2021年08月重要功能更新
以下功能在1.10.0及之后的版本中均可使用
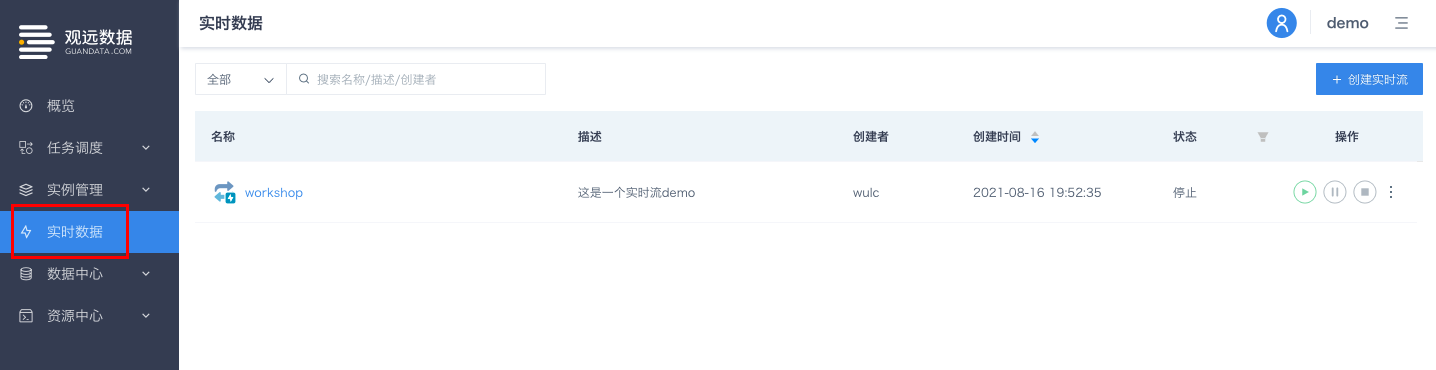
新增对实时数据同步的支持
(此功能为付费增值模块,如需试用请联系商务)
观远数据开发平台提供轻量级的实时数据同步功能,方便您使用单表同步方式,将源端数据库中的增量数据变化实时同步至目标数据库中,实现目标库实时保持和源库的数据对应,为低延时的应用场景夯实底层数据基础。
7 实时数据
入口:导航栏-实时数据
数据集存储支持设置分区
数仓建设的增量更新场景中,仅需要获取满足某些筛选条件的增量数据(eg:昨日新增的订单数据),数据量较大时针对全量数据进行查询会带来比较明显的性能瓶颈。
数据集支持分区设置后,基于分区字段进行筛选的数据查询,可以直接从数据集中使用分区以最快的速度获取数据。
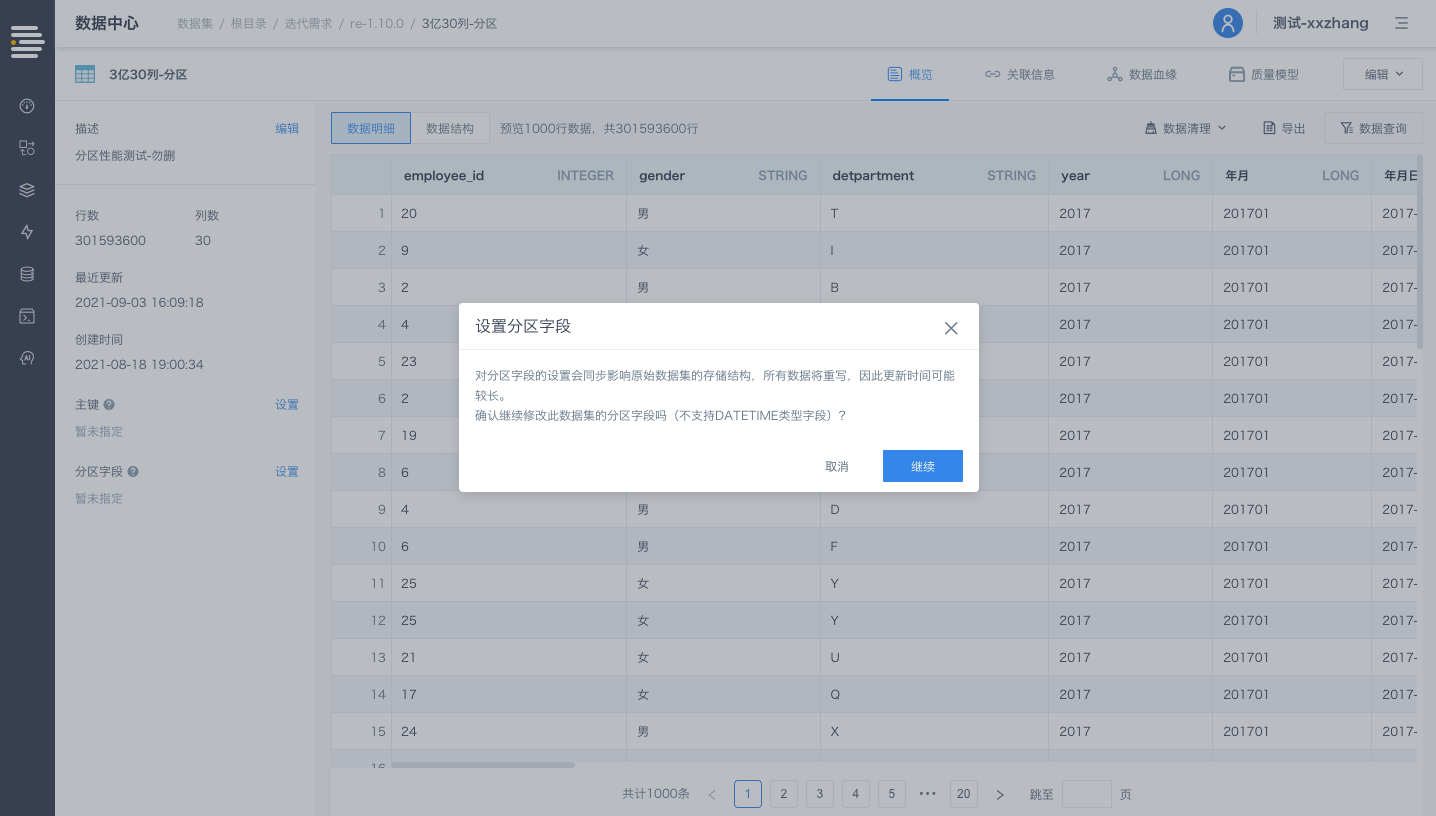
