标准数据库连接指南
概述
观远数据提供从多种数据库进行数据接入的功能服务,支持 40+ 种标准数据库接入:包括但不限于MySQL、PostgreSQL、 Greenplum、 SQL Server、 Oracle、Presto、Amazon Redshift、MaxCompute、SAP HANA、Teradata、BW、TiDB、Doris、Vertica、Netsuite、ClickHouse、Hive、IBM DB2、HAWQ、AnalyticDB、Gbase 8t、Informix、Kylin、Impala、Sybase、MangoDB、Druid、Trino、DAMENG、Snowflake、StarRocks、CirroData、Access等。
本文为您介绍如何将标准数据库接入 BI 。
整体流程
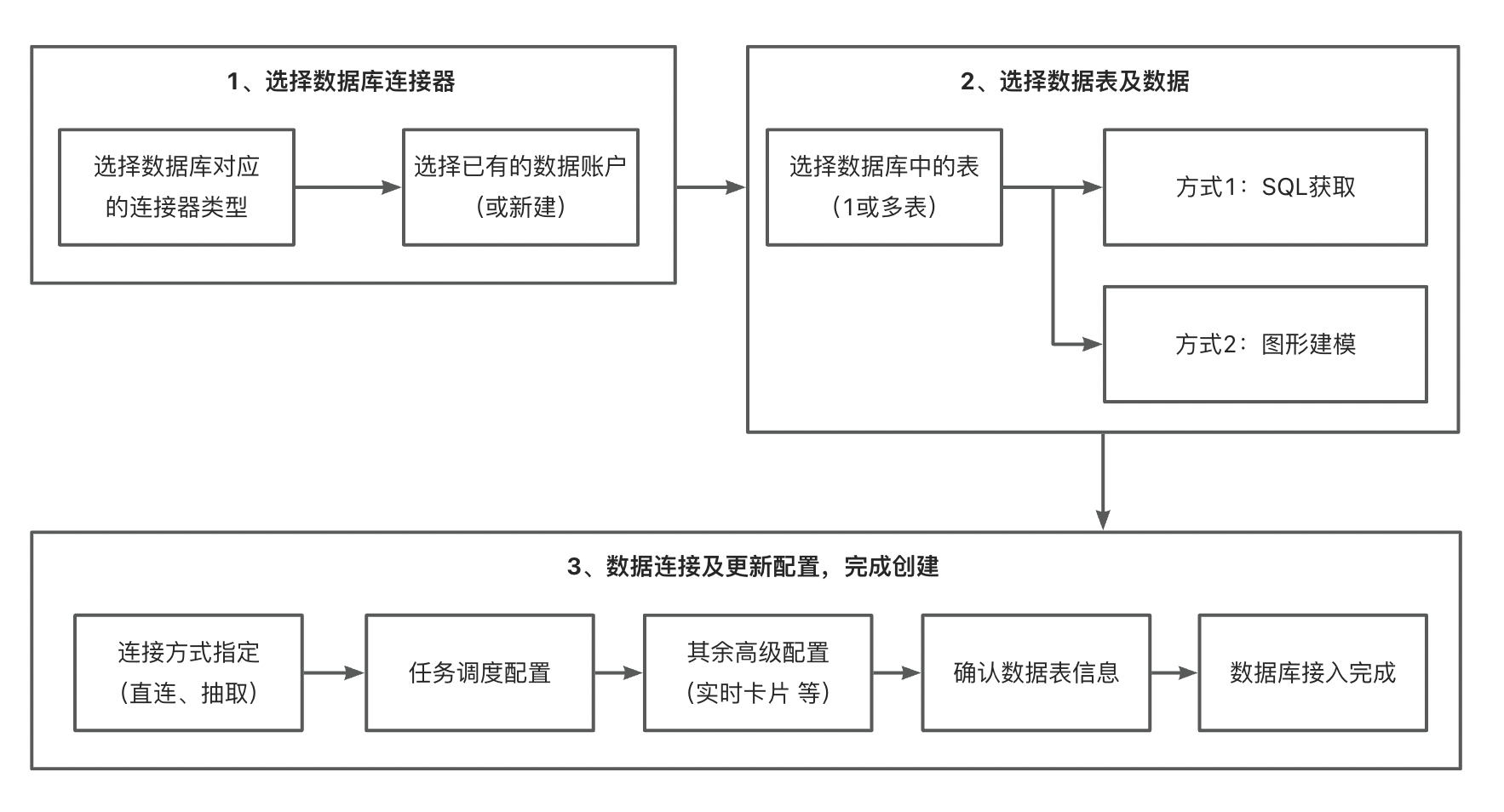
操作步骤
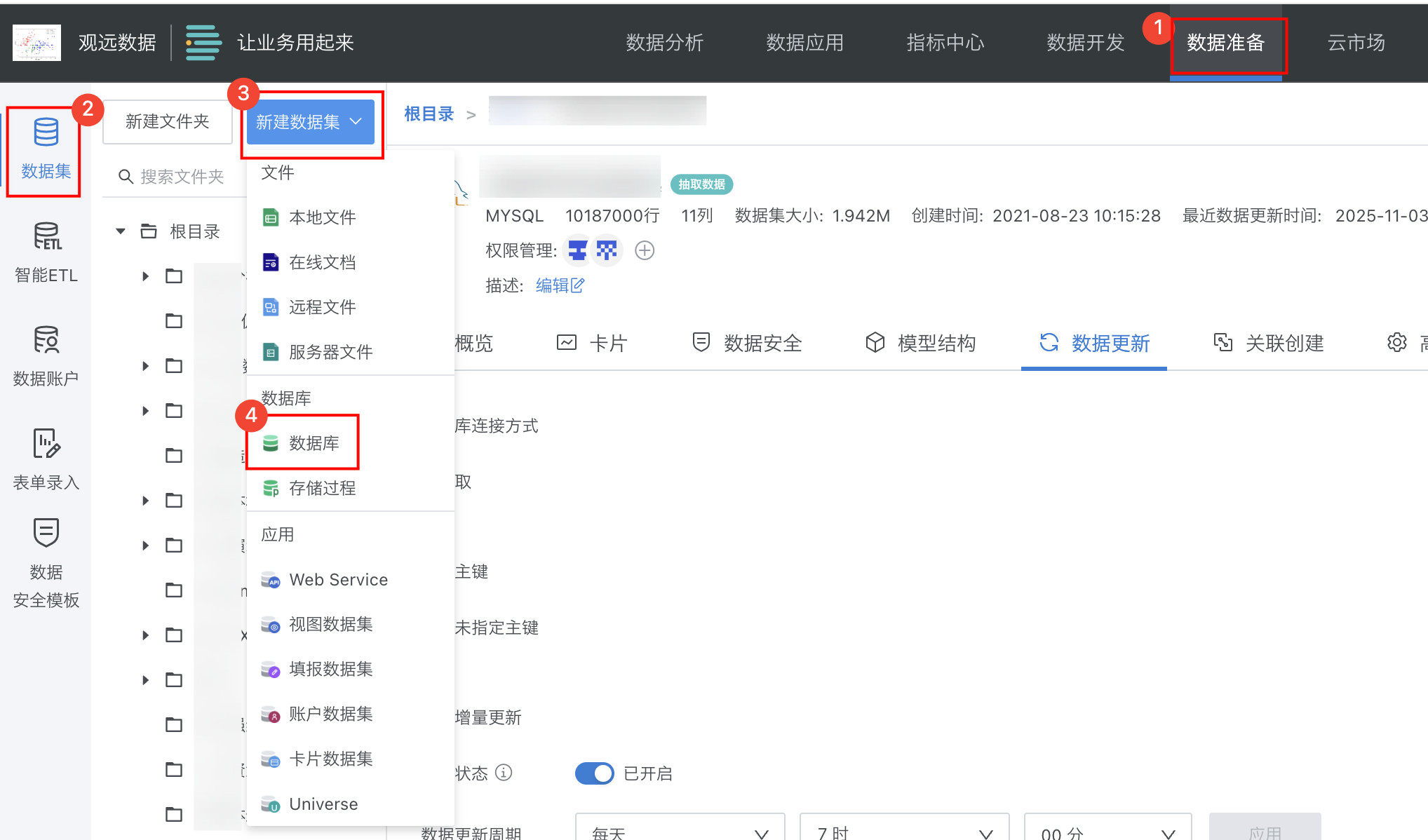
入口:数据准备 > 数据集 > 新建数据集 > 数据库
选择数据账户及数据表
选择「单个创建」,并选择或新建一个数据库账户,详情请参阅数据账户。
在数据连接的配置过程中,观远 BI 支持用户对数据库中的一张或多张表进行 SQL 查询和图形建模两种操作模式。
-
SQL 查询:面向 IT 或技术人员开放的传统查询方式,用户可以对数据库中的一张或多张表进行复杂的 SQL 查询操作。
-
图形建模:面向业务人员的界面化操作方式。通过图形化界面,用户可以进行表间的操作,降低了数据对接的复杂性和操作门槛,使非技术人员也能方便地进行数据建模。
- 目前仅MySQL与Impala两种数据库,支持图形建模操作。
