用窗口函数制作历史拉链表
背景
上篇文章《用时序UDF制作历史拉链表》介绍了如何使用观远自定义时序函数制作历史拉链表,不过,时序自定义函数使用逻辑比较复杂,对用户来说可能操作起来不太方便,本文将介绍如何在ETL使用 Spark 窗口函数来制作历史拉链表。
《用时序UDF制作历史拉链表》传送门:
点击链接查看:https://docs.guandata.com/?g=Doc&m=Article&a=index&id=1&aid=428145563741978624
拉链表2种制作方式对比如下,请根据实际场景选择合适的方式:
| 拉链表制作方式 | 适用场景 | 注意点 |
| 时序 UDF 函数 | 适合巨量数据(上亿),可以使数据量最大程度缩减 | 对用户SQL水平有要求 |
| Spark 窗口函数 | 适合小数据量,上手友好 | 数据量缩减有限;窗口函数较耗资源,数据量变大后效率会变低; |
Spark 窗口函数使用请参考:spark窗口函数及应用
实现步骤
数据准备
把已经准备好的库存快照表(用ETL制作数据快照)或者流水明细表导入到观远数据平台中,创建一个Smart ETL,先把数据聚合到需要的颗粒度。这里我们准备一张门店、商品的日汇总表,以下图为例,既存在连续日期,也存在跳跃日期,缺失的日期实际库存数等同于历史最近日期的库存数。
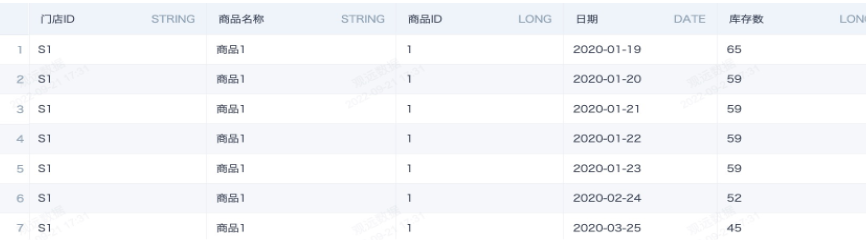
ETL数据处理
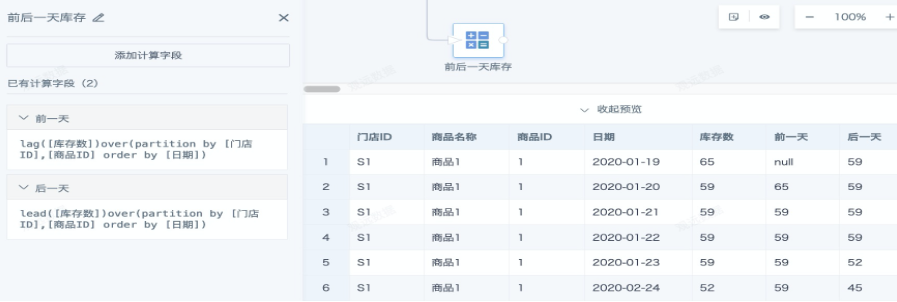
- 添加计算列,添加计算字段,使用 lead/lag 窗口函数分别计算出每个门店每种商品前一天和后一天的库存数。
lead([库存数])over(partition by [门店ID],[商品ID] order by [日期])
lag([库存数])over(partition by [门店ID],[商品ID] order by [日期])
--按照[门店ID][商品ID]分组,[日期]升序排列,分别取前后一行数据
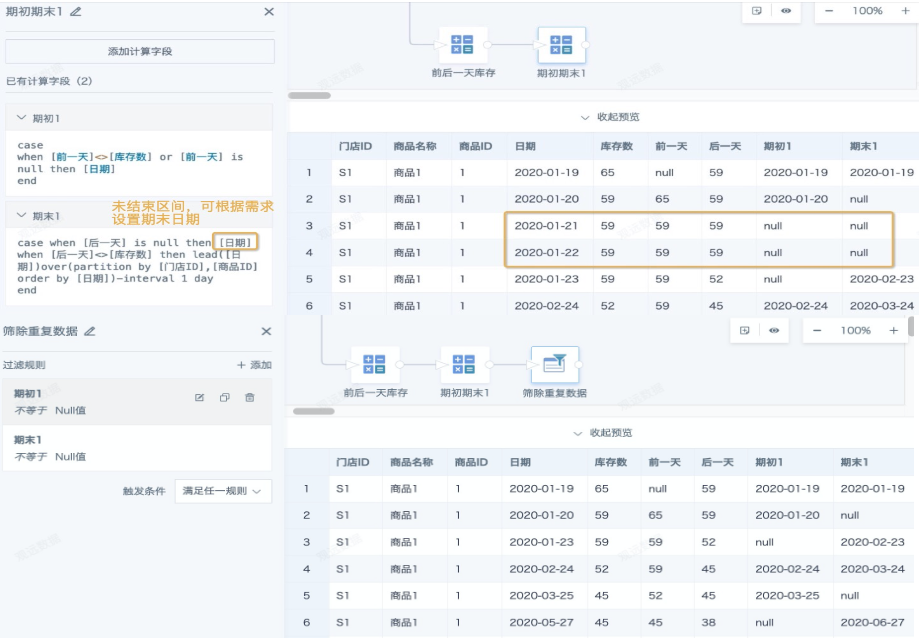
