2021年05月重要功能更新
以下功能在1.7.0及之后的版本中均可使用
管理中心支持进行服务器资源监控及告警
入口:管理中心-运维管理-服务器资源
管理中心支持针对服务器硬件资源进行监控,包括服务器各节点的内存、CPU、磁盘使用情况。
.png)
针对服务器硬件资源的使用情况,支持开启阈值告警(默认采用阈值CPU 75%、磁盘 85%、内存 75%),针对多节点环境只要有一个节点命中阈值即会触发告警。

管理中心Spark任务监控类型扩展并新增超时处理机制
入口:管理中心-运维管理-任务管理
目前任务管理列表针对Spark任务进行全覆盖,包括:工作流、数据流、数据集、数据质量模型操作中相关的所有Spark任务。
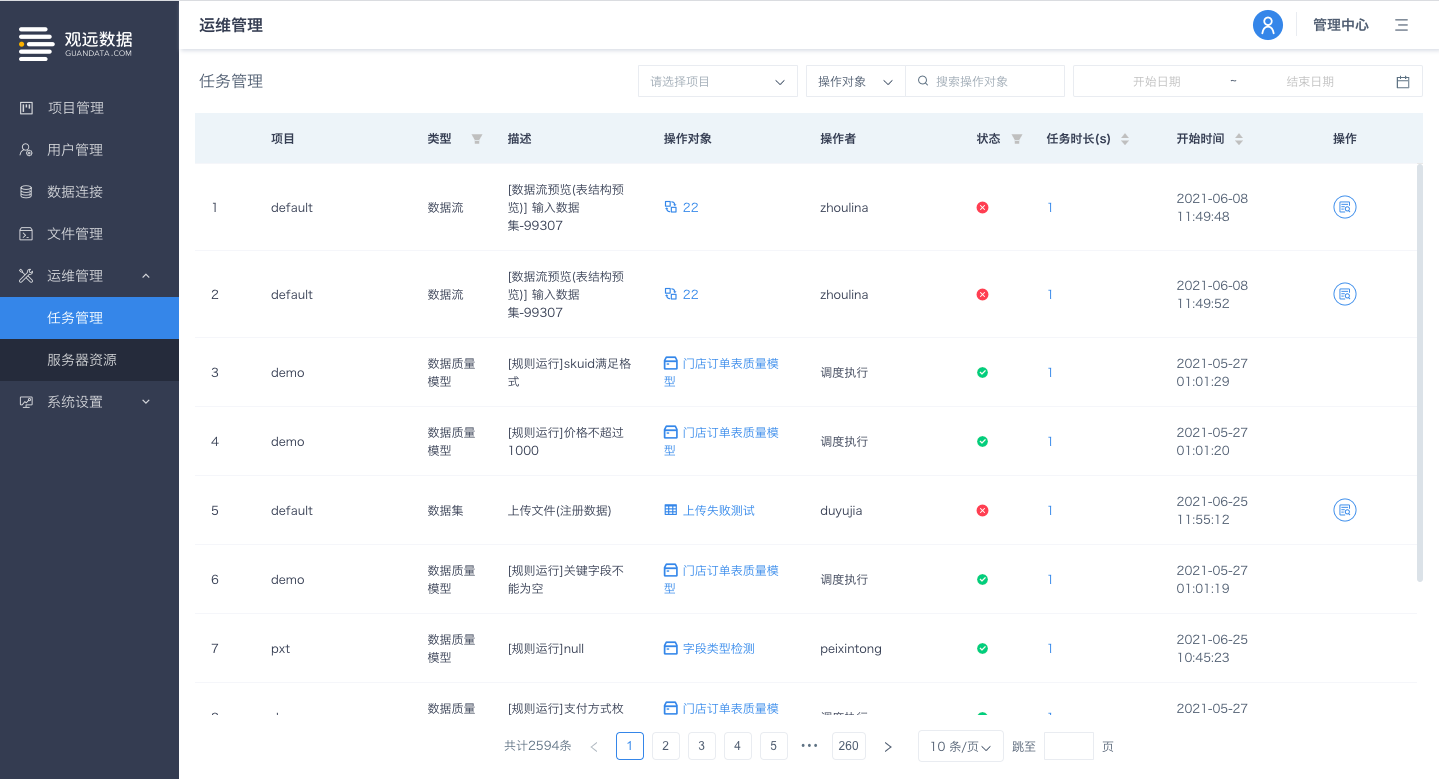
对于所有类型的Spark任务新增超时处理机制,默认超时两小时后自动kill相关任务,避免某些配置不合理的Spark任务占用大量计算资源并影响其他任务。