- 由于MongoDB、SAP BW数据库的数据结构和查询特性有所不同,因此在接入观远 BI 的选择数据表时,配置流程会相应地有所差异。建议用户参考MongoDB_SAP BW连接指南。
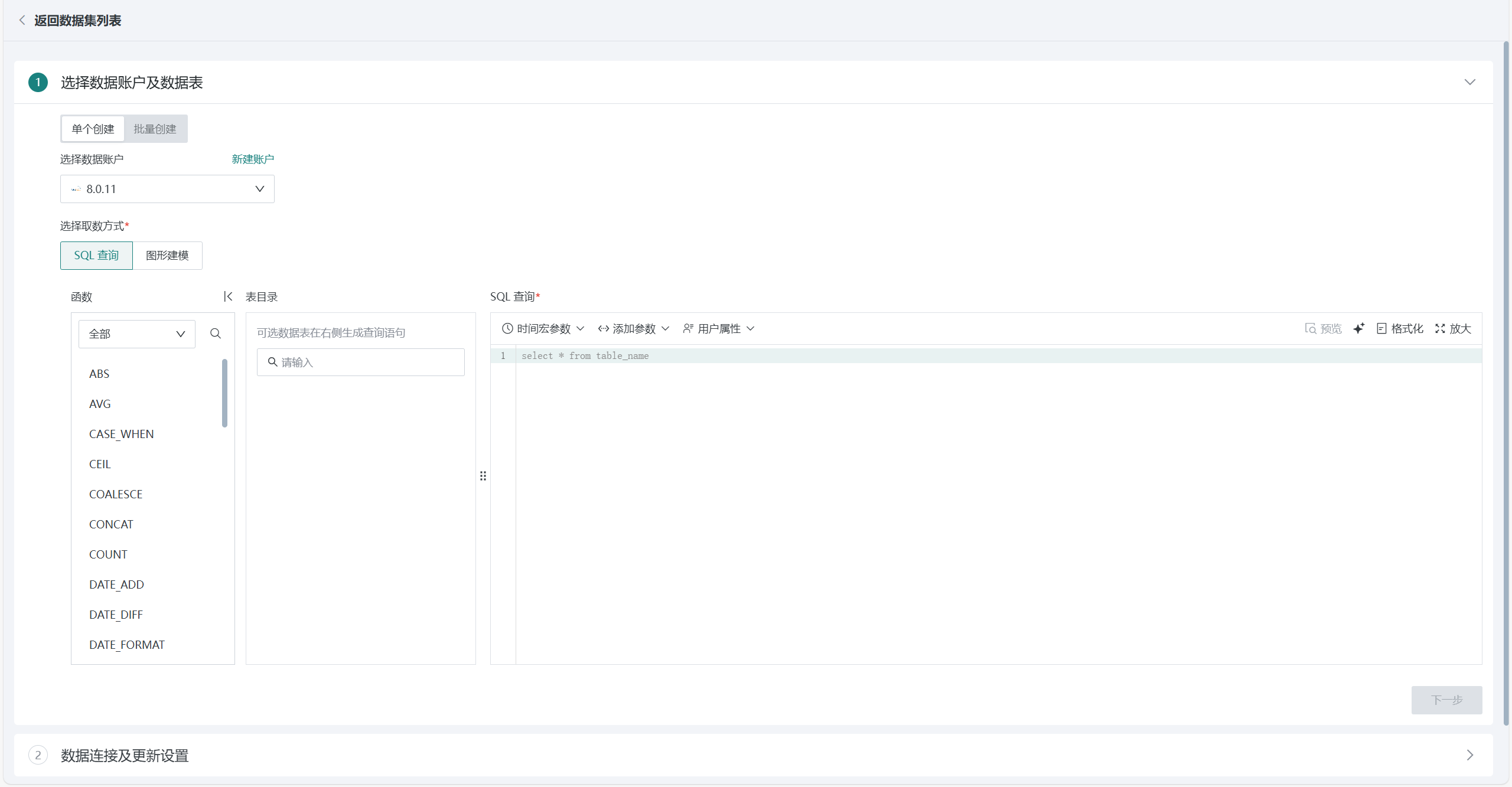
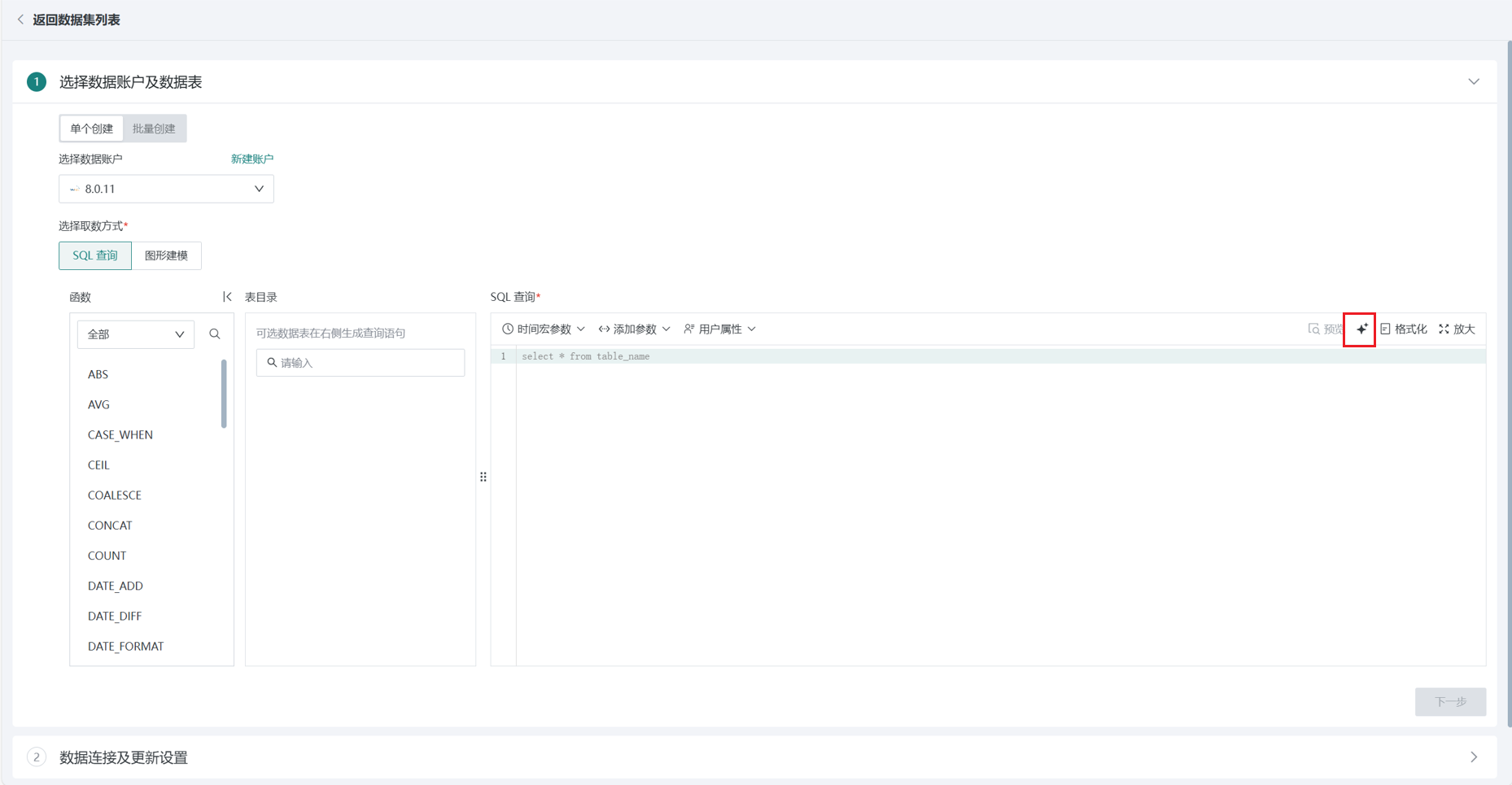
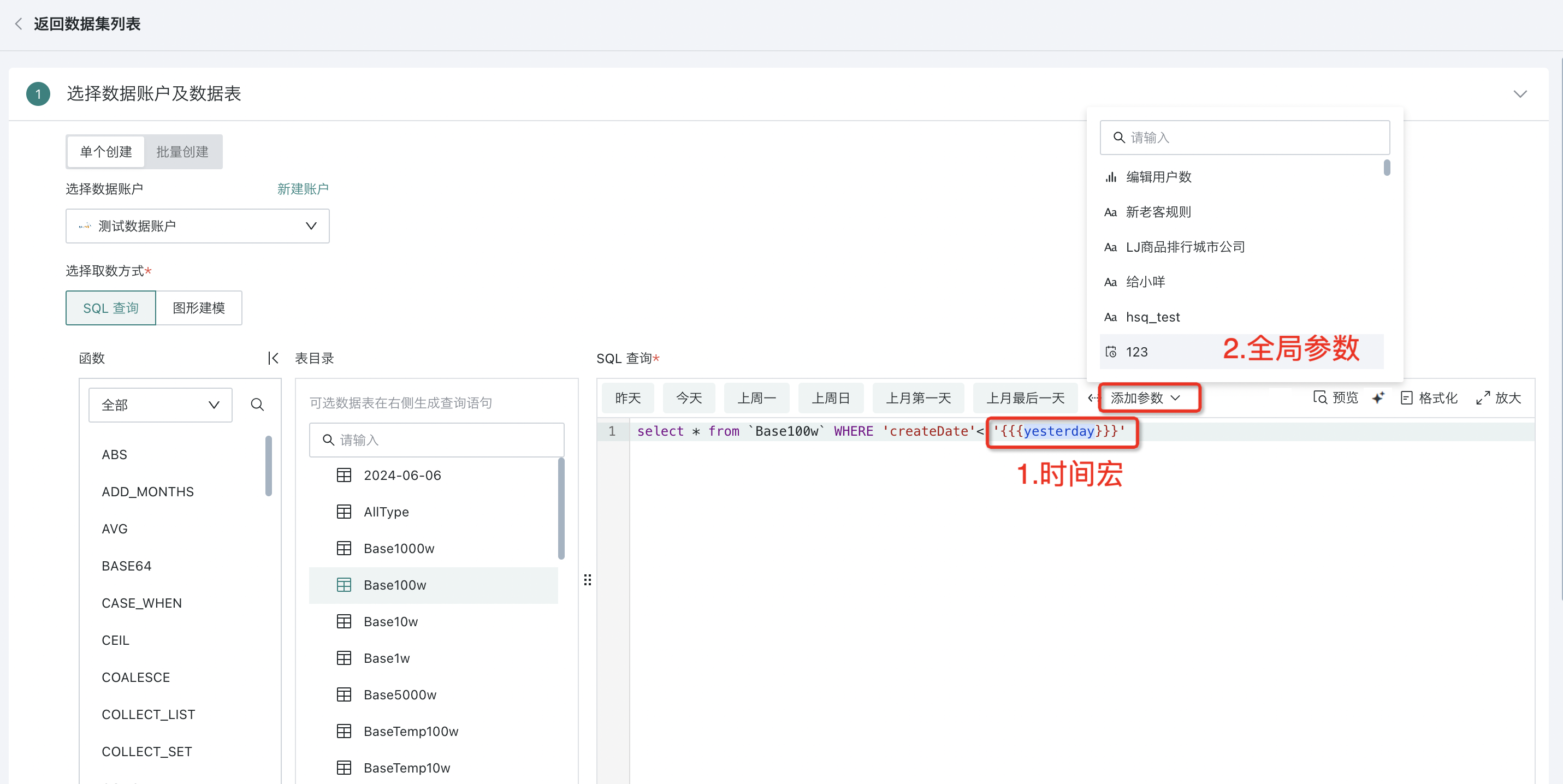
SQL 查询
在左侧的数据库表目录中选择一个或多个表,在右侧编辑区中进行 SQL 输入完成数据的指定获取。
并且,在数据表配置过程中,支持引入时间宏参数、全局参数、用户属性等。在实际计算时会将动态参数的值带入到查询语句中,实现复杂的数据分析维度切换和灵活查询,不需要每次查询时手动修改参数。
「用户属性」仅支持直连数据集,抽取数据集若使用该参数会报错。 引用用户属性创建的直连数据集,用于卡片查询时,取当前访问用户的用户属性进行计算。
例如,时间宏参数场景下,可帮助用户根据当前日期生成动态SQL,为数据的更新和动态分析设置时间范围要求,实现定时刷新数据与增量更新,输入:
select date, cost, revenue from table_name where date >='{{{yesterday}}}'
可点击右侧「智能编码」 AI 小图标,通过 AI 自动生成符合内容的 SQL,如何使用详见AI 助手。
图形建模
图形建模,是观远数据为了降低数据对接过程中的操作门槛,方便非技术同事也能更快更好进行数据连接工作,而提供的进行表和表之间关联操作的功能。在创建数据集的开始,选择MySQL或Impala后,即可在数据库查询环节,选择「图形建模」方式。
