数据集行权限使用案例分享
案例一:“一人多店”,用户属性多值匹配
业务场景
针对类似像店铺管家这种,用户数较多且用户层级鲜明的情况:店长-城市主管-城市经理,三种类型的用户都只能查看自己所管辖店铺的业绩情况,且存在一人管多店的情况。
方案
1. 配置用户属性:在用户属性添加「门店」这一属性,填写用户对应的门店编码;若一人管辖多个门店,则填写多个门店编码,并以分隔符(如逗号)隔开。
2. 行权限配置:在数据集「数据安全」界面设置行权限,条件模式下,添加条件,选择“in(用户属性)”,点选进行界面化配置(此功能5.5及以后版本可用)。
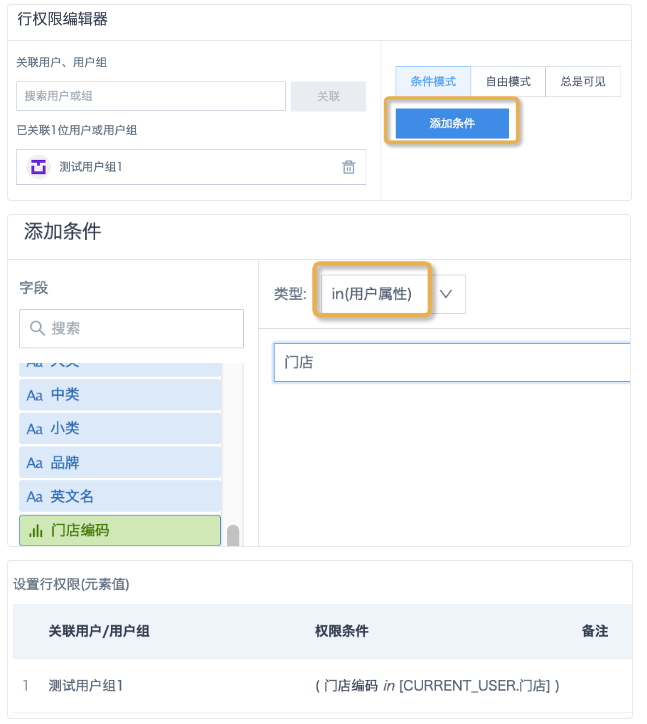
3. 5.5以前的版本,可以使用自由模式配置权限条件。
非直连数据集行权限写法:
array_contains(split( [CURRENT_USER.门店] ,','),[门店编码])
Clickhouse写法:
[门店编码] in splitByChar(',',[CURRENT_USER.门店])
注意事项
-
用户属性为字符串string格式,数据集字段若非string格式,建议先把字段转换为string格式,再设置行权限;
-
建议优先使用条件模式下的“in(用户属性)”用法,条件模式无法满足需求时再使用自由模式。
-
其他数据库语法可以参考:各直连数据库行权限设置语法。
案例二:用户属性多值+逻辑判断+模糊匹配
业务场景
用户属性里有大区、城市。总公司员工大区属性里有值,可能有一个或者多个值(例如华东),城市为空,可以查看自己所在大区的所有数据,子公司员工大区为空,城市可能有一个或者多个值(例如上海,杭州),只可以查看自己管辖城市下的数据。总公司和子公司员工同属于一个大的用户组。
非直连(非加速)数据集,字段有大区、省份、城市,大区可以精确匹配,但是省份、城市是全称,例如上海市、杭州市、内蒙古自治区,跟用户属性不能精确匹配。
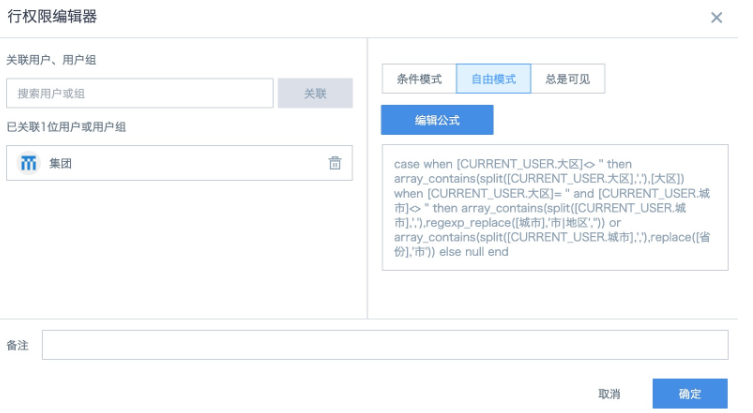
行权限写法
case when [CURRENT_USER.大区]<> '' then array_contains(split([CURRENT_USER.大区],','),[大区])
when [CURRENT_USER.大区]= '' and [CURRENT_USER.城市]<> '' then array_contains(split([CURRENT_USER.城市],','),regexp_replace([城市],'市|地区','')) or array_contains(split([CURRENT_USER.城市],','),replace([省份],'市'))
else null end
逻辑说明
-- 判断总公司用户,匹配“大区”字段
case when [CURRENT_USER.大区]<> '' then array_contains(split([CURRENT_USER.大区],','),[大区])
-- 判断子公司用户
when [CURRENT_USER.大区]= '' and [CURRENT_USER.城市]<> ''
-- 把城市字段去掉“市“或者“地区”再进行匹配,如果某些城市名字里带有其他后缀例如”自治州“,可以嵌套使用 replace 函数或者使用正则表达式 regexp_replace来去掉后缀;
then array_contains(split([CURRENT_USER.城市],','),regexp_replace([城市],'市|地区',''))
-- 直辖市城市名如果在省份里,需要匹配"省份"
or array_contains(split([CURRENT_USER.城市],','),replace([省份],’市’))
注意事项
-
如果用户属性是字符串单值,可以直接使用 [CURRENT_USER.大区]=[大区] 这样的精确匹配,和 instr([城市],[CURRENT_USER.城市])>0 这样的模糊匹配。
-