.png)
工作流定义中QUALITY_MODEL节点支持输出规则运行结果
通过工作流运行QUALITY_MODEL节点时,往往需要根据QUALITY_MODEL节点的运行结果,对合规数据及异常数据进行不同的处理。(例如对合规数据落库操作,异常数据不落库,或将异常数据注册为数据集,用于进行结果留存或数据质量可视化分析等)
为支持用户进一步进行数据质量分析,工作流定义中QUALITY_MODEL节点支持输出各规则运行结果,其各项输出可被当前工作流定义中其他节点作为输入项引用。
入口:工作流定义详情页-QUALITY_MODEL节点-选择数据质量模型-输出
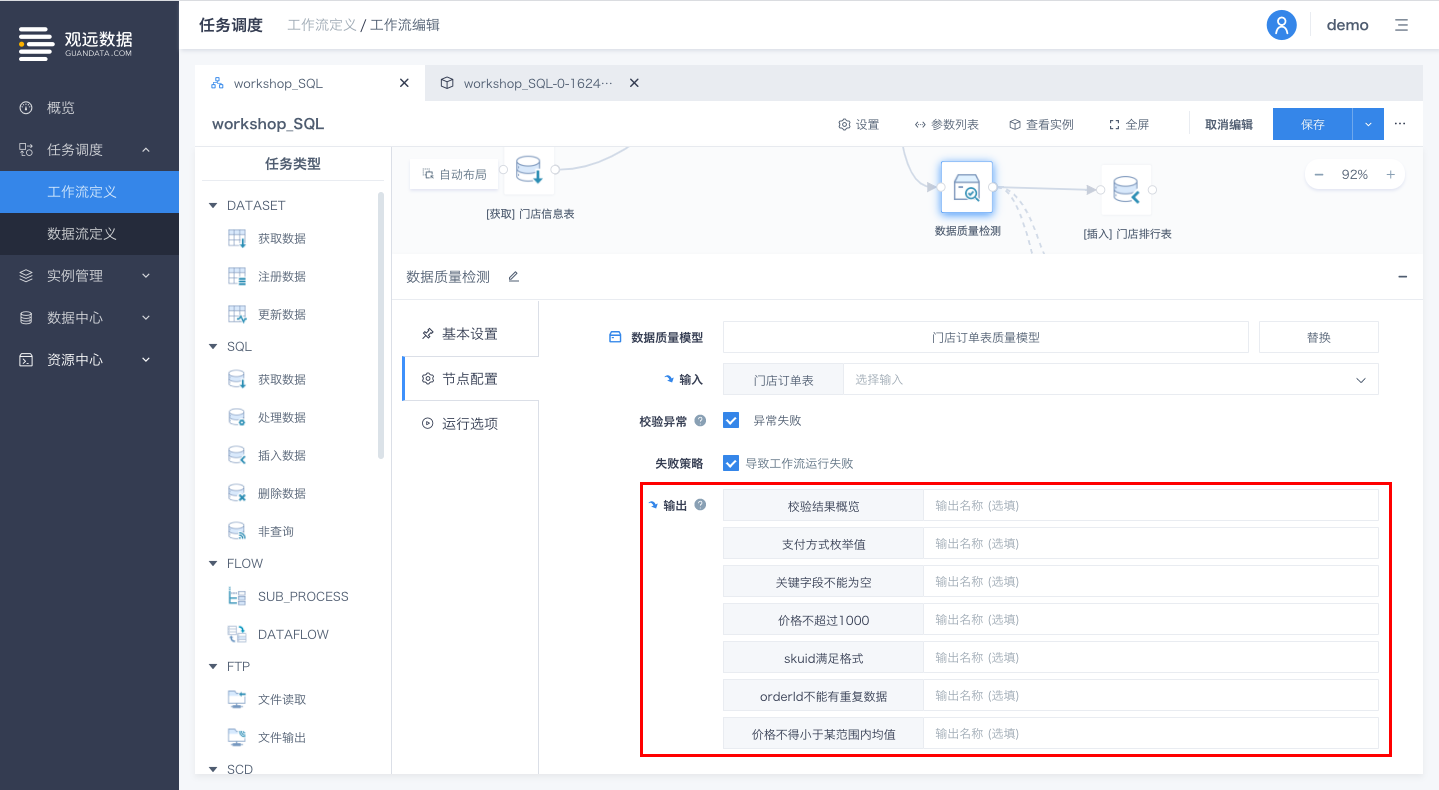
输出项分为:
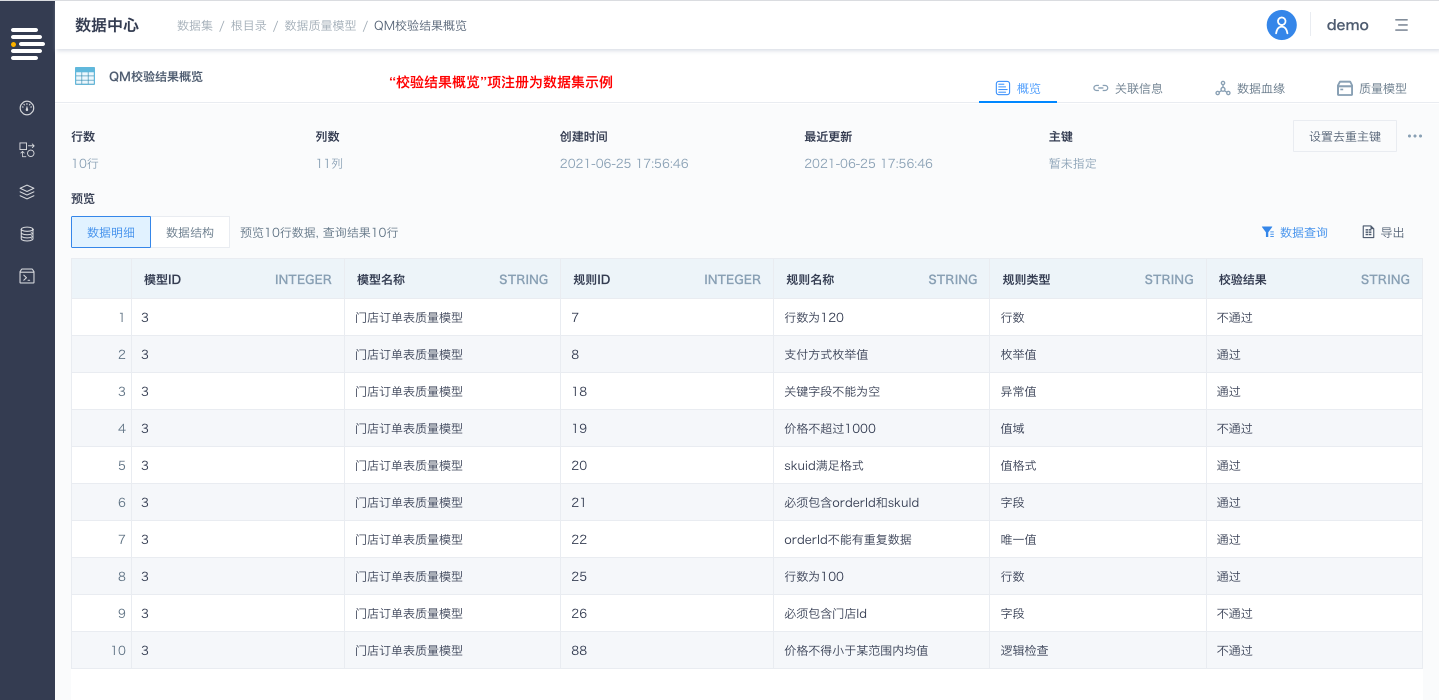
1.校验结果概览;