目前仅MySQL与Impala两种数据库,支持图形建模操作。
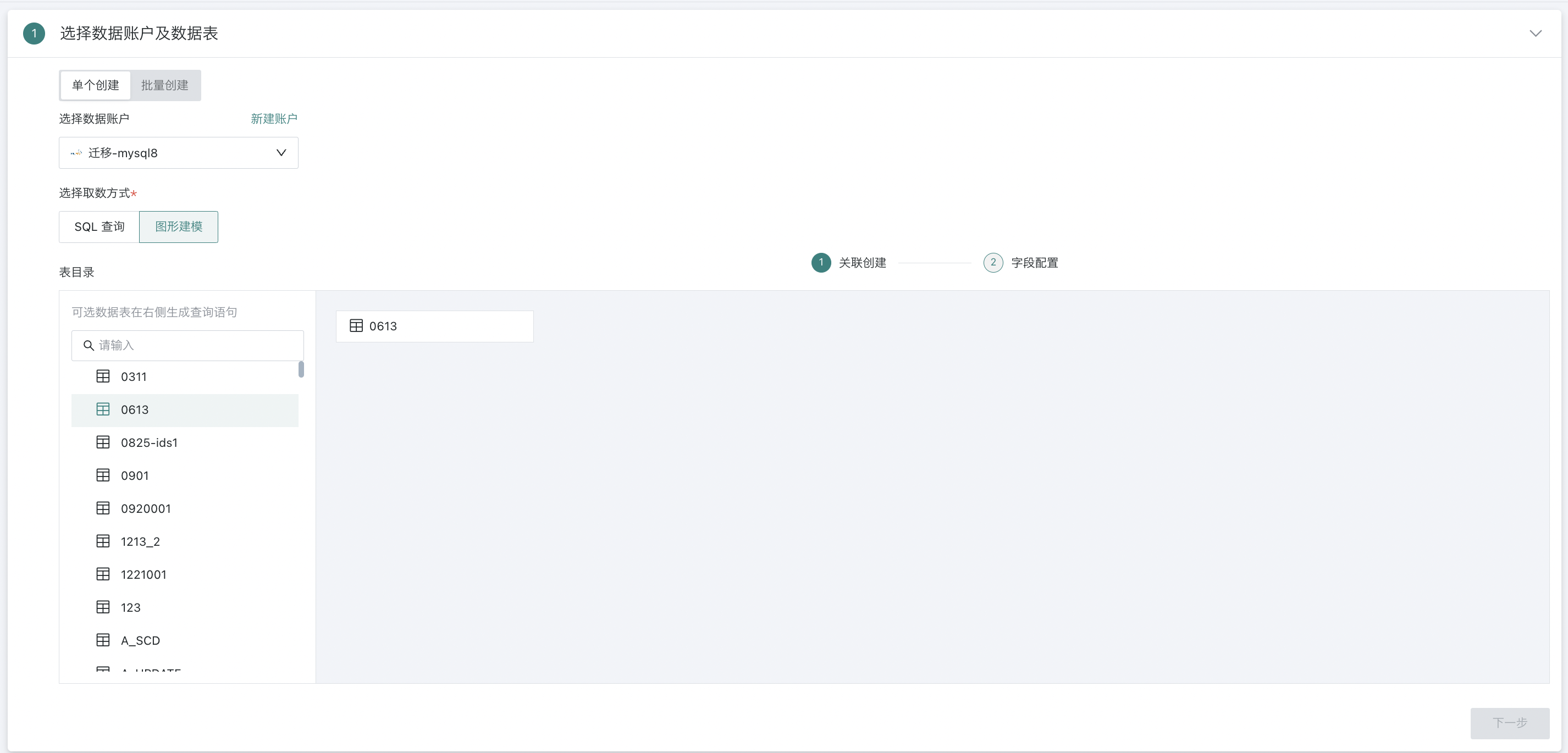
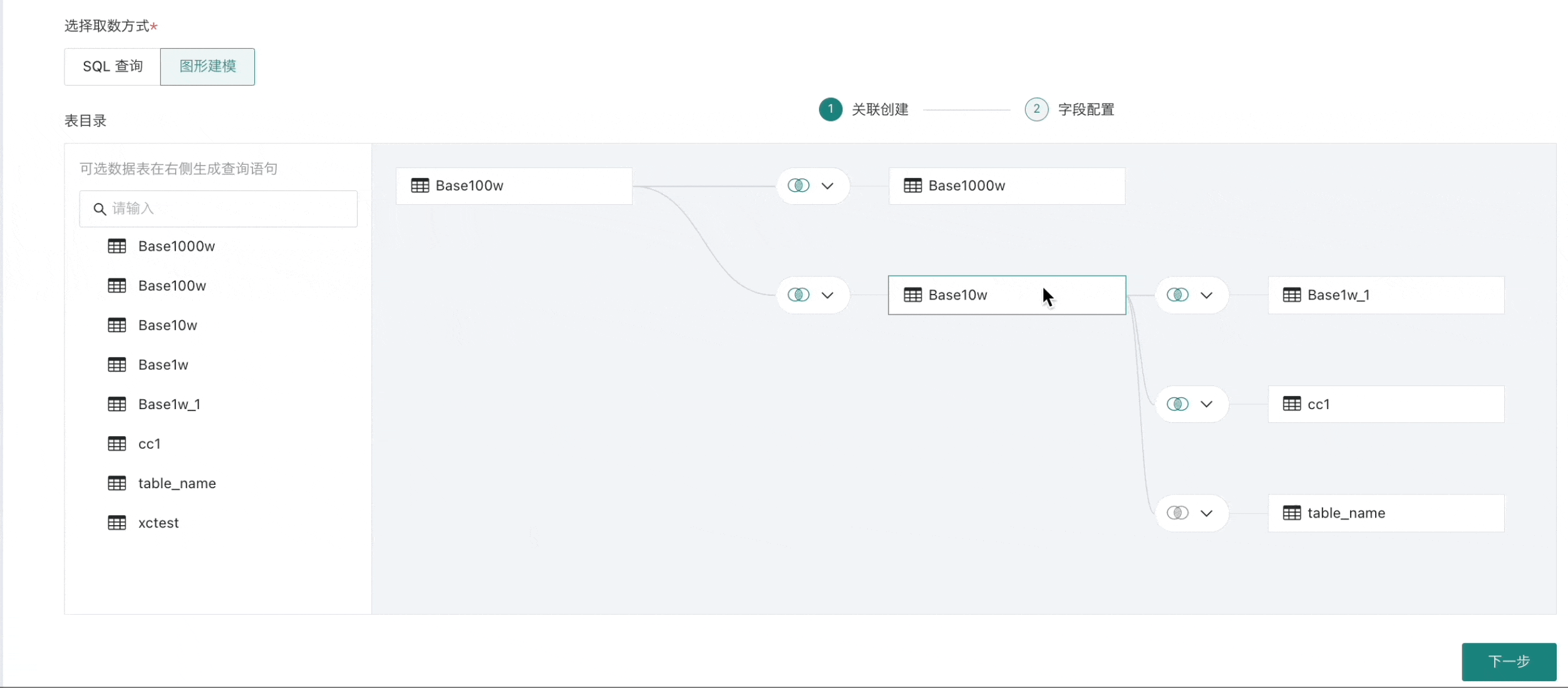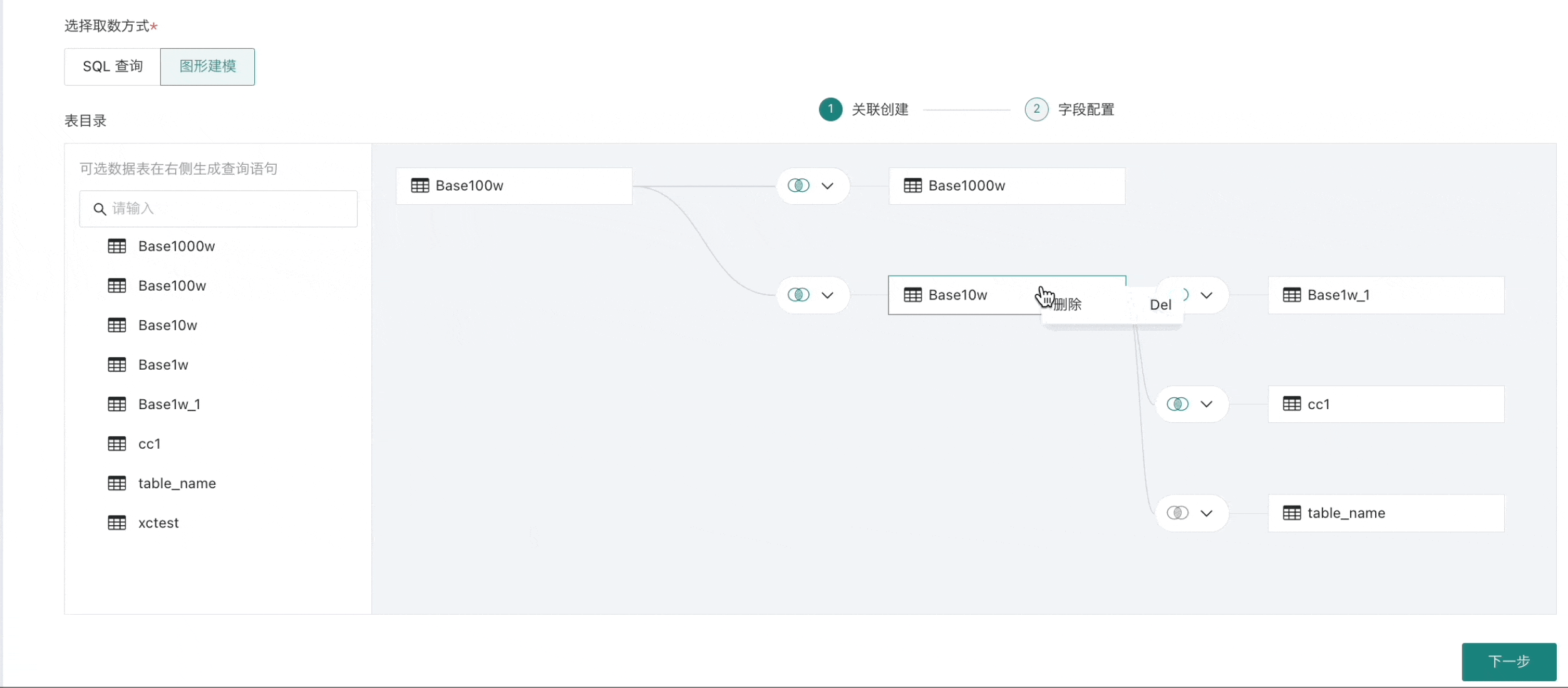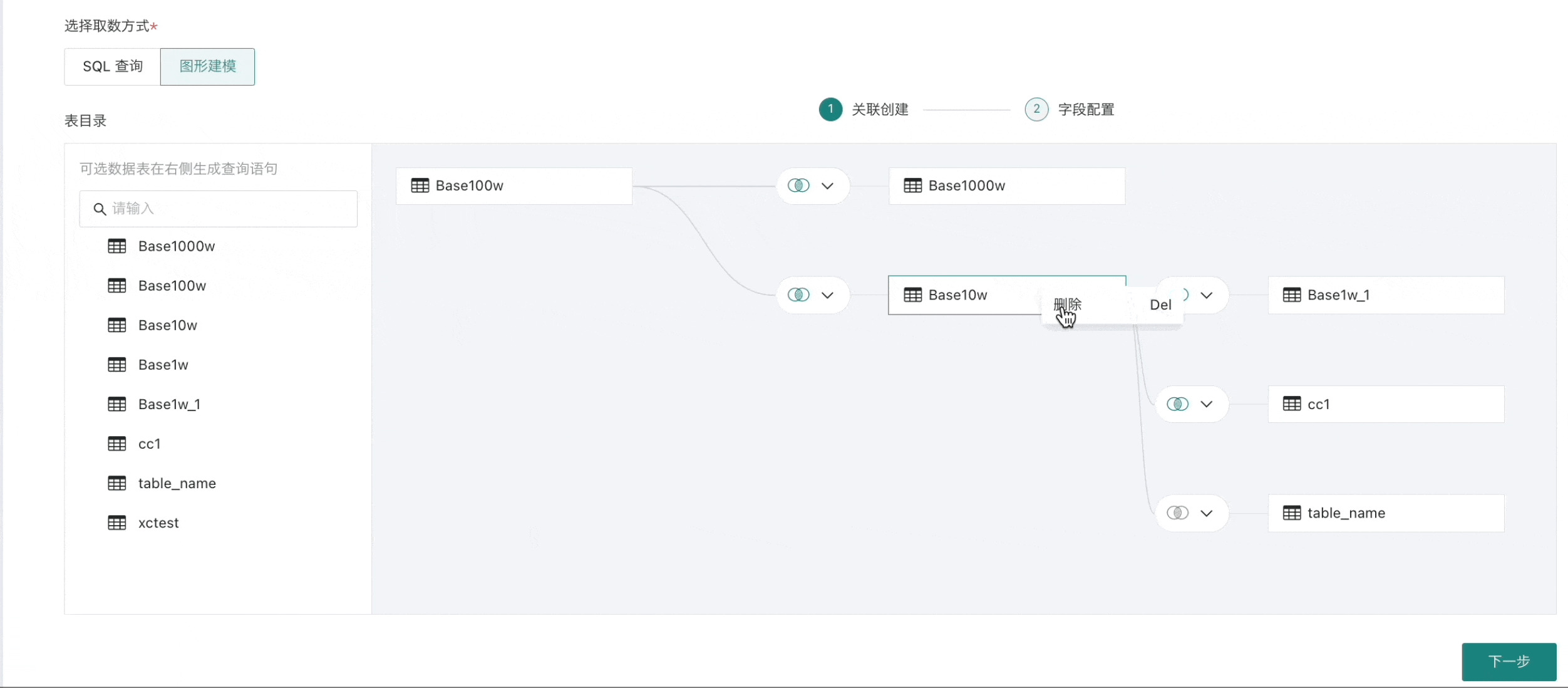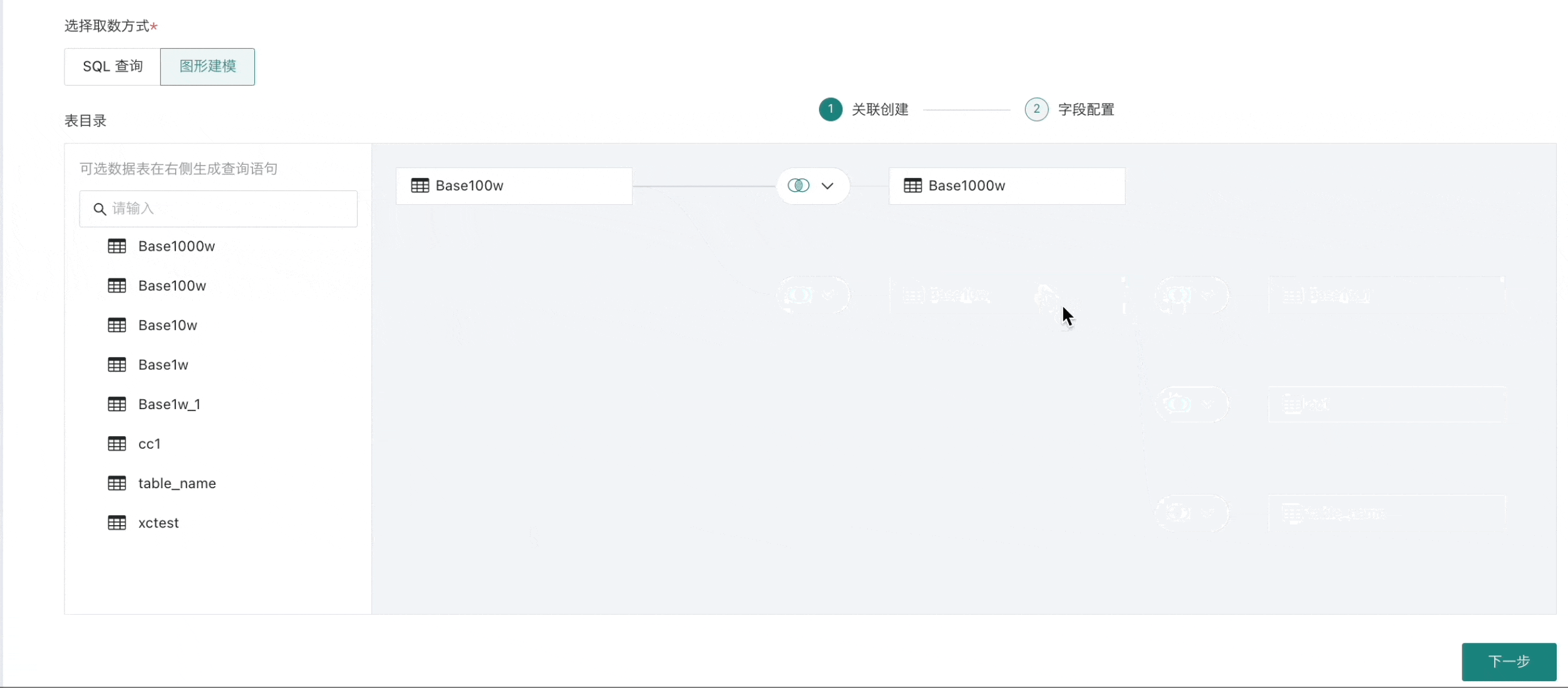
关联创建
针对已创建的数据集,在修改模型结构时,也支持图形建模方式,操作方式不变,具体如下:
-
在左侧数据库表目录中,将一个或多个数据表拖拽至「关联创建」画布中。
-
选择一张数据表时,可直接进入字段配置步骤,完成一个或多个字段的勾选后,预览查看效果。
-
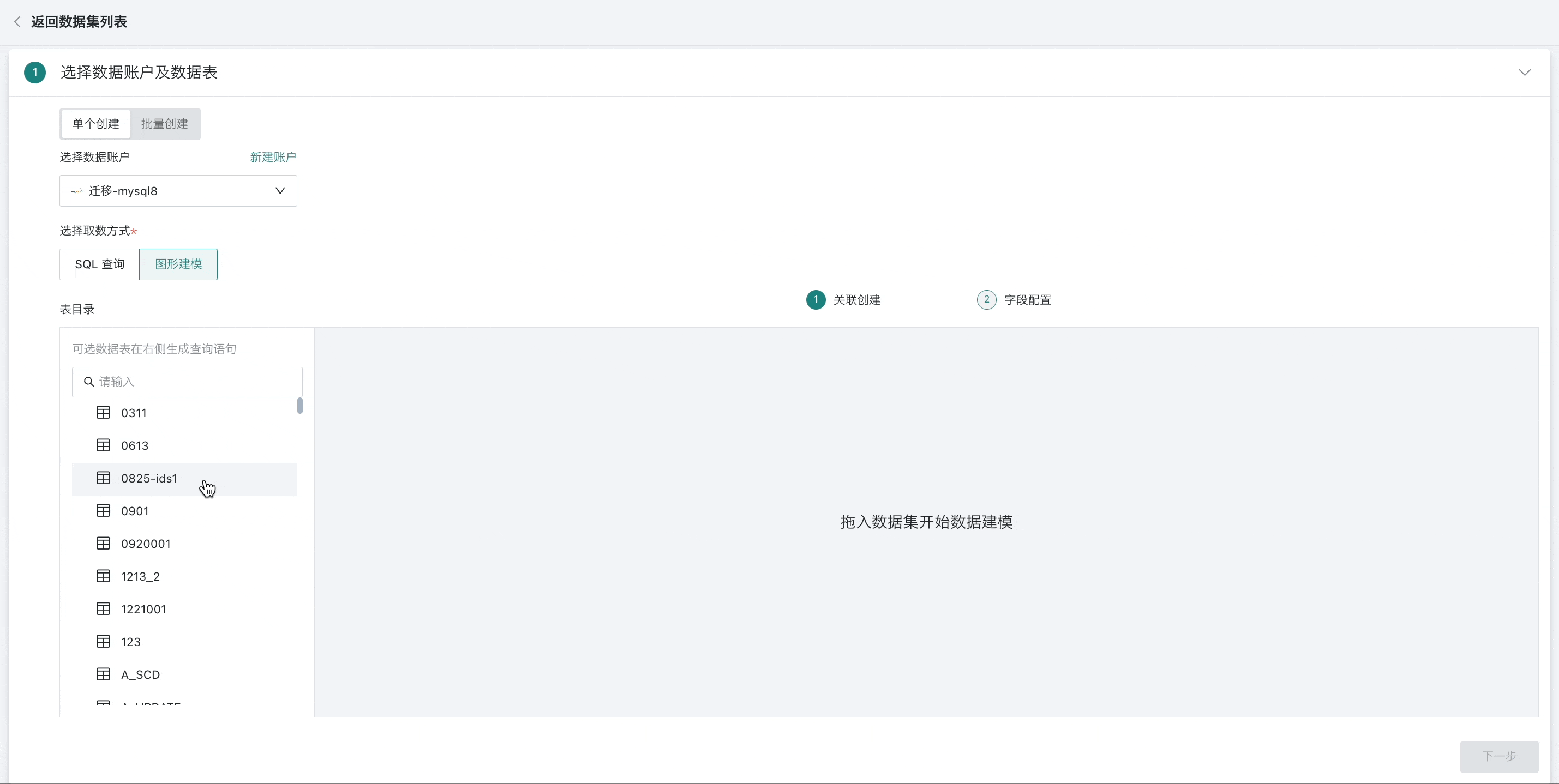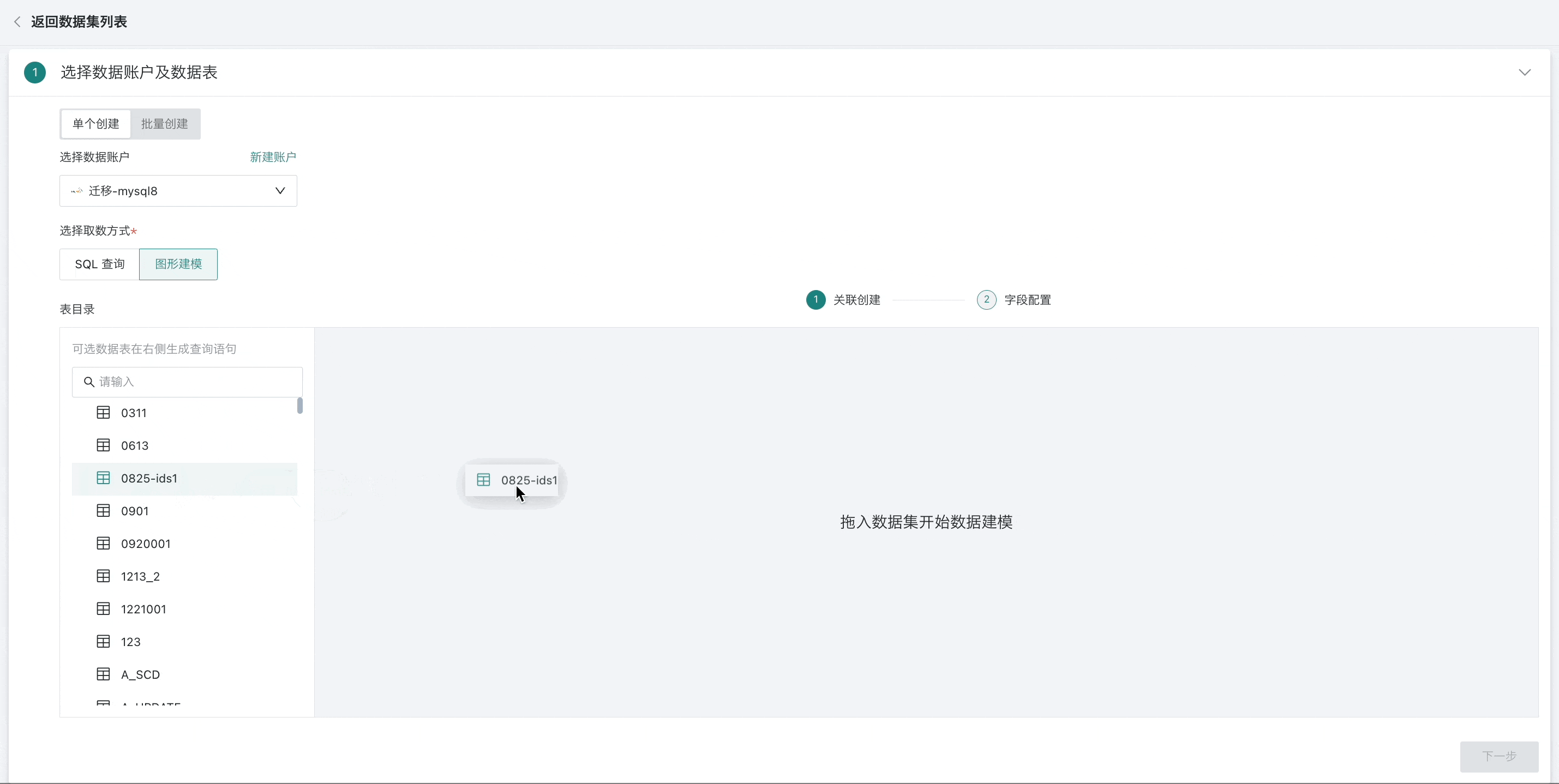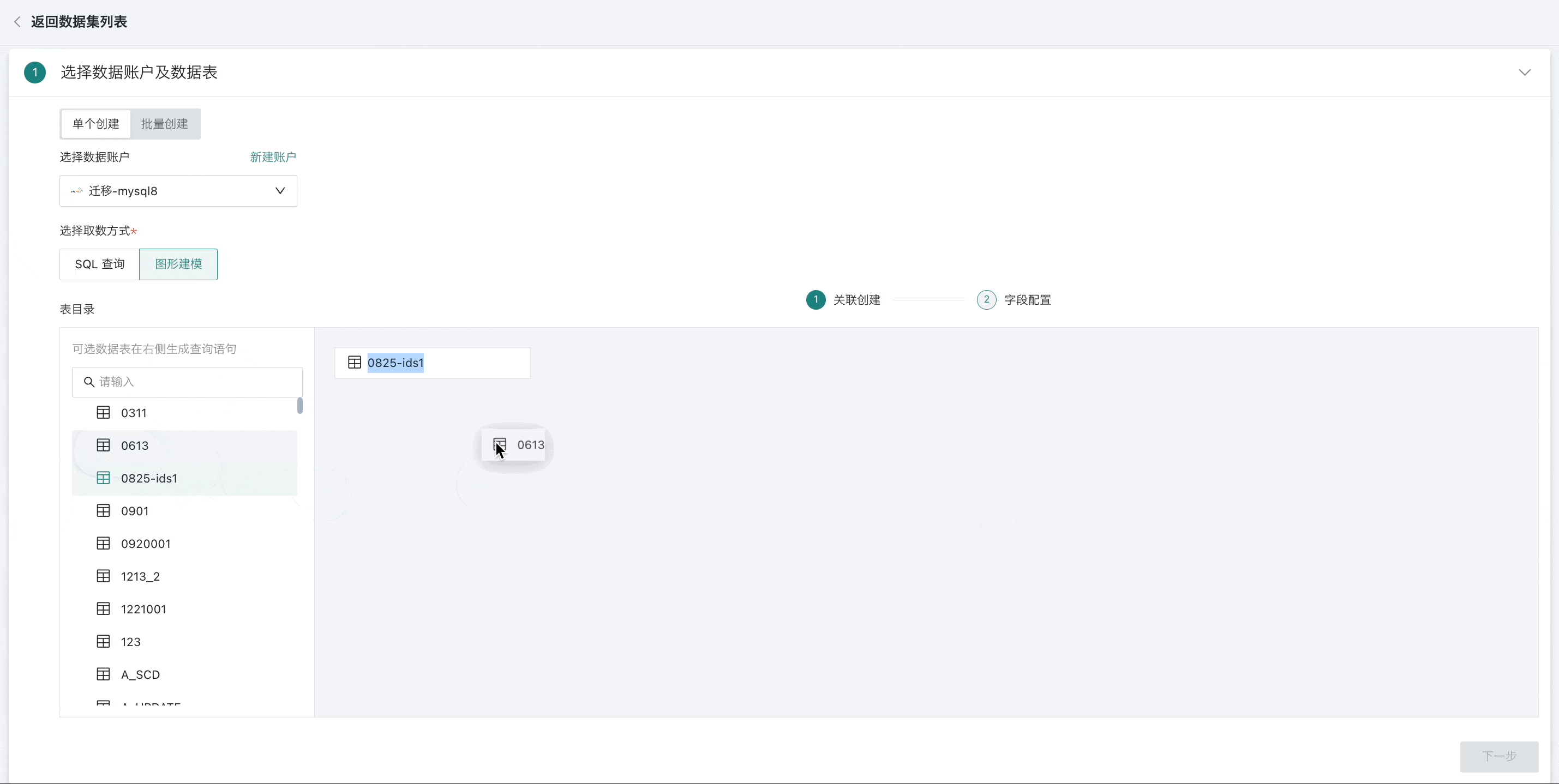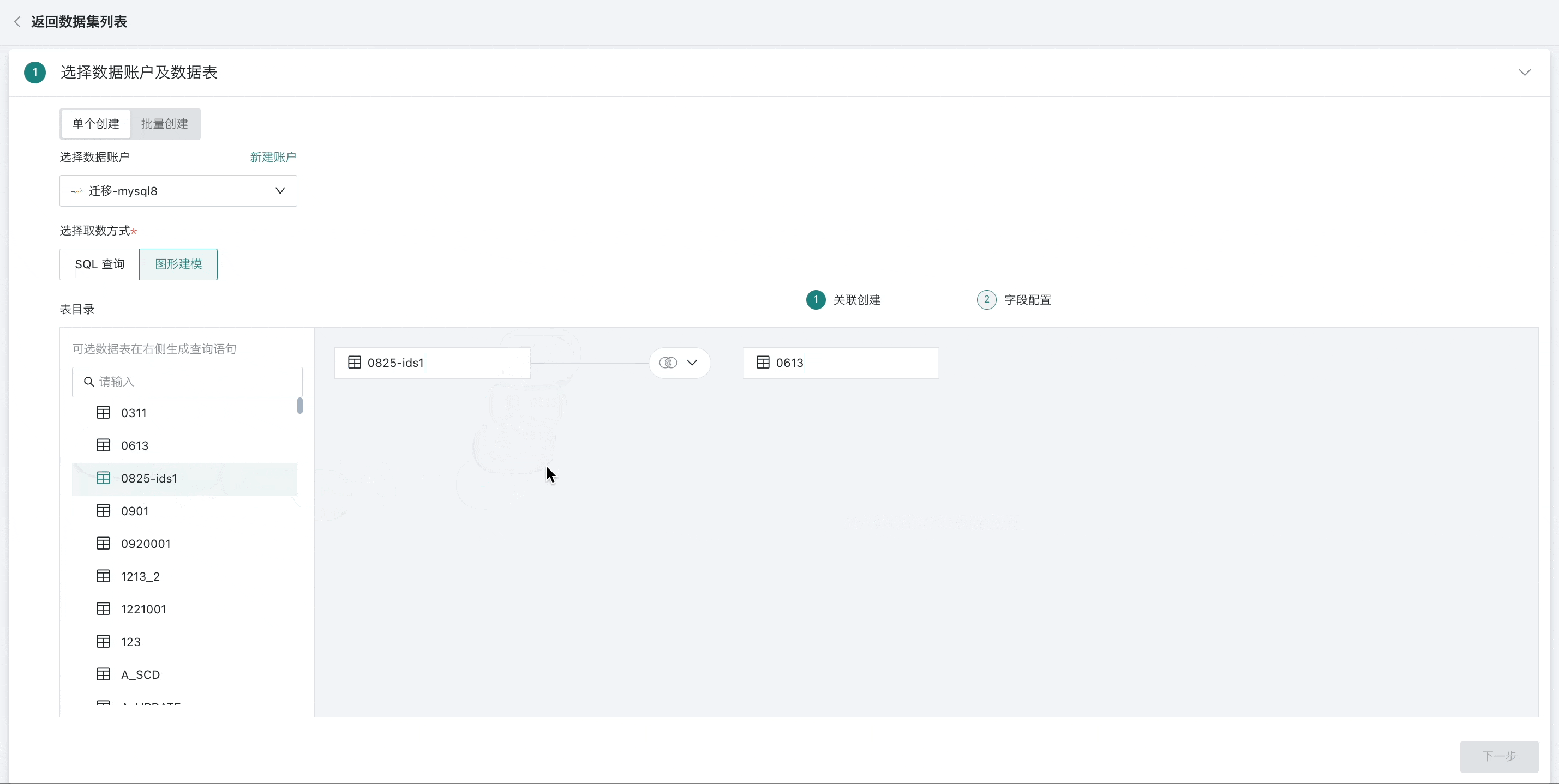
选择多张数据表时,需要将后一个数据表拖至前一个数据表末尾,通过表关联或者行拼接成一张数据宽表;
-
-
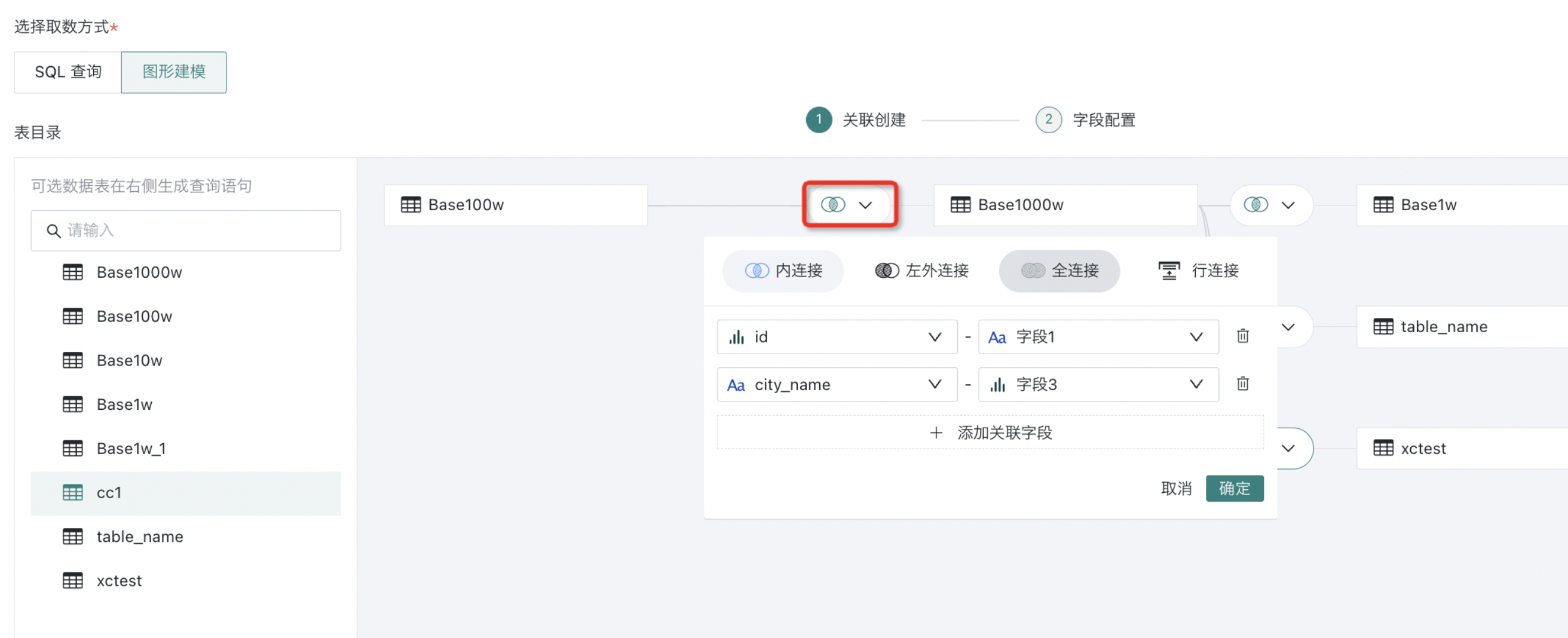
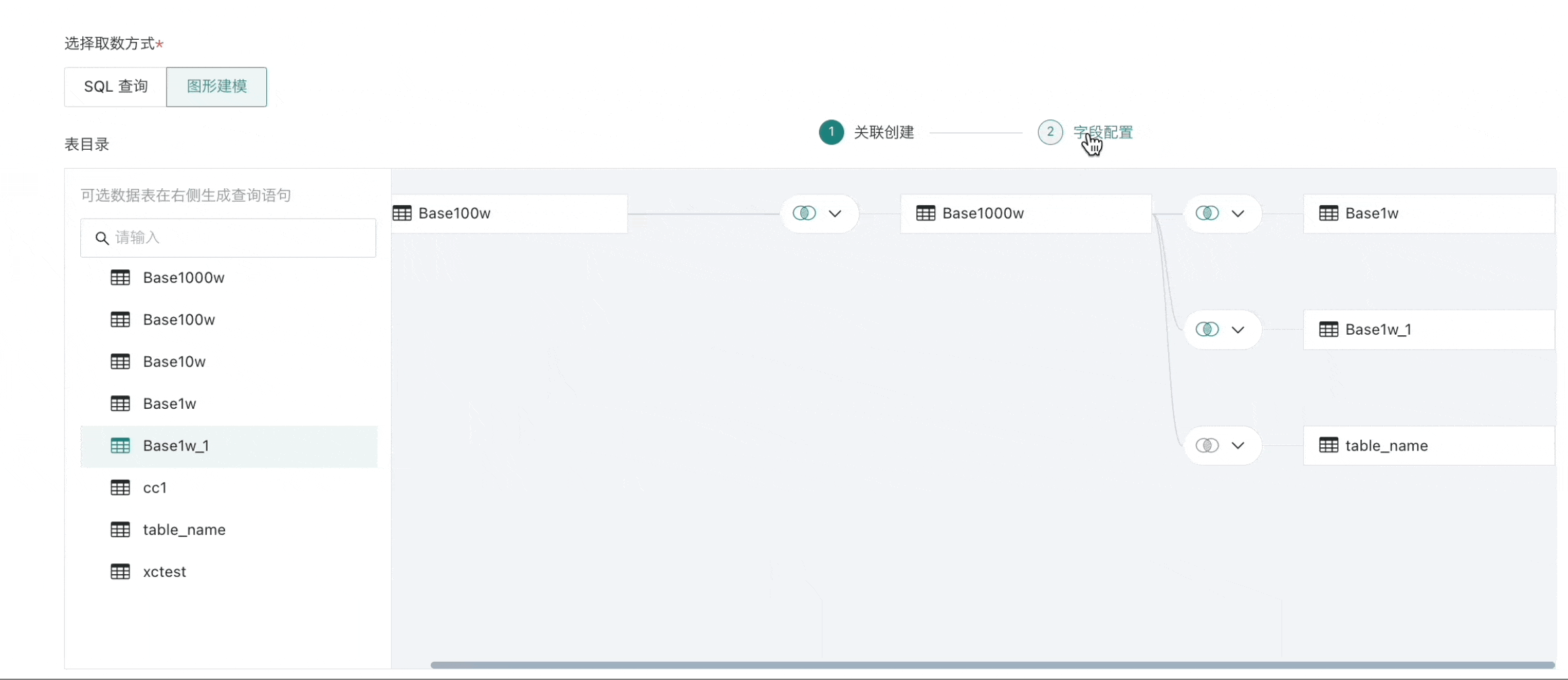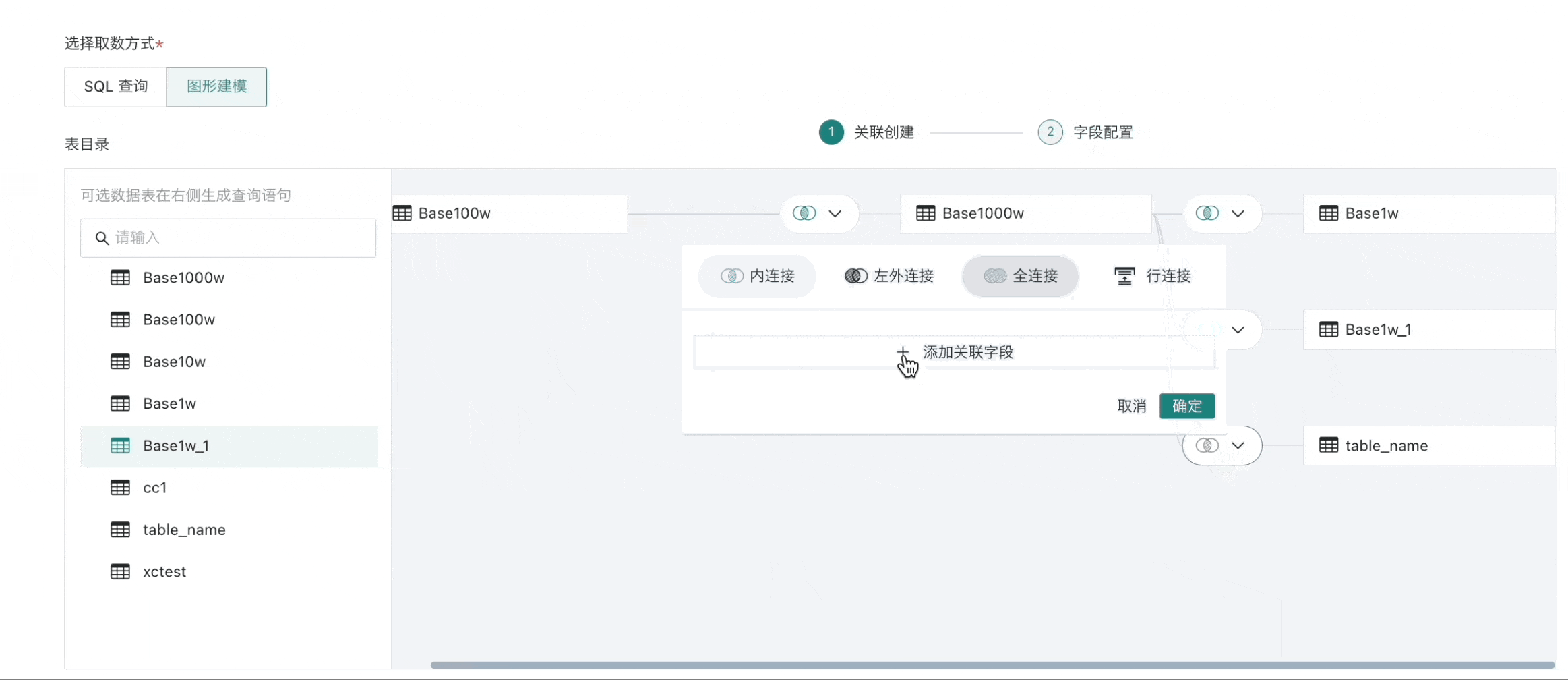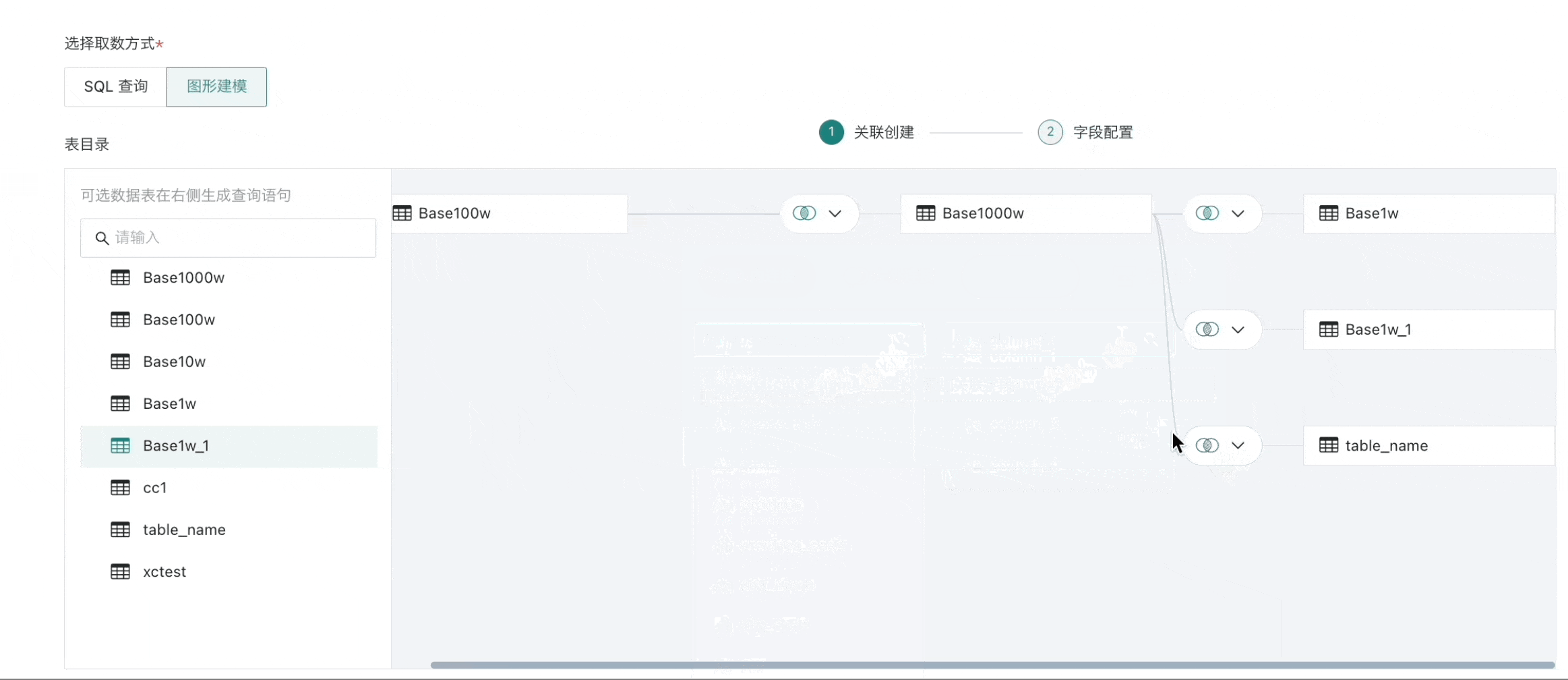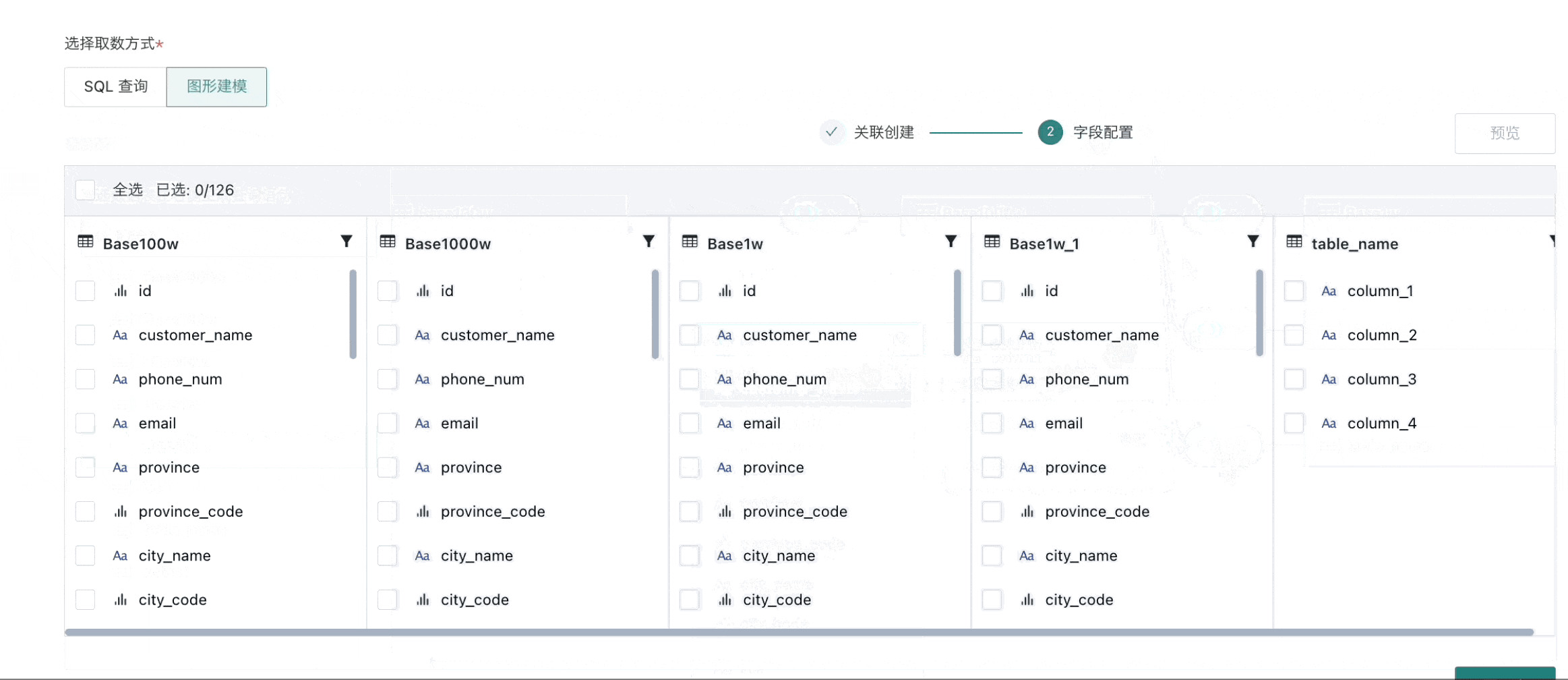