多值的情况下要用 array_contains(split()) 函数逐个匹配(同时也完全适应单值的情况); 不过数组不适用模糊匹配,不能用 like, 所以需要对数据集字段做处理。位置和长度都一样的情况可以使用 substr 来代替 replace,例如 array_contains(split([CURRENT_USER.城市],','),substr([城市],1,2)) 。
Clickhouse写法
case when [CURRENT_USER.大区]<> '' then has(splitByChar(',',[CURRENT_USER.大区]),[大区])
when [CURRENT_USER.大区]='' and [CURRENT_USER.城市]<>''then has(splitByChar(',',[CURRENT_USER.城市]),replaceRegexpOne([城市],'市|地区','')) or has(splitByChar(',',[CURRENT_USER.城市]),replaceOne([省份],'市',''))
else null end
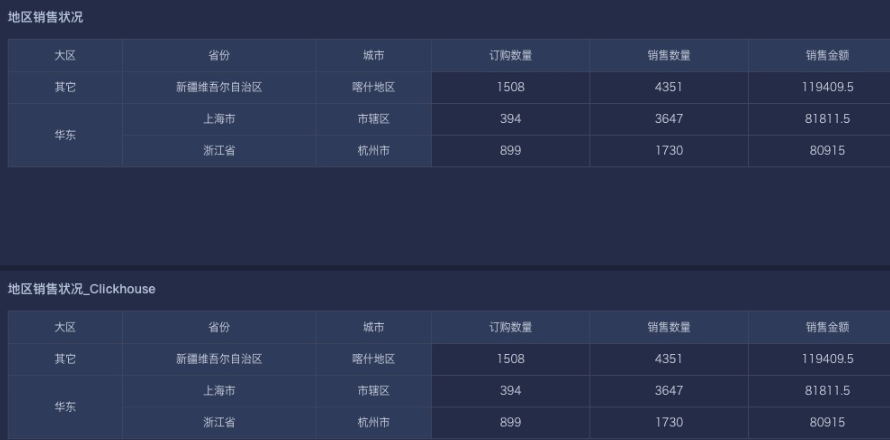
最终效果:
例如:用户属性「城市」:上海,杭州,喀什
案例三:用户属性多值+只匹配第一个值+模糊匹配
业务场景
用户属性城市为多值,每个用户至少有一个城市,一般情况下用户可以看自己属性里所有城市的数据。但是有个别数据集只允许用户看自己所在地城市的数据,所在地城市就是城市属性里的第一个值,所以需要数据集字段只匹配第一个城市。
案例一同一数据集,非直连(非加速)数据集,省份、城市是全称,例如上海市、杭州市、内蒙古自治区,跟用户属性不能精确匹配。普通城市名需要去掉“市”“地区”之类后缀,直辖市需要去掉“市”再跟省份匹配。
行权限写法一
array_position(split([CURRENT_USER.城市],','),regexp_replace([城市],'市|地区',''))=1 or array_position(split([CURRENT_USER.城市],','),replace([省份],'市'))=1
逻辑说明:
-
用 split([CURRENT_USER.城市],',') 把城市拆分成数组。
-
array_position()=1 确保提取的是数组中第一个元素,即使用户属性是单值也适用。
行权限写法二
case when INSTR([CURRENT_USER.城市],',')>1 then SUBSTR([CURRENT_USER.城市],0,INSTR([CURRENT_USER.城市],',')-1) in (regexp_replace([城市],'市|地区',''),replace([省份],'市'))
else [CURRENT_USER.城市] in (regexp_replace([城市],'市|地区',''),replace([省份],'市')) end
逻辑说明:
-
把用户属性“城市”按照字符串处理。
-
用 case when 判断是单值还是多值,多值时截取第一个分隔符前的城市名,单值直接匹配城市/省份。
Clickhouse写法
arrayElement(splitByChar(',',[CURRENT_USER.城市]),1) = replaceOne([省份],'市','') or arrayElement(splitByChar(',',[CURRENT_USER.城市]),1) =replaceRegexpOne([城市],'市|地区','')
case when position([CURRENT_USER.城市],',')>1 then substring([CURRENT_USER.城市],1,position([CURRENT_USER.城市],',')-1) = replaceRegexpOne([城市],'市|地区','') or substring([CURRENT_USER.城市],1,position([CURRENT_USER.城市],',')-1) = replaceOne([省份],'市','')