'校验结果概览'为QUALITY_MODEL节点的固定输出,包括当前模型的基本规则信息及对应规则的当次运行记录详情(如下表格所示):
| 模型ID | 模型名称 | 规则ID | 规则名称 | 规则类型 | 检查规则 | 数据要求通过率 | 数据实际通过率 | 校验结果 | 运行时间 | 规则运行记录ID |
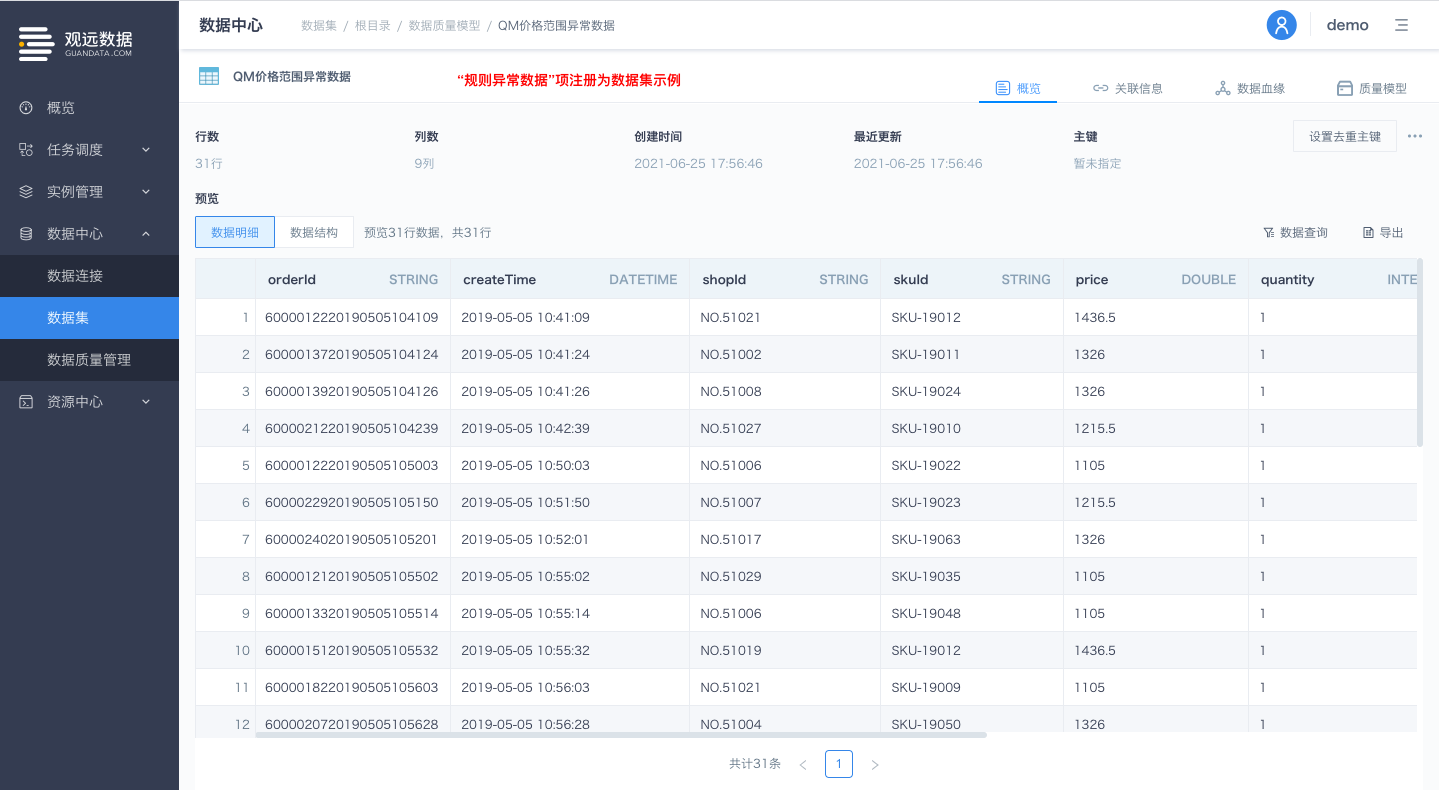
2.字段粒度规则及逻辑检测规则的校验异常数据;
每个字段粒度规则及逻辑检测规则的异常数据均会作为独立的输出项(表粒度规则暂不支持作为输出项);
输出项包含:
字段粒度规则生成的异常数据的各行各列信息(与当前数据质量模型-运行记录-规则异常数据详情一致);
规则运行记录ID(可根据规则运行记录ID与'校验结果概览'中的运行记录详情信息进行匹配);