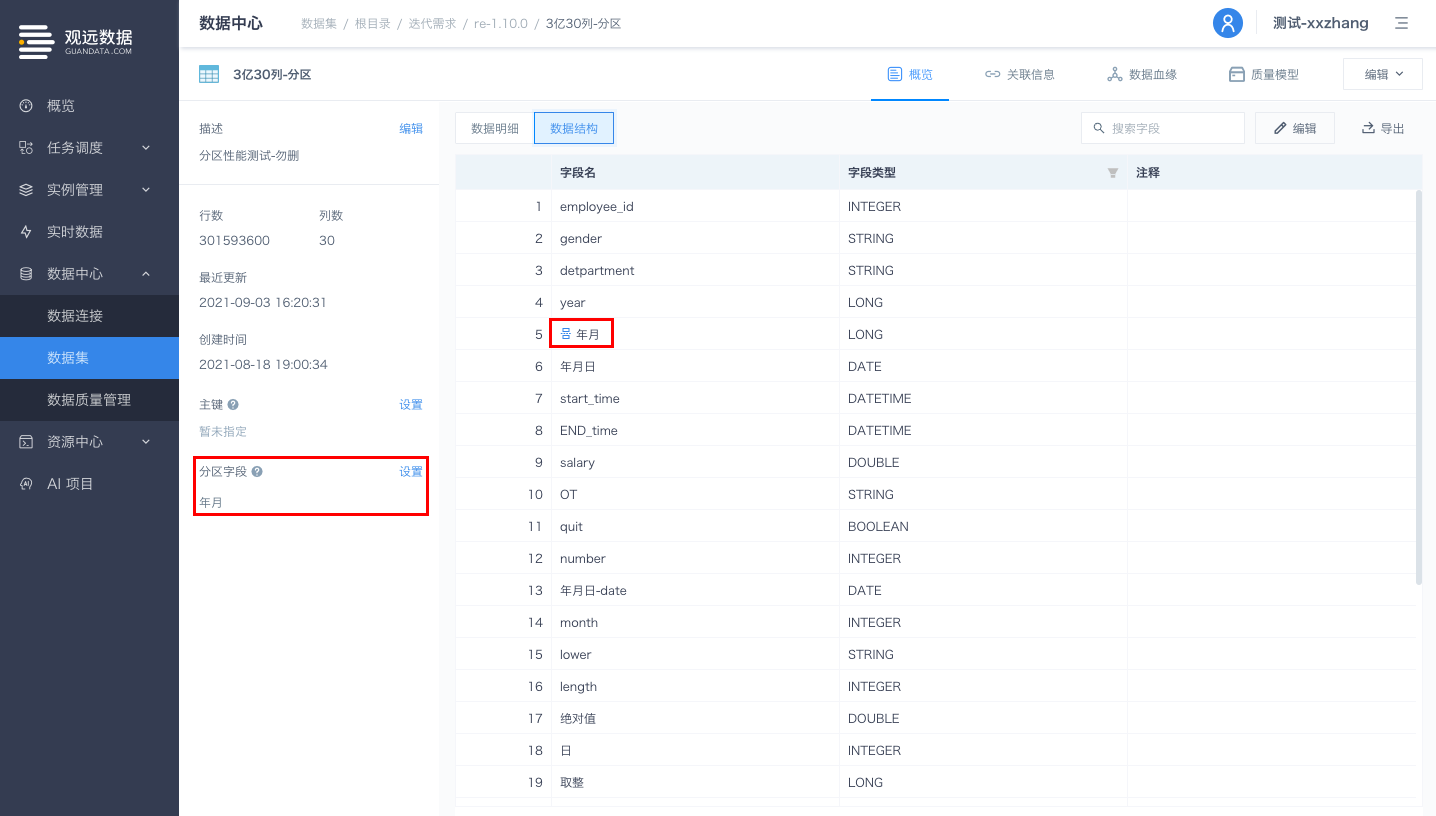
分区设置
数据集支持设置分区字段,设置完成后数据集会自动按照分区方式进行物理存储。
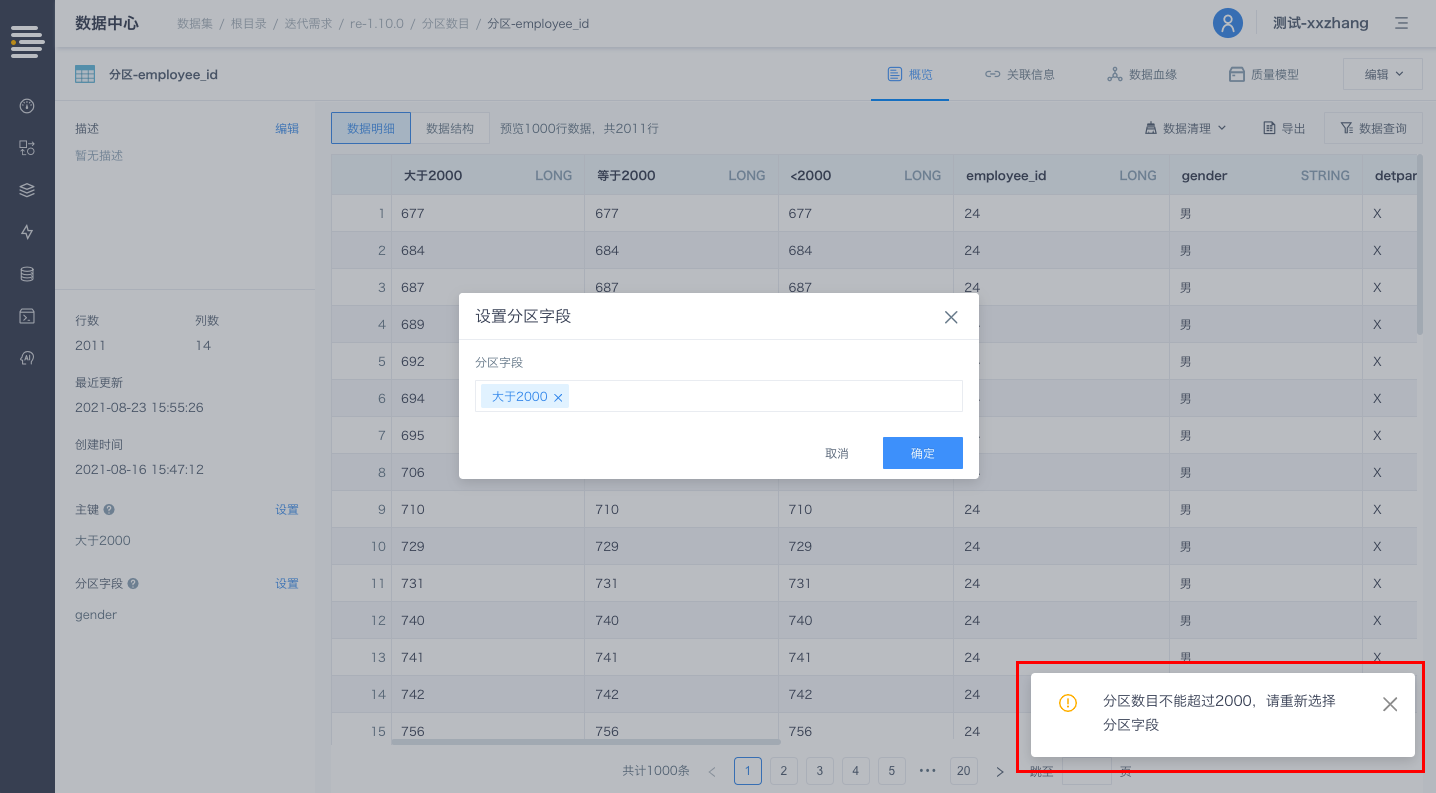
数据集会依据分区字段的具体数据值进行遍历来划分分区,单表分区数目上限为2000个(目前分区字段暂不支持DATETIME类型)。
入口:数据中心-数据集-数据集详情页-分区字段


数据读取
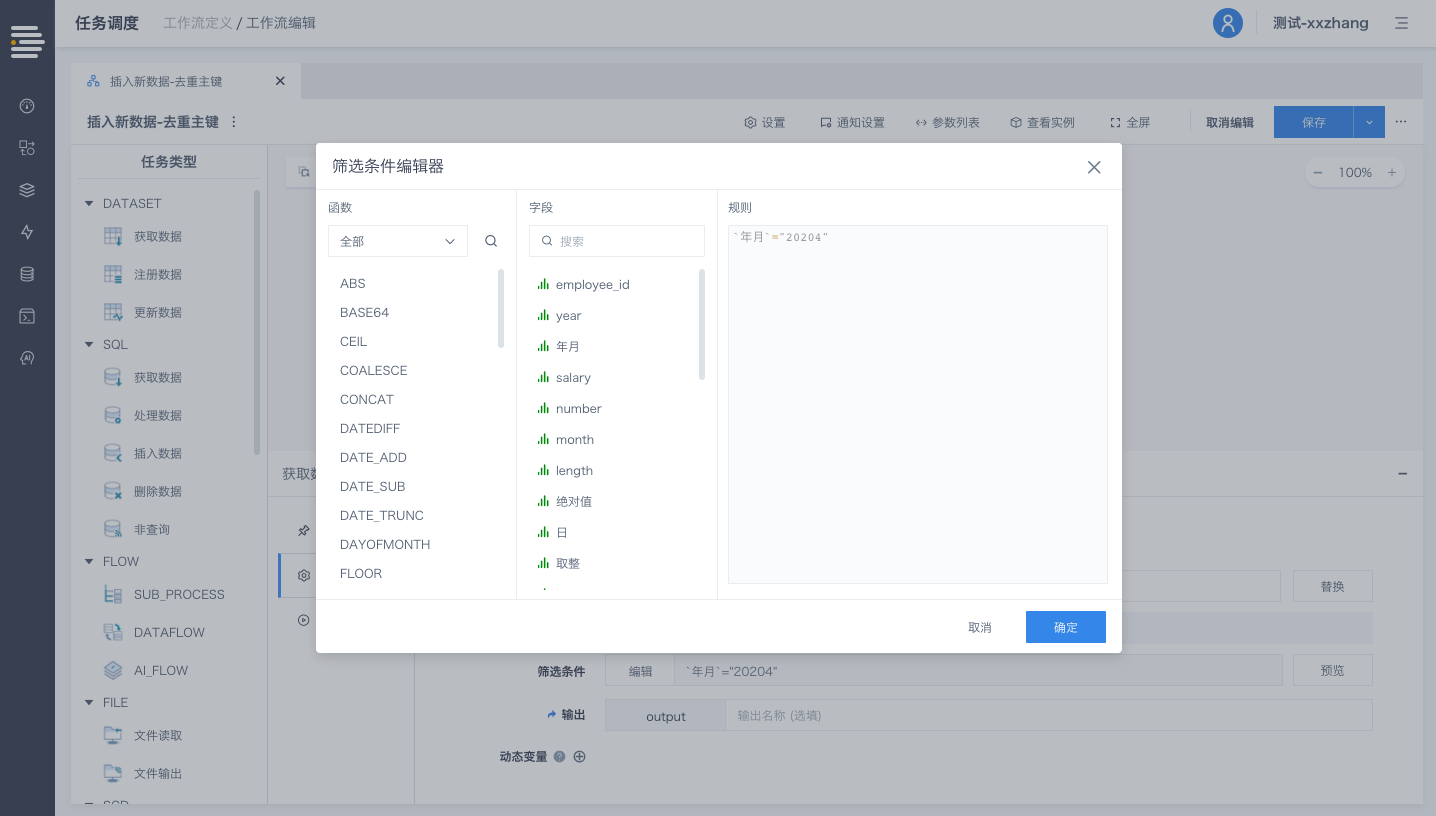
工作流中的“DATASET-获取数据”节点,新增对于筛选条件的设置,支持自由编辑过滤规则表达式:
表达式中支持使用全局参数/工作流参数(便于日常增量更新调度中动态获取增量数据)
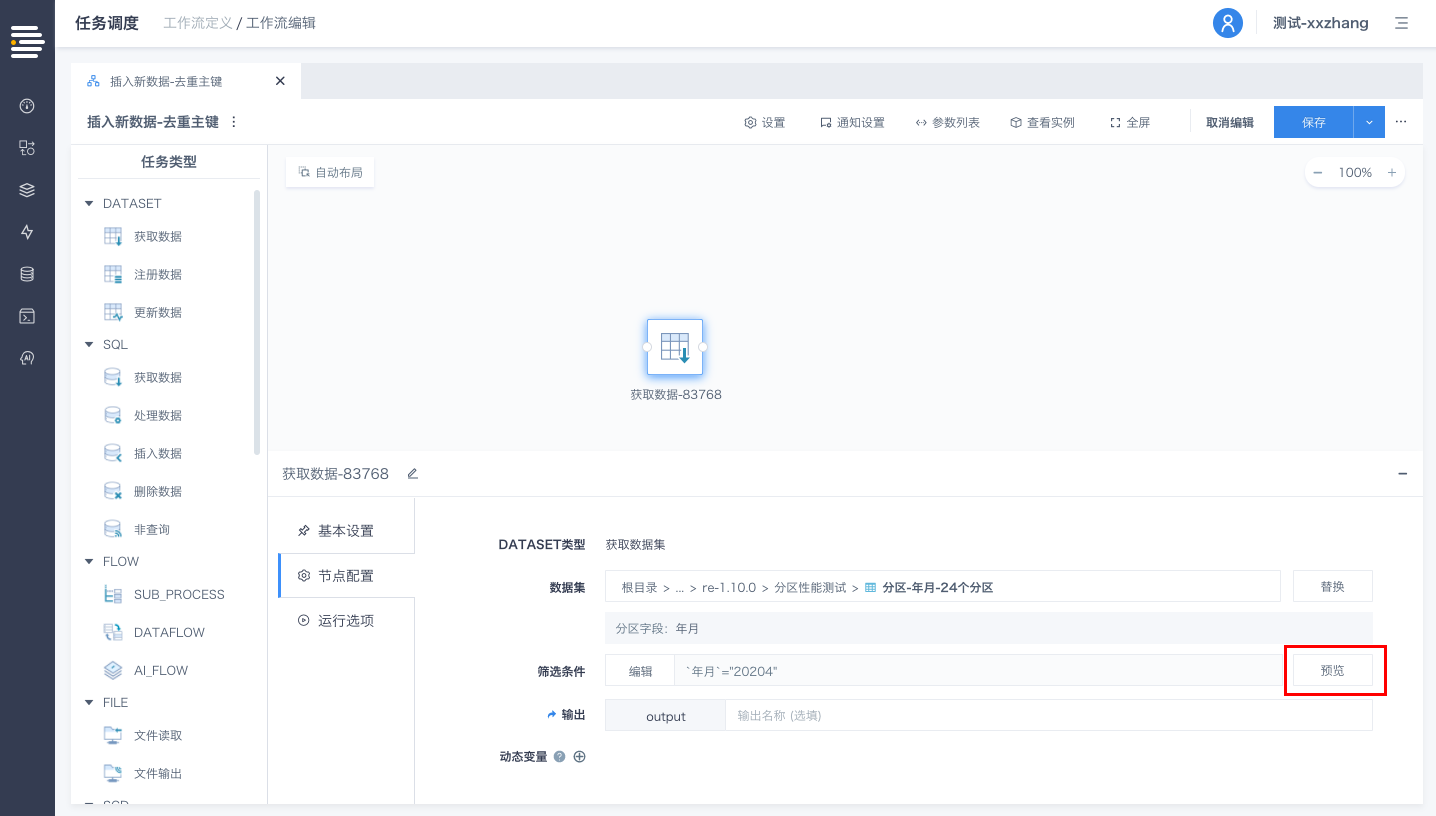
