2021年10月重要功能更新
以下功能在2.1.0及之后的版本中均可使用
工作流/数据流定义支持非法态保存
针对工作流/数据流的保存条件放宽:如果存在未配置完成/异常状态的节点,该流程依然支持”保存“操作,同时被标记为“非法”状态。
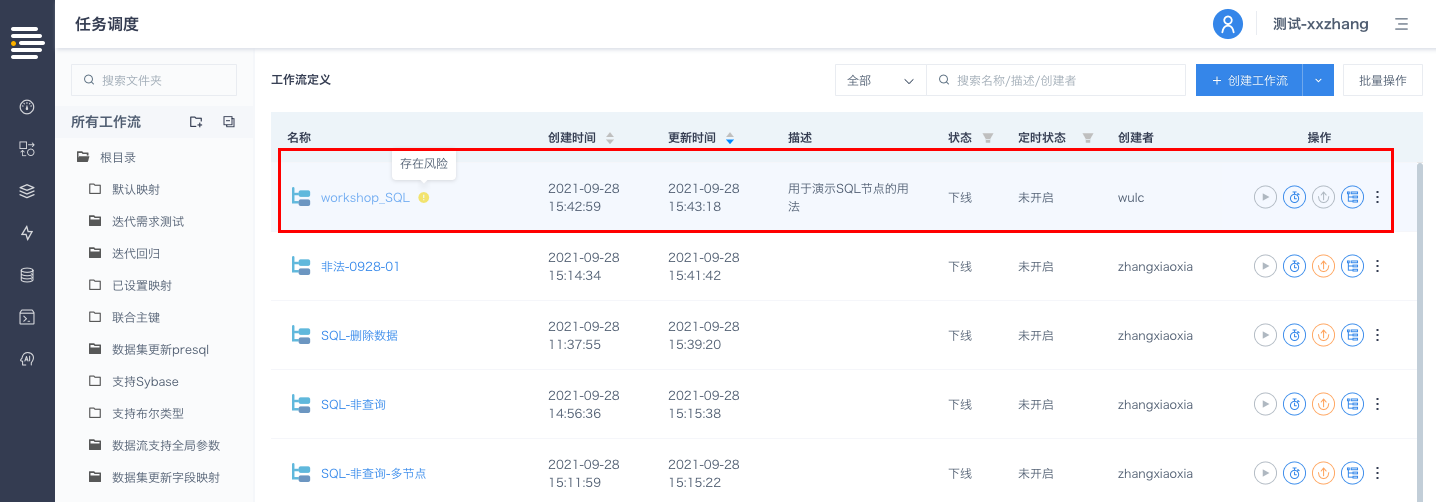

“非法“状态的工作流/数据流不支持以下操作:导出、上线、运行。
对于“非法“状态的工作流,不支持通过SUB_PROCESS节点进行引用。

对于“非法“状态的数据流,不支持通过DATAFLOW节点进行引用。
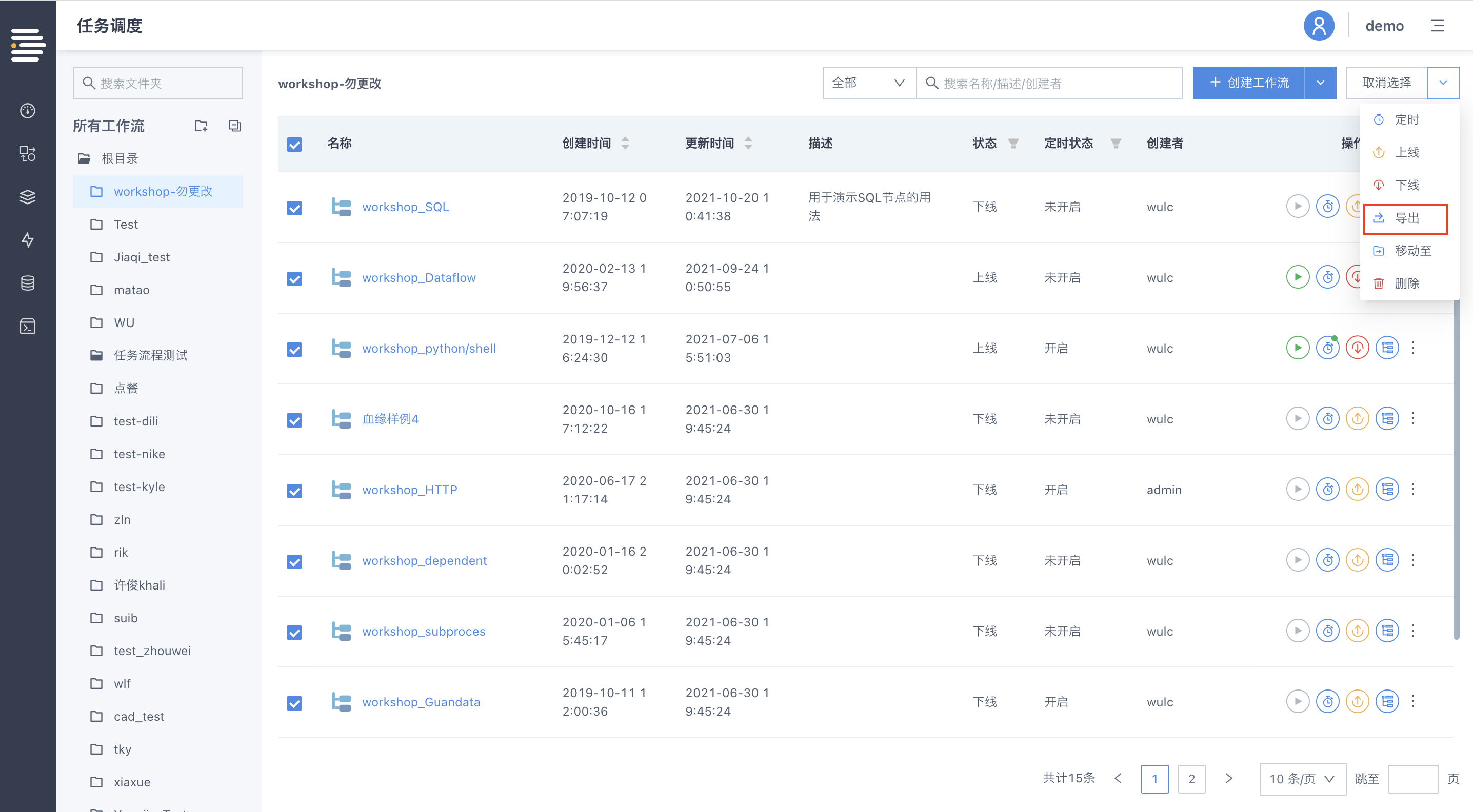