else [CURRENT_USER.城市]= replaceRegexpOne([城市],'市|地区','') or [CURRENT_USER.城市]= replaceOne([省份],'市','') end
最终效果:
例如:用户属性「城市」:上海,杭州,喀什

案例四:仅允许特定用户查看180天内的数据
业务场景
希望给某个使用BI的群体增加一个权限,让这批用户只能查看最近180天(或半年)的数据。
行权限写法
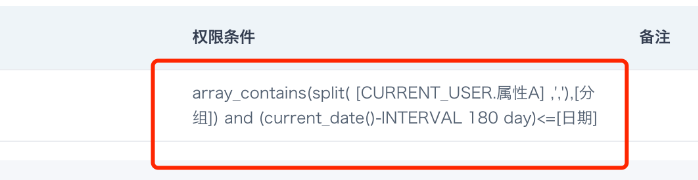
(current_date()-INTERVAL 180 day) <= [日期]
逻辑说明
1. 使用current_date() 函数获取当前日期,通过 INTERVAL 可以进行增减日期时间,所以这里通过(current_date()-INTERVAL 180 day) 或者(current_date()-INTERVAL 6 month) 可以取到当前日期-180天(或6个月)的具体日期,再小于等于数据集中的日期数据,即可将看到的数据控制在180天内。
该方式需要数据集中存在日期字段,且数据集每天保持更新,才能正常使用。
2. 多个规则需要同时生效时,用 and/or 连接即可。例如:
array_contains(split([CURRENT_USER.属性A] ,','),[分组]) and (current_date()-INTERVAL 180 day)<=[日期]
案例五:⽤户session动态修改全局参数
业务场景
某银行客户在第三方系统中内嵌了观远BI平台,对于数据行权限的管控非常精细,自己的第三方系统中已经存在一套权限的配置逻辑,需要在BI中生效。对于同⼀个BI看板,希望对于不同的⽤户展示的数据不相同,仅能看到自己有权限的数据;对于同一个用户,访问不同的BI看板,仅能看到自己有权限的数据。
此外,第三方系统中的用户有A,B两种角色,期望用户在A角色登录第三方系统看到的数据全是A角色对应的数据。
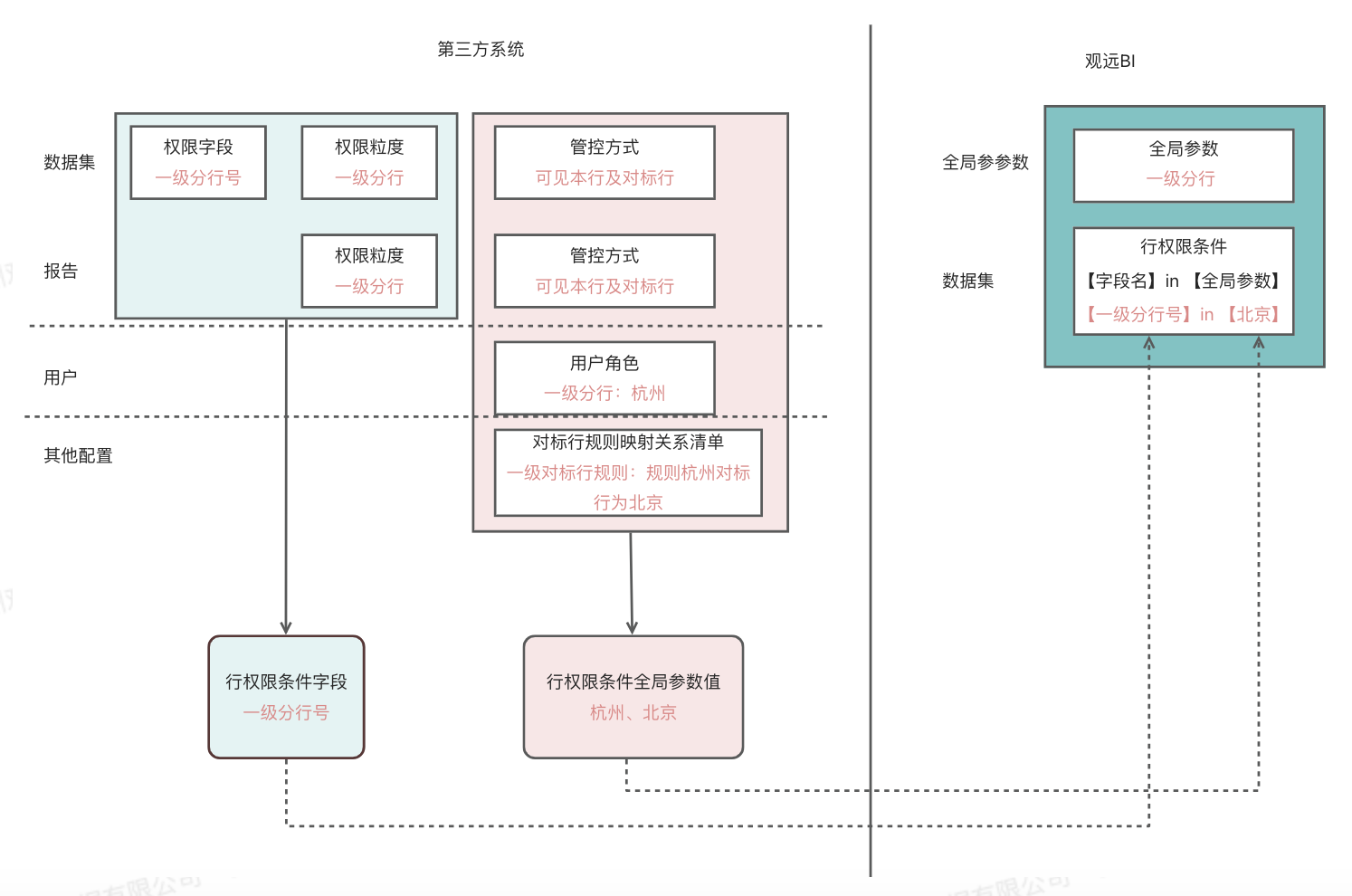
例如,某用户以一级分行身份登录时,在查看报表A时仅能看到本一级分行的数据,但在查看报表B时能看到本一级分行及本一级分行对标行的数据。
操作步骤
总体说明
- 观远BI的数据集⾏权限规则⽀持使⽤全局参数进⾏配置
- 管理员⽀持为普通⽤户⽣成uIdToken(session)⽤于平台登录访问
- 管理员⽀持通过接⼝对uIdToken(session)进⾏全局参数的参数值配置。session配置优先级最⾼,session配置值可动态替换全局参数的默认值,以实现指定⽤户数据集⾏权限的动态配置
- 普通⽤户使⽤管理员配置好权限规则的uIdToken访问平台时,对应数据集的⻚⾯卡⽚的数据展示 即可被管理员在session中以指定的规则进⾏管控
- 用户在智能ETL保存时,创建人的用户session信息将会保存到ETL元数据中,定时调度时进行权限判断。ETL编辑保存、转移所有者会更新session信息
案例实践
数据集可以根据一级分行和二级分行两个字段控制行权限,当用户以一级分行身份登录访问报告时,可以查看有权限的一级分行的数据,当用户以二级分行身份登录访问报告时,可以查看有权限的二级分行的数据。ETL定时调度运行时,采用ETL保存时seesion中配置的权限。
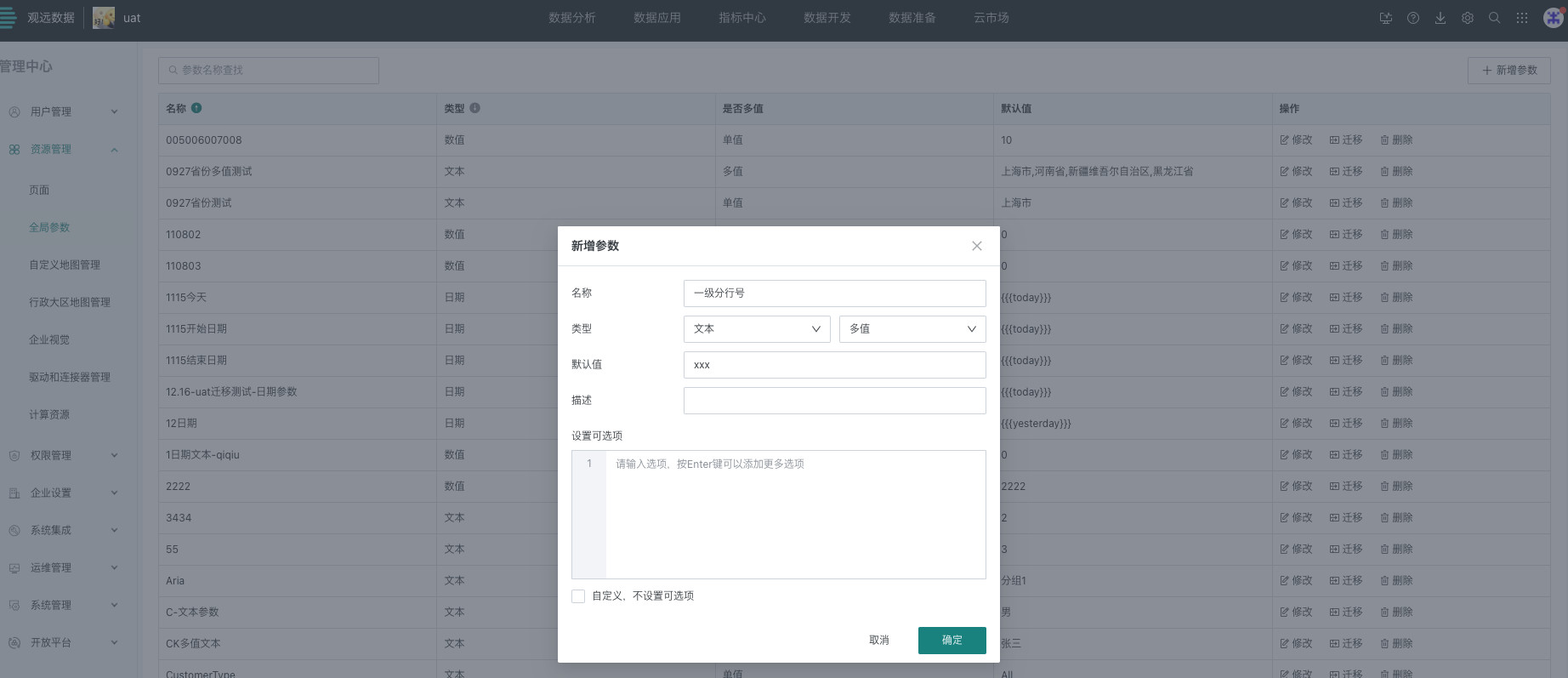
步骤一:管理员配置全局参数
入口:管理中⼼ > 资源管理 > 全局参数
配置全局参数一级分行号、二级分行号。
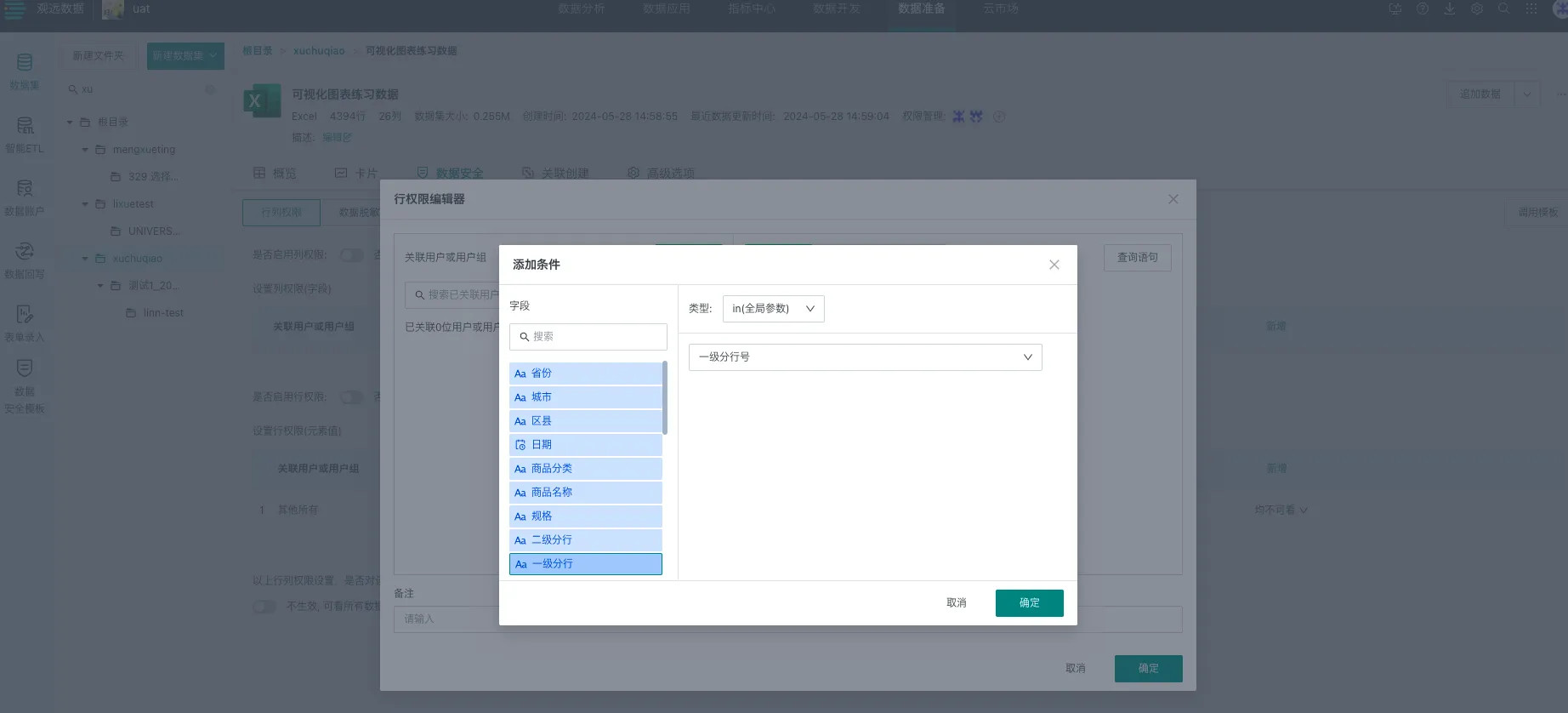
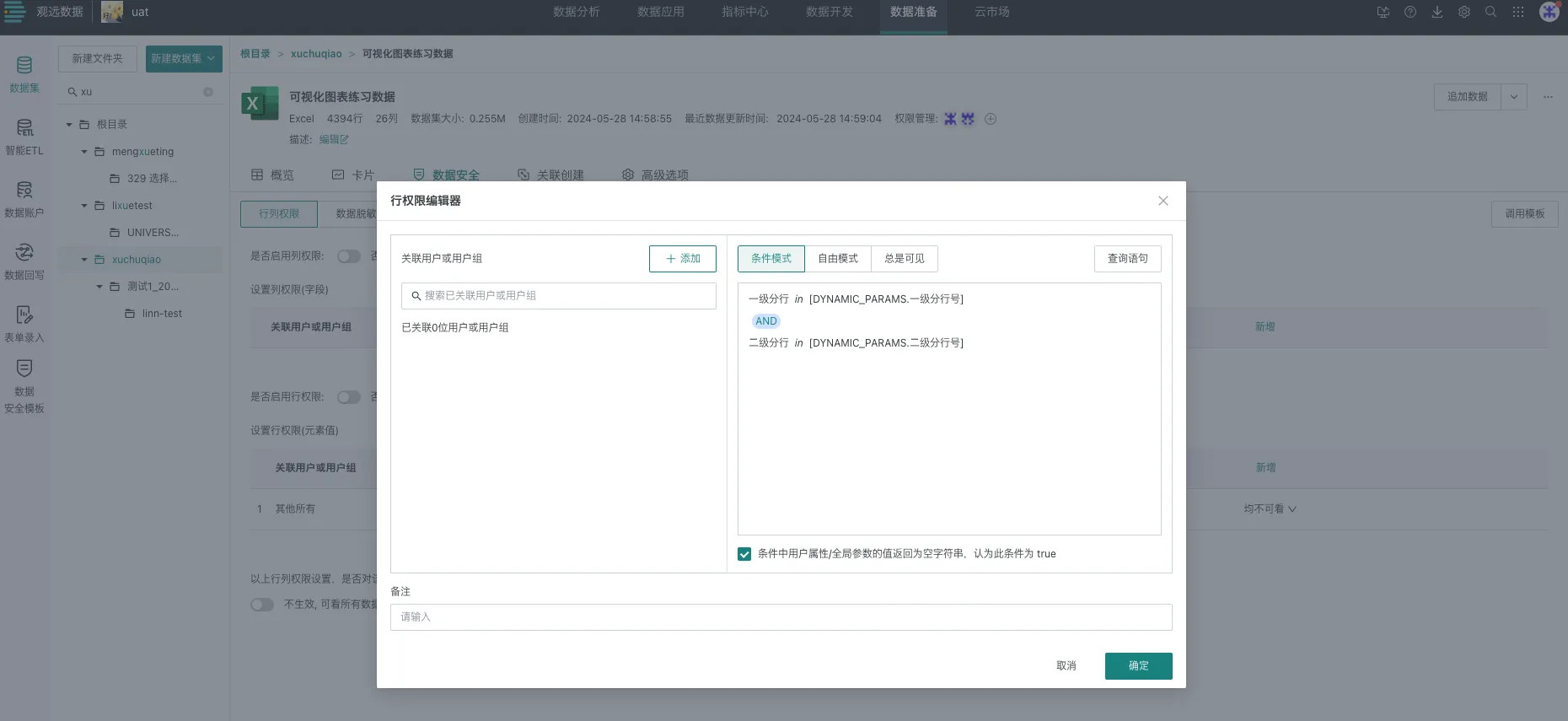
步骤二:配置数据集数据⾏权限
入口:数据准备 > 数据集 > 数据集详情 > 数据安全
配置行权限,选择条件模式中的in(全局参数)类型。用户在用不同身份登录时仅能查看自己有权限的一级分行/二级分行对应的数据行,具体能看到哪些一级分行/二级分行的数据则由全局参数的值动态决定。
