数据回写至数据库
温馨提示:此产品模块为增值模块,如需试用体验请联系观远数据商务人员或客户成功经理(通常是贵公司当前的服务交流负责人)。
概述
该功能允许用户将 BI 平台中计算处理与分析后的数据集通过在线化的配置方式写入到用户业务系统或底层数据仓库中,帮助用户闭环后续的业务营销以及数据共享场景,并提供在线化的运维管理能力。相比于 Public API 数据对接方式,数据回写降低了回写场景的开发和管理门槛,大规模数据回写上的性能优势更加明显。
应用场景
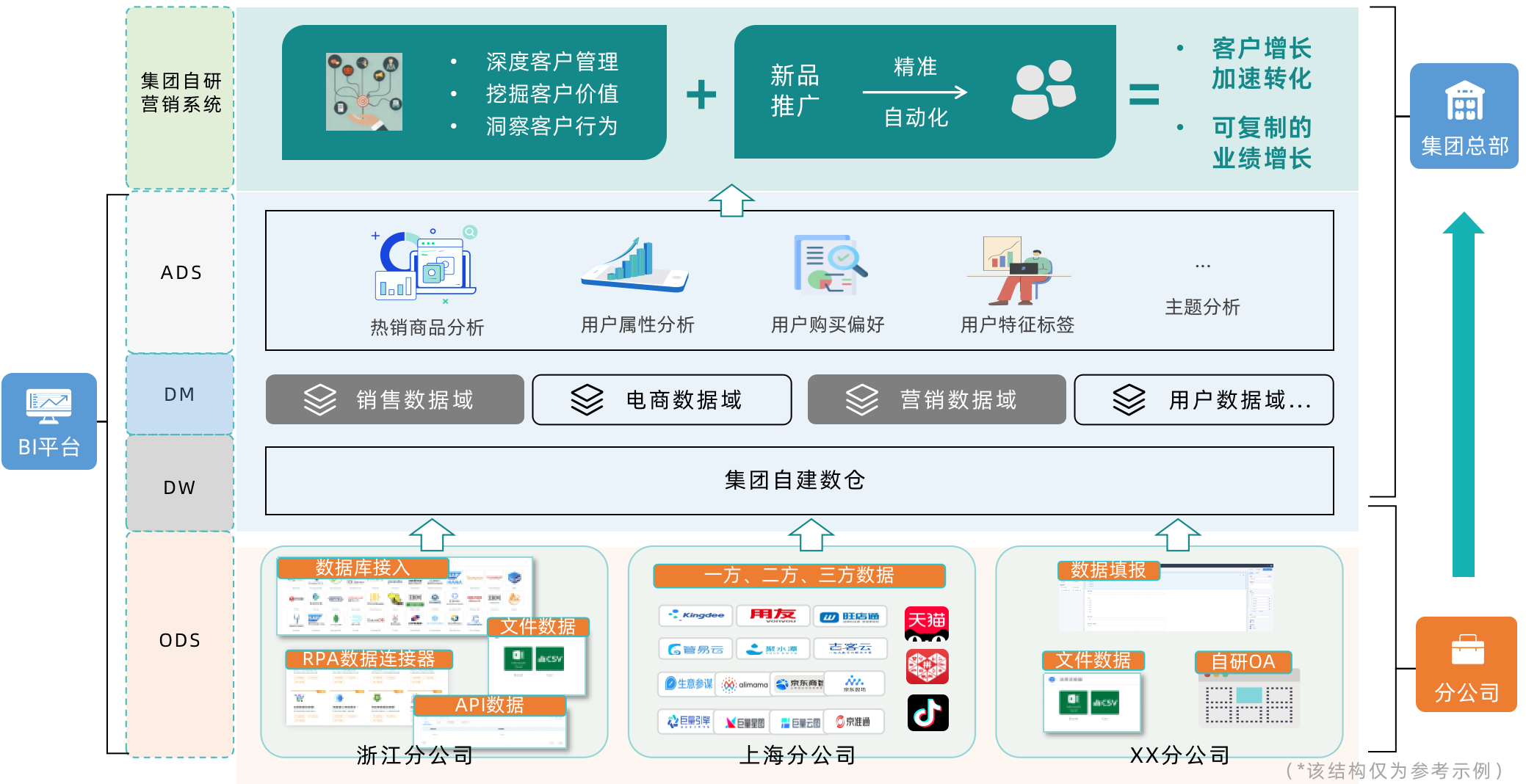
用户精准营销
在 BI 上做了人群画像分析,营销团队进行新品推广期间,希望可以发送相关信息到目标的客群。通过数据回写能力,将目标人群的用户属性分析数据、购买偏好结果、用户特征标签等数据自动回流到营销系统数据库,并在营销系统配置新品推广计划,定向推送给目标人群,完成从营销到转化的业绩加速增长过程。
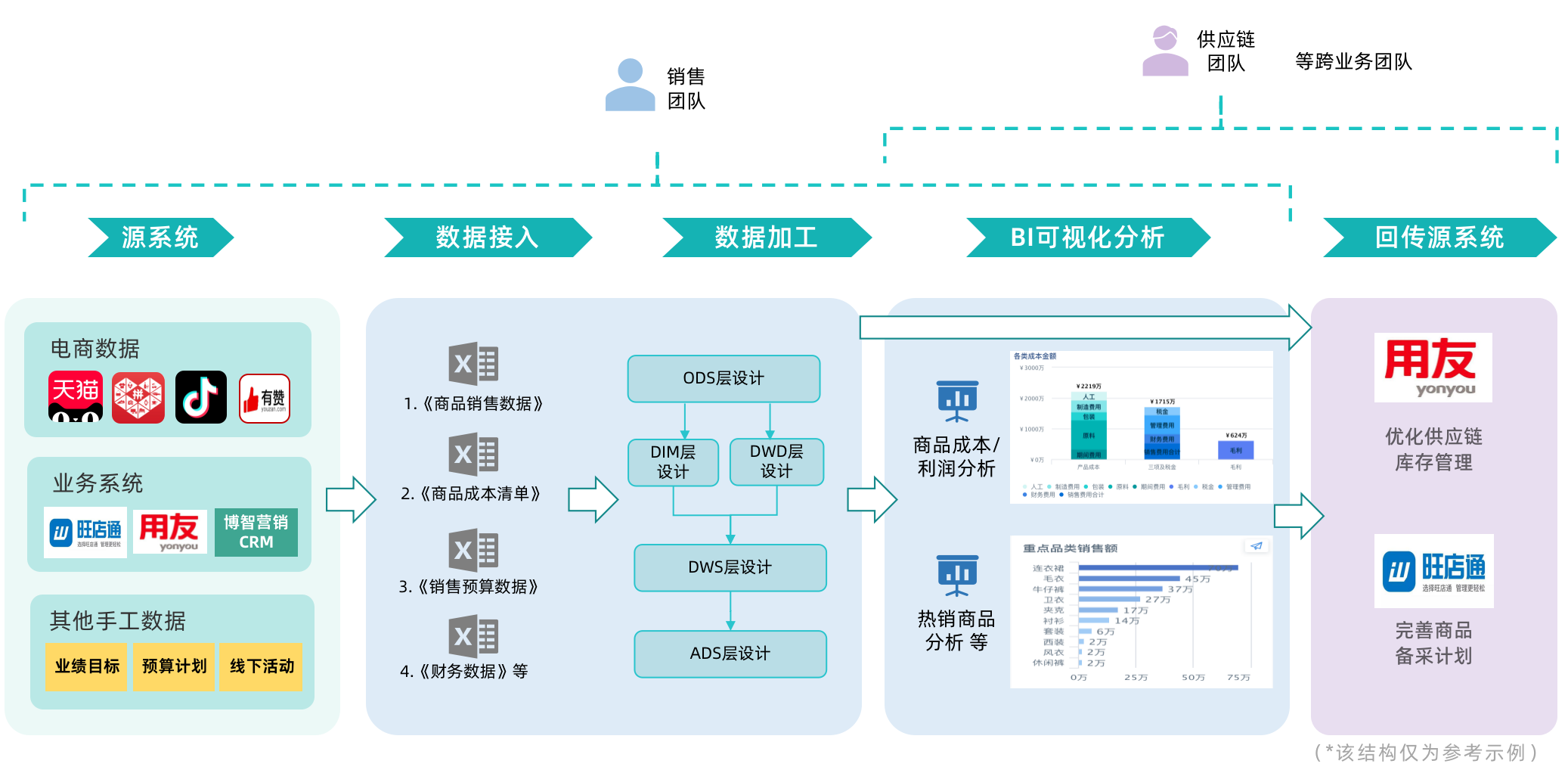
ERP/供应链需求规划