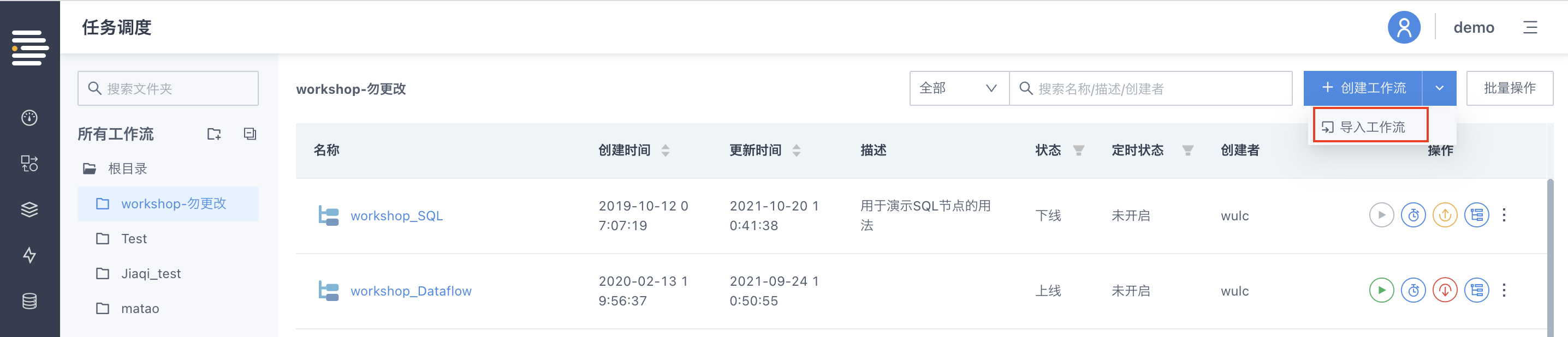
工作流/数据流定义支持批量导出导入
工作流/数据流定义的批量导出文件为zip格式,内部包含所有导出流程的json文件(其中包括相应流程的“目录信息”)。
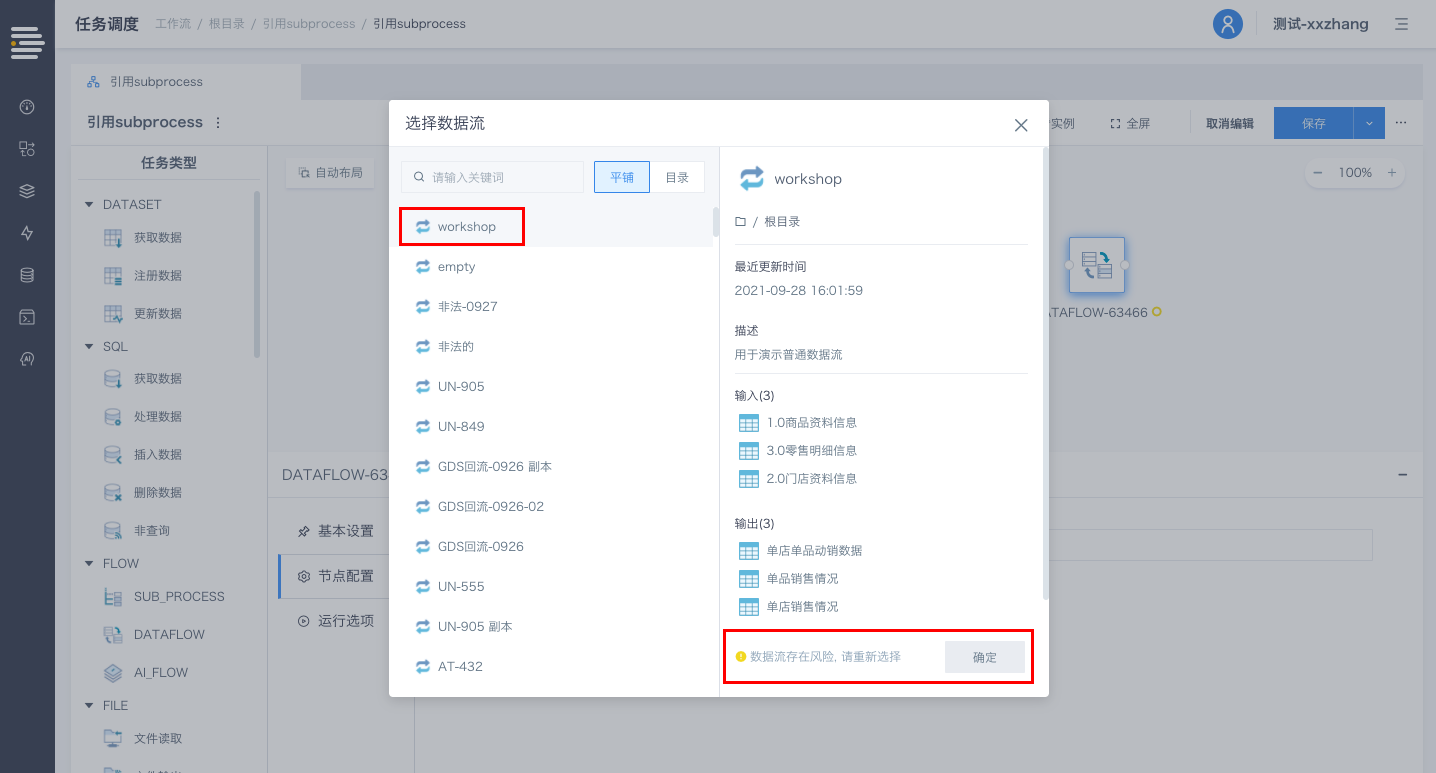
工作流定义/数据流定义进行批量zip文件的导入操作时支持选择是否应用路径信息。
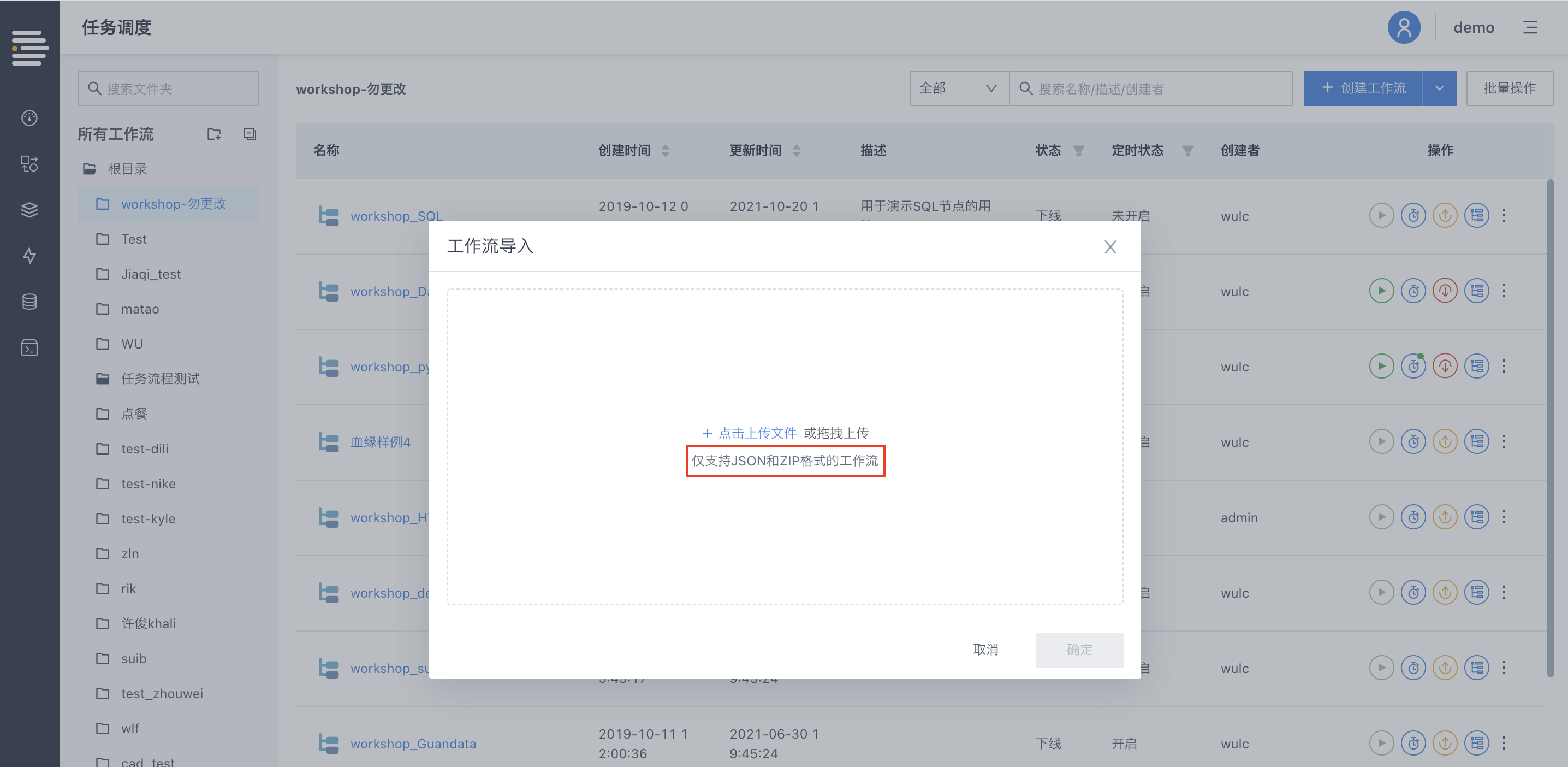
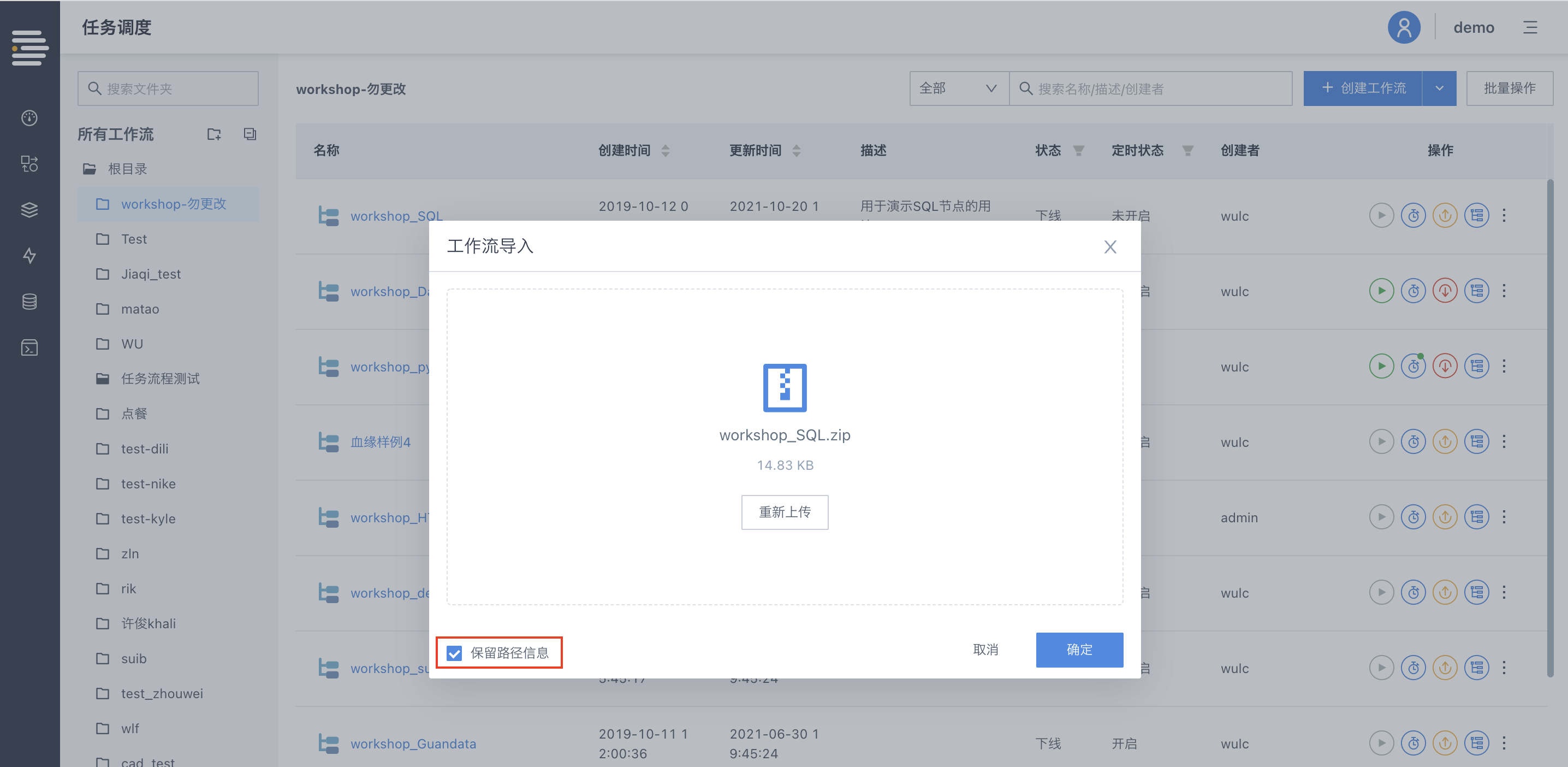
