借鉴公司部门层级生成BI用户组层级
需求背景
背景:某客户公司成立时间久,部门层级复杂,公司员工数众多。
需求1:
BI上线时需要借鉴公司的部门层级,规划并处理出BI相应的用户组层级,相应部门员工归属到相应用户组。
eg.零售一区和二区的所有人划分至零售一组用户组,零售三区和四区的所有人划分至零售二组用户组。
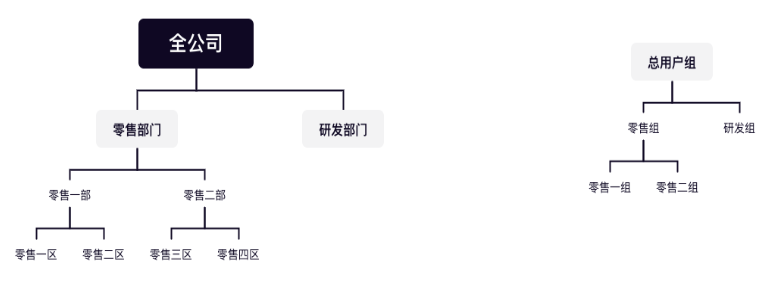
图一 公司部门层级与BI用户组层级样例
需求2:
当公司发生人员变动(入职、离职、换岗等)时,BI账号的所属用户组也随之发生变化,以减少人工维护用户组的成本。
基础数据源与目标数据集
基础数据源
首先通过账户数据集功能获取公司的部门层级,可以得到员工表、公司部门层级表两张表,分别如表一、表二所示。员工表会记录每个员工的工号、姓名、邮箱、所属部门等信息,部门层级表记录公司的部门层级,有deptid、name、parent_id等字段。
| name(姓名) | userid(工号) | email(邮箱) | deptid(部门ID) |
| 张三 | A001 | zhangsan@guandata.com | retail101 |
| 李四 | A002 | lisi@guandata.com | retail101 |
| 王五 | A003 | wangwu@guandata.com | retail101 |
| 赵七 | A004 | zhaoqi@guandata.com | retail201 |
| 钱八 | A005 | qianba@guandata.com | retail201 |
表一 公司员工表
| deptid(部门ID) | name(部门名称) | parent_id(直属部门) |
| retail101 | 零售一区 | retail1 |
| retail102 | 零售二区 | retail1 |
| retail103 | 零售三区 | retail2 |
| retail104 | 零售四区 | retail2 |
| retail1 | 零售一部 | retail |
| retail2 | 零售二部 | retail |
| retail | 零售部门 | all |
| all | 全公司 | null |
表二 公司部门层级表
目标数据集
结合需求背景、基础数据源、账户同步功能,可以设计出需要整理得出的两个目标数据集:BI用户组层级和员工信息总表,分别如表三、表四所示。
| BI用户组ID | BI用户组名称 | BI父用户组ID |
| BI_001 | 总用户组 | null |
| BI_002 | 零售组 | BI_001 |
| BI_003 | 研发组 | BI_001 |
| BI_004 | 零售一组 | BI_002 |
| BI_005 | 零售二组 | BI_002 |
表三 BI用户组层级
表三的BI用户组层级:
-
根据客户需求梳理得到,展现的是客户所需要的BI用户组层级
-
将会在账户同步中被使用,用来在BI中创建各层级用户组
| name | userid | 部门 | parent*1 | parent*2 | parent*3 | BI用户组ID | BI用户组名称 |
| 张三 | A001 | 零售一区 | 零售一部 | 零售部门 | 全公司 | BI_004 | 零售一组 |
| 李四 | A002 | 零售二区 | 零售一部 | 零售部门 | 全公司 | BI_004 | 零售一组 |
| 王五 | A003 | 零售三区 | 零售二部 | 零售部门 | 全公司 | BI_005 | 零售二组 |
| 赵七 | A004 | 零售四区 | 零售二部 | 零售部门 | 全公司 | BI_005 | 零售二组 |
| 钱八 | A005 | 零售一部 | 零售部门 | 全公司 | null | BI_004 | 零售一组 |
| 孙九 | A006 | 零售二部 | 零售部门 | 全公司 | null | BI_005 | 零售二组 |
| 李十 | A007 | 零售部门 | 全公司 | null | null | BI_002 | 零售组 |
| 周二 | A008 | 全公司 | null | null | null | BI_001 | 总用户组 |
表四 员工信息总表
表四的员工信息总表:
-
员工的name、userID、部门等信息直接从表一所示的公司员工表得到
-
parent1、parent2、parent*3...代表的是该员工的上级部门、上上级部门、上上上级部门...能比较直观地看出某员工所有的上级部门,方便给客户做员工信息管理。字段的生成过程请参考下文“公司部门层级信息梳理”部分。
-
parentN的名词解释:指的是某部门的第N层上级部门。以表四举例,零售一区的parent1是零售一部,其parent2是零售部门,parent3是全公司;零售一部的parent1是零售部门,parent2是全公司。
-
parentN_id指的是某部门的第N层上级部门ID,parentN_name指的是某部门的第N层上级部门名称
-
员工所属BI用户组ID和名称,会在账户同步功能中被使用,用来给员工分配其所在BI用户组。字段的生成过程请参考下文“将员工归属于BI用户组”部分。
需求1实现
Step1-公司部门层级信息梳理
表二的公司部门层级表(deptid、name、parent_id)适合用来存储公司的所有部门层级关系,但不利于用户直观快速查清某部门所有上级部门层级。表四的展现形式(部门,parent1、parent2、parent*3)更加贴近用户习惯。
那么如何将表二的部门层级表,转化为表四的展现形式呢?