步骤三:构建uIdToken,并种⼊浏览器cookie
用户在用一级分行身份登录时,访问某报告仅能查看自己有权限的一级分行的数据行,能看到的一级分行号清单由session中所传的全局参数参数值决定。
用户在用二级分行身份登录时,访问某报告仅能查看自己有权限的二级分行的数据行,能看到的二级分行号清单由session中所传的全局参数参数值决定。
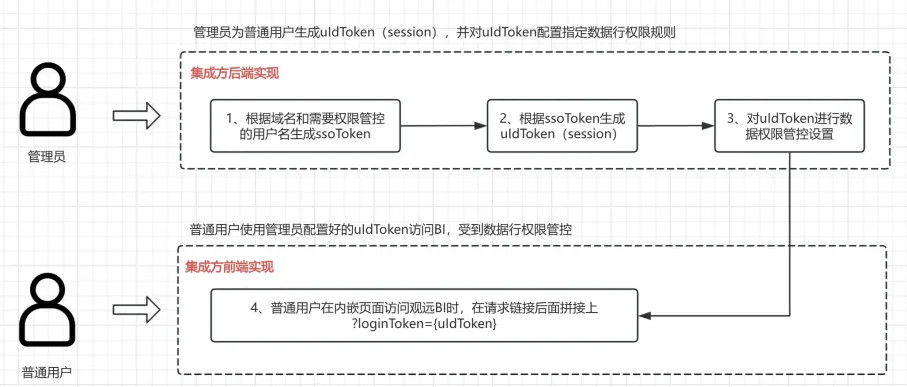
1)参考观远BI-SSO集成⽂档构建ssoToken 「集成⽅后端实现」
Java代码示例
- RSAUtil⼯具类
import org.apache.commons.codec.binary.Base64;
import javax.crypto.Cipher;
import java.io.ByteArrayOutputStream;
import java.security.*;
import java.security.interfaces.RSAPrivateKey;
import java.security.interfaces.RSAPublicKey;
import java.security.spec.InvalidKeySpecException;
import java.security.spec.PKCS8EncodedKeySpec;
import java.security.spec.X509EncodedKeySpec;
import java.util.HashMap;
import java.util.Map;
public class RSAUtil {
public static final String CHARSET = "UTF-8";
public static final String RSA_ALGORITHM = "RSA";
public static final int KEY_SIZE = 1024;
public static Map<String, String> createKeys() {
//为RSA算法创建⼀个KeyPairGenerator对象
KeyPairGenerator kpg;
try {
kpg = KeyPairGenerator.getInstance(RSA_ALGORITHM);
} catch (NoSuchAlgorithmException e) {
throw new IllegalArgumentException("No such algorithm-->[" +
RSA_ALGORITHM + "]");
}
//初始化KeyPairGenerator对象,密钥⻓度
kpg.initialize(KEY_SIZE);
//⽣成密匙对
KeyPair keyPair = kpg.generateKeyPair();
//得到公钥
Key publicKey = keyPair.getPublic();
String publicKeyStr = Base64.encodeBase64String(publicKey.getEnco
ded());
//得到私钥
Key privateKey = keyPair.getPrivate();
String privateKeyStr = Base64.encodeBase64String(privateKey.getEn
coded());
Map<String, String> keyPairMap = new HashMap<String, String>();
keyPairMap.put("publicKey", publicKeyStr);
keyPairMap.put("privateKey", privateKeyStr);
return keyPairMap;
}
public static RSAPublicKey getPublicKey(String publicKey) throws NoSu
chAlgorithmException, InvalidKeySpecException {