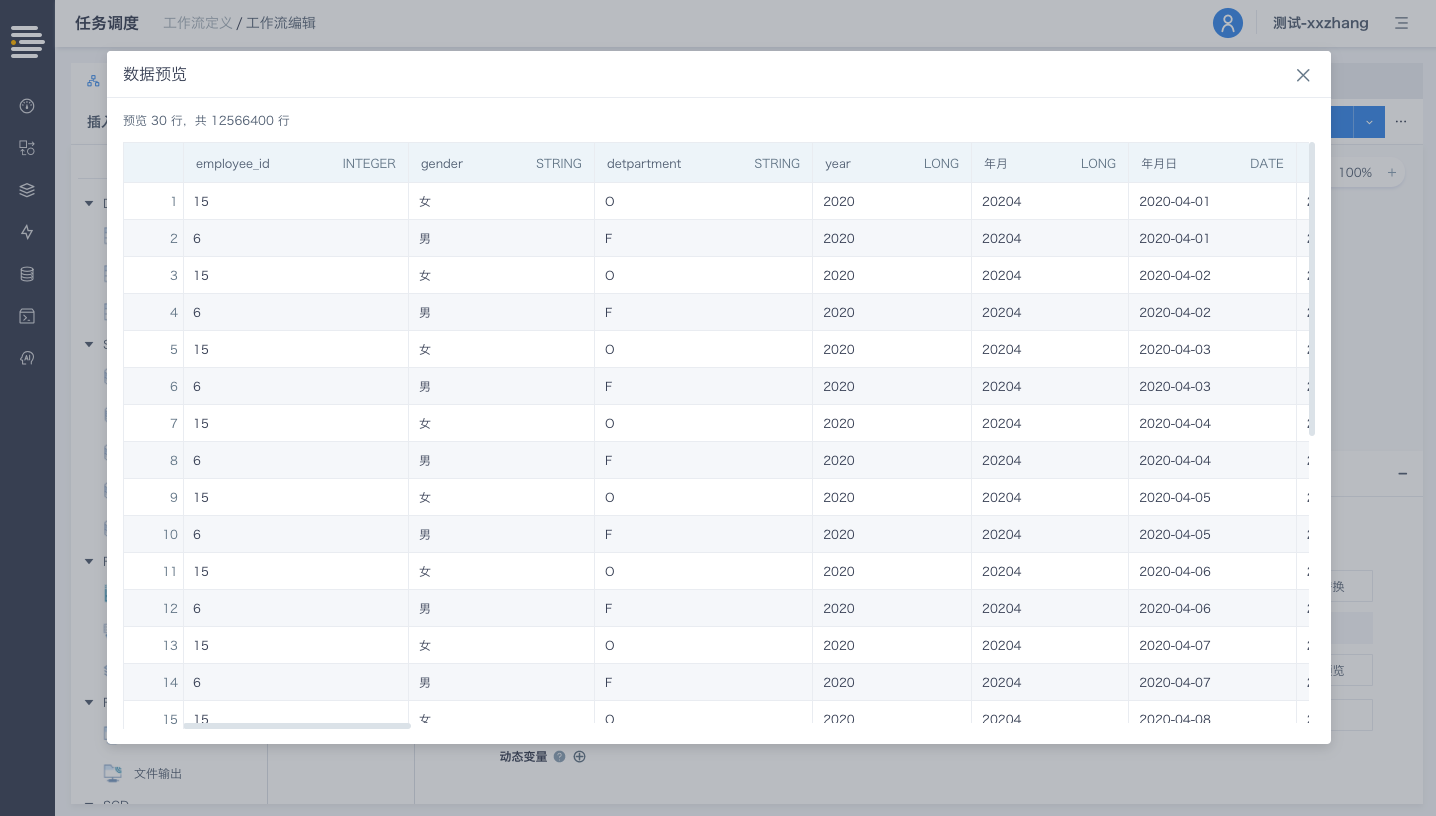
针对筛选条件支持进行数据“预览”(筛选条件无内容则预览全量数据)
数据流依然可通过“筛选数据行”&“SQL输入”算子进行数据筛选及预览。
针对分区表,通过设置筛选条件,工作流/数据流运行时可以直接从数据集中使用分区获取最少量的数据,从而提高运行性能。

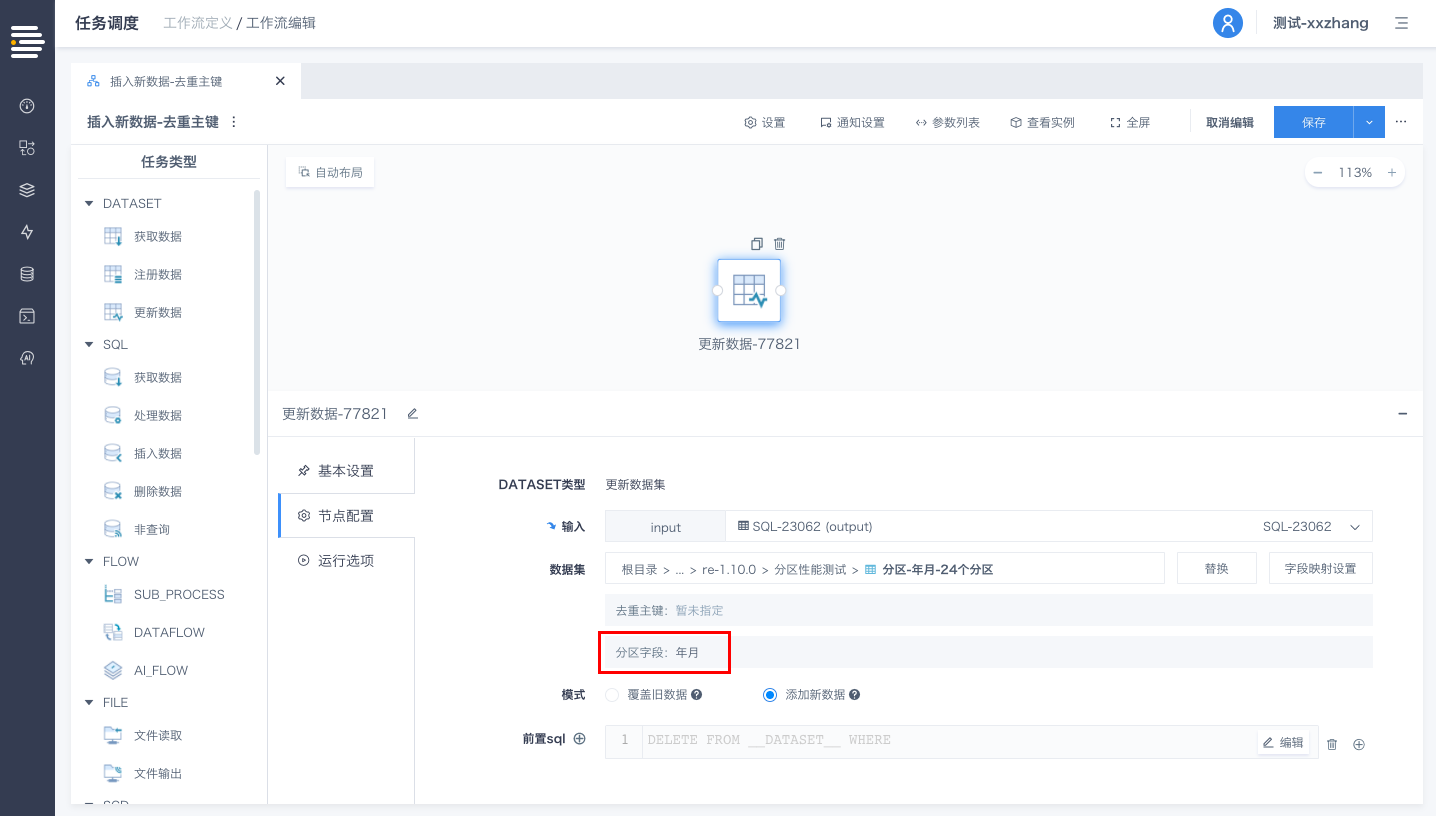
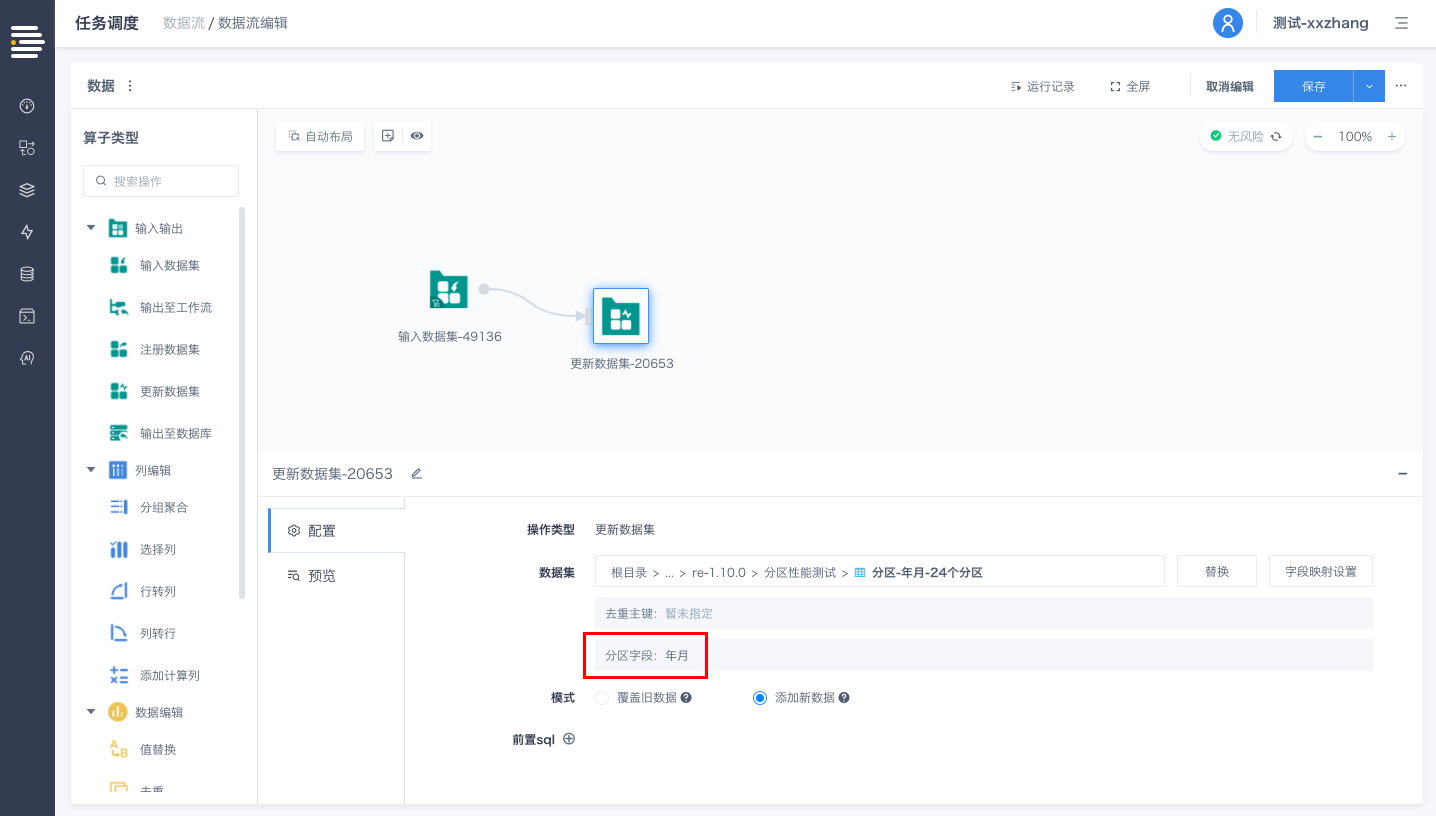
数据写入
工作流中的“DATASET-注册数据”节点以及数据流中的“注册数据集”算子,新增对于分区字段的设置。工作流/数据流运行过程中注册数据集时,会按照设置的分区字段以分区方式进行物理存储。
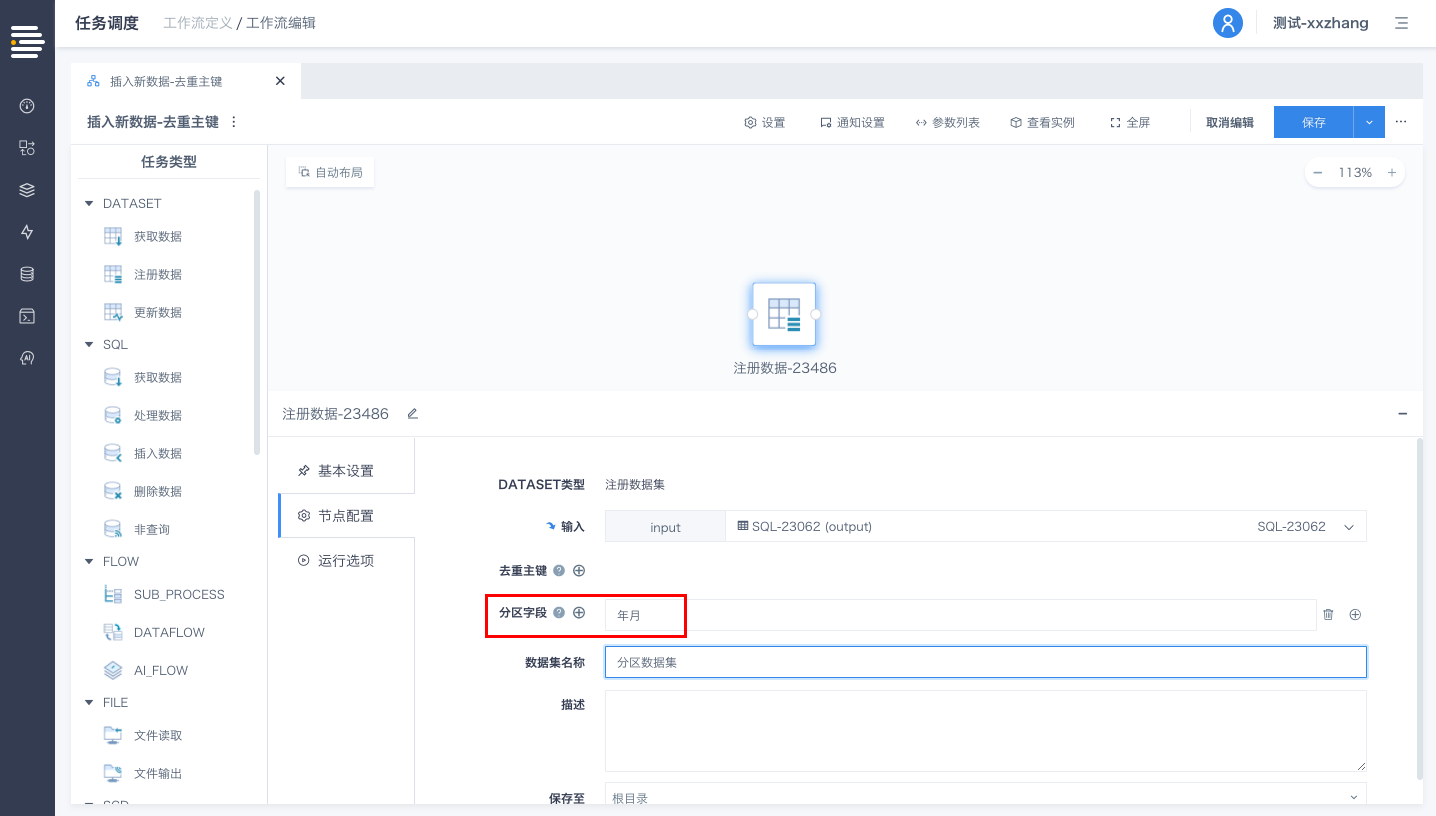
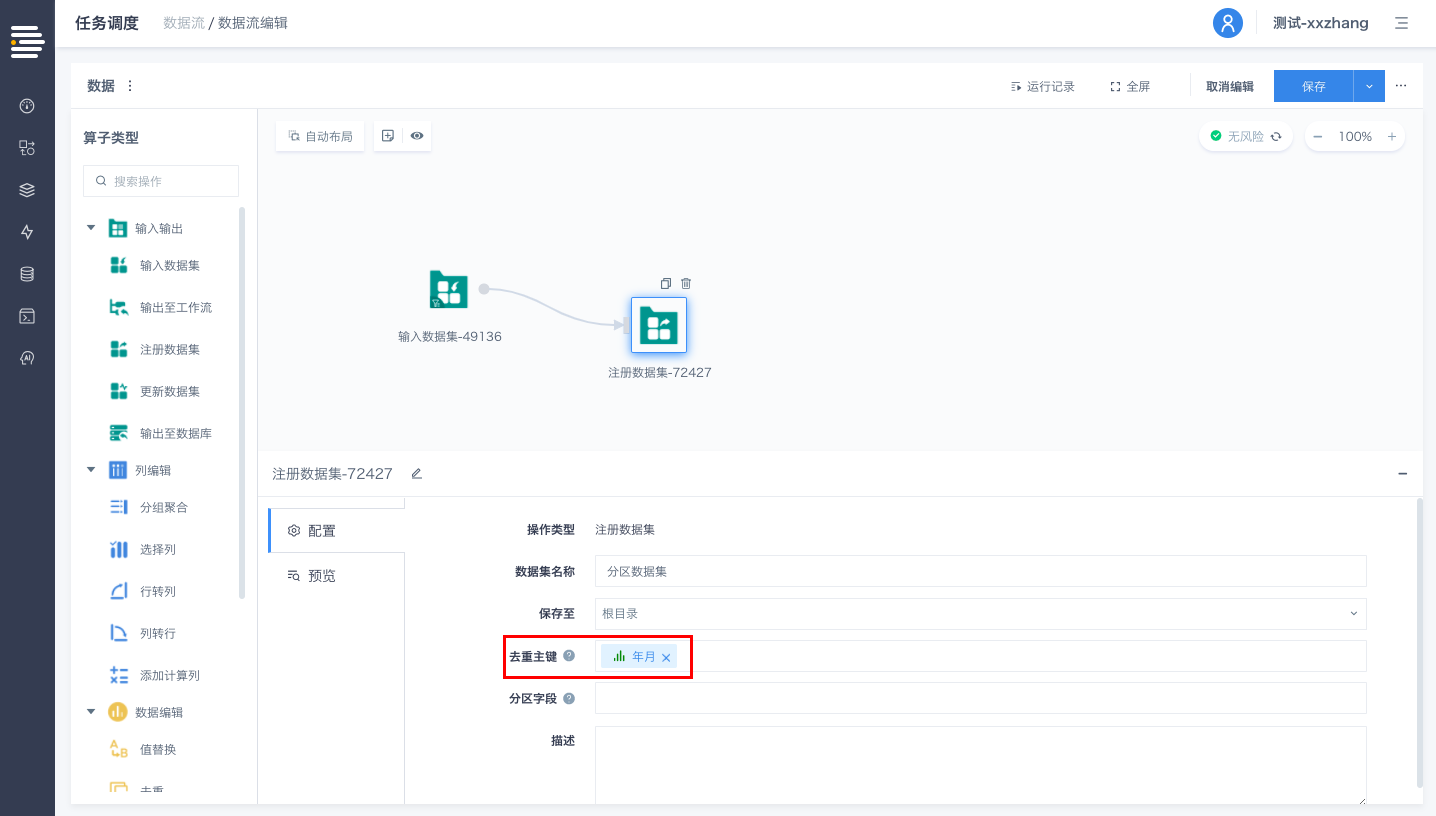