拖入多张表时,表和表间支持内连接(默认)、左外连接、全连接以及行拼接等四种操作,并按需设置关联字段。
说明- 支持的操作会协同数据库本身,如MySQL本身不支持全连接,在图形建模的关联创建中也不支持全连接。
- 若两张表存在同名字段,会优先自动将同名字段作为外键进行关联;
- 用户也可通过手动方式增减以及设置关联条件。
当不再需要当前数据集时,在当前节点右键唤起删除操作,点击「删除」即可。
注意此操作将同时移除所有子节点,请谨慎处理。
-
需要设置完成所有关联关系,才可以进入到第二步「字段配置」;
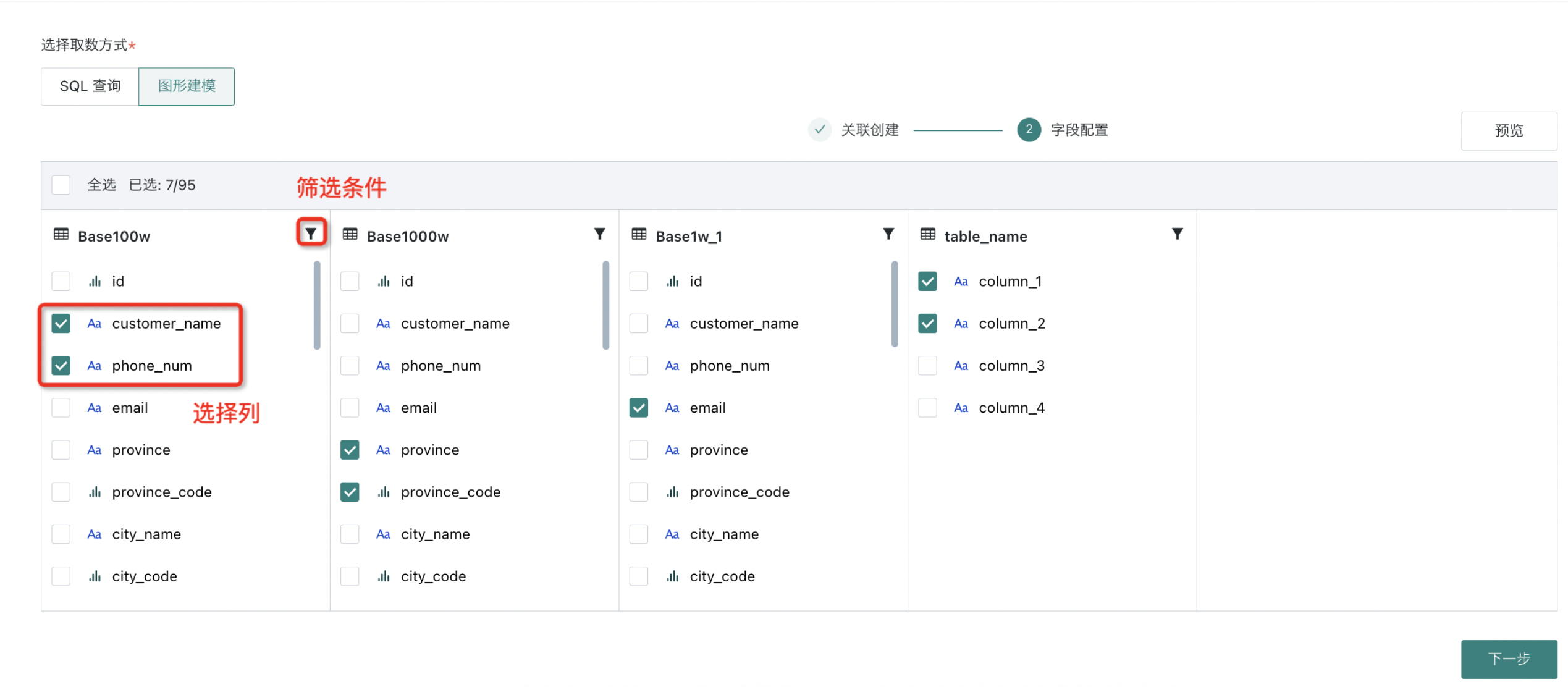
字段配置
-
完成关联创建后,进入到字段配置,进行选择列以及条件筛选环节;
-
预览数据集无问题后,可进入下一步操作。
数据连接及更新配置
通用配置
数据库连接方式
| 连接方式 | 说明 | 适用场景 |
|---|---|---|
| 直连 | 直接连接用户数据库进行数据的查询和计算,BI获取数据库返回结果做可视化展现。 | 企业出于数据安全考虑,禁止数据落地到其他系统;业务数据频繁变化,又要求看到实时最新的数据;数据量大且客户本身的数据库查询性能较好。 |
| 抽取 | 数据需要抽取保存到 观远BI 中进行计算,抽取分全量/增量抽取。 | 客户无数据中台/数仓,基于观远BI搭建轻量级数仓 |
调度状态
调度状态控制了数据集是否按照预设的更新策略自动进行更新,当调度开启时,系统将根据配置自动触发数据集的更新过程;