在 BI 上完成了热销商品的销售分析,并将对应分析结果数据回传到 ERP 或供应链系统中,为后续的商品采购计划提供数据支撑,减少库存积压,提高资金利用率。
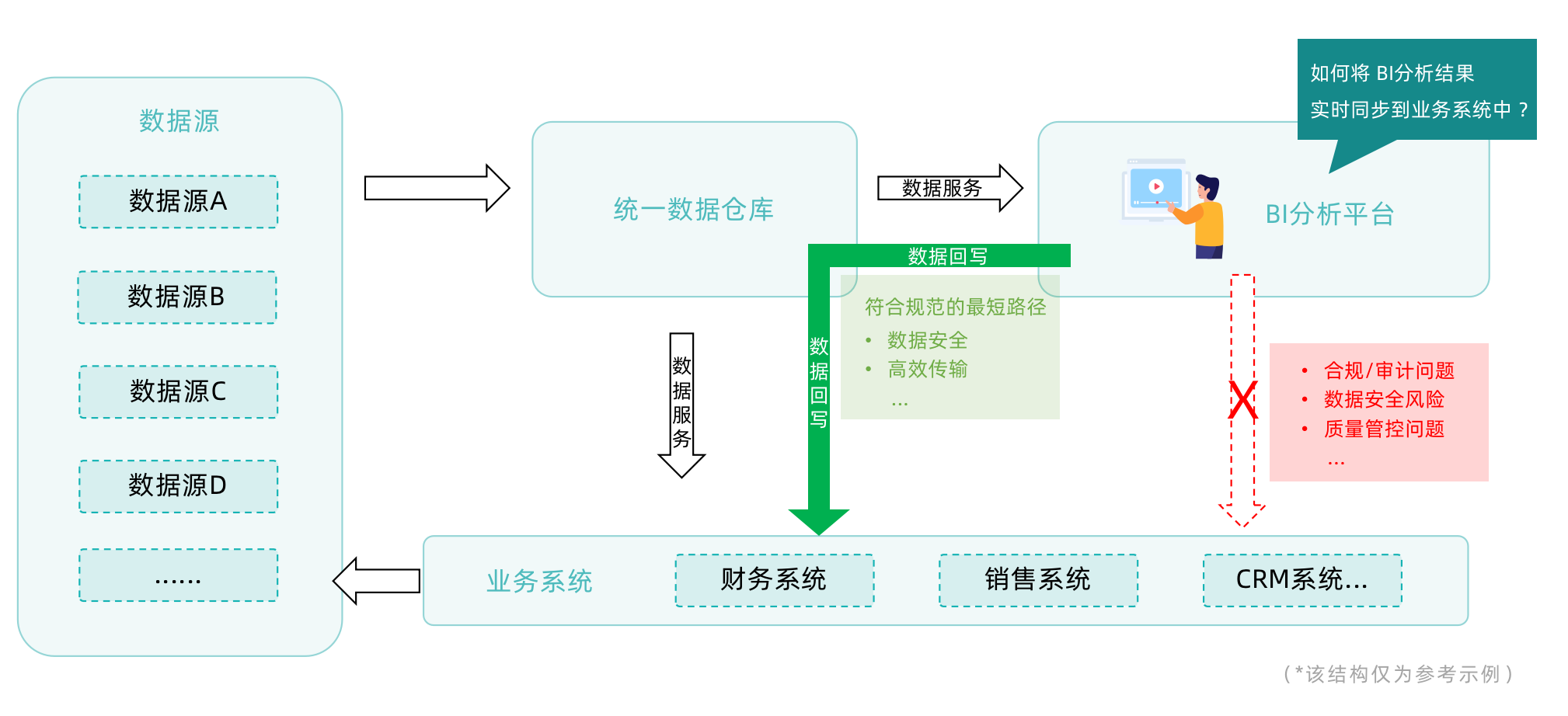
企业数仓 - 数据服务场景
企业级数仓架构中有严格的数据使用规范,BI 中的数据是无法直接开放给其他业务系统直接调用的,通过数据回写就可以将 BI 中的分析结果回流到统一数据仓库,通过数据仓库再反哺其他业务应用中去。
产品价值
更低的拥有成本:
过去,许多企业为了完成数据同步的任务,往往选择使用独立的产品应用。虽然这些应用能够满足数据同步的需求,但却需要企业购买昂贵的软件服务,并配置高性能的服务器,这无疑增加了企业的采购成本和部署负担。而现在,数据回写能力集成于观远 BI 平台中,用户只需购买相应的功能模块并进行 2GB 内存的容量升级,便能低成本实现数据同步的需求。
更低的开发及运维门槛:
除独立产品应用外,部分企业也会通过 API 对接来进行数据同步工作,但 API 对接的方式存在开发门槛高、运维难等弊端。API 对接需要开发人员编写专用接口代码,并维护复杂的接口文档,这些都增加了数据同步工作的难度和成本,同时给企业带来了更多的人力支出。 