例如QUALITY_MODEL A,存在2个表粒度规则,8个字段粒度规则,1个逻辑检测规则,在节点处的展示为10个输出(8个字段粒度规则异常数据输出+1个逻辑检测规则异常数据输出+1个校验结果概览)
可根据业务需要,将输出项搭配SQL/DATASET等节点进行灵活配置使用。
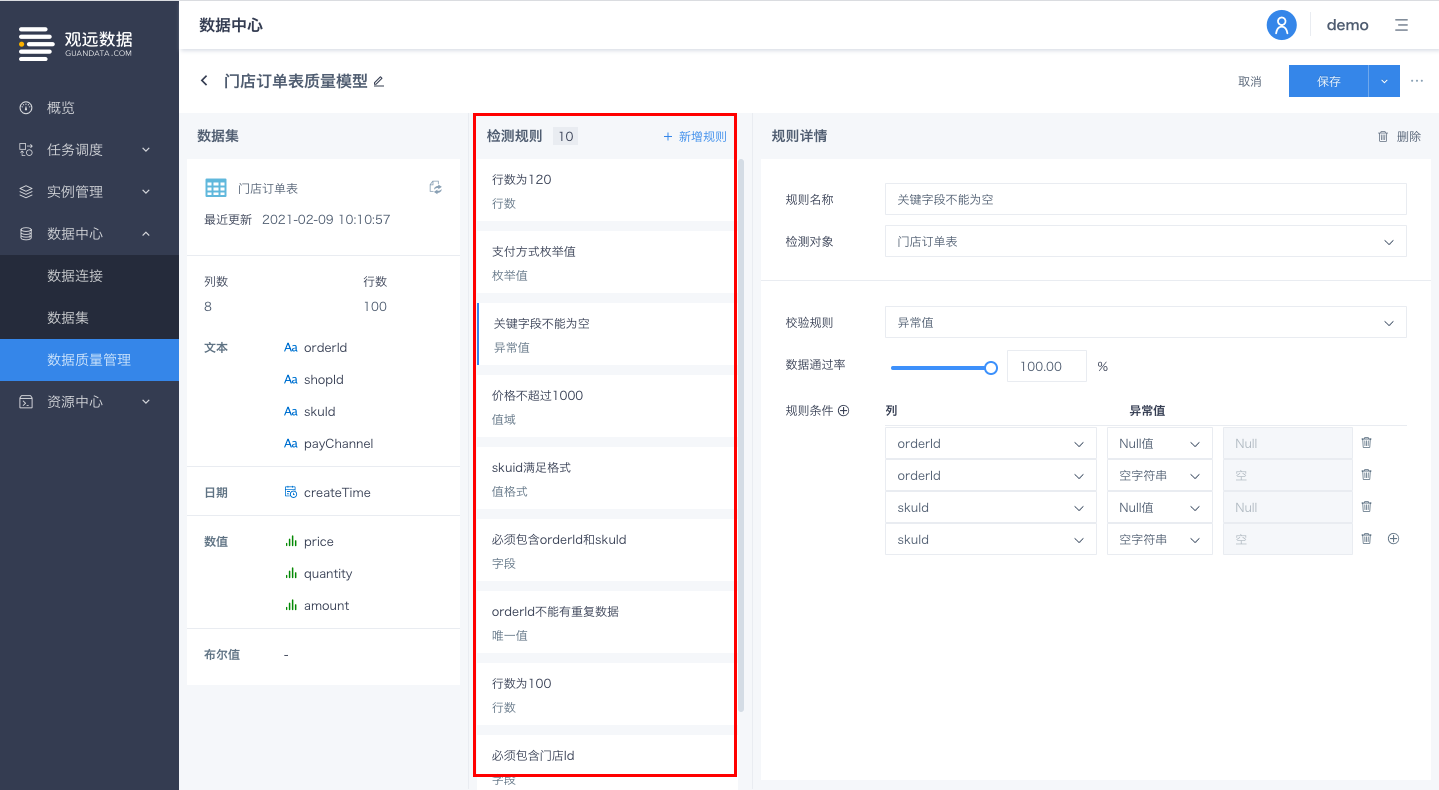
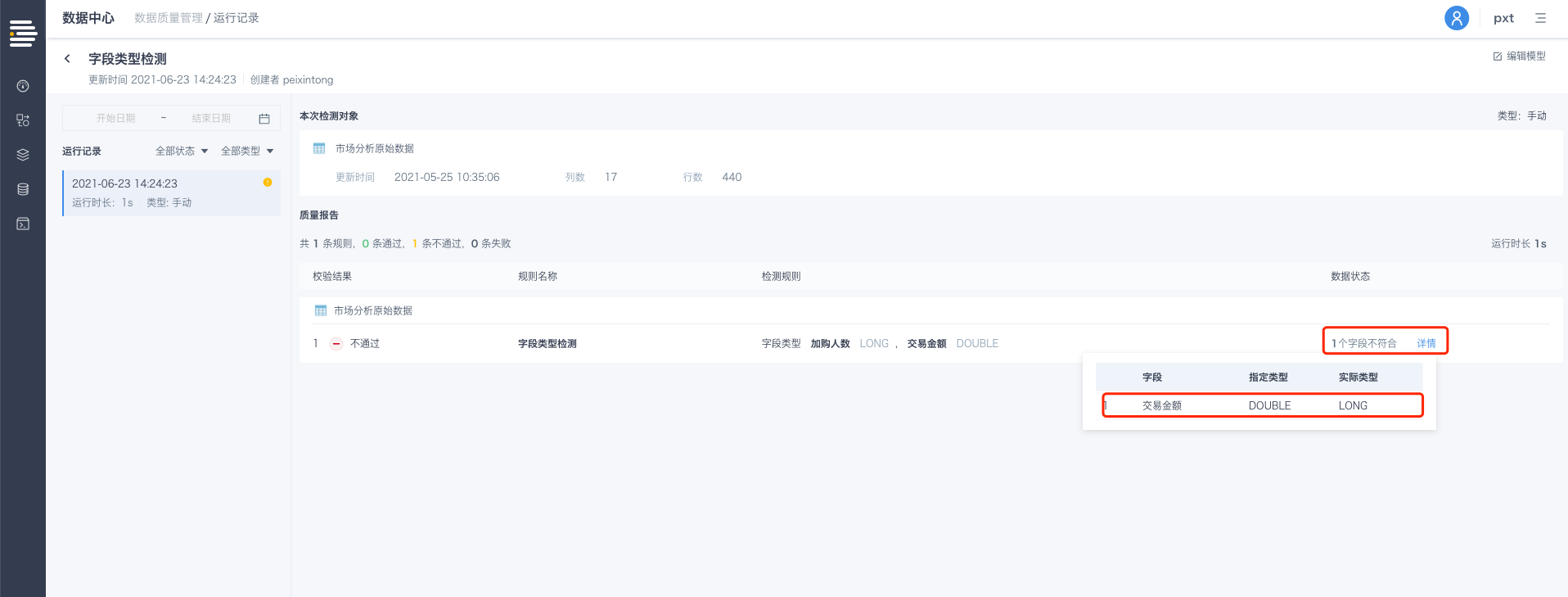
数据质量模型新增字段类型检查
在ETL的过程中,可能会发生预期外的字段类型变更情况,用户往往需要明确关键字段的类型是否符合要求,以保证后续操作无误。平台在数据质量模型表粒度的检查规则中,新增了对字段类型检查的支持。
入口:数据质量模型-编辑-校验规则-表粒度-字段类型
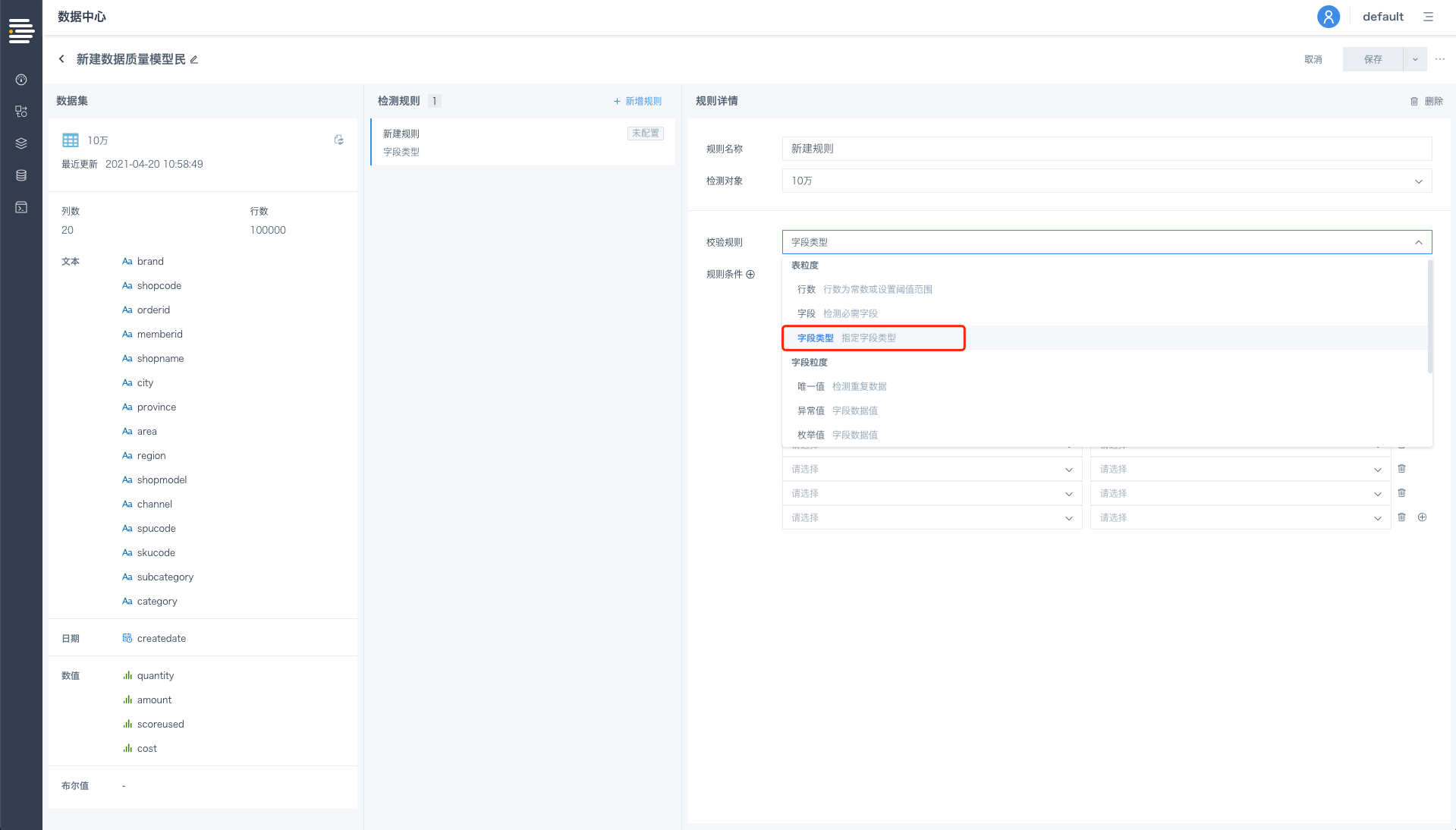
选择目标数据集的待检测字段,及该字段的期望类型,保存规则并运行,即可执行对该字段的类型检测。
