ETL数据结果不准确问题汇总
常见问题
-
ETL预览数据和结果数据集不一致,例如ETL中能筛选出数据,但是在结果数据集中又没有;
-
ETL预览数据和输入数据集不一致;
-
ETL得到的数据每次计算出来都不一样;
-
ETL得到的数据错误。
原因
行列权限问题
输入数据集设置有行列权限。5.5以前的版本,ETL预览是按照ETL所有者的行列权限生效的,即ETL访问者预览时可以看到自己权限以外的数据,但是结果数据集里只能看到自己有权限的数据,这样ETL预览数据和结果数据集不一致是正常的。
解决方案:从5.5版本开始,管理员可以从「管理员设置-系统管理-高级设置」里设置『是否允许访问者按ETL所有者权限预览数据集』。

ETL运行滞后
1)ETL运行时间和ETL「最近修改时间」不一致:ETL修改逻辑了,但没有及时运行ETL。
解决方案:修改时用预览数据来验证数据,保存ETL后及时运行ETL。
2)ETL运行时间和输入数据集「最近更新时间」不一致:有多个输入数据集,ETL更新逻辑设置不恰当。
解决方案:建议使用「所有勾选的数据集都更新后才会触发」;如果对数据时效有要求,需要设置「任何一个勾选的数据集更新后都会触发」,那么需要确保多个输入数据集更新时间错开、不要扎堆(时间间隔要大于ETL运行时长,且留出排队的余地),一旦同一个ETL同时出现多个排队任务时,后来的重复的排队任务会被系统自动去重丢弃。
示例:(点击展开)
ETL设置了「任何一个勾选的数据集更新后都会触发」,5个输入数据集更新时间太过接近,导致第一次运行还没结束,新的任务已经开始排队。由于ETL排队任务的去重机制,本该运行5次的ETL只运行了2次,结果数据集输出的并不是最新数据。


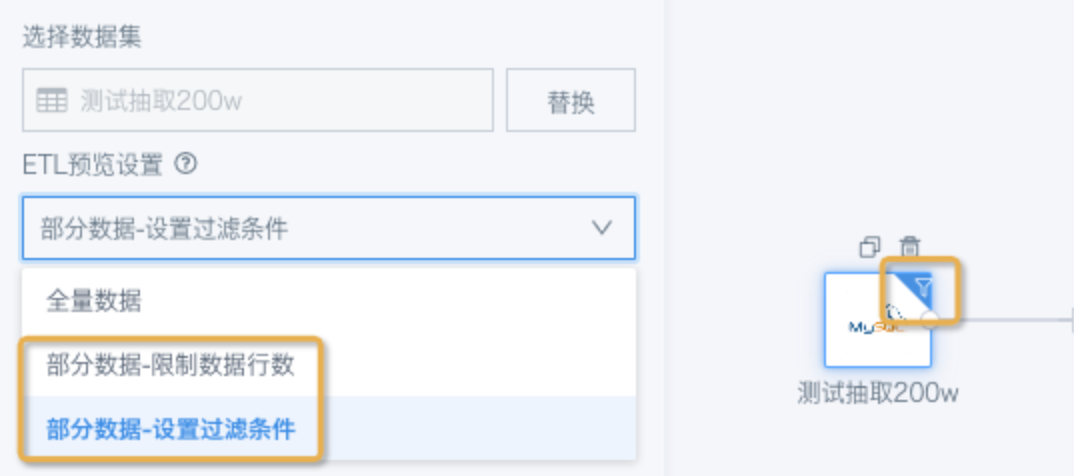
ETL预览过滤
为了提高预览速度,方便验证数据,ETL里支持「预览设置」,仅预览输入数据集的部分数据。该设置不影响结果数据集,但是用户比较容易忘记自己是否设置过,导致误认为数据不准确。
解决方案:检查输入数据集节点右上角是否有漏斗标志,可根据需求修改该设置。