而观远 BI 提供的数据回写功能,却能让用户在线就能轻松完成数据同步的开发配置工作,并且后续在数据中心就能对回写任务进行集中管控,这样一来,即便是没有代码基础的业务人员,也能承担起数据同步任务开发和维护的工作,这大大降低了数据同步的开发运维门槛,为用户提高工作效率的同时,也为企业节约了用工成本。
更大的数据传输规模:
在传统的 API 接口方案中,出于安全考虑单次数据传输往往受到数据条数的限制,这对于有大量数据传输需求的用户带来了更大的挑战。而观远 BI 提供的回写模块支持最高 2 亿条起步的数据传输规模,这一特性满足了用户对同步大规模数据的紧迫需求,显著提升了整体数据传输的效率以及安全性。
使用说明
任务创建
功能入口
数据准备 > 数据回写 > 新建数据回写
任务编辑
-
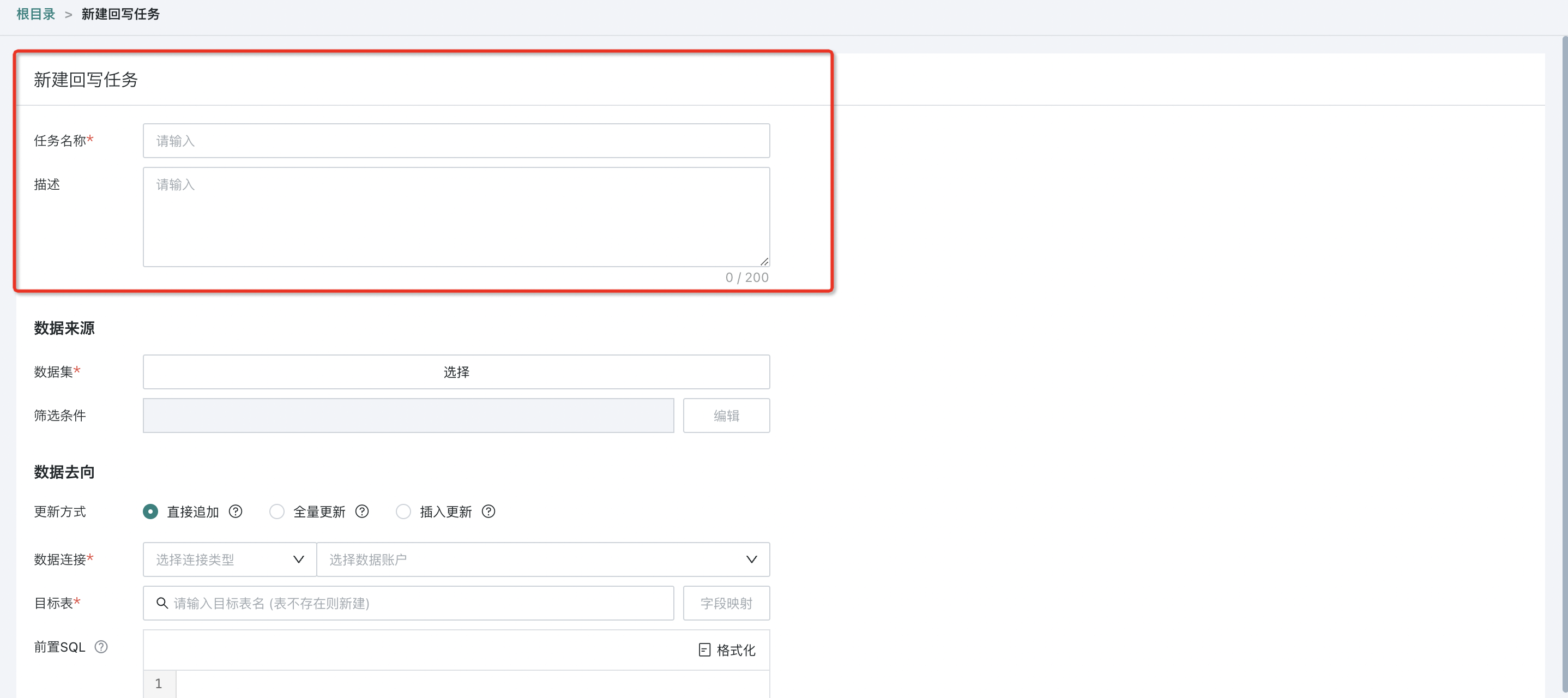
填写基本信息:自定义回写任务名称(必填)、及描述信息(非必填)。
-
配置数据来源:选择需写入业务系统或数据仓库的数据源,并配置筛选条件。

-
数据集:包括回写场景使用到的当前用户权限范围内的 ETL 结果集、卡片数据集、填报数据集等。
-