//通过X509编码的Key指令获得公钥对象
KeyFactory keyFactory = KeyFactory.getInstance(RSA_ALGORITHM);
X509EncodedKeySpec x509KeySpec = new X509EncodedKeySpec(Base64.de
codeBase64(publicKey));
RSAPublicKey key = (RSAPublicKey) keyFactory.generatePublic(x509K
eySpec);
return key;
}
public static RSAPrivateKey getPrivateKey(String privateKey) throws N
oSuchAlgorithmException, InvalidKeySpecException {
//通过PKCS#8编码的Key指令获得私钥对象
KeyFactory keyFactory = KeyFactory.getInstance(RSA_ALGORITHM);
PKCS8EncodedKeySpec pkcs8KeySpec = new PKCS8EncodedKeySpec(Base6
4.decodeBase64(privateKey));
RSAPrivateKey key = (RSAPrivateKey) keyFactory.generatePrivate(pk
cs8KeySpec);
return key;
}
public static String privateEncrypt(String data, RSAPrivateKey privat
eKey) {
try{
Cipher cipher = Cipher.getInstance(RSA_ALGORITHM);
cipher.init(Cipher.ENCRYPT_MODE, privateKey);
return Base64.encodeBase64String(rsaSplitCodec(cipher, Ciphe
r.ENCRYPT_MODE, data.getBytes(CHARSET), privateKey.getModulus().bitLength
()));
}catch(Exception e){
throw new RuntimeException("加密字符串[" + data + "]时遇到异
常", e);
}
}
public static String publicDecrypt(String data, RSAPublicKey publicKe
y) {
try{
Cipher cipher = Cipher.getInstance(RSA_ALGORITHM);
cipher.init(Cipher.DECRYPT_MODE, publicKey);
return new String(rsaSplitCodec(cipher, Cipher.DECRYPT_MODE,
Base64.decodeBase64(data), publicKey.getModulus().bitLength()), CHARSET);
}catch(Exception e){
throw new RuntimeException("解密字符串[" + data + "]时遇到异
常", e);
}
}
private static byte[] rsaSplitCodec(Cipher cipher, int opmode, byte
[] datas, int keySize) {
int maxBlock = 0;
if(opmode == Cipher.DECRYPT_MODE){
maxBlock = keySize / 8;
}else{
maxBlock = keySize / 8 - 11;
}
ByteArrayOutputStream out = new ByteArrayOutputStream();
int offSet = 0;
byte[] buff;
int i = 0;
try{