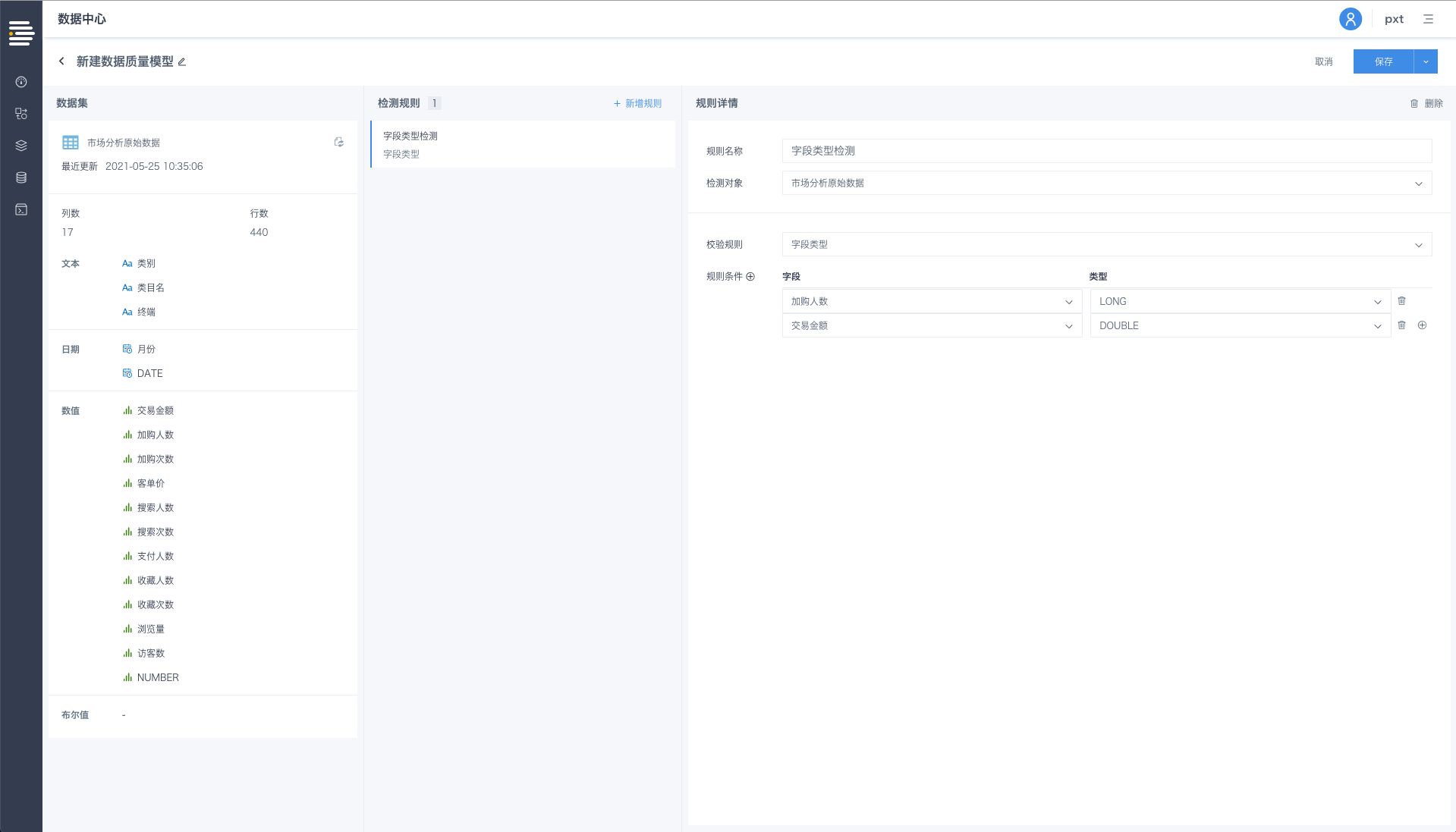
若字段类型检测符合预期,该规则通过; 若字段类型检测不符合预期,将在运行记录页对当次运行进行异常明细展示;
平台当前可支持检测的字段类型有以下9种:
| INTEGER | SHORT | LONG | FLOAT | DOUBLE | STRING | DATE | DATETIME | BOOLEAN |
DB数据流支持导入导出功能
对于用外部数据库进行数仓建设的项目,从测试环境发布至生产环境时,将会涉及到DB数据流的迁移。
为支持DB数据流在跨环境时的[DB数据流初始化]、[DB数据流更新]迁移场景,新增DB数据流支持导入导出的功能。
导出功能
入口:DB数据流详情页-导出
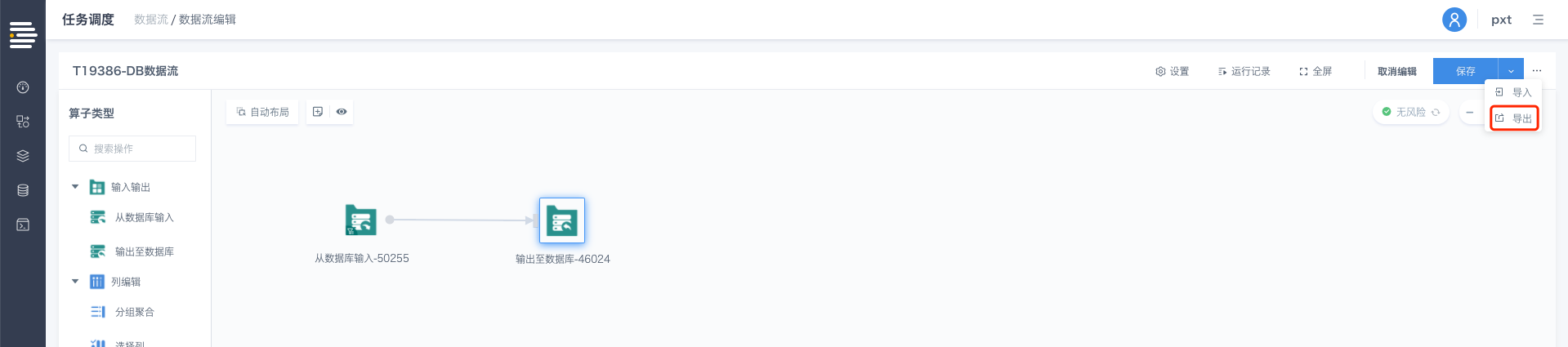