而当调度关闭时,系统将停止自动更新,但用户仍可通过其他方式(如手动更新或URL触发)来更新数据集。不受调度状态(开启或关闭)的影响,如可以通过观远BI的用户界面手动点击更新按钮来立即更新数据集,或者通过向系统发送一个包含特定参数的URL请求来触发更新过程。
直连配置
缓存有效周期
在直连模式下,设置缓存有效周期可以优化查询性能,减少数据库负担,同时确保用户获取到的是相对较新的数据。
- 为减轻数据库压力,相同查询SQL会优先使用缓存,缓存可设置有效周期。
- 当缓存过期时,系统会重新从数据库查询数据并更新缓存。
举例: 缓存有效周期设置每天10点,则昨天10点后第一次访问卡片生成的查询缓存,有效期到今天10点,期间对该卡片的相同查询会使用同一份缓存。同理,今天10点以后再次访问该卡片,会在数据库重新查询并生成新的缓存,有效期到明天10点。
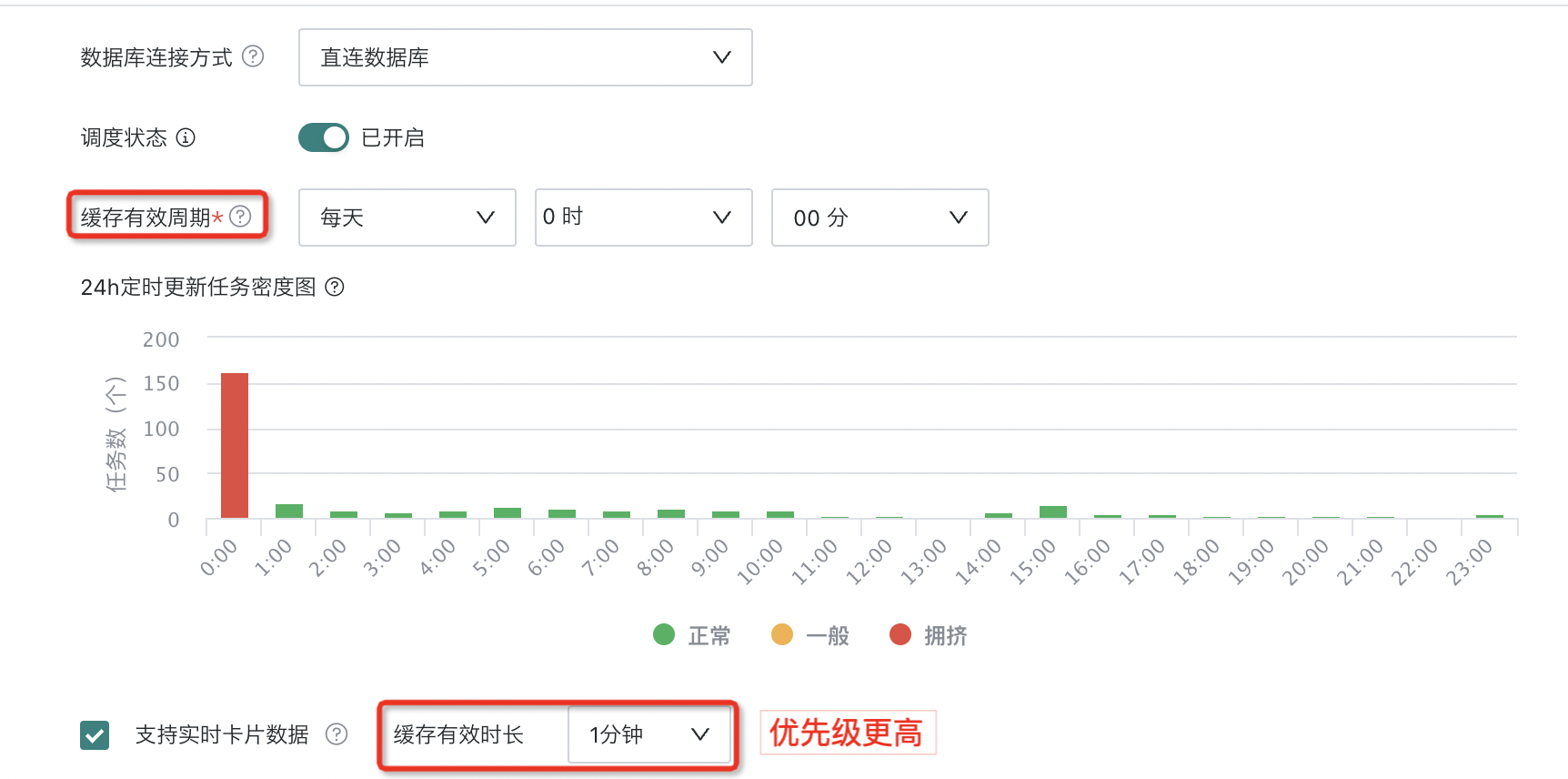
实时卡片数据/缓存有效时长
为满足对实时性分析的诉求,观远 BI 支持基于数据集创建的可视化看板/卡片提供实时刷新功能。该功能通过「实时卡片数据/缓存有效时长」配置项来实现,允许用户精细控制数据的更新频率,以满足不同业务场景的看数需求。默认情况下,实时卡片数据的更新周期被设置为1分钟 ~ 30 分钟,或无缓存模式。
例如,设置 1 分钟时,意味着每过一分钟,相关卡片就会自动从数据源获取最新数据并更新显示,确保用户看到的是最新的近实时数据。
- 依赖配置:为达到在仪表板/数据大屏上数据实时刷新的效果,不仅需勾选此项,还需同时将相关仪表板/数据大屏上的「自动刷新」开关打开;只有当这两个条件同时满足时,用户才能在仪表板或数据大屏上看到持续、实时更新的数据。