while(datas.length > offSet){
if(datas.length-offSet > maxBlock){
buff = cipher.doFinal(datas, offSet, maxBlock);
}else{
buff = cipher.doFinal(datas, offSet, datas.length-off
Set);
}
out.write(buff, 0, buff.length);
i++;
offSet = i * maxBlock;
}
} catch(Exception e){
e.getMessage();
}
byte[] resultDatas = out.toByteArray();
try {
out.close();
} catch(Exception e){
e.getMessage();
}
return resultDatas;
}
public static String toHexString(String s) {
String str="";
for (int i=0;i<s.length();i++)
{
int ch = s.charAt(i);
str += Integer.toHexString(ch);
}
return str;
}
}
- 生成SSO Token
public class Demo {
public static void main(String[] args) {
String privateKey =
"MIICdQIBADANBgkqhkiG9w0BAQEFAASCAl8wggJbAgEAAoGBAJPmp56tu
r+vOjpuke0xbId+GCmycImd/iIqJFb9b+tIJD2qgsYZHouhvEV2qorfyLs87eQYJGGf+CGHg83
DQG/SasFn46/NR+dAF33wvBhsq+lrqg7zW8ILy5cF33zHM3mCTqAUEPThRqmj28xkkwD5X2DVt
C5gLputWfRikZrDAgMBAAECgYAyhQ0ohItPwpkPMImkDcfWmFnElHEgcNlH7kEvfa5nHeNTNRU
qeZYXeA2JZLloanx0iKFx0lVLC4uEWHfLJzCw/KQ9OQM9bOLoPMuHRh70cBLaBgJepgD/I/hgW
GNKo+u61GQ0U0AbzYJU9fJ+yp4n53Gj84E6pOT71HEki++SAQJBAMdZXu37ONYgMtG4EOnnsQK
BLVHwZykwKH1szqkvfR3VlO/w0wWuKleQnh1DOoHK5Qhl4C4fBlBxp8y7/3i1OIECQQC97nBMk
lNr+oVXnkx2NgNLb5Ohjd85z1LH5b5QEQ2lIZ43wsUr+gFL6TP7bfOxvAbtUgWdtiiEemlOUfd
qw1FDAkA2HDcdR8y0qobA0EKfCwnMET44+JU349+JtAggekhu2bOUsXzGFPFfVVzluoLeCjHC5
sxEGJ3BJiiS9RCyNhaBAkA/8LiPnqdE77baM2mMVkyvpaVuuuNOg/RbZYW3ULZmRDYOkZxtXKH
5G04rs+1ZhXJTjMxlNsDXMJqpCkEgCRcfAkBJBU7Cy+p/HjBzTVLnlo8x+4io0OMjfu9BFJVqc
o2QCSmdZrW0ACiFoc5a5TJU7y+6pqw1GcM4am1vuAeR+qax";
try {
JSONObject plainData = new JSONObject();
plainData.put("domainId", "demo");
plainData.put("externalUserId", "hello@world.com");
plainData.put("timestamp", new Date().getTime());
String cipherData = RSAUtil.privateEncrypt(plainData.toJSONStr
