如何计算连续发生天数
场景介绍
某一事件可能会存在发生或者不发生的情况,系统中会按日记录这一事件的发生状态,如事件发生的情况下,会记录正常,不发生则记录异常。
而我们希望知道事件的连续发生的情况,当事件为正常状态,则记录正常状态的持续天数,如某天发生异常,则终止计数,从下次正常状态重新计数。
数据结构示例
需要根据事件A对应日期的状态,来计算连续发生的天数。(加粗列为希望通过ETL处理后获得的数据):
| 事件名称 | 日期 | 状态 | 连续发生天数 |
|---|---|---|---|
| 任务A | 2022/1/1 | 正常 | 1 |
| 任务A | 2022/1/2 | 正常 | 2 |
| 任务A | 2022/1/3 | 正常 | 3 |
| 任务A | 2022/1/4 | 正常 | 4 |
| 任务A | 2022/1/5 | 正常 | 5 |
| 任务A | 2022/1/6 | 异常 | 0 |
| 任务A | 2022/1/7 | 正常 | 1 |
| 任务A | 2022/1/8 | 正常 | 2 |
| 任务A | 2022/1/9 | 异常 | 0 |
| 任务A | 2022/1/10 | 异常 | 0 |
实现方法
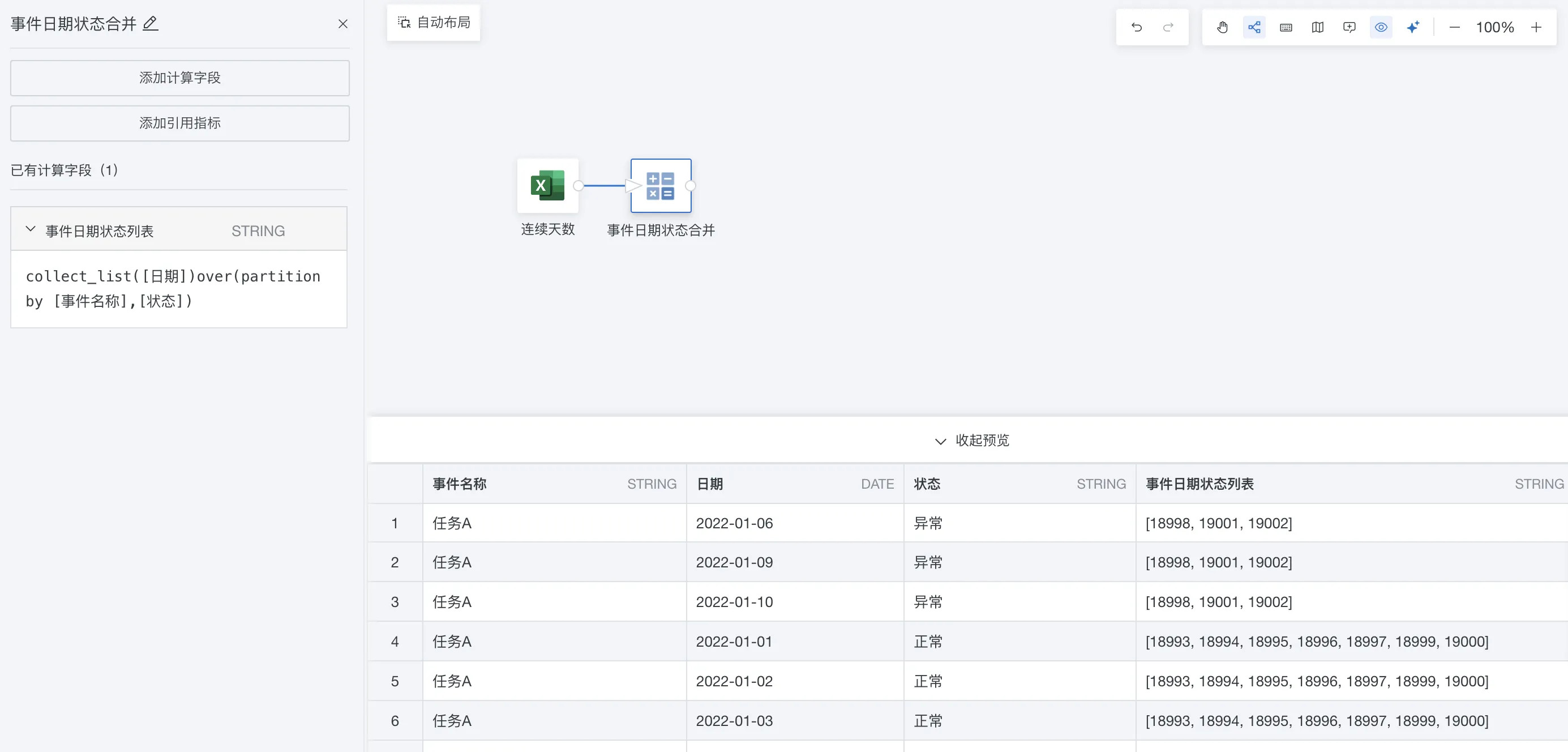
步骤一:在ETL里「添加计算列 > 添加计算字段」,把日期按照维度字段“事件名称”和“状态”分组后合并为数组。公式和预览效果如下图(数组里日期自动转换为unix date数值保存)。
collect_list([日期])over(partition by [事件名称],[状态])
--也可以使用 collect_set 函数。
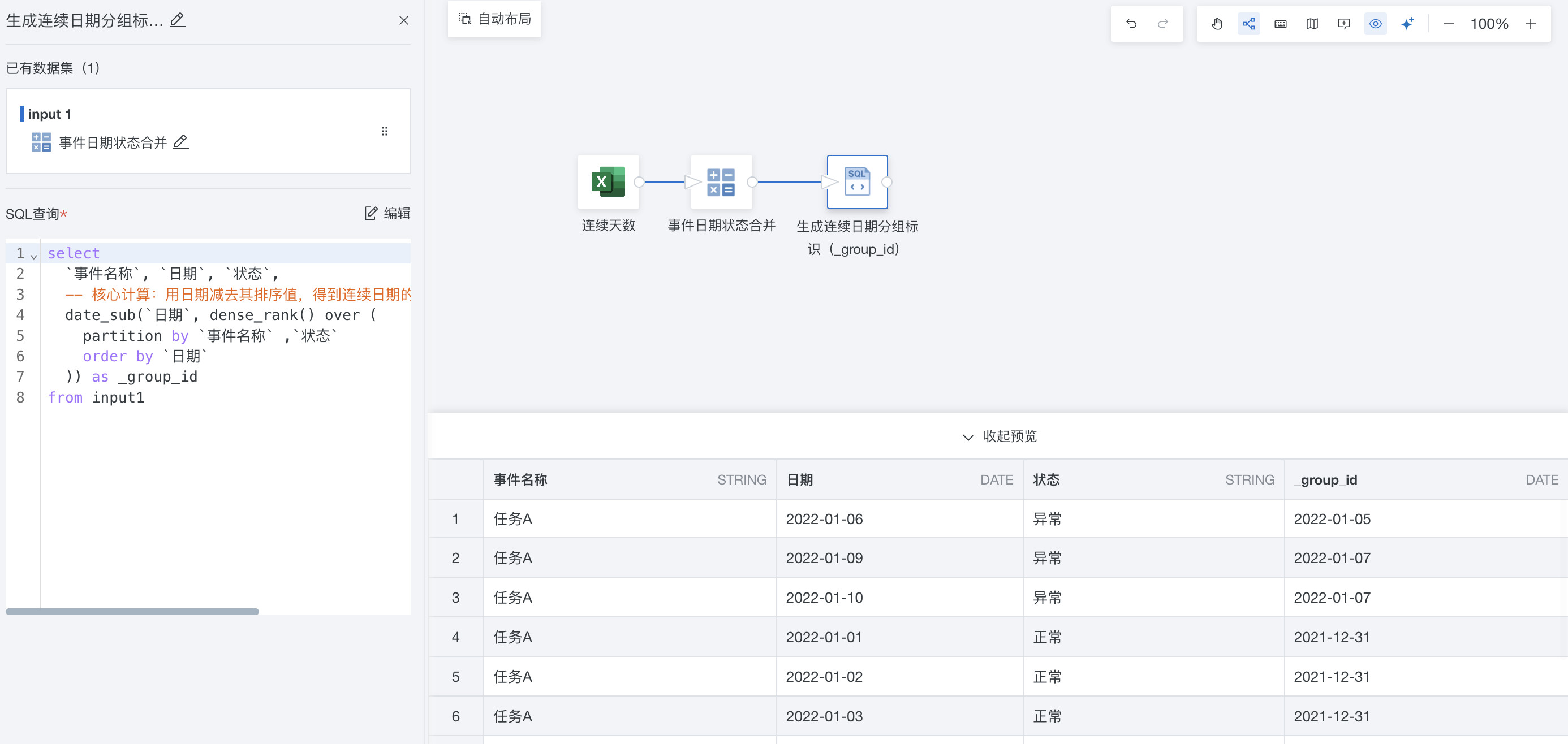
步骤二:添加SQL输入,使用 dense_rank + date_sub 计算得到每行“状态”的持续天数。 核心逻辑 - 计算所选维度(事件名称)下的连续日期的天数序号,状态为 “异常” 时连续天数重置为 0。
-
生成连续日期分组标识(group_id)
SQL语法:dense_rank() over (partition by [维度1], [维度2] order by orddate)