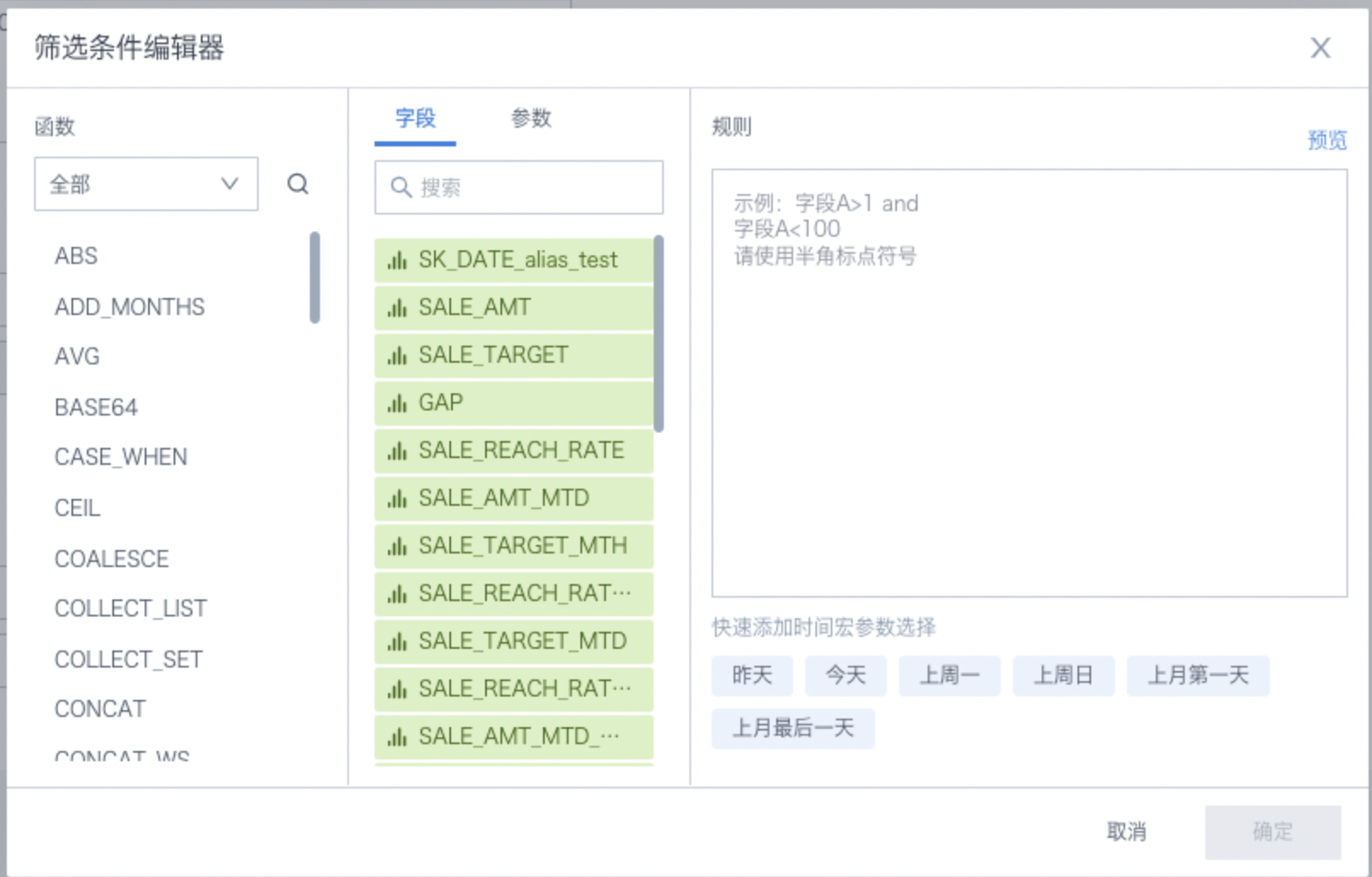
筛选条件:支持使用时间宏、全局参数来定义来源数据集的筛选条件,例如一个周期性的回写任务配置中可以使用时间宏参数筛选前一天的增量数据回写到目标数据库中。筛选条件的配置逻辑和绘制图表时的数据筛选基本一致,可参考学习 数据筛选。
-
-
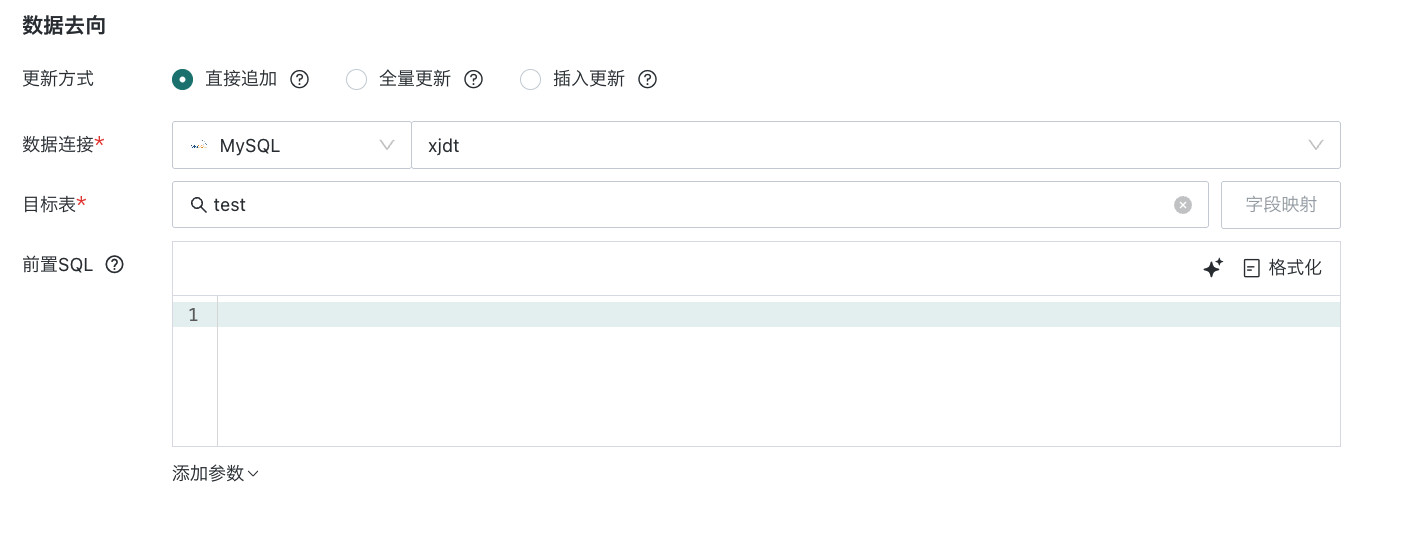
配置数据去向:指定写入的目标对象,一般为客户业务系统或数据仓库(需指定到具体的数据库与数据表)。
-
更新方式
- 直接追加:保留目标表已有数据直接进行写入新数据。
- 全量更新:清空目标表历史数据后进行写入新数据。
- 插入更新:按照比对字段设置,若在目标表内匹配成功,将执行更新数据,否则直接追加数据。
说明- 追加和全量更新,如果没有表的话会默认建表,因此没有表的情况下,需要用户有创建表的权限;表存在的情况下,除 max compute 和 hive 外不需要有建表权限。
- 插入更新场景必须有建表权限的。
- 插入更新每次会根据当前的时间戳创建临时表,然后去执行插入更新的动作。
-
数据连接