针对分区表,工作流/数据流运行过程中更新数据集时,默认采用“动态分区”模式将数据存储至相应分区内。
数据质量模型支持分级检测及告警
在实际场景中,对一个数据集做质量检测时,通常需要根据各规则的质量检测情况进行不同级别的告警及告警处理。
平台在数据质量模型各规则运行结果中,新增“警告”状态。若规则运行结果为”警告”,则其检测出的问题紧急程度介于通过/不通过状态之间。
分级检测配置方式
字段粒度规则&逻辑检测-条件判断规则
[数据通过率]支持设置红色警告线、黄色警告线(如下图所示)
若数据通过率<红色警告线,则规则运行结果为[不通过];
若红色警告线≤数据通过率<黄色警告线,则规则运行结果为[警告];
若数据通过率≥黄色警告线,则规则运行结果为[通过];
.png)
*业务方可根据需要,自行选择规则的警告等级,至少需要选择红色/黄色警告线中的一个,作为规则运行结果判断的依据。
表粒度规则&逻辑检测-高级判断规则
通过选项:检测数据不通过时,仅标记为警告(如下图所示),来控制规则运行结果
若检测数据通过,则规则运行结果为[通过];
若检测数据不通过,且勾选该选项,则规则运行结果为[警告];
若检测数据不通过,但未勾选该选项,则规则运行结果为[不通过];
.png)
*业务方可根据需要,自行选择检测数据不通过时,是否标记运行结果为[警告]。新增规则时,平台默认不勾选[检测数据不通过时,仅标记为警告]选项。
2.同样地,对数据质量模型新增[警告]类型的运行结果
.png)
数据质量模型运行结果判断逻辑如下:
数据质量模型运行结果 | 判断依据 |
失败 | 模型内存在任一规则运行结果为[失败] |
取消 | 模型取消运行 |
不通过 | 无规则运行结果为[失败] [且] 存在任一规则运行结果为[不通过] |
警告 | 无规则运行结果为[不通过]/[失败] [且] 存在任一规则运行结果为[警告] |