去重计算
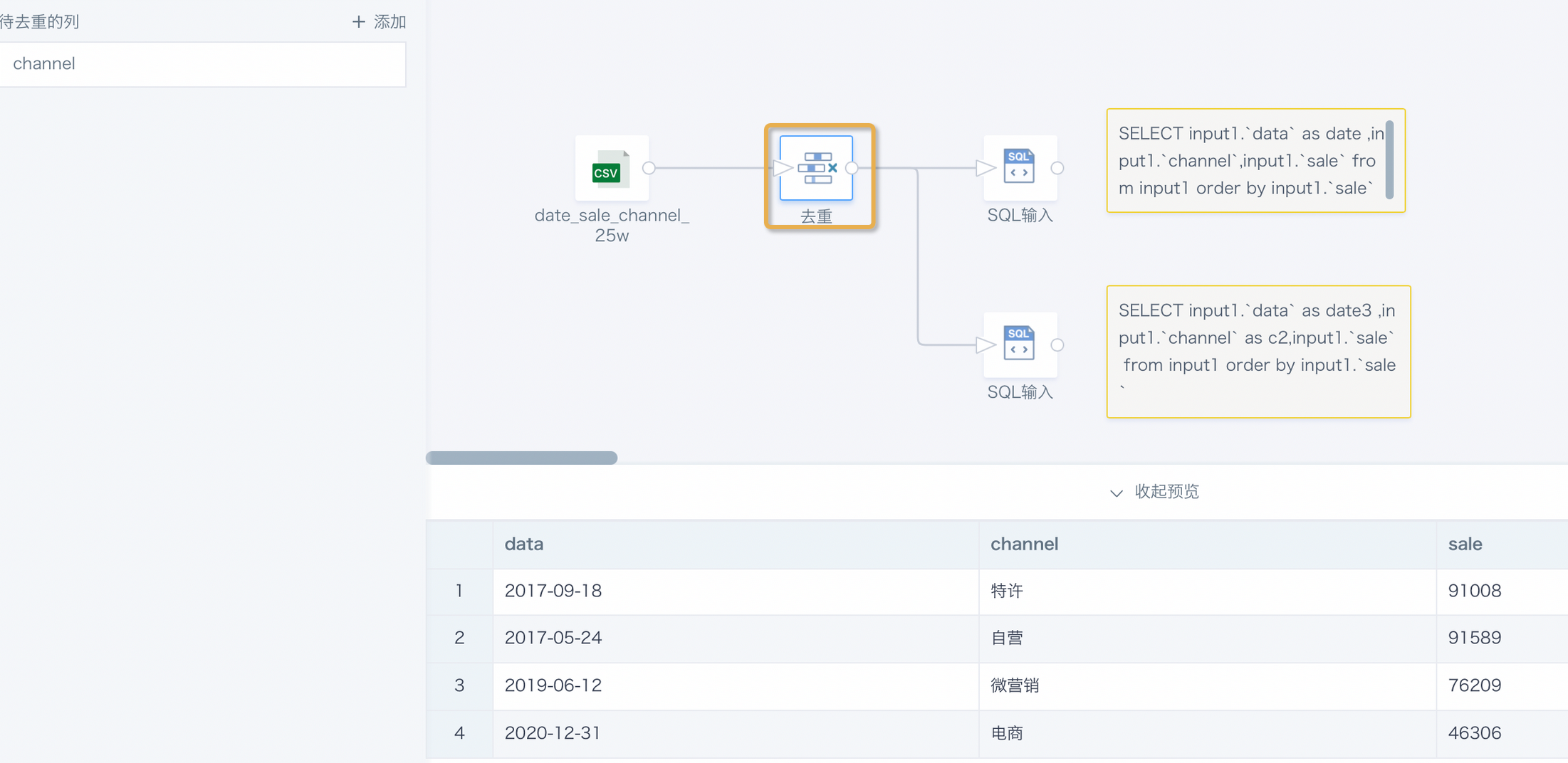
在ETL中使用去重节点,有可能会对输出结果产生随机性影响。去重时,会选择相应的去重主键,对于同一组去重主键,如果存在多行不同的数据,那每次预览或者运行后的数据可能是不同的。
解决方案:选择合适的去重主键,「去重」+「选择列」配合使用;如果需要按照一定逻辑去重,建议新建计算字段对同一组主键下的多行数据进行排序或标记,再使用「筛选数据行」过滤数据。
示例 :(点击展开)
根据`channel`字段去重,三个节点预览出来的数据各不相同。
去重节点预览结果:

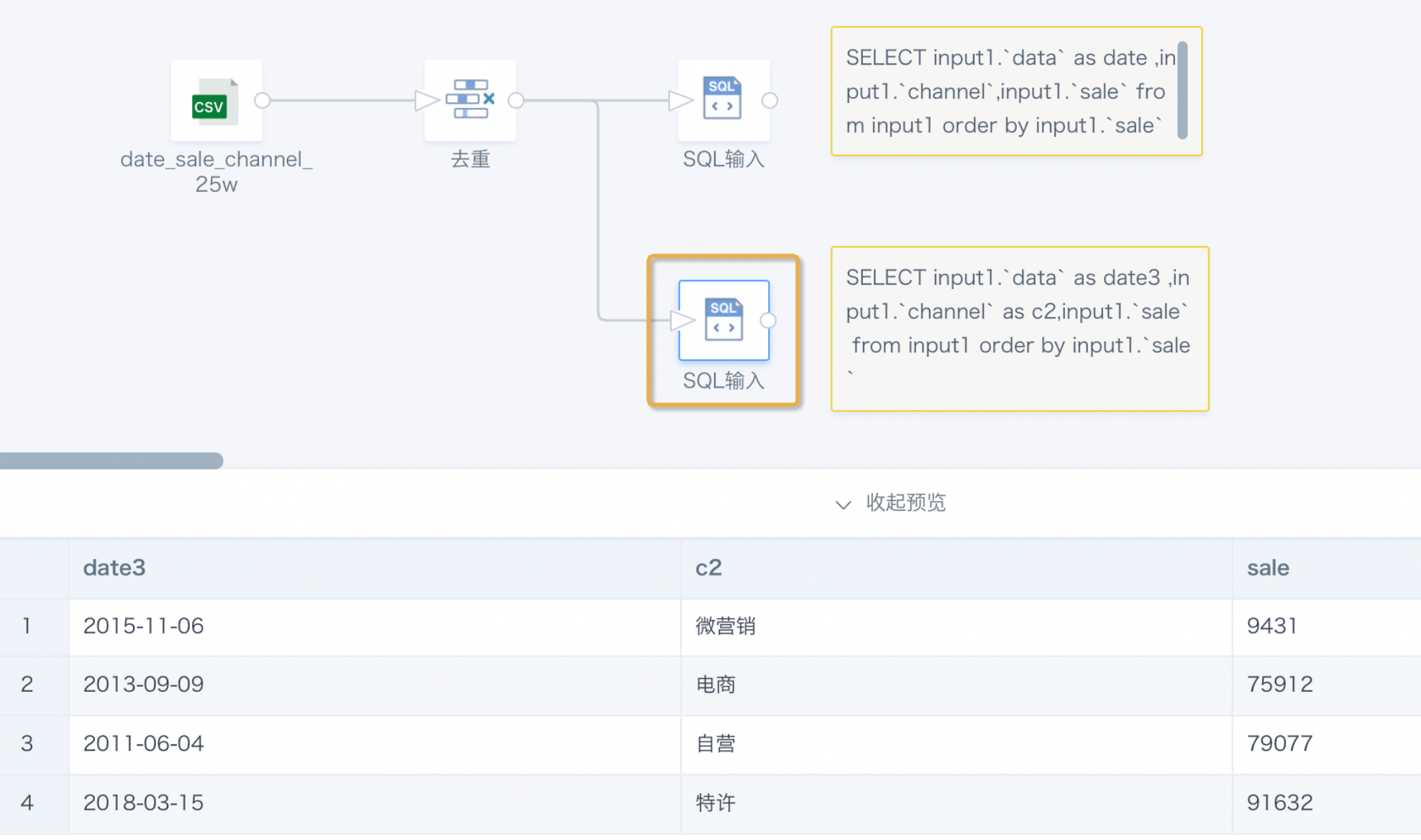
SQL输入(上)预览结果:

SQL输入(下)预览结果:
row_number函数
row_number()主要功能是生成行号,常见的用法为 row_number( ) over(partition by [分组字段] order by [排序字段]) 。如果用row_number对数据进行排名,不支持并列排名的特性会导致,数据相同时排名会具有随机性。