目前暂时没有非常完美的方法,现推荐以下方法,如果大家有更好的办法,也欢迎大家补充:
通过dept_id与parent_id的对应关系,将parent_id左关联dept_id得到parent2_id,同理可得到parent3_id、parent4_id、parent5_id...parent*N_id,大致过程如下图所示。
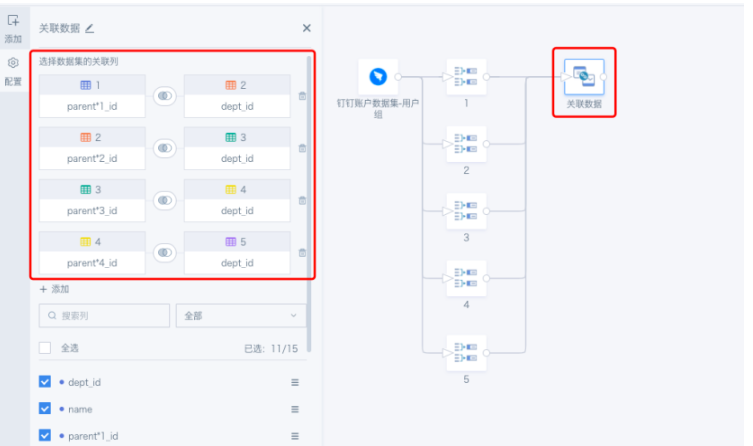
图二 公司部门层级信息梳理
但是,N的大小还无法确定,N偏小,就无法完全获取该部门所有的上层部门。
为了确定N的值,可以先摸清客户目前的组织架构层级数。先多做几次左关联,直到某个parent*N_id的取值均为null,此时的层级数N就是客户当前的组织架构层级(如图二的组织架构层级为4,即N=4)。
实际情况参考:某客户钉钉用户数超1.8万人,其公司部门层级数为9,即N=9**
通常情况下,组织层级是相对稳定的,不会有大幅度的变动,以防万一客户有做新增组织层架相关的调整,在当前的层级数N的基础上,多加几个层级数,比如N+5,基本就能确保parent*N+5_id的值全为null,于是就得到了每一个dept_id完整的上层部门层级。
此时的汇总所有的上层部门层级的公式可以写为:
concat(部门名称, parent1_name, parent2_name... parentN_name... parentN+5_name)
step2-将员工归属于BI用户组
有两种方法可以实现。
方法一,用模糊匹配的方式。
如果用户的所属部门或者其上层部门层级里含有某关键词,即归属于某用户组。举个例子,某部门上层部门层级含“零售一组”关键词,那么该部门就归属于“零售一组”用户组。
如:上层部门层级=concat(部门名称,parent1_name,parent2_name,parent*3_name......)
于是模糊匹配的公式为:case when 上层部门架构 like "%零售一组%" then "零售一组" else ... end
这样可以直接得到userid-部门-BI用户组名称的对应关系。
-
这种方式的优势在于
- 假如日后出现了一个归属于“零售一组”的新部门,通过对该部门的上层部门层级的模糊判断,可以自动将其划分为“零售一组”用户组,省去了人工维护的成本;
-
劣势在于
-
部门名称的变动会使得判断条件无效,如“零售一组”改为“销售一组”时,必须将模糊匹配的条件语句也一并修改才行
-
模糊匹配条件的维护,在产品上线后肯定会交给客户自己去维护,这就要求客户自己拥有基本的SQL语句编写能力(主要是case when语句)。有些客户不具备这种能力,加上其自身学习能力也差,难以掌握此技能
-
在小公司或者用户组层级简单的公司里,使用模糊匹配的方式维护用户组是可以的,但如果是大公司或者用户层级复杂的公司,就会有很多用户组,也就是说,判断条件会很多,case when 语句会很长,如 case when 上层架构 like "%零售一组%" then "零售一组" when 上层架构 like "%零售二组%" then "零售二组" ... else ... end。过长的语句,在ETL里是不方便维护的。
-
方法二,人为梳理部门ID与用户组ID的对应关系表(如下表),将此对应关系与公司员工表(表一)做匹配,以此得到员工所属的BI用户组。
| deptid | 公司部门名称 | BI用户组ID | BI用户组名称 |
| dept_8 | 全公司 | BI_001 | 总用户组 |
| dept_7 | 零售部门 | BI_002 | 零售组 |
| dept_9 | 研发部门 | BI_003 | 研发组 |
| dept_5 | 零售一部 | BI_004 | 零售一组 |
| dept_1 | 零售一区 | BI_004 | 零售一组 |
| dept_2 | 零售二区 | BI_004 | 零售一组 |
| dept_6 | 零售二部 | BI_005 | 零售二组 |
| dept_3 | 零售三区 | BI_005 | 零售二组 |
| dept_4 | 零售四区 | BI_005 | 零售二组 |
表五 部门ID与用户组ID对应关系表
-
这种方式的优势在于
-
无需编写SQL语句
-
利用部门ID而非部门名称去维护与用户组的对应关系,避免后期部门改名称带来的麻烦
-
-
劣势在于
-
新增一个部门时,就需要人为维护一次新部门ID与用户组的对应关系,无法自动根据其上层架构规划至用户组
-
以部门ID的形式维护对应关系,没有部门名称那么直观
-
在某项目实际实施中,慎重考虑后认为,公司的组织架构一般比较成熟,出现调整组织架构的可能性比较低,于是最终选择了第二种方法。
需求2实现
在把两个目标数据集制作完成后,可以在BI后台进行账户同步配置,系统会自动生成BI用户组,并进行人员基础属性设置(账户同步帮助文档:账户同步)。下图为某客户环境下的账户同步配置页面,可供参考。