通过 | 所有规则运行结果为[通过] |
3.数据质量模型运行结果通知
支持在数据质量模型运行结果为[警告]时,通过系统预设的通知渠道,对相关人员进行警示。
.png)
4.工作流引用
当数据质量模型被工作流内的QUALITY_MODEL节点引用时,若勾选[异常失败],则当数据质量模型运行结果为[失败]/[取消]/[不通过]时,该节点运行将会失败。
*[警告]、[通过]均不属于异常情况,不会导致工作流失败。
数据集支持添加描述信息
在数仓建设中,往往需要对各层级的数据集进行较为详细的描述,以阐明该数据集的效用,便于后期的协作及运维工作。
入口:数据中心-数据集-详情页面
在8月更新中,对数据集详情界面进行了展示优化,主要功能分布如下。
.png)
在左侧表基本信息位置,支持添加数据集描述信息。
.png)
此外,在工作流/数据流-注册数据集节点,同样支持为待注册的数据集添加描述信息。
添加完成后,描述信息将在平台内引用当前数据集的多处位置进行展示,以适配不同的应用场景。如:
数据集列表页
.png)
选择数据集弹窗页等
.png)
优化工作流&数据流名称及描述修改流程
在新版本中,对工作流&数据流名称及描述信息的修改入口及修改条件进行了优化。
修改入口
工作流/数据流定义列表-操作-编辑(下图以工作流定义为例)
.png)
工作流/数据流定义详情页(下图以工作流定义为例)
.png)
编辑弹窗:
.png)
修改条件
当前工作流定义名称、描述信息的编辑及保存,不依赖于工作流下线,无论工作流处于上线/下线状态,均可编辑并保存工作流名称、描述信息。
数据流定义“分组聚合”算子配置优化
针对数据流定义-分组聚合算子,进行了如下优化:
添加计算字段时,支持设置计算字段类型为“维度”
.png)
当添加的计算字段为“数值”类型时,支持选择数值聚合方式
.png)