当前支持的目标数据库:MySQL、Oracle、SQLServer、Hive、Maxcompute,ClickHouse、PostgreSQL、Greenplum、Gbase、GaussDB、Impala、TiDB、StarRocks、行云数据库、Doris、SelectDB、LakeHouse、DAMENG、HANA。当「更新方式」选择为「全量更新」时,数据连接支持选择「飞书电子表格」。
其中,数据回写 Hive 作为目标源时候支持文件方式的高速导入模式。新建或编辑数据回写任务时选择 HIVE 类型的连接后,支持开启「高速导入模式」,开启后,需要上传 HDFS 连接所需的 core-site.xml 和 hdfs-site.xml 两个配置文件用于临时文件向 HDFS 的缓存。
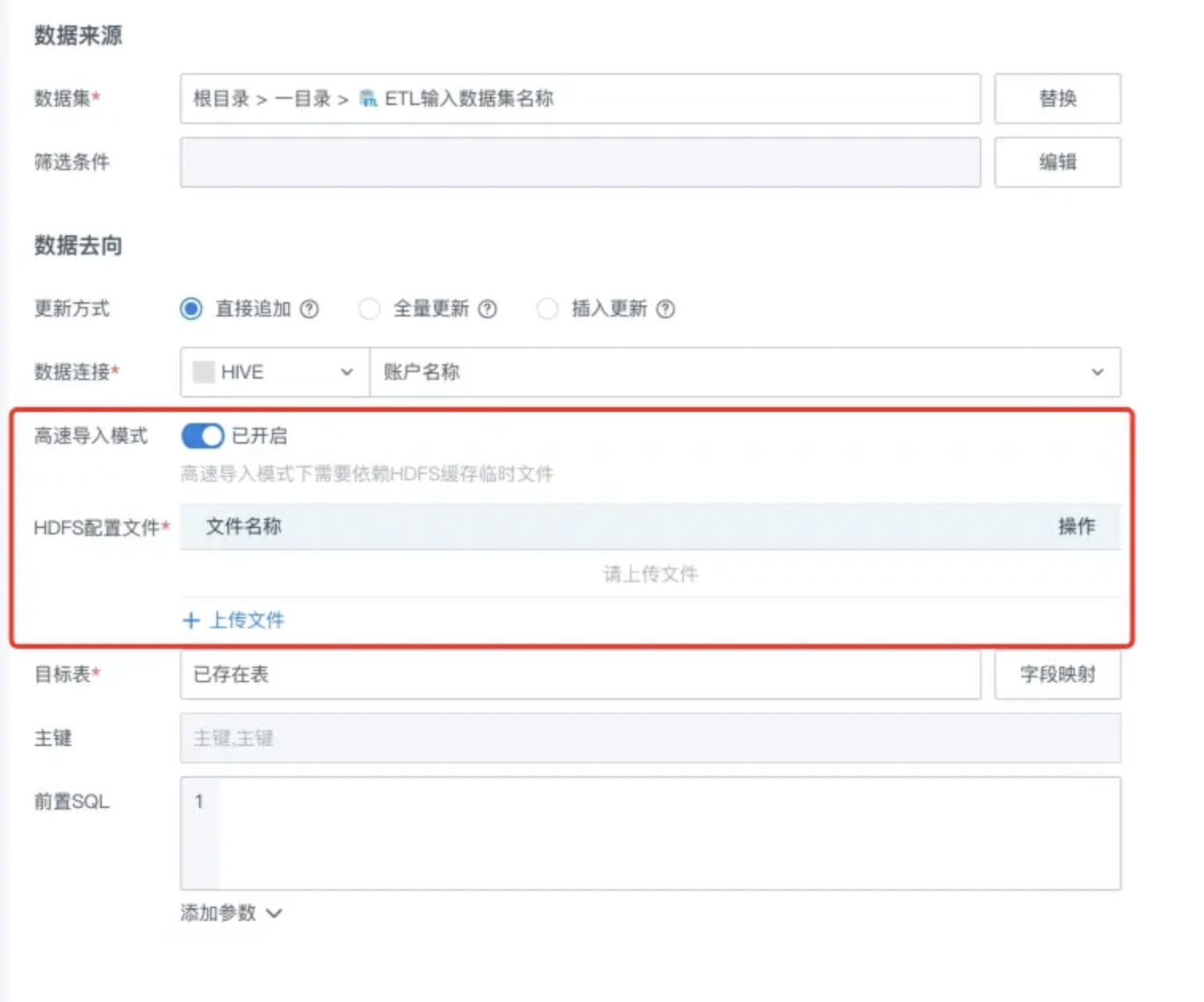
-
目标表
支持选择已有表及新建表两种方式,新建表数据结构与待回写数据集结构保持一致。
对于目标表已经存在的情形,需设置数据集与目标表的字段映射关系,未设置映射关系的目标表字段新数据写入为空。目标表字段既可以同步来源表的数据,也可以同步用户自定义的常量,以及回写任务参数。