单击[导出],自动下载DB数据流对应的JSON文件至本地。
[DB数据流初始化]迁移场景:
入口:数据流定义列表页-导入数据流
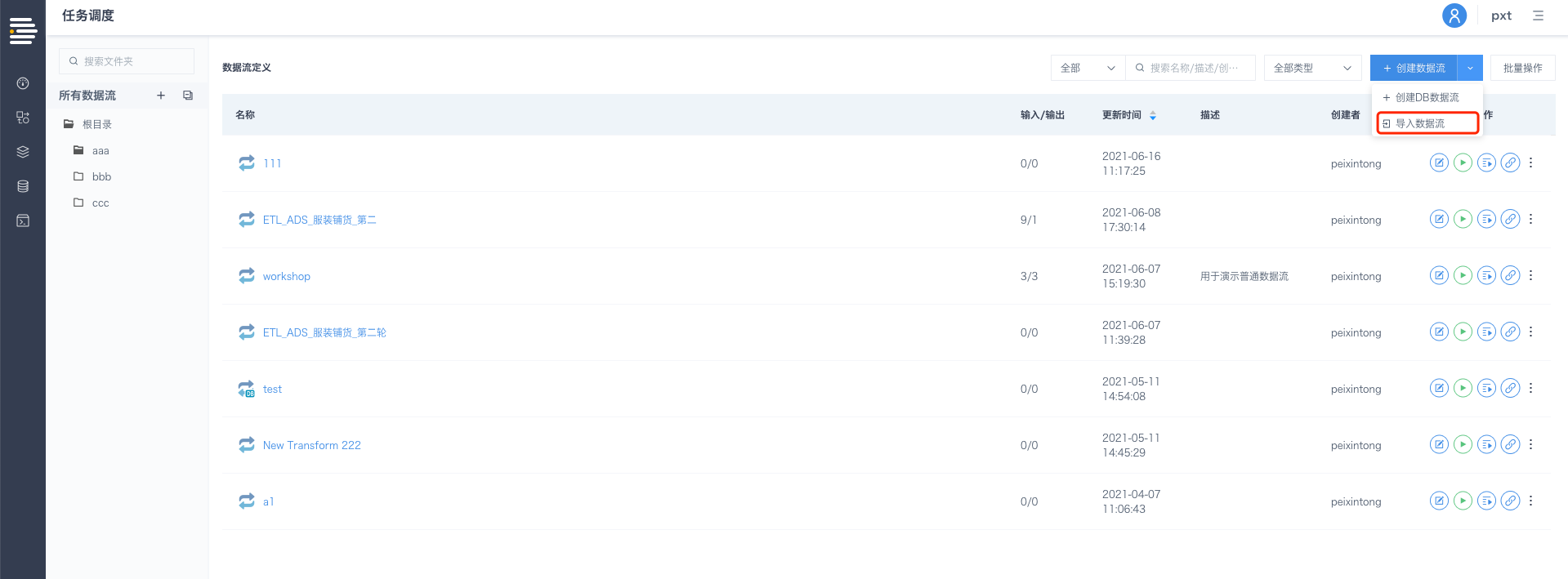
在导入数据流弹窗上传目标DB数据流的JSON文件(该入口同时支持普通数据流&DB数据流导入,系统将自动识别导入的数据流类型);
配置DB数据流基本信息(名称、位置、描述等),单击[确定],进入DB数据流详情页,即完成DB数据流的导入过程。
导入策略:
平台对JSON文件中的各项配置信息进行导入(如数据流结构、sql语句、各算子详细配置等);
考虑到跨环境时的数据连接不一定与原环境完全对等,数据连接相关信息不做导入,相关算子状态显示为未配置,需要在新环境完成连接配置后,才能保存数据流定义。

[DB数据流更新]迁移场景:
入口:DB数据流详情页-导入