解决方案:使用rank/dense_rank来计算排名。具体使用请参考排序函数及应用 。
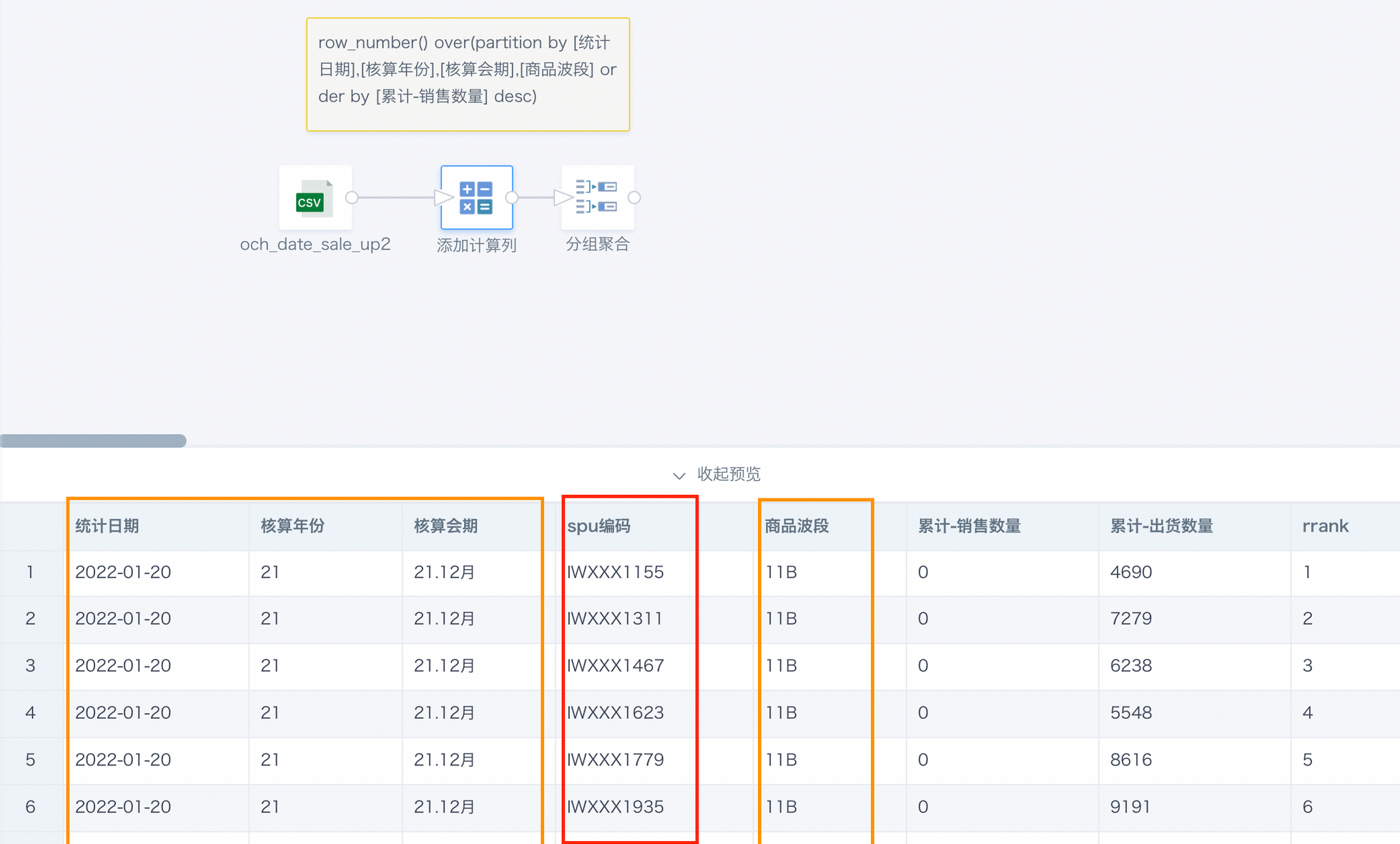
示例 - 计算节点新增对「累积-销售数量」的排序,根据字段“统计日期”、“核算年份”、“核算合同”、“商品波段”作为分区,得到不同商品在同一天内的销售排名。
因为「累积-销售数量」实际上存在重复字段,导致最后在相同的分区里,有着同样销售数量的不同商品,他们的排名先后就有随机性了,每次得到结果可能是不一样的。
时间函数
正常的时间函数,如date、day、month等是不会有随机性的。但是如果客户在计算中使用了now()和current_timestamp(),因该类函数生成的是当前的时间,那在不同时间点运行的结果就和BI服务器的时间有关系。
示例 - 计算当前日期到某个日期的差值 date_diff(now(),[date])