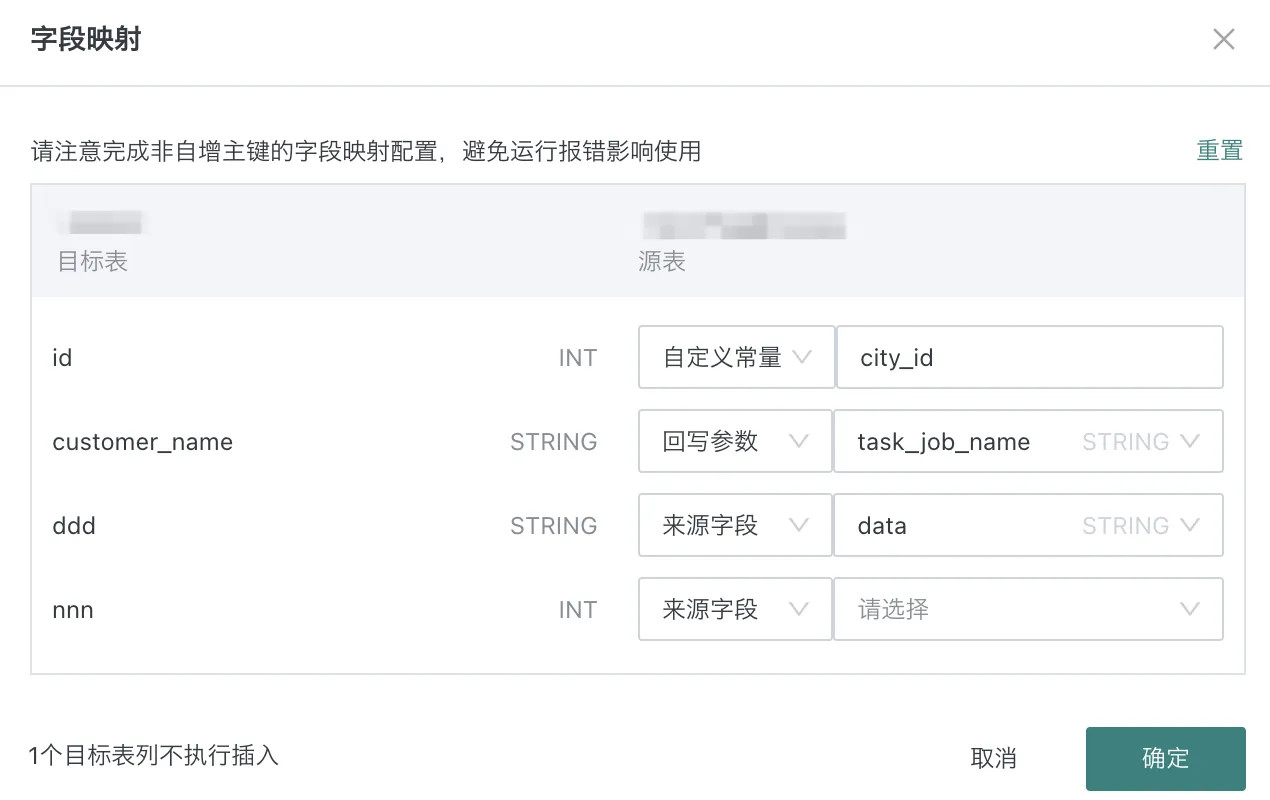
回写参数可使用:
- start_time,回写任务实例运行开始时间;
- task_job_name,回写任务名称;
- task_id,回写任务实例 id
-
前置 SQL
-
在目标表数据写入前先执行前置 SQL,对目标表历史数据进行删除等操作:
-
支持快捷添加并使用全局参数&时间宏,通过全局参数&时间宏动态进行数据删除;
-
典型场景:回写目标表仅保留最近 30 天的数据,每次写入数据前,需要删除 30 天前的数据: DELETE FROM table_name WHERE "date" <= "{{{today-30days}}}";
-
使用限制:
- 仅支持对目标表执行 DELETE、TRUNCATE 语句;
- 不支持 DROP TABLE、DROP DATABASE 语句。
-
-
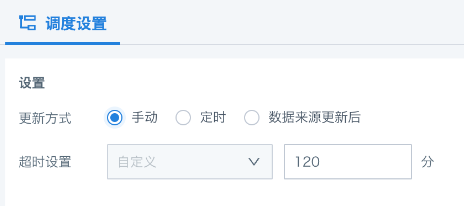
调度策略配置
回写任务创建完成后,可进入回写任务的详情页,通过「调度配置」来进行执行策略配置,包含手动、定时、数据来源更新后三种更新方式。
-