- 优先级:实时卡片数据中的「缓存有效时长」配置后,优先级>上面的缓存有效周期。
抽取配置
数据更新周期
在抽取模式下,数据更新周期直接关联到定时抽取任务的触发时间。用户可以根据业务需求设置定时任务,指定在何时(如每天凌晨、每周一等)触发数据抽取过程。抽取可以是全量抽取,也可以是增量抽取,具体取决于数据的变动情况和业务需求。通过设置抽取任务的触发时间,用户可以灵活地控制数据的更新频率,确保数据集中的数据保持最新状态。
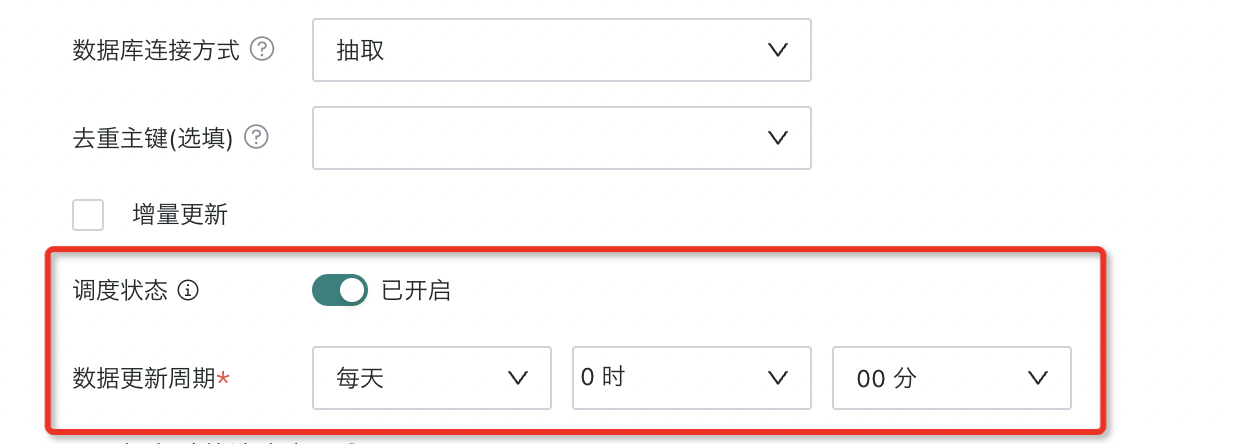
单个数据集一天内不能更新超过4次。
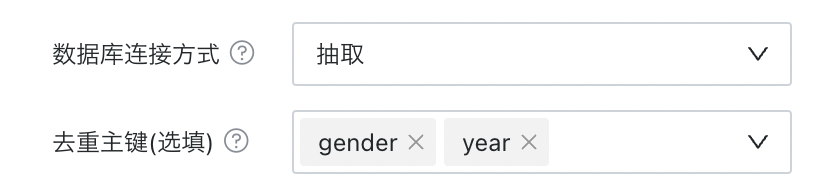
去重主键
「去重主键」可以理解为利用表的主键来防止或去除数据库中的重复数据(重复的记录或某行),保证表中每行数据的唯一性,避免因重复记录导致数据分析误差和结果不准确。其配置主要涉及到主键的定义、去重策略:
主键定义:是数据库表中能够唯一确定一个行数据的字段(或索引),它保证了表中每行数据的唯一性。
去重策略:可配置一个或多个字段作为去重的依据。
- 类似概念在智能 ETL 中的「数据去重算子」中有涉及,可参考学习数据去重。
- 在进行去重操作时,需要仔细选择去重的字段,以确保不会误删重要数据。
- 对于大数据量的表,去重操作可能会消耗较多的计算资源和时间,因此需要谨慎处理。
全量更新/增量更新
观远BI在数据抽取与更新的过程中,支持全量更新与增量更新两种模式。
默认情况下,若不勾选增量更新选项,系统将自动执行全量更新。以下是对这两种更新模式的详细说明及适用场景,帮助用户根据具体需求和业务场景做出最佳选择,以确保数据的准确性和处理效率。