应用路径信息:所有流程均按照json中“目录信息”作为目标目录进行导入操作,如果当前环境缺少相应目录则针对该流程给出报错;
不应用路径信息:所有流程均导入当前目录内(如果当前目录为“所有工作流”则默认导入“根目录”)。
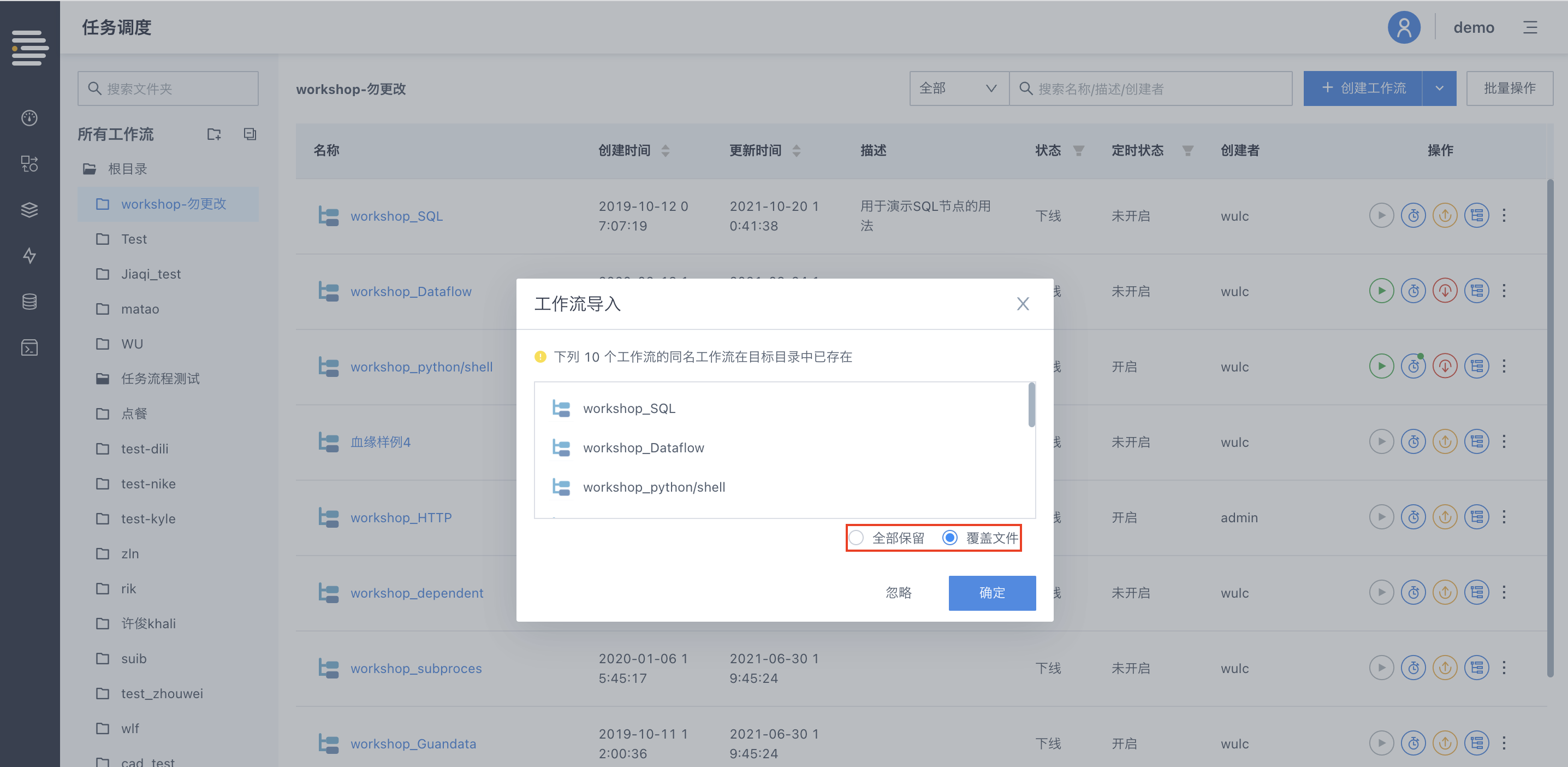
目标目录下如果不存在同名流程,则自动进行“新建”;如果存在同名流程,则支持选择进行“全部保留”/“覆盖文件”。
“全部保留”:会自动在新导入的流程名称后增加副本后缀
“覆盖文件”:会对已存在的流程内容进行覆盖更新(对于“上线”状态的流程无法进行“覆盖文件”操作)