- 添加计算列,添加计算字段「期初1」「期末1」,通过对比前一天和后一天的库存数来初步判断每个库存数的期初日期和期末日期。未结束日期区间,期末日期可根据需求设置为今天或者固定日期(例如年末)。
以下图为例,2020-01-20至2020-01-23期间库存没有变化,2020-01-21和2020-01-22两天就既不是期初也不是期末,期末为库存数发生变化的前一天。 然后用筛选数据行节点把非期初期末的重复库存数据筛除。
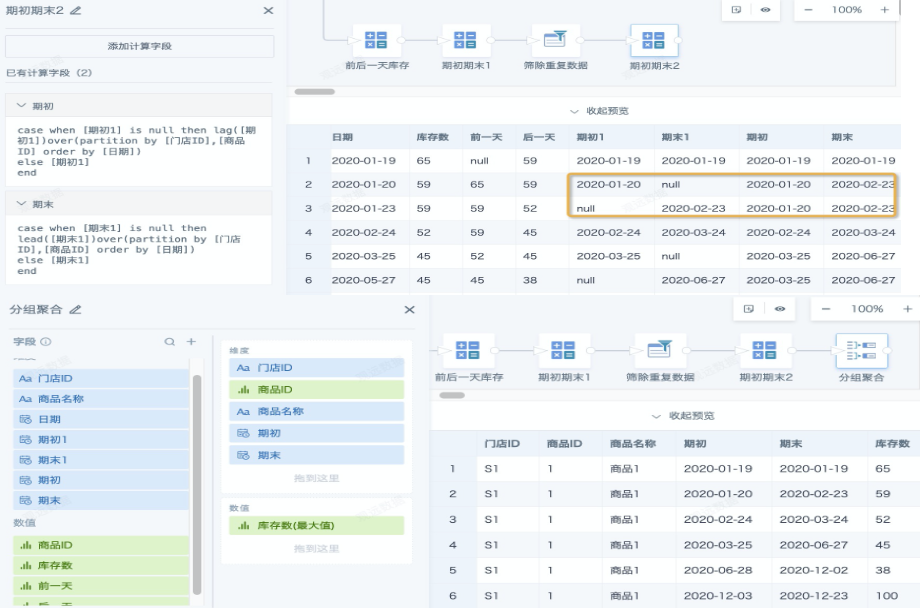
- 上一步重复数据筛除后,日期都变成非连续日期,但是同一个日期区间内的期初和期末日期仍旧是分为2行的,需要合并为1行。这里依次分别添加一个“添加计算列”和“分组聚合”节点来把「期初1」「期末1」里的null值补齐并去重,数据进一步缩减,添加输出节点并保存运行,拉链表制作完成。
注意:以上非唯一方案,可以使用窗口函数探索更多解决方案。例如,库存快照表(或者任何日期连续的情况)也可使用 lasting_days_to_date 函数制作拉链表。
请参考 https://docs.guandata.com/?g=Doc&m=Article&a=index&id=1&aid=428149303114989568 。
仪表板展现
场景一:直接查询
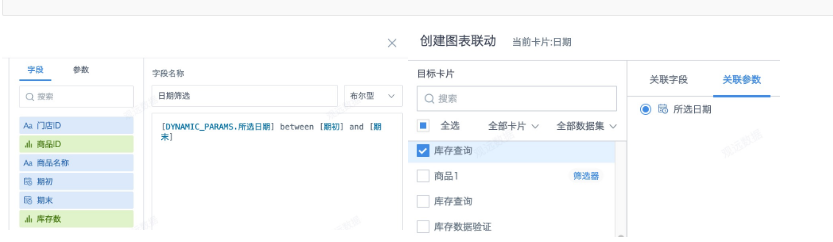
页面卡片上制作卡片,新建计算字段「日期筛选」,布尔型,引用时间型全局参数,拖入筛选栏(默认筛选true)。然后在页面上创建日期筛选器,联动卡片里使用的全局参数即可。
[DYNAMIC_PARAMS.所选日期] between [期初] and [期末]
[DYNAMIC_PARAMS.所选日期] >= [期初] and [DYNAMIC_PARAMS.所选日期] <=[期末]
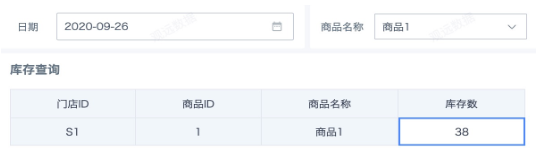
最终页面效果:
场景二:同环比计算
由于拉链表是基于日期区间模糊查询,卡片里无法使用系统自带的同环比计算,需要借助全局参数直接计算出同环比数据并展示。以下案例展示月同比数据。
新建以下2个计算字段,拖入数值栏,不需要筛选日期。然后在页面上创建日期筛选器,联动卡片里使用的全局参数即可。