| 类型 | 说明 | 适用场景 |
| 全量更新 | 全量更新是指将数据源中的全部数据抽入观远 BI 中,覆盖之前已存在的数据集数据。 | 适用于数据表结构发生变化、需要重置数据或进行大规模数据迁移等场景。 |
| 增量更新 | 按照设定的主键,将获取的增量数据更新或插入到数据集中。 | 适用于频繁更新或数据量比较大的表。如:数据源表频繁发生数据变动,如实时交易数据、用户行为日志等 |
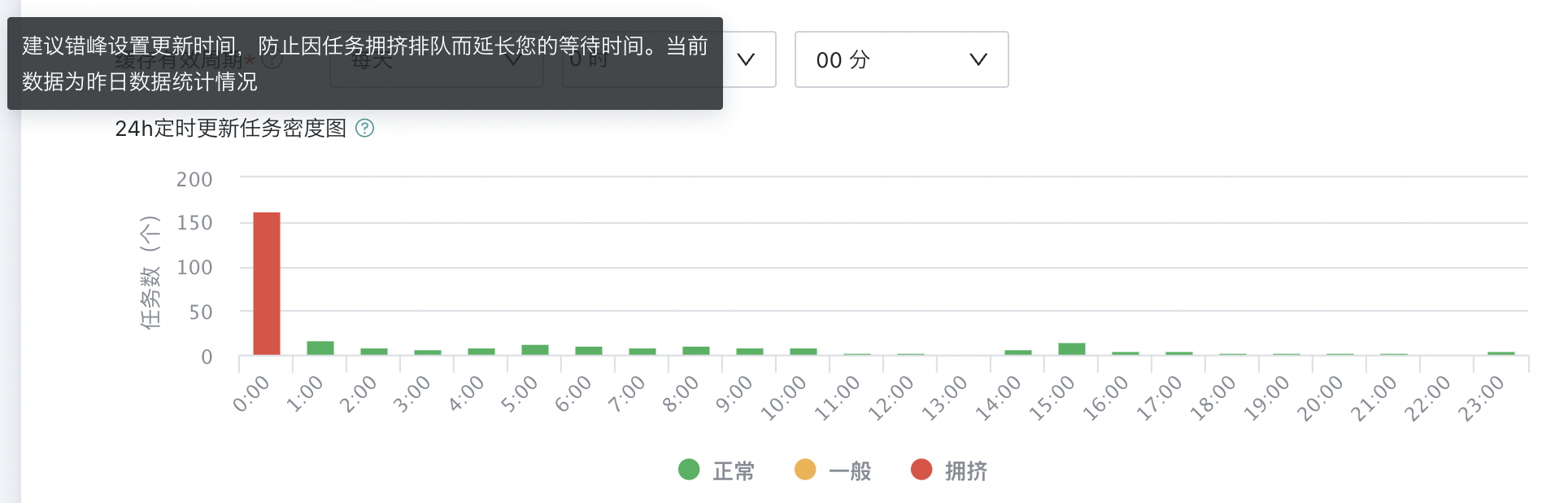
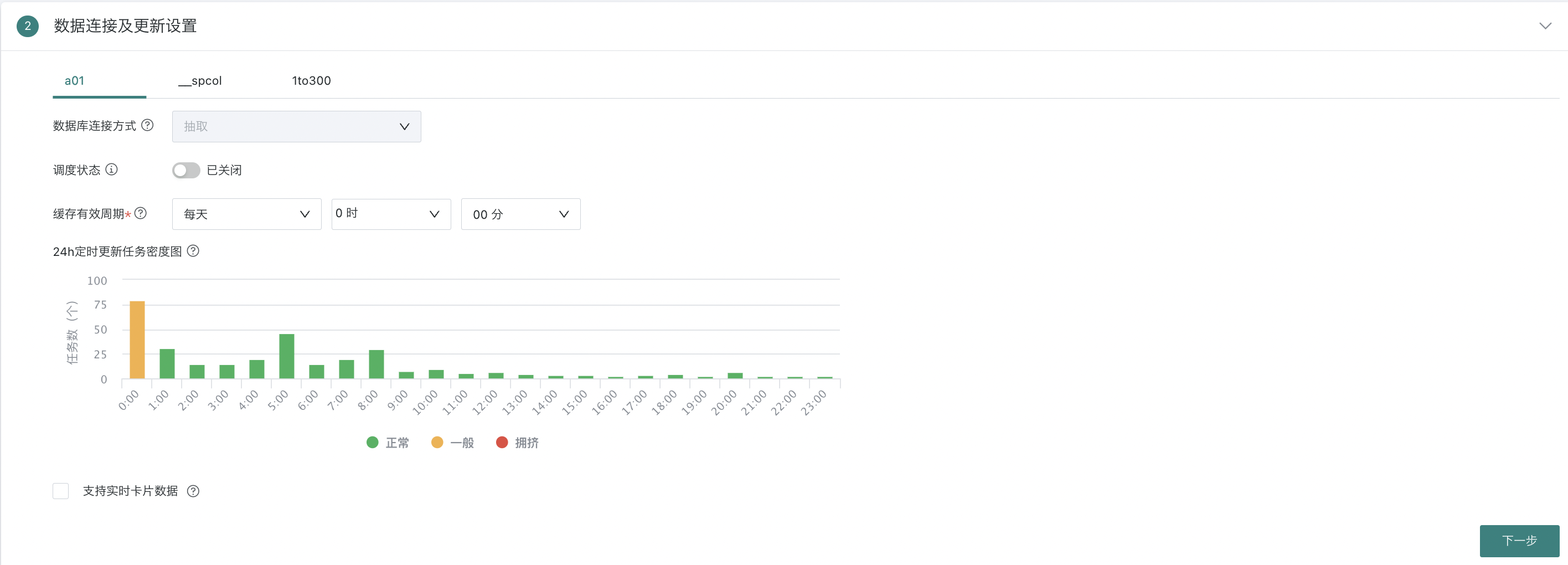
24h定时更新任务密度图
参考时间段内定时更新数据集任务数和拥挤程度,选择相对闲时为当前数据集更新时间,避免任务排队,减轻系统压力。数据仅用做设置更新时间参考,与实际运行任务可能存在少许偏差,请勿用于统计。
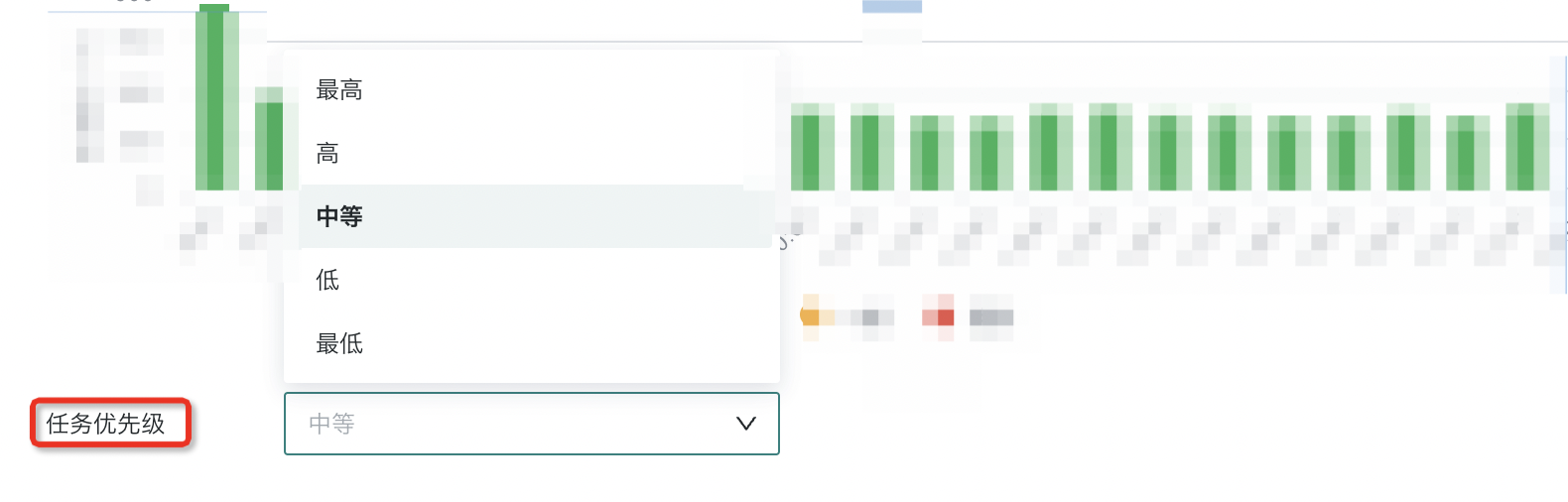
任务优先级
可设置数据集抽取的任务优先级,保证同一时间调度起来的业务高关注度任务可以优先执行。分为最高、高、中等、低、最低五种,默认为中等。当触发数据集更新任务后,会按照当前配置的优先级插入到任务队列中。
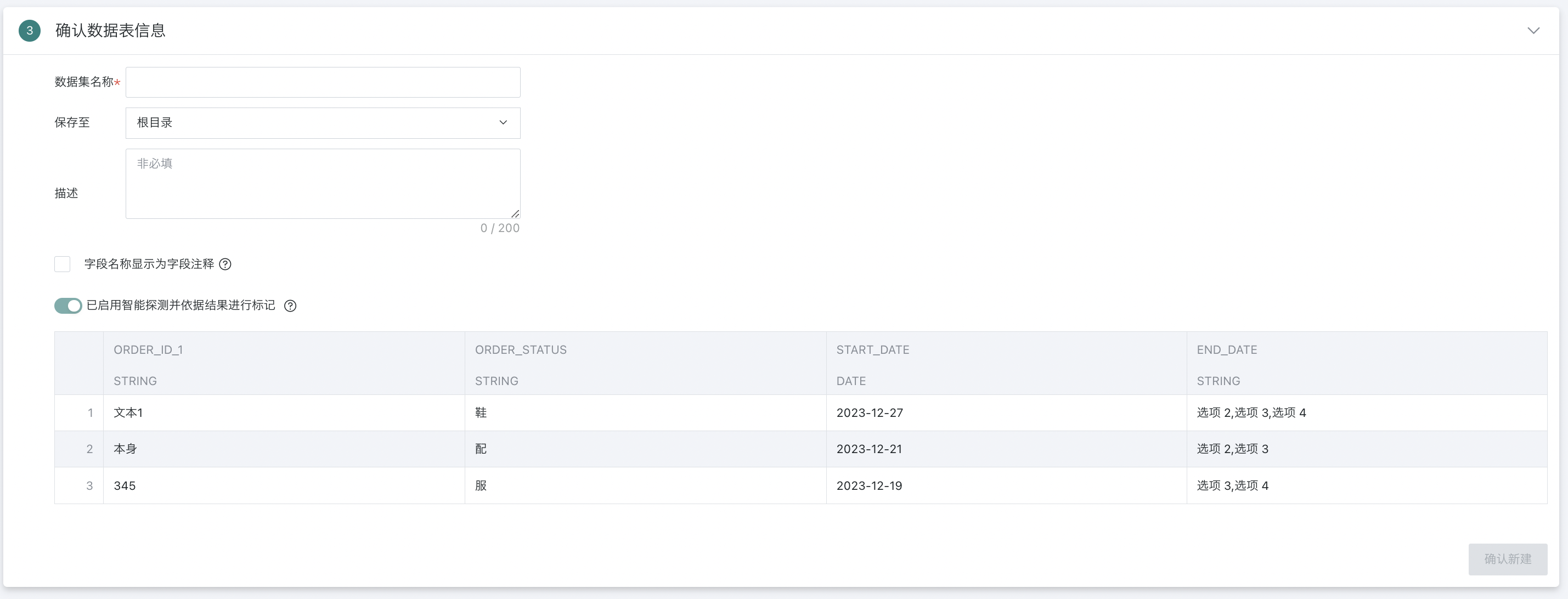
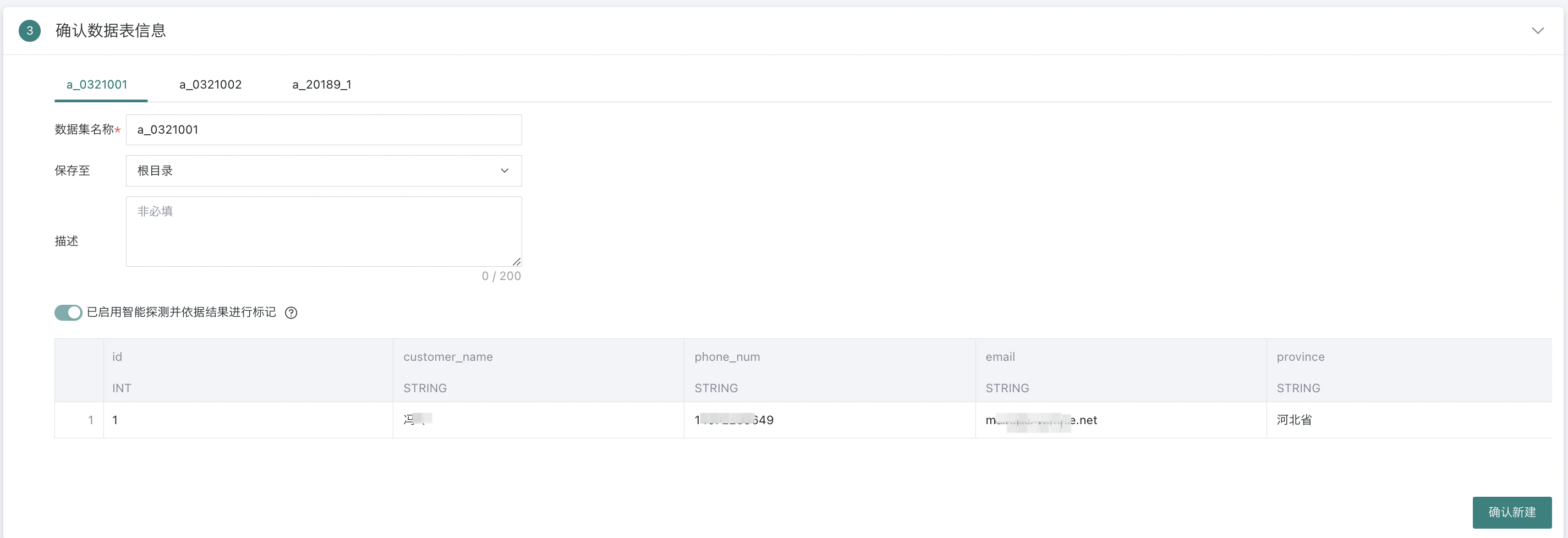
确认数据表信息
本章节将详细介绍确认数据表信息,包括数据集的存储、灵活处理字段注释、敏感数据集标记、数据集预览及字段属性的调整等,以确保数据在后续分析、处理及展示过程中的一致性和准确性。
| 序号 | 名称 | 描述 |
|---|---|---|