ing(), RSAUtil.getPrivateKey(privateKey));
System.out.println(RSAUtil.toHexString(cipherData));
} catch (Exception ex){
ex.printStackTrace();
}
}
}
⽅法结果是⼀个ssoToken字符串
2)基于ssoToken调⽤/backend/sso/sign-in接⼝⽣成uIdToken「集成⽅后端实现」
以下为curl或postman的请求示例,具体需要集成⽅后端实现
curl --location --request POST 'https://bi-address.com/backend/sso/sign-i
n' \
--header 'User-Agent: Apifox/1.0.0 (https://apifox.com)' \
--data-raw '{
"provider":"demo",
"info":{
"ssoToken":
"65324869576b62476e6f75374b43386f485a41554762565765753358305030304a
2f727866697732695646524b50727749697a6d6a7444337772696a55326f705575424c50343
63254634f3067436e6c345a6f39714356585362373631326c56616c6a2f7550554245327255
304b4b4d384a414d6f2b7954426976547757796b79596c674b6a4c385151697364767349644
86846424f6830774a784738425459573055372f496f427a6e6f3d"
}
}'
postman请求示例:
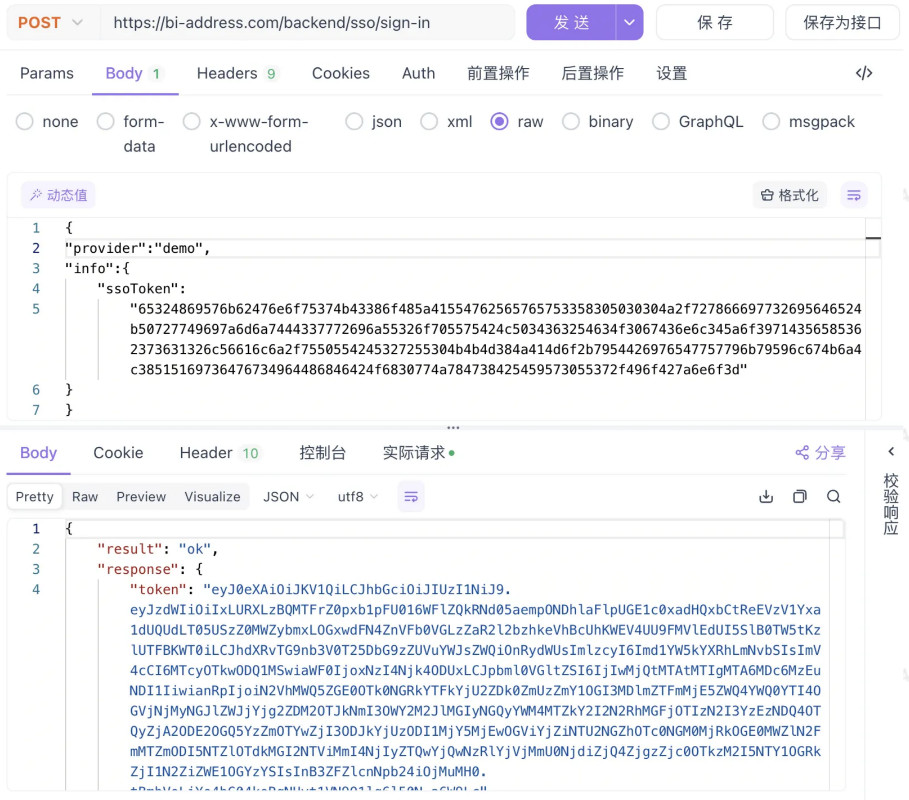
接⼝请求结果token是uIdToken字符串。
3)对uIdToken进⾏参数配置 「集成⽅后端实现」
session创建or更新public api接⼝定义
路由:POST
/public-api/session/createOrUpdate
请求参数:
| 参数名 | 参数值说明 | Location | 类型 | 是否必填 | 备注 |
|---|---|---|---|---|---|
| token | 应用token | body | String | 是 | 应用token,用于鉴权 |
| uIdToken | uIdToken | body | String | 是 | uIdToken用于生成session |
| bizType | 业务类型 | body | String | 是 | GLOBAL_PARAMETER |
| data | session 数据 | body | Json Array | 是 | session 对应配置数据 |
token为调用观远BI public api的请求凭证,在观远BI「管理中心 > 系统集成 > 统一账户集成」处获取
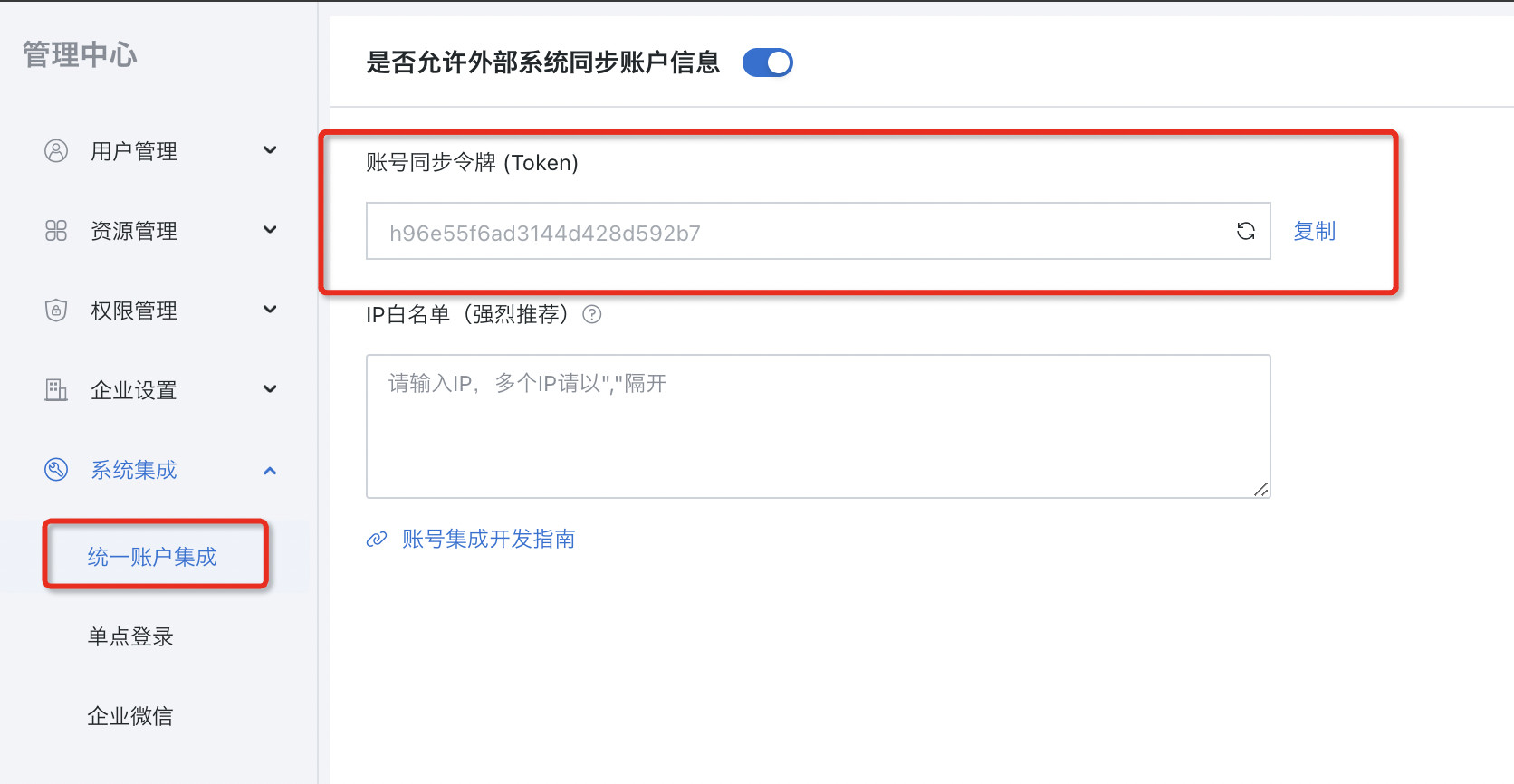
uIdToken参数为上一步接口生成的uIdToken;data的值是一个数据对象的Json Array
| 参数名 | 参数值说明 | Location | 类型 | 是否必填 | 备注 |
|---|---|---|---|---|---|
| dsId | 数据集ID | body | String | 否 | 需要设置数据行权限的数据集ID |
| dpId | 全局参数ID | body | String | 否 | 需要动态替换的全局参数ID |
| dpName | 全局参数名称 | body | String | 否 | 需要动态替换的全局参数名称 |
| value | 全局参数替换值 | body | String | 是 | 需要动态替换的全局参数值 |
data值示例如下,dpId和dpName2个参数二选一,推荐传dpId