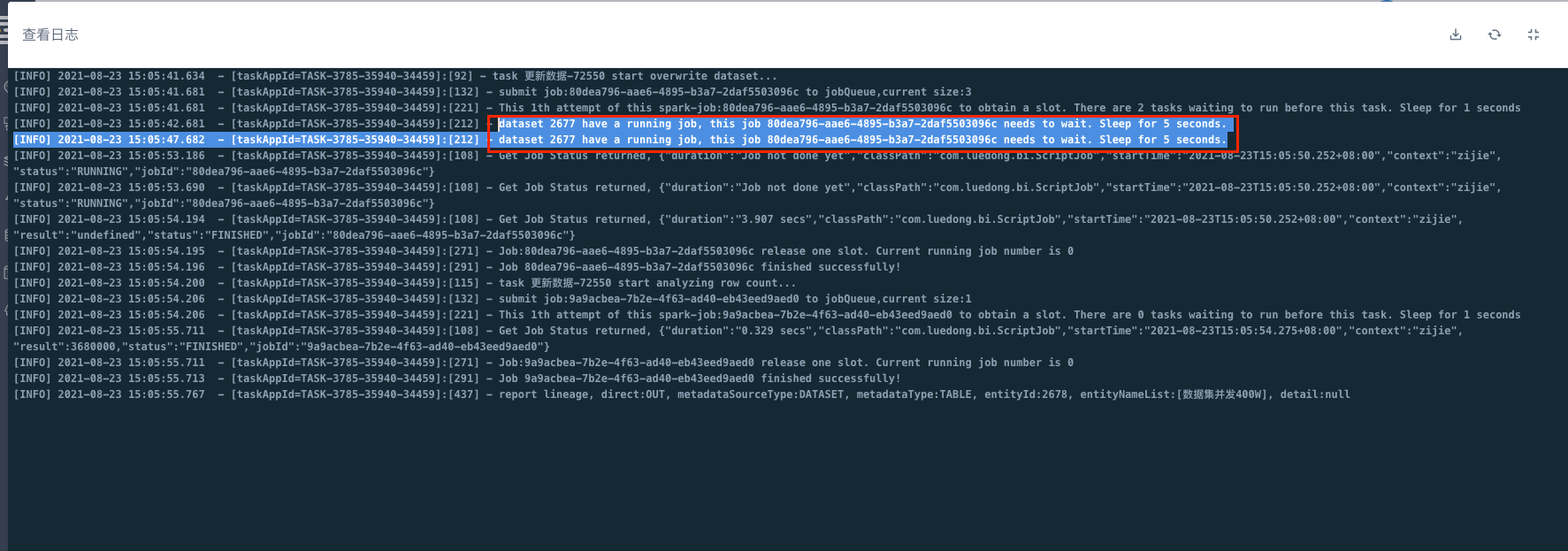
数据集更新操作新增并发排队机制
工作流/数据流运行时针对数据集进行更新操作新增并发排队机制(包括:覆盖旧数据、添加新数据、前置sql中的delete操作)。
对于同一个数据集进行并发更新时,稍后提交的更新任务不会运行失败,而会自动进入排队队列,等排队靠前的任务完成运行后继续运行。
数据库更新操作增加超时限制
为避免出现某些节点运行时间过长而影响后续调度的情况,平台对容易发生超时现象的数据库操作相关节点,增加SQL执行超时限制。
当以下节点SQL执行超过超时设置的时长(默认为2小时),判定为节点运行超时,对应任务被kill:
工作流 | SQL-插入更新数据 |
SQL-非查询 | |
SQL-删除数据 | |
DB数据流 | 输出至数据库-插入数据 |
输出至数据库-插入更新数据 |
*以上节点的主功能及前置、后置SQL,均在超时限制范围内。