手动:非自动调度策略,依赖人为触发。
-
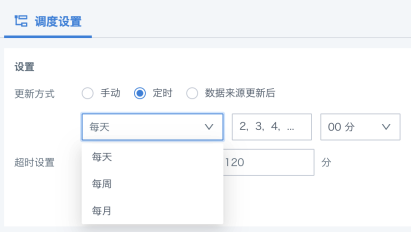
定时:按照每天/每周/每月配置定时策略,系统将在用户指定的时间点,自动运行回写任务。
-
数据来源更新后:回写任务依赖的上游数据集更新后将自动运行回写任务。
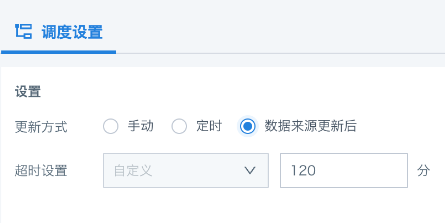
其次还支持任务超时设置,防止任务异常导致系统资源的非正常占用情况,默认为 120 分钟(可设置的时间区间:1~300 分钟)。
任务管理及运维
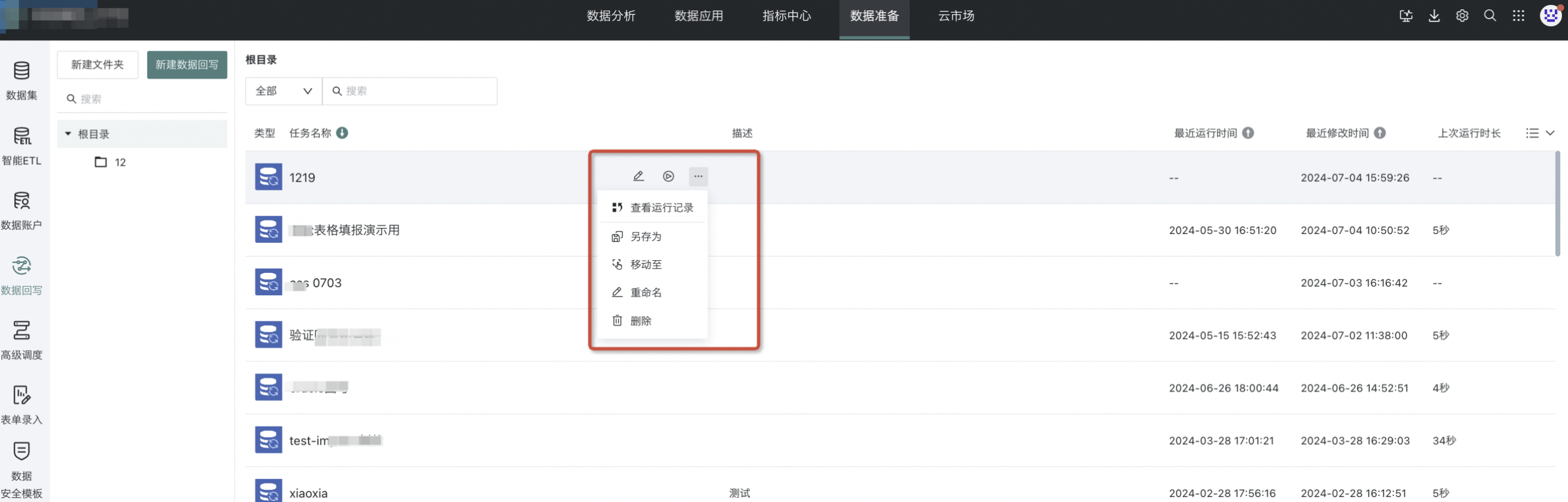
支持对数据回写任务进行管理,包括查看运行记录、修改任务配置、所有者转移、访问者授权、配置通知告警等一系列操作。
-
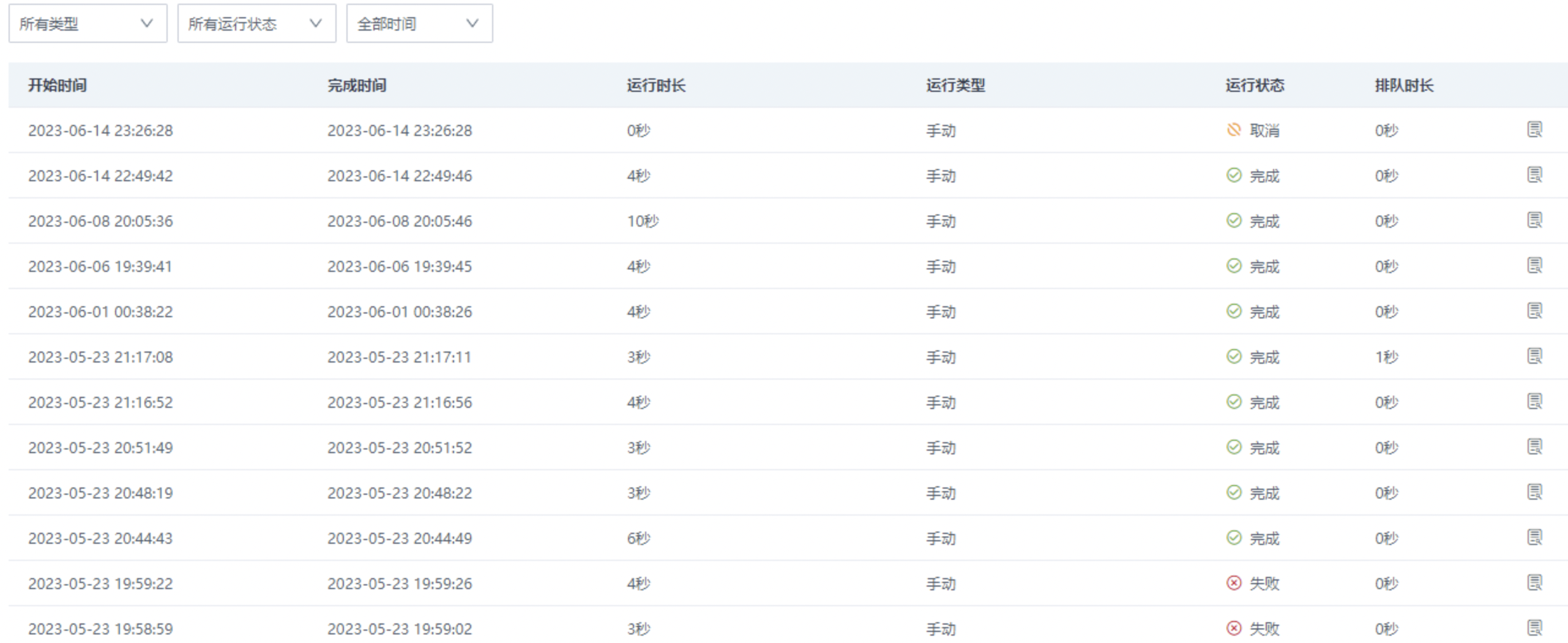
查看运行记录:提供当前数据回写任务的运行状态与历史执行情况。
-
任务的运行状态包括:完成、失败、取消(指运行中被用户手动停止的回写任务)。
-
任务的每一次运行情况均可溯源,包括运行时长、调度类型、排队时长、运行日志 OKLlog 等,其中运行日志支持在线查看与下载分析。