[
{
"dsId": "k5652f88f33a4494abb7c97b",
"dpId": "w0288f3ba99274e92b71891a",
"dpName": "testDataset",
"value": "12345"
}
]
以下为curl或postman的请求示例,具体需要集成方后端实现
curl请求示例:
curl --location --request POST 'http://bi-server:9000/public-api/session/createOrUpdate' \
--header 'User-Agent: Apifox/1.0.0 (https://apifox.com)' \
--header 'Content-Type: application/json' \
--data-raw '{
"token": "h96e55f6ad3144d428d592b7",
"uIdToken": "eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJkZXZpY2VUeXBlIjoiUEMiLCJzdWIiOiIxLWpUUktIVSsxNlNTdlVYdmNsMkpEZFJEZmxPV0VON01Ob3pZTzc3WXdzZ0VzcHB5YmY4Vm9LR2poaEI1SHlXODh4QXZiK0dTMnZVTGFrTnFLaDlaMHF0Qy9HSnNIOU1Uam42OWVibUpjUlFzQTNSNXciLCJhdXRvTG9nb3V0T25DbG9zZUVuYWJsZWQiOmZhbHNlLCJpc3MiOiJndWFuZGF0YS5jb20iLCJleHAiOjE3Mjk5MDYxNzYsImlhdCI6MTcyODY5NjU3OCwiaW5pdFRpbWUiOiIyMDI0LTEwLTEyIDA5OjI5OjM2LjQwNiIsImp0aSI6IjNhODY5YjY0MzI0MGRmMzUzOTQzZGUwZmY5ZmUzMjk1OWIxYTY0NmNmYmIxNDI3NjI5YTU0NjAzOTk5OGI3ODRmZjVlYjFmMWVmMmJiZjViNDNmNmY0Y2ZjOGIwNTY4NzMzMTY0ODkwMGI0ZjZhMjJlN2MzNTYwMTA5NWY5ZjBhNmJiOTJiNjU1ZjAyYzM4YjYwZWU5YjdiOGZlMjA3YjdjM2MwMDRiYTMzZTgwYjNkYjQxZDNiNzBiMzZlMDJjYWU2OTA1MTI0NGQ1OWM2ZTY1OGY4YjYxZTA5NGNlZDJiOGFhYzBhODU4OTg1NDJhMmQ2NGIwYjQ4NTc2ZDNjYzIiLCJwd2RWZXJzaW9uIjowLjB9.oBIv_VDHbJaeHcLBRW83H6_Gj4hedE2356RvUqCMW6Q",
"bizType": "GLOBAL_PARAMETER",
"data": [
{
"dsId": "k5652f88f33a4494abb7c97b",
"dpId": "w0288f3ba99274e92b71891a",
"value": "12345"
}
]
}'
postman请求示例:
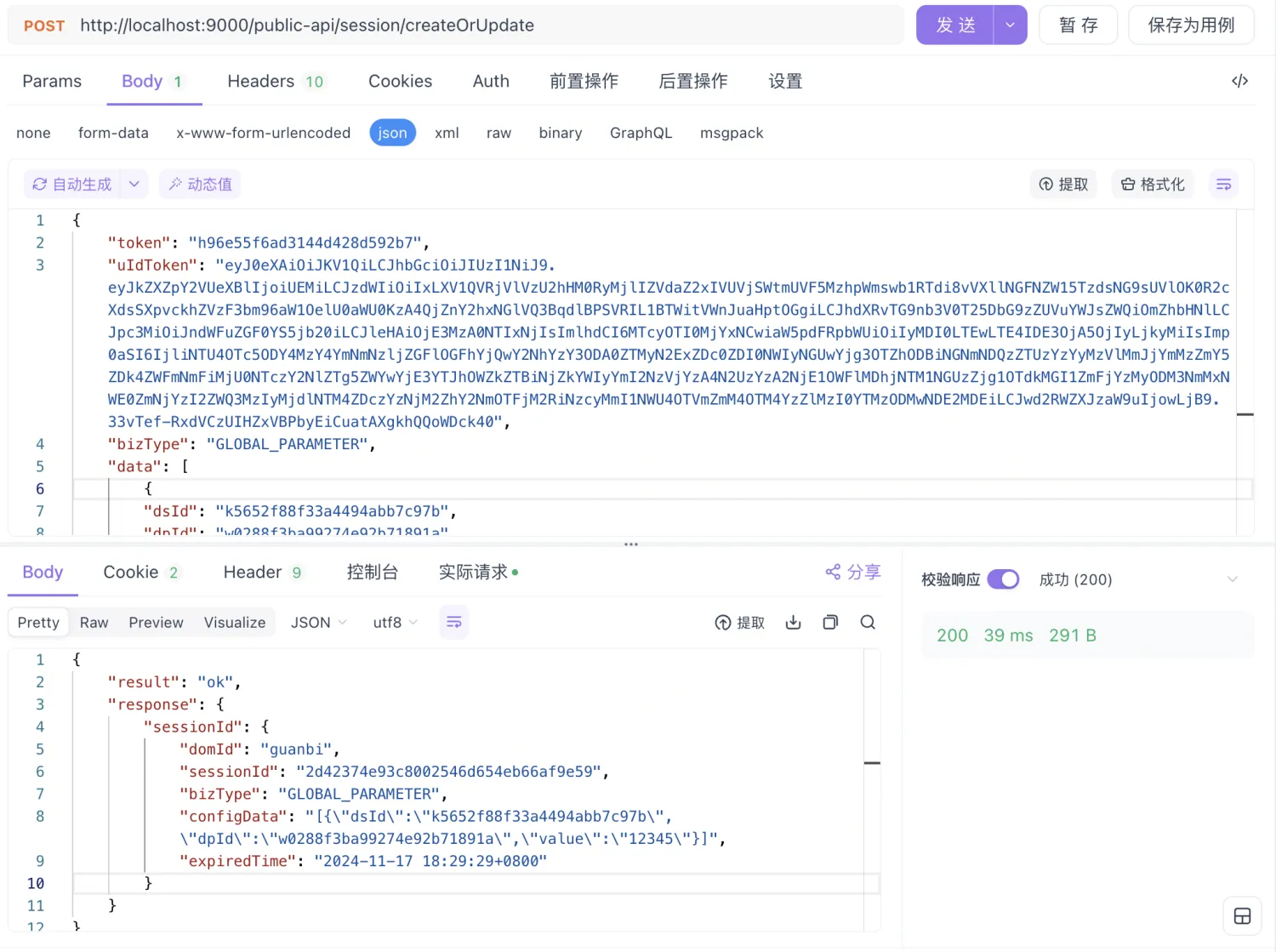
接口调用成功后,session即配置完成。该接口支持多次调用,第一次调用为创建session配置,后续调用为更新session配置。
参数优先级:session传的优先级最高,大于卡片上自己配置的/数据集自己配置的。
session传的全局参数值在BI上引用全局参数的地方均生效,包括视图数据集模型结构等场景。
4)将uIdToken种入浏览器Cookie 「集成方前端实现」
在内嵌系统中集成方前端在需要访问的 BI 页面链接后面增加参数:?loginToken={uIdToken},即可应用session配置,内嵌链接示例:http://domain/xxx?loginToken={uIdToken}