| 1 | 数据集名称 | 1. 支持手动填写数据集名称。 2. 支持直接获取数据库表注释作为数据集名称,若输入SQL中包含多个表,会提醒用户选择其中一个获取注释。 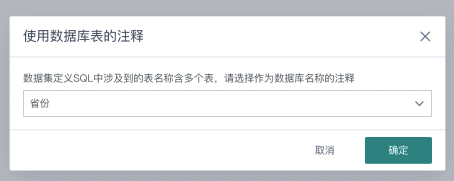 |
| 2 | 保存至 | 选择保存路径。 |
| 3 | 描述 | 自定义描述内容,非必填。 |
| 4 | 字段名称显示为字段注释 | 勾选后字段名称将自动同步成数据库中已设置的字段注释。 当企业的IT部门构建应用层宽表时,通常在数仓或者数据库环境会将宽表的数据集字段中文名称标注在表结构的 comments 中。当 BI 在对接宽表时,可通过此功能直接将原表 comments 中的字段注释直接覆盖成字段名称,减少手动修改的重复工作。 (注意:该功能现只支持单表数据集,当前支持的数据库包含:MySQL、Hive、Impala、Presto、ADB、ClickHouse、MaxCompute、GaussDB、StarRocks、GBase)。 |
| 5 | 字段注释同步为数据库字段注释 | 勾选后字段注释将自动同步成数据库中字段的已有注释。 |
| 6 | 标记为敏感数据 | 支持对当前数据集标记为「敏感数据集」,开启后,敏感数据集不可直接用于创建卡片,需前往数据集详情-数据安全页配置敏感字段及脱敏规则,有效防止敏感数据的非授权访问和泄露,详见数据脱敏。 |
| 7 | 数据集信息 |
|
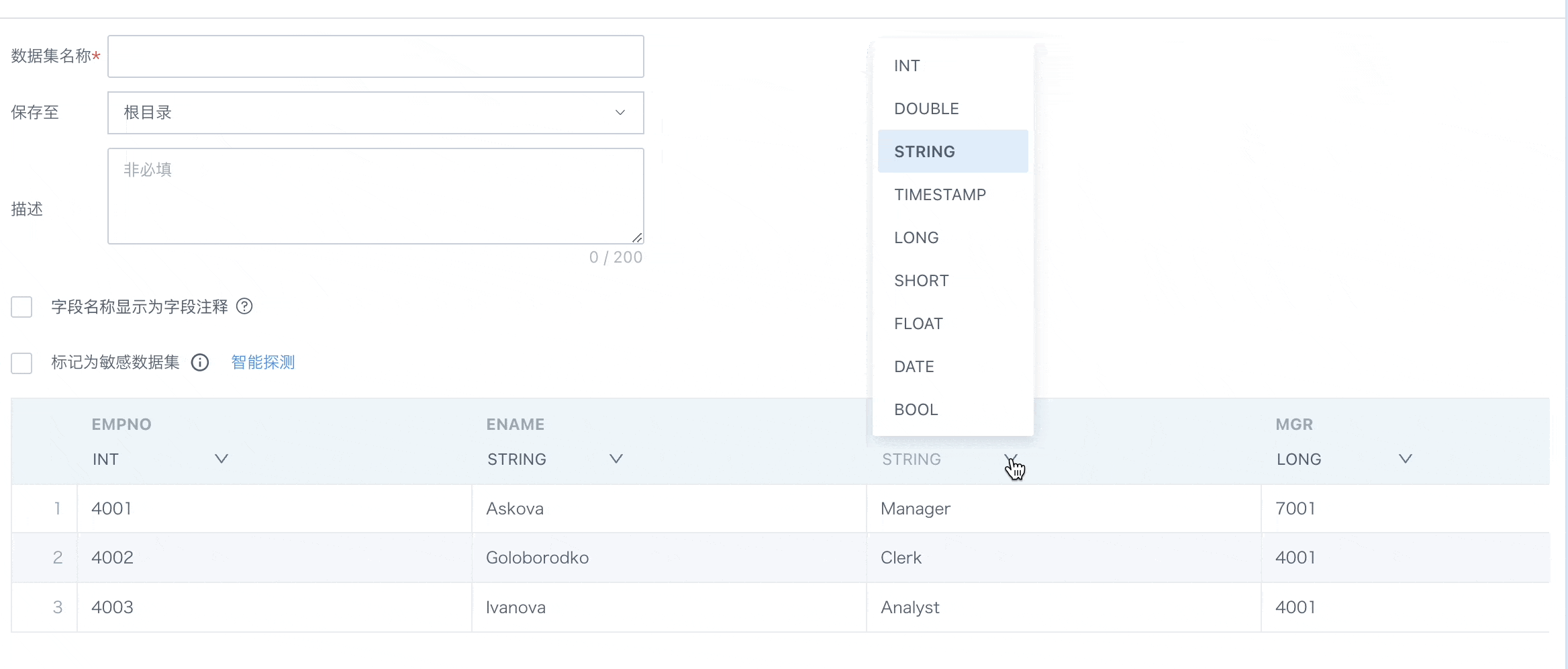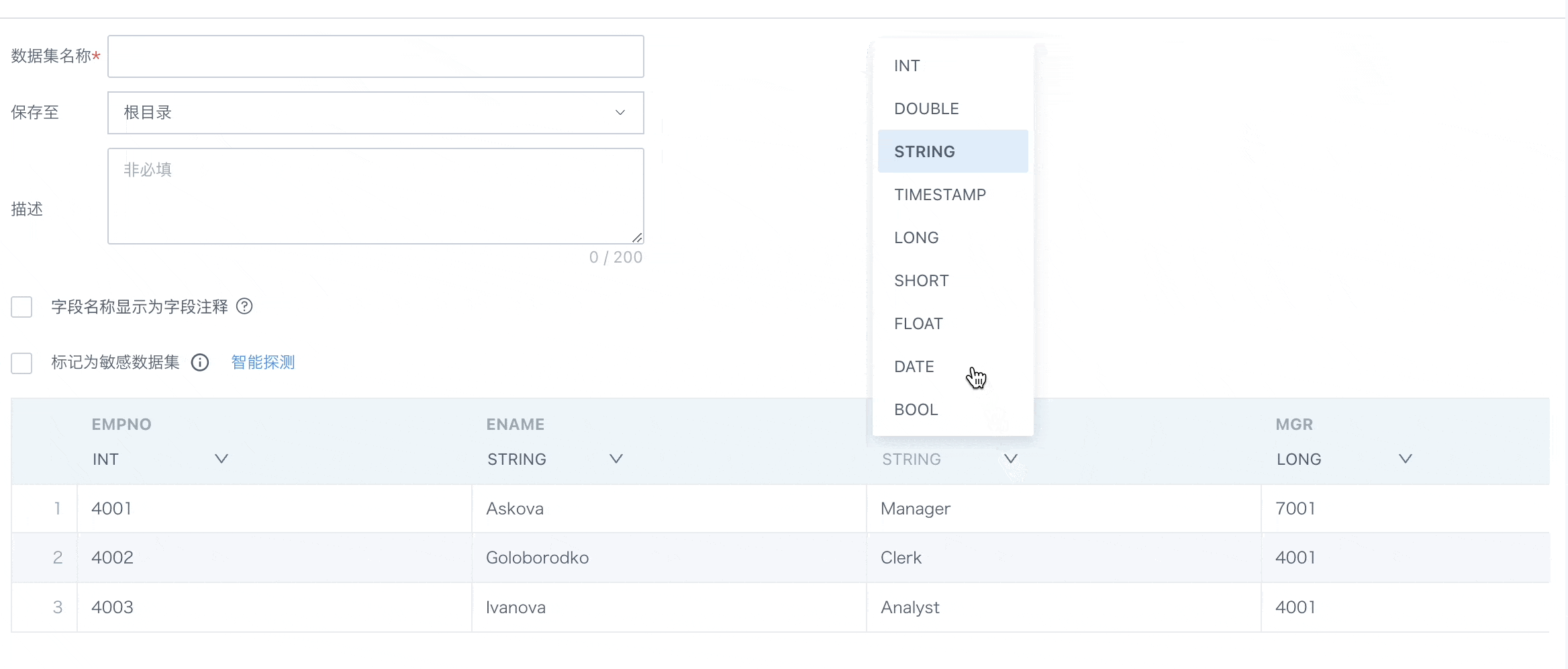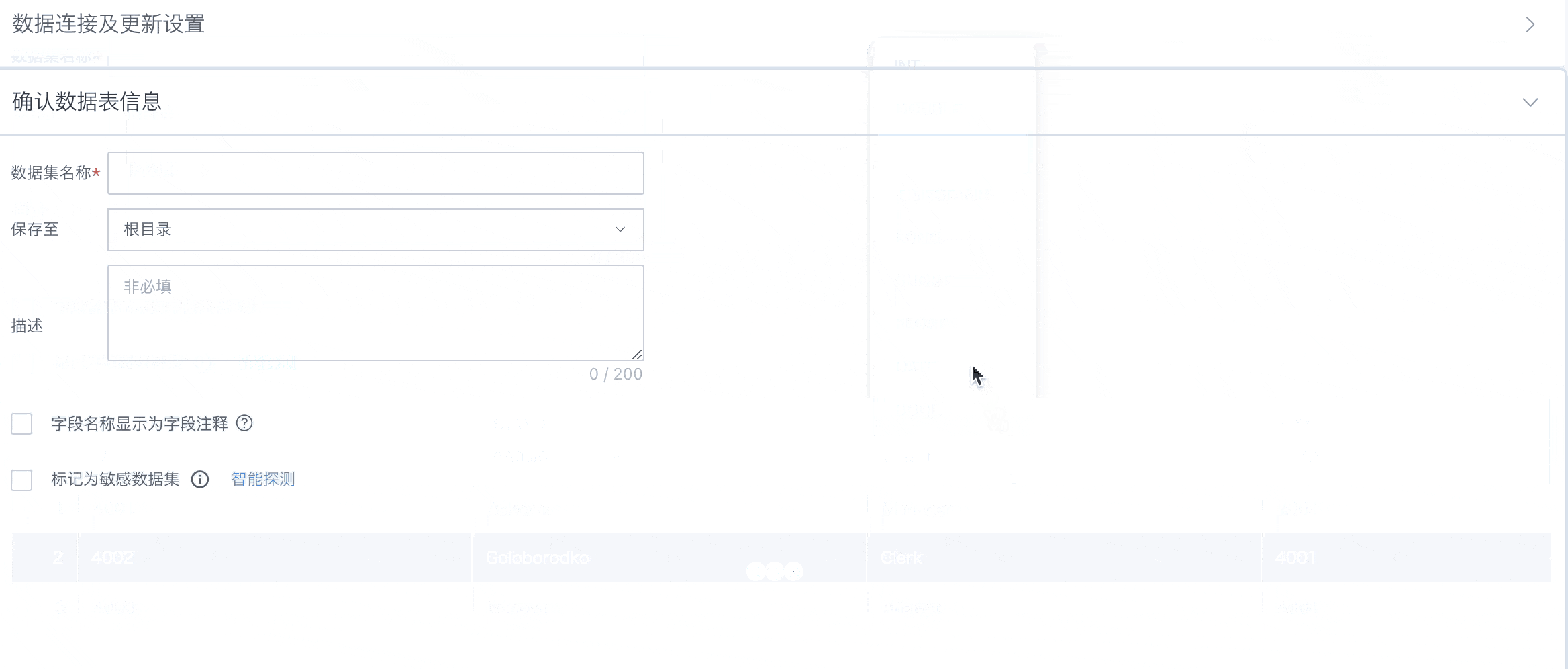