在导入数据流弹窗上传目标DB数据流的JSON文件(该入口仅支持对应DB数据流的上传,上传普通数据流/其他JSON文件将会报错),单击[确定],即完成DB数据流的导入。
若为[DB数据流更新]场景(即原详情页中存在算子),平台将按照如下策略进行导入操作:
根据算子ID进行匹配:
若导入的JSON文件算子ID与详情页内的算子ID一致,则按照JSON文件配置,对该算子进行配置项更新,保留详情页内已配置的数据连接相关内容不变;
若导入的JSON文件算子ID与详情页内的算子ID不一致,则根据JSON文件的数据流结构进行算子新增/删除,新算子按照JSON文件进行配置,数据连接相关内容为空,待用户自主配置。
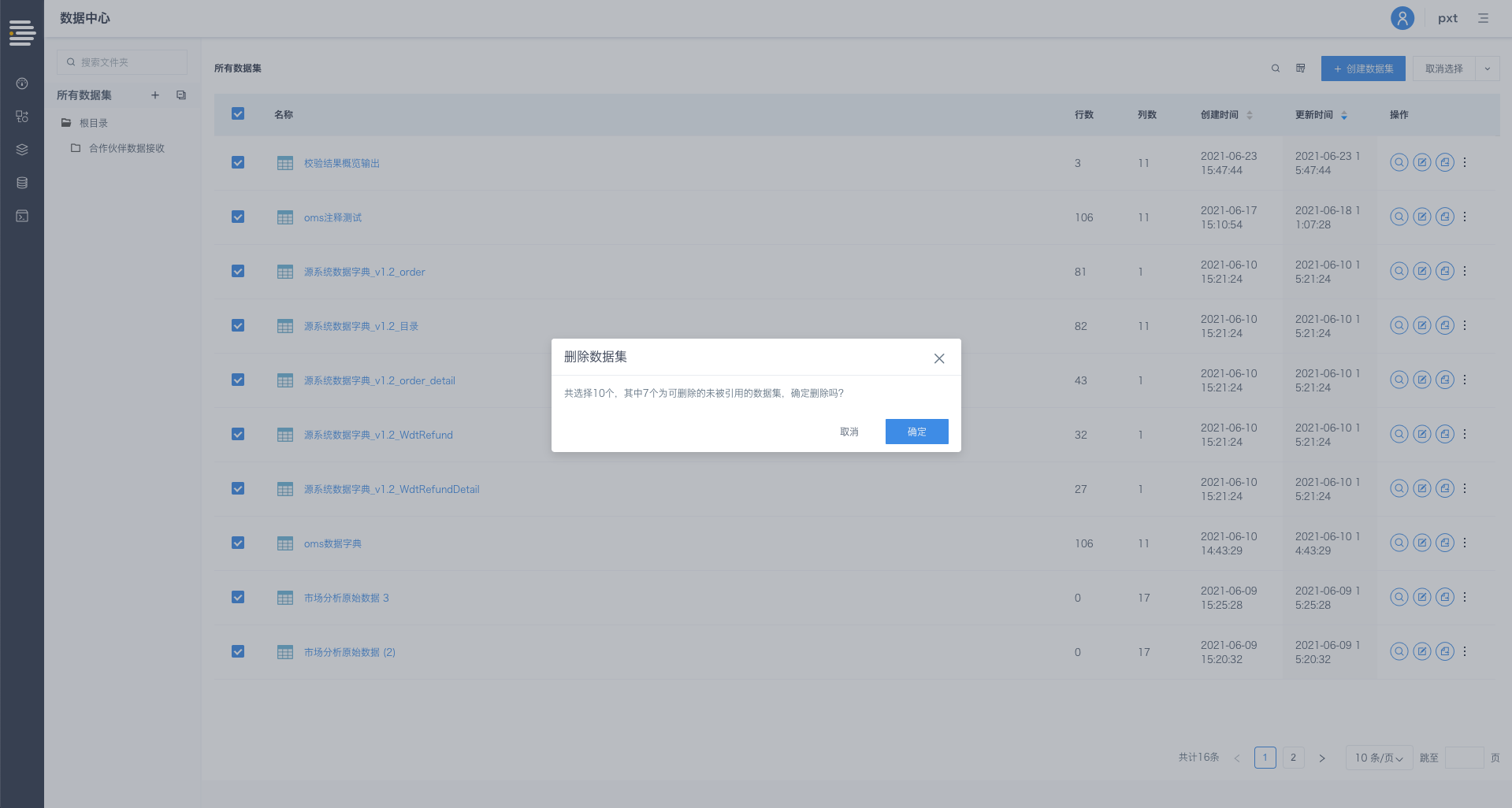
数据流定义&数据集支持批量删除
平台支持对未被引用的数据流定义/数据集进行批量删除。
入口:数据流定义列表页/数据集列表页-批量操作-选择目标文件-删除