数据集的数据清理操作新增并发互斥判断
对于正在更新中的数据集不支持进行数据清理操作,新增并发互斥判断并支持进行相关提示。
非查询支持HIVE数据源
工作流-非查询节点,新增对HIVE类型数据源的支持,选择对应数据连接及SQL语句后运行,即可将SQL语句推至对应HIVE数据连接运行。
.png)
“资源中心”Python文件支持使用全局参数
在通过工作流Python节点引用资源中心的Python文件时,若Python文件中包含全局参数/工作流参数/动态参数/节点参数等,均可正常进行解析替换。
在Python节点上使用参数及变量
.png)
在Python文件中使用参数及变量
.png)
在Python节点引用Python文件
.png)
工作流定义补数运行支持按天/周/月运行
工作流定义开启补数运行时,支持选择补数策略。
.png)
补数日期优化:仅需指定至日期,默认代表时间范围为[起始日期 00:00:00~终止日期 23:59:59];
补数策略控制在指定日期范围内需执行补数的时间,当前支持指定每天/每周/每月的特定时间运行,支持:
每天运行,支持设置至时、分;
每周运行:每周周N,支持设置至时、分;
每月运行:每月N日,支持设置至时、分;
设置完成后,补数时间按照补数范围内符合补数策略的时间运行。
例如设置补数日期范围:2021-10-13 ---2021-10-31,补数策略:每周周一,三 21时15分,则补数时间:
如参数为date类型:2021-10-13 、2021-10-18、2021-10-20、2021-10-25、2021-10-27
如参数为datetime类型:2021-10-13 21:15:00(以此类推...)
工作流中添加便签注释功能
入口:
.png)
.png)
原数据流注释同样做了入口优化
.png)
DB数据流支持展示历史记录
在工作流、普通数据流支持展示历史记录的基础上,新增了DB数据流对历史记录的展示支持。
入口:
.png)
功能详情见:《2021年09月重要功能更新》