select
`事件名称`, `日期`, `状态`,
-- 核心计算:用日期减去其排序值,得到连续日期的分组标识(仅针对状态正常的记录)
date_sub(`日期`, dense_rank() over (
partition by `事件名称` ,`状态`
order by `日期`
)) as _group_id
from input1
用日期减去其排序值,得到一个 “基准日期”。对于连续的订单日期,这个基准日期会相同(即属于同一组);对于不连续的日期,基准日期会不同(分属不同组)。
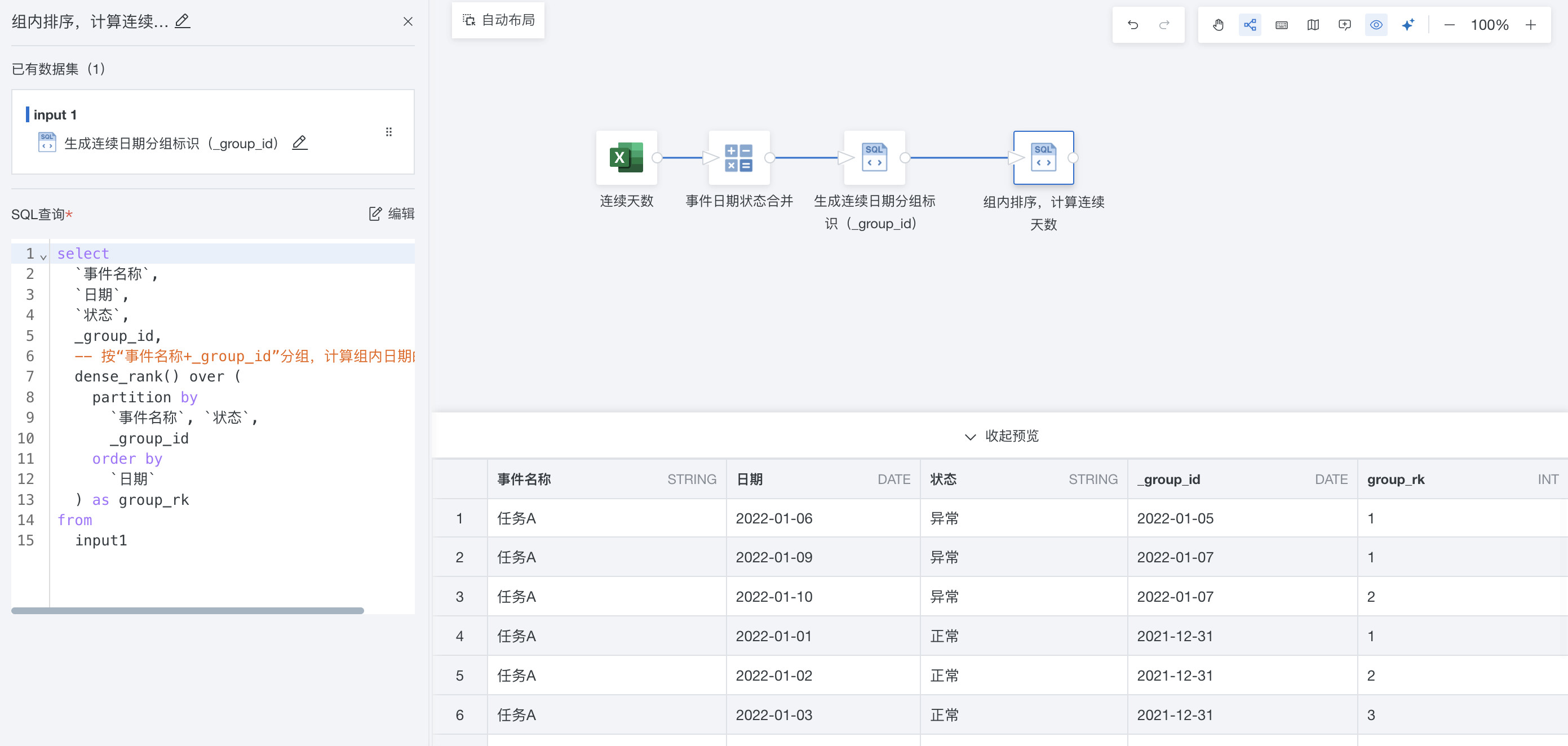
-
组内排序,计算连续天数
SQL语法:dense_rank() over (partition by [维度1], [维度2], _group_id order by orddate)
select
`事件名称`,
`日期`,
`状态`,
_group_id,
-- 按“事件名称+_group_id”分组,计算组内日期的排序值
dense_rank() over (
partition by