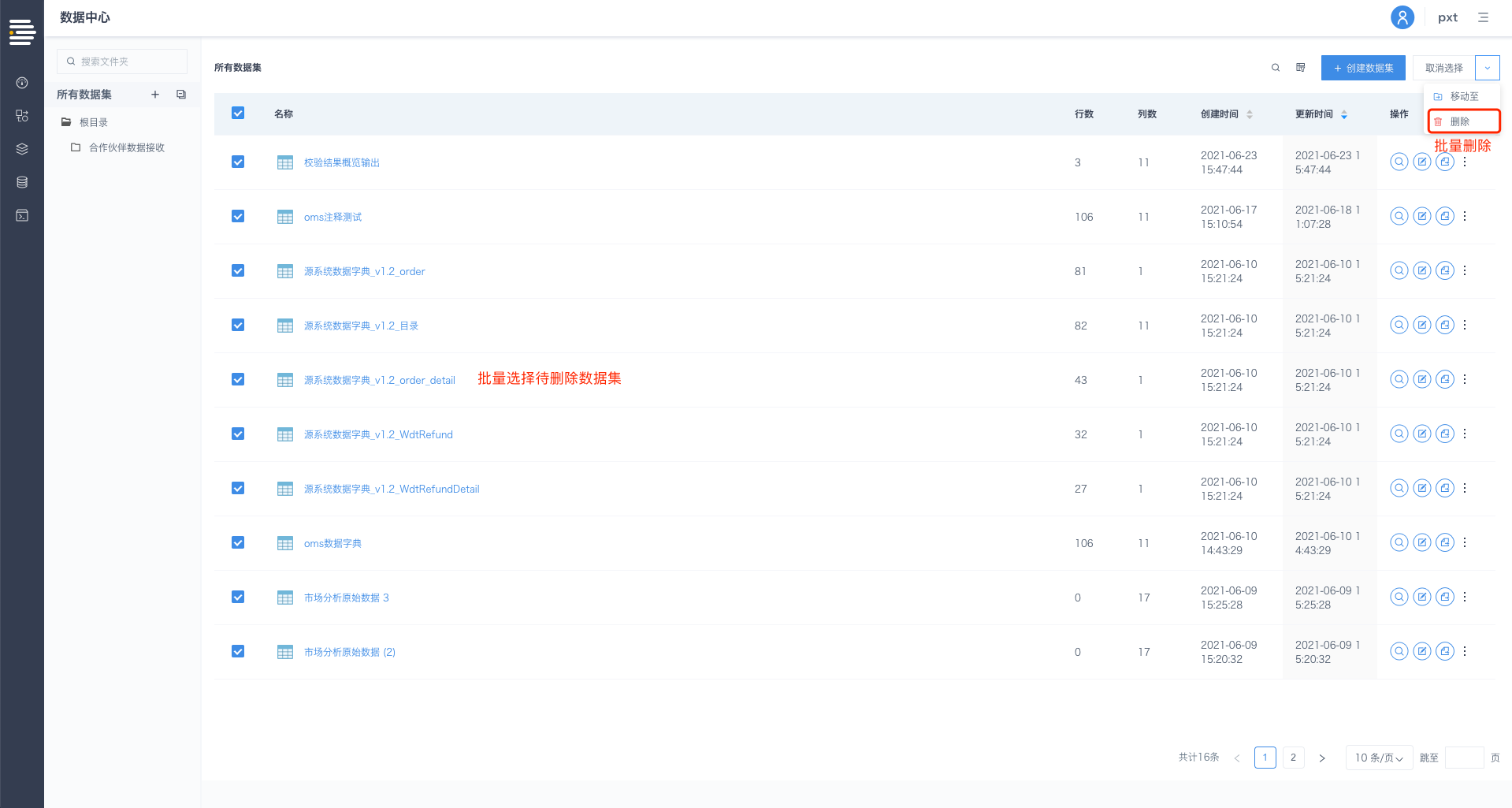
选择删除,出现删除数据集/数据流定义确认弹窗,显示可支持删除的数据集/数据流定义数量,单击[确定]完成数据集/数据流定义的删除操作;
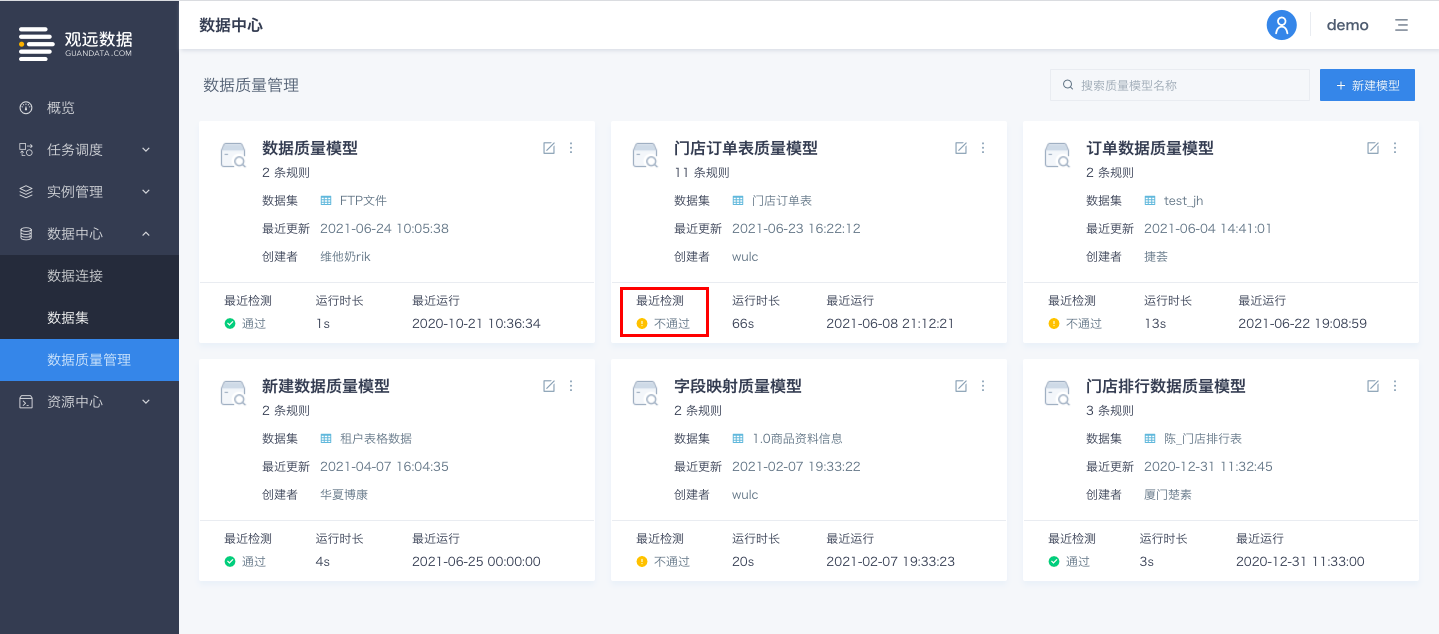
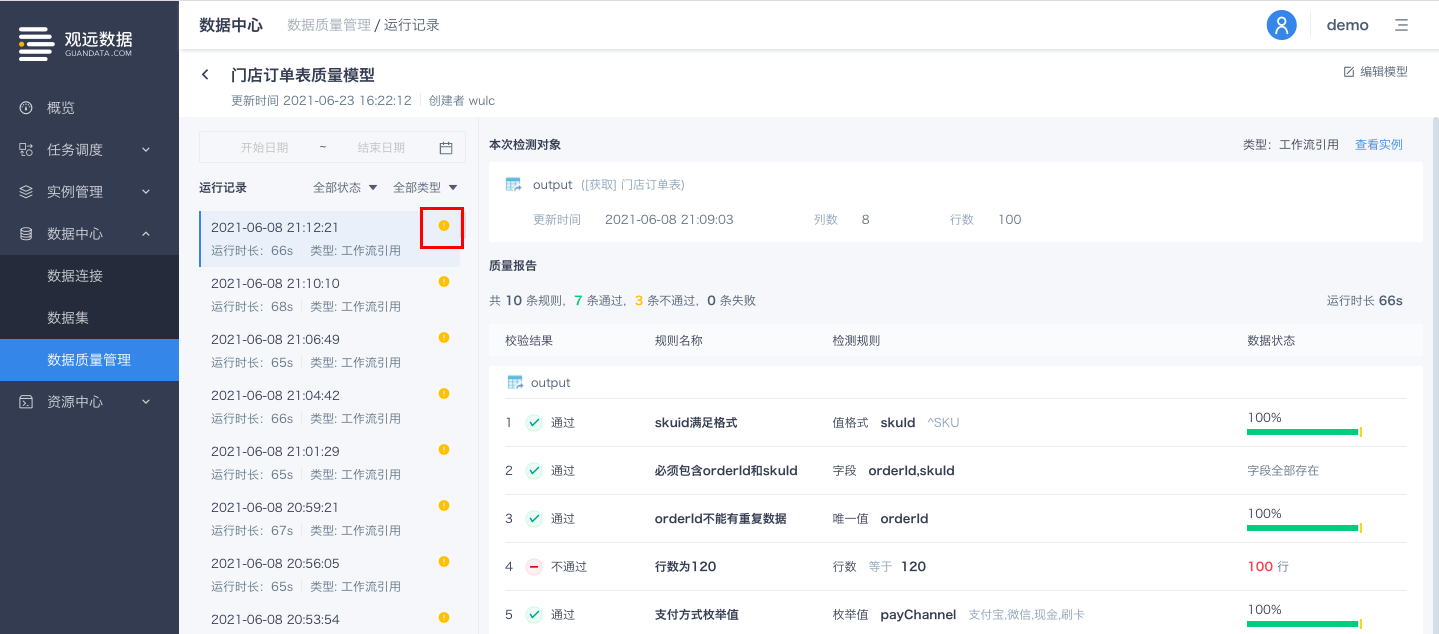
数据质量模型的运行状态支持实时更新
数据质量模型的运行状态支持实时更新,包括:数据质量模型列表页、数据质量模型运行记录页。
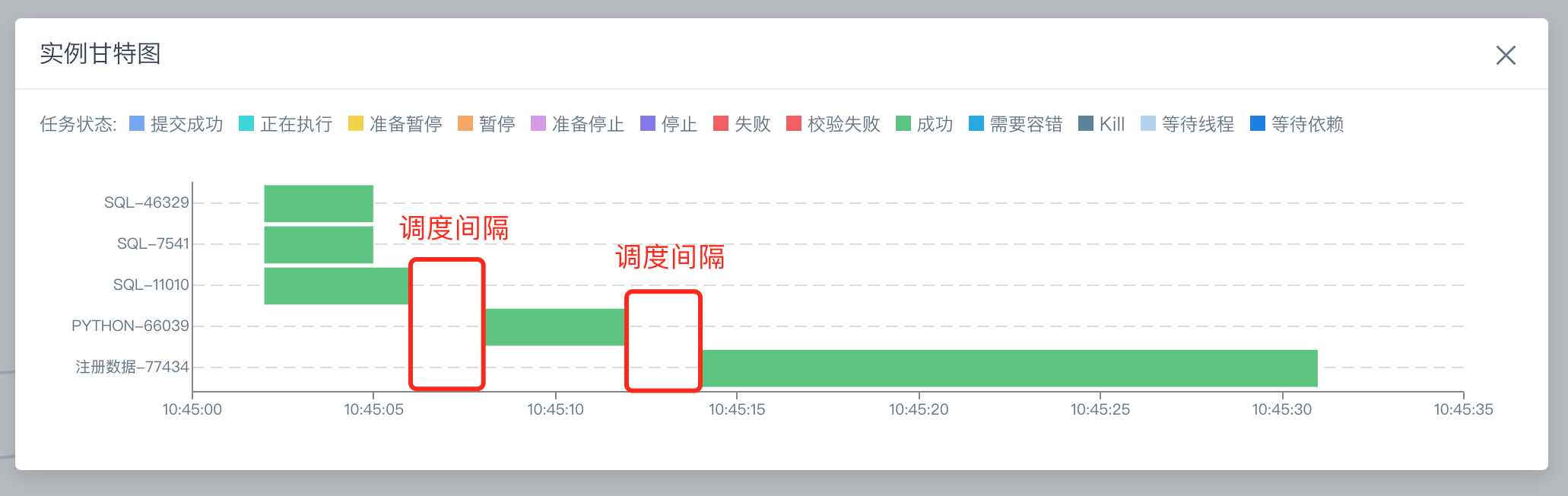
工作流支持调度间隔支持配置化调整
平台默认配置的工作流调度间隔参数为1000ms,可支持的最小间隔参数为100ms,用户可根据平台实际工作流调度间隔需要,调整间隔参数,进行调度策略优化。(可联系平台研发进行参数调整)
入口:工作流实例-查看甘特图