-
-
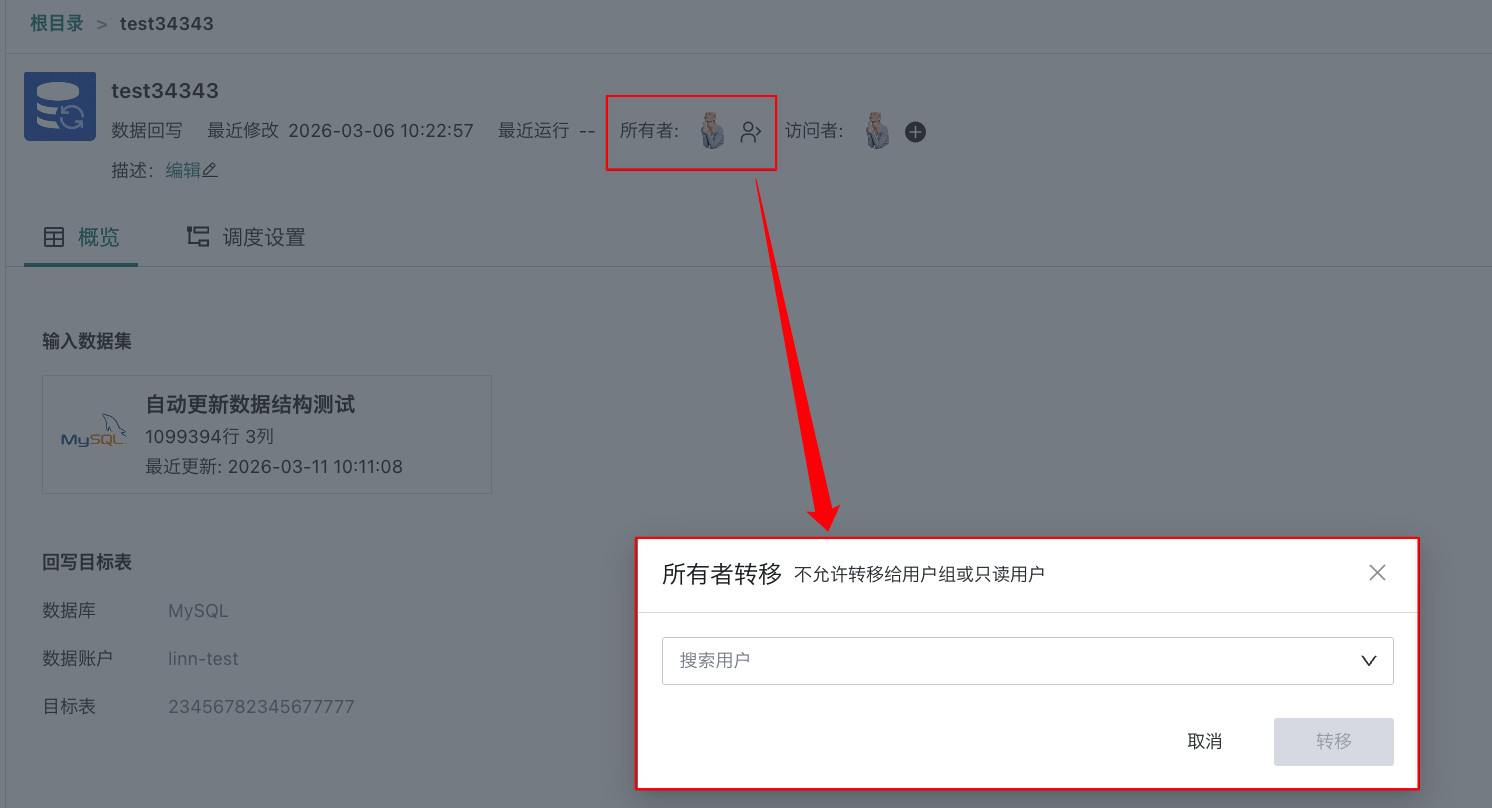
所有者转移:将该回写任务作为资源实体全权转移给另一位用户。
 说明
说明不允许转移给用户组或只读用户。
-
访问者授权:将该回写任务的管控权分配给用户或用户组。
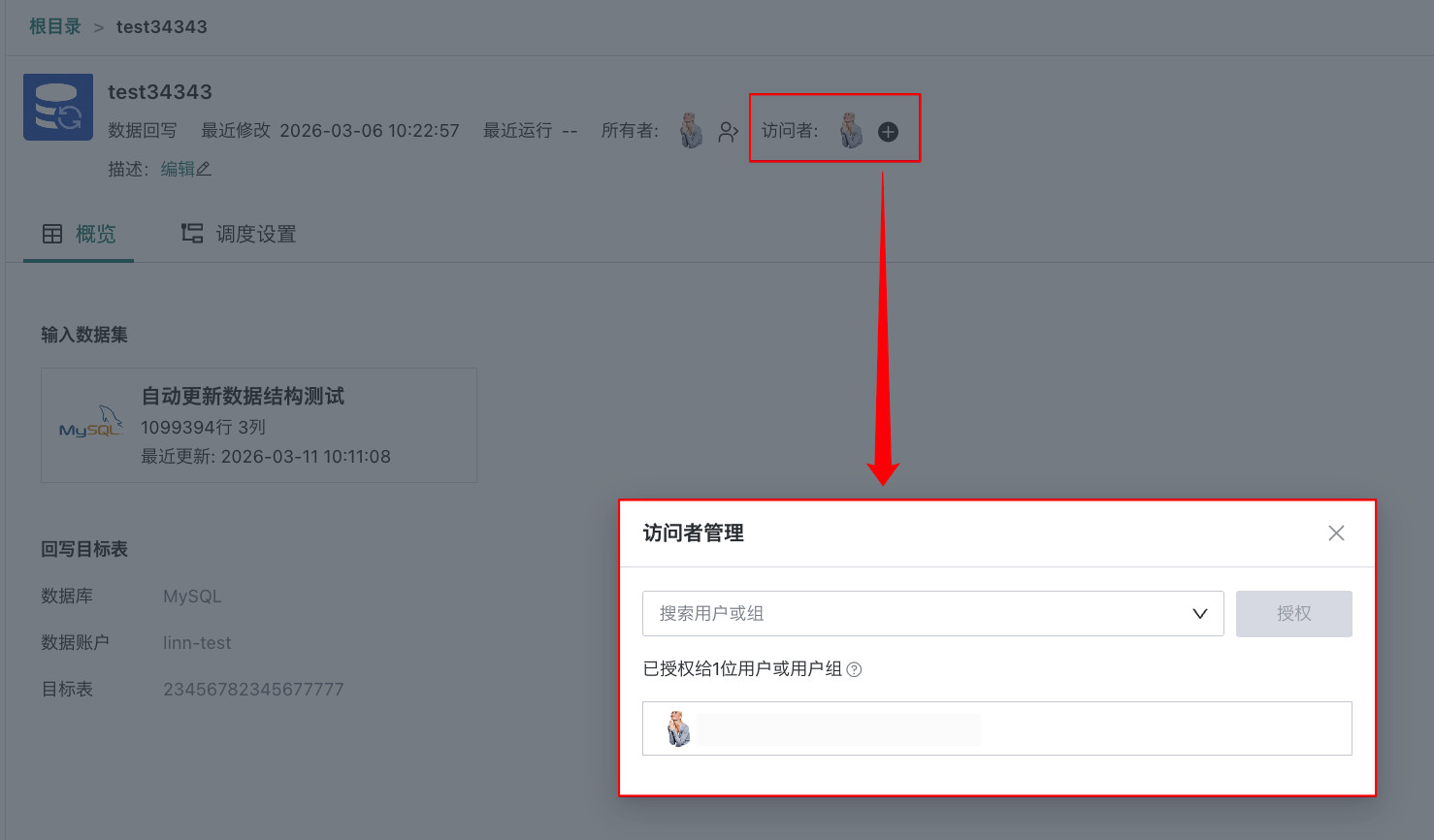 说明
说明若分配到只读用户,该只读用户仅可查看该数据回写任务(仅享有回写任务的只读权限)。
-
删除回写任务:删除后任务不可恢复,操作不可逆。
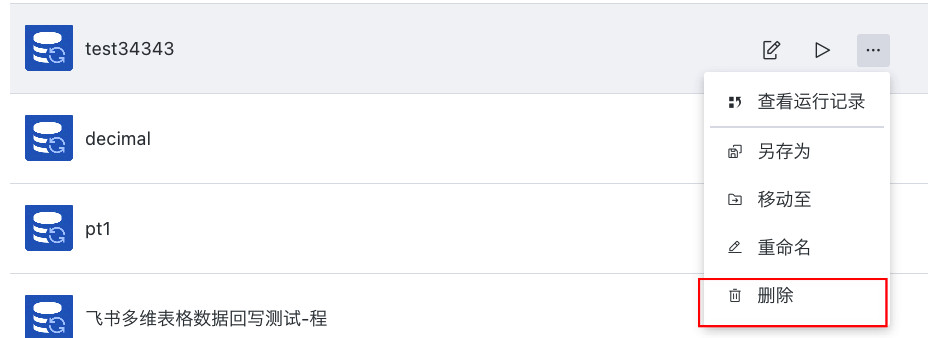
-
修改任务配置:支持对「创建回写任务」的窗口配置进行重编辑。
 说明
说明若更改「数据来源」或「数据去向」中的任意配置项,请重新检查目标数据表中的「字段映射关系」,否则可能存在数据写入错误的潜在风险。
-
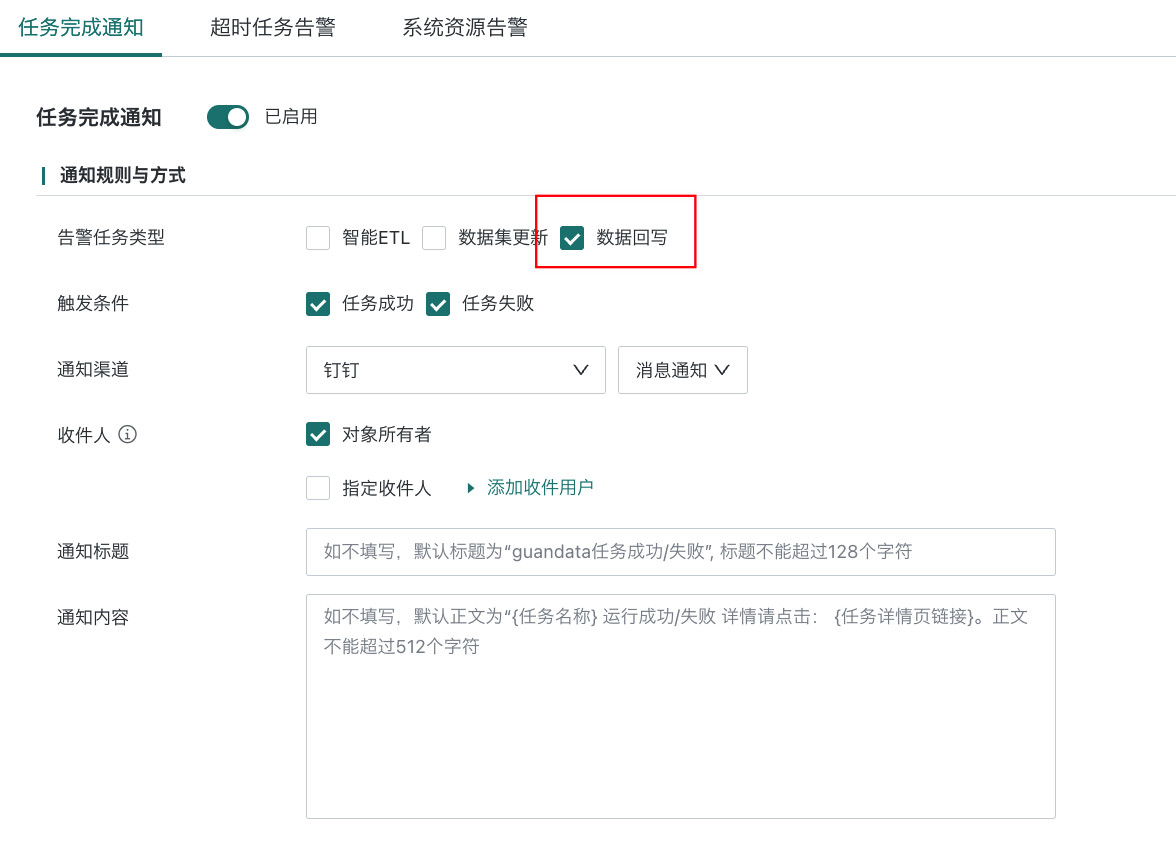
配置通知告警:支持数据回写成功或者失败时收到报警通知。功能入口:「管理中心 > 运维管理 > 通知告警 > 任务完成通知」界面。