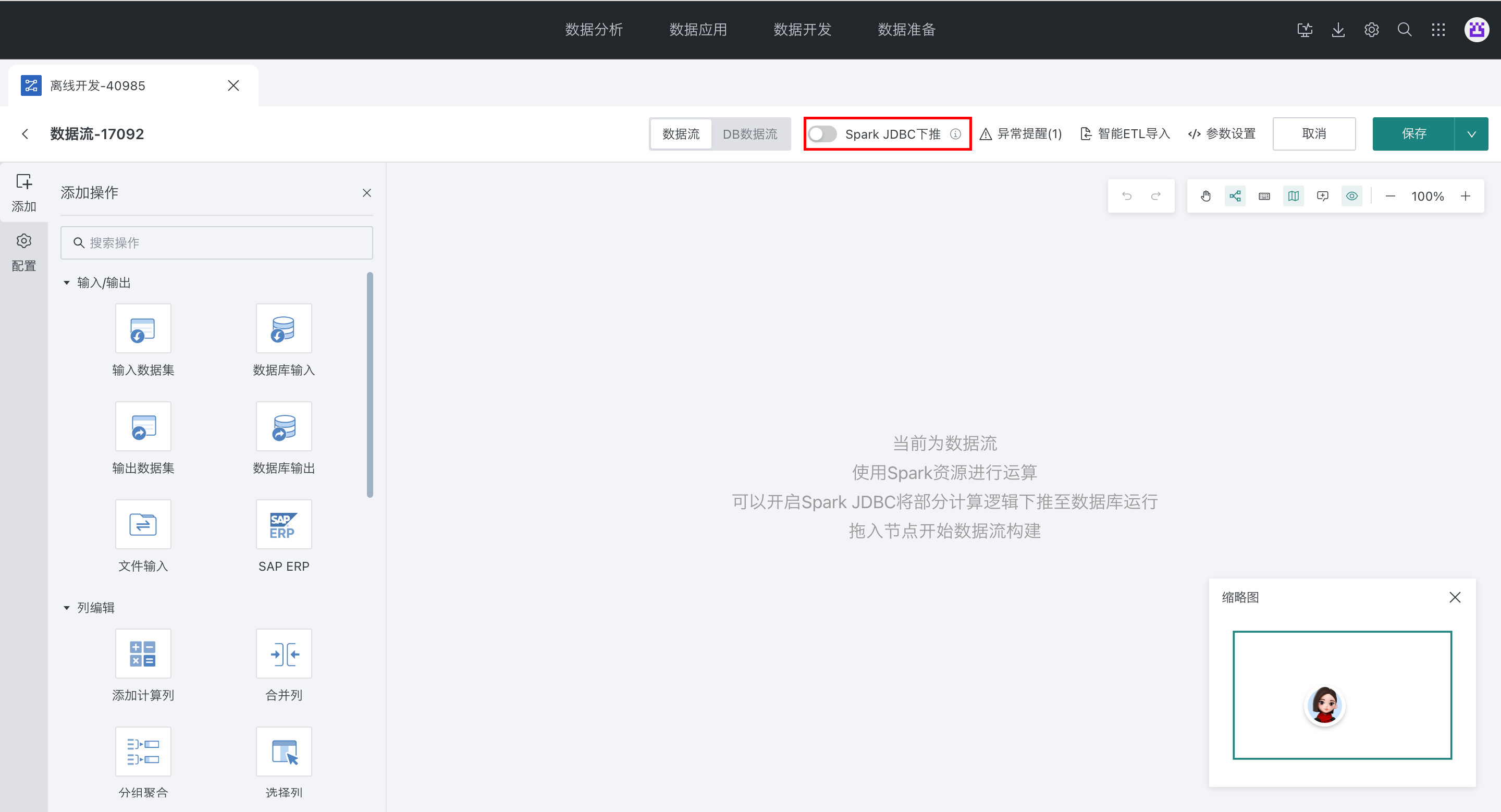
注意事项
Spark JDBC 下推目前仅支持 PostgreSQL 驱动的数据库。