假设用户的服务器时间和中国东8区的时间是一致的,客户在半夜12点前后,得到差值就是不一样的。如果服务器在国外,但是用户在国内,那用户就可能在白天遇到这种问题。
解决方案:服务器在海外,存在时区差的场景,建议用时间函数对日期时间进行时区转换。函数请参考 Spark日期函数。
浮点数筛选
因为对于计算机对浮点数存储和计算都是基于二进制,这导致本身浮点数就存在一定的精度误差。对于浮点数的比较,计算机采取的都是近似比较,所以当浮点数的误差本身已经超过精度范围时,得到比较结果就不准确。详情介绍请参考 浮点数准确性问题。
解决方案:
-
把数据转换成整型(int)来做比较。整型数的比较不存在误差的情况。
-
设置一个你所需要的精度值,来对浮点数做比较:假设浮点数的精度为0.00001,小于-0.00001可以判断这个数是小于0的;同理,判断浮点数等于0,可以设置条件为大于-0.00001且小于0.00001;判断浮点数大于0,可以设置条件为大于0.00001。
-
先通过round(x)取到想要的精度的数,然后再做筛选。一般可以选取round(6),这个和BI的默认显示精度是一样的。
筛选数据行
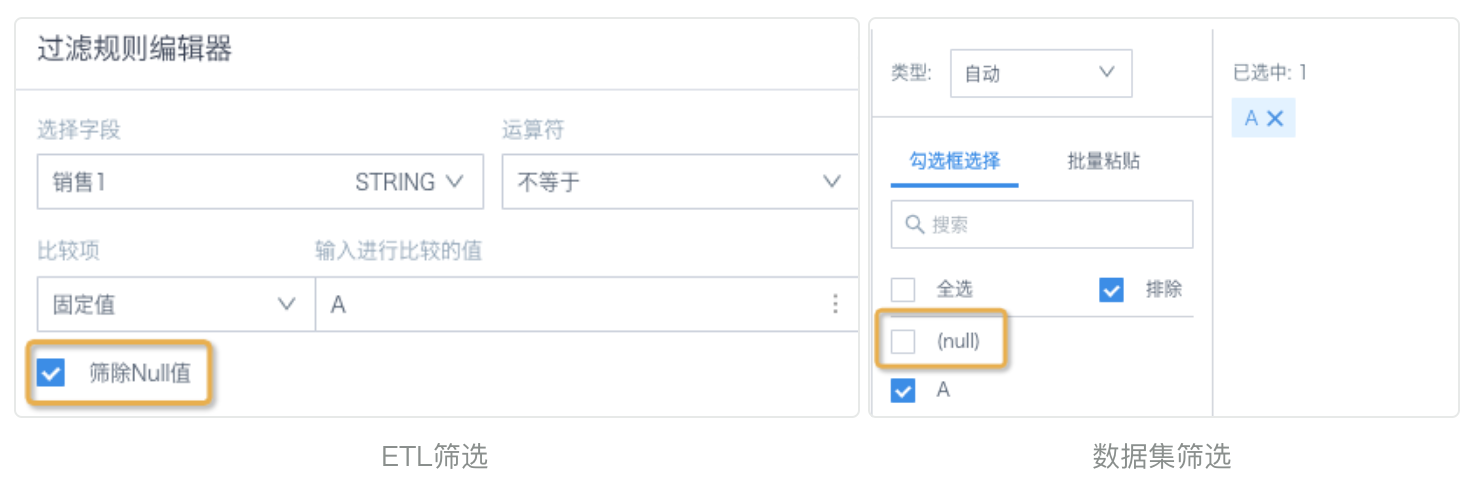
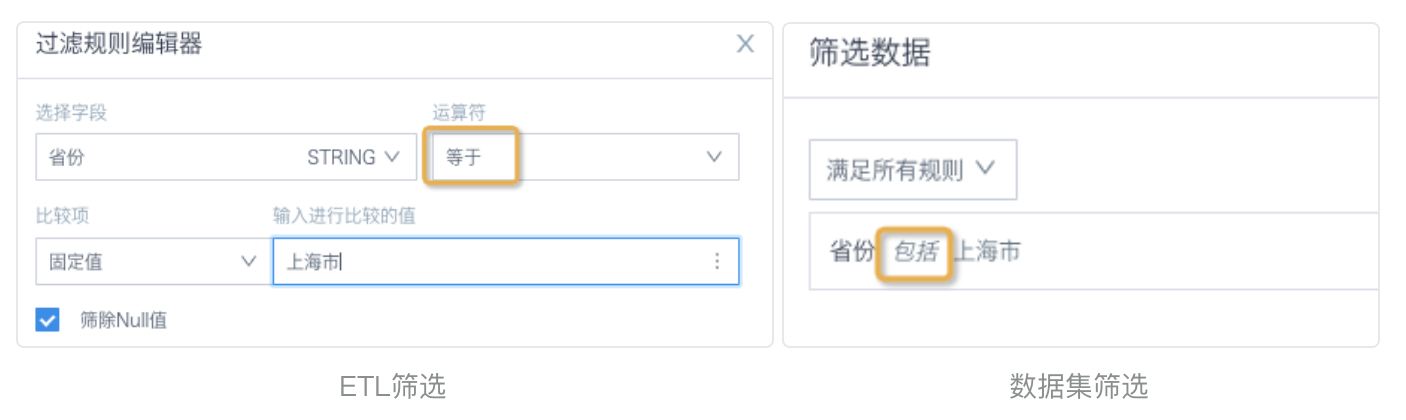
场景1:ETL里「筛选数据行」节点,选择文本类型字段后,运算符默认「等于」;数据集、页面、卡片筛选文本字段,常见做法是:从列表里勾选选项——提交后运算符为「包括」。如果文本字段的值前后存在空格或者其他不可见的符号,两种筛选方式结果就会有差别。
解决方案:ETL里筛选运算符改为「包含」,或者用函数去掉文本前后的空字符(参考函数trim())。
场景2:筛选条件为 「不等于、不包含」等数据时,ETL里默认勾选“筛除Null值”,会自动过滤Null值;数据集和卡片里筛选使用“排除”功能时,Null值不会自动过滤掉。这样导致相同筛选条件下,ETL得到的数据和直接对输入数据集筛选得到的数据不一致。
解决方案:ETL里考虑好是否需要筛除Null值,理清逻辑。