`事件名称`, `状态`,
_group_id
order by
`日期`
) as group_rk
from
input1
按 “事件名称 + 状态 + 连续日期组(group_id)” 分组,对每个组内的订单日期按时间排序,得到的排名就是该组内的连续天数序号(group_rk)。
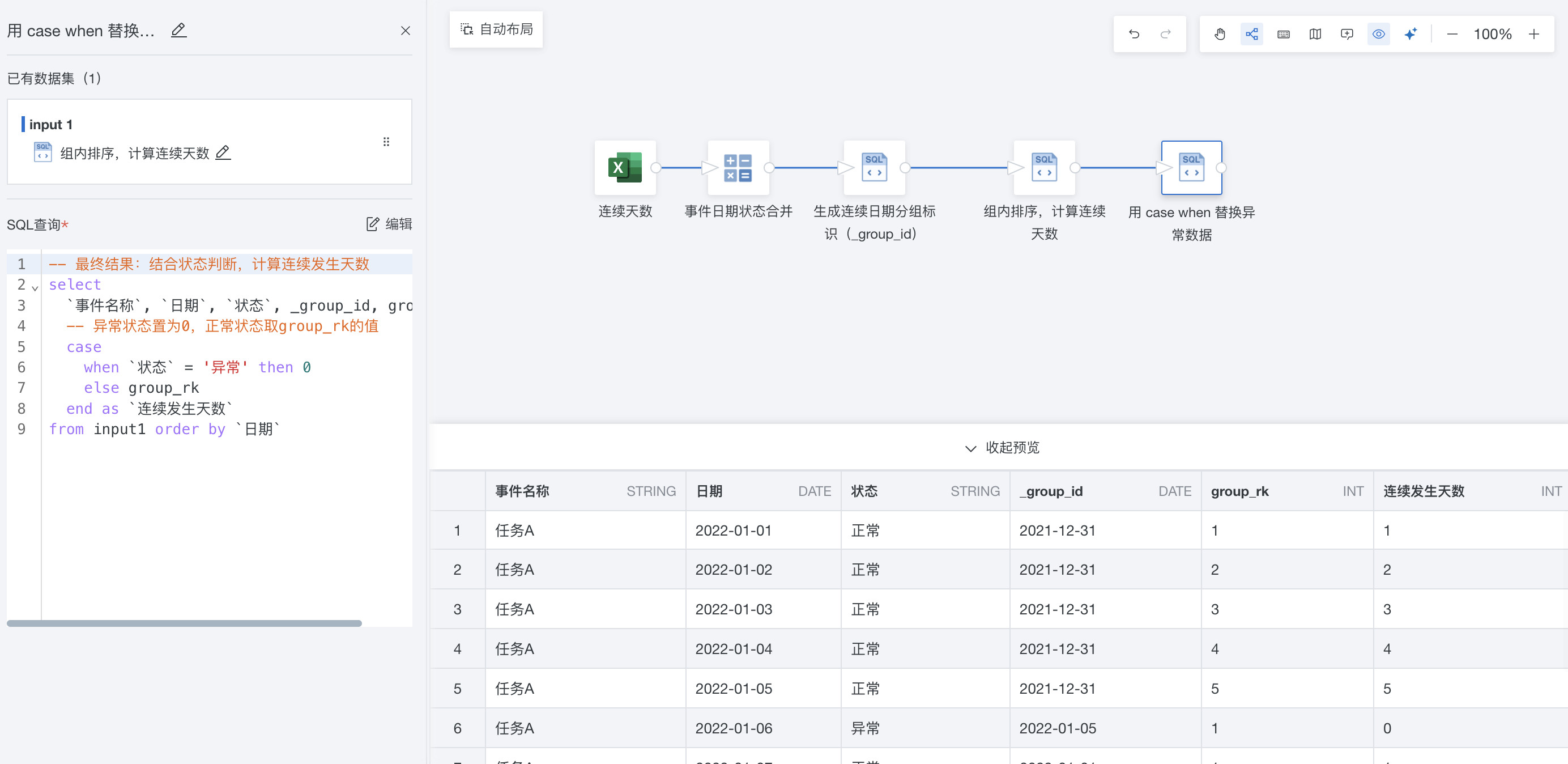
- 用 case when 替换异常数据
-- 最终结果:结合状态判断,计算连续发生天数
select
`事件名称`, `日期`, `状态`, _group_id, group_rk,
-- 异常状态置为0,正常状态取group_rk的值
case
when `状态` = '异常' then 0
else group_rk
end as `连续发生天数`
from input1 order by `日期`
当状态 = '异常'时,直接返回 0(忽略group_rk的值,强制重置连续天数)。
ETL内预览数据为随机显示,想要按固定顺序预览数据,可以额外添加SQL节点对数据排序后再预览,排序不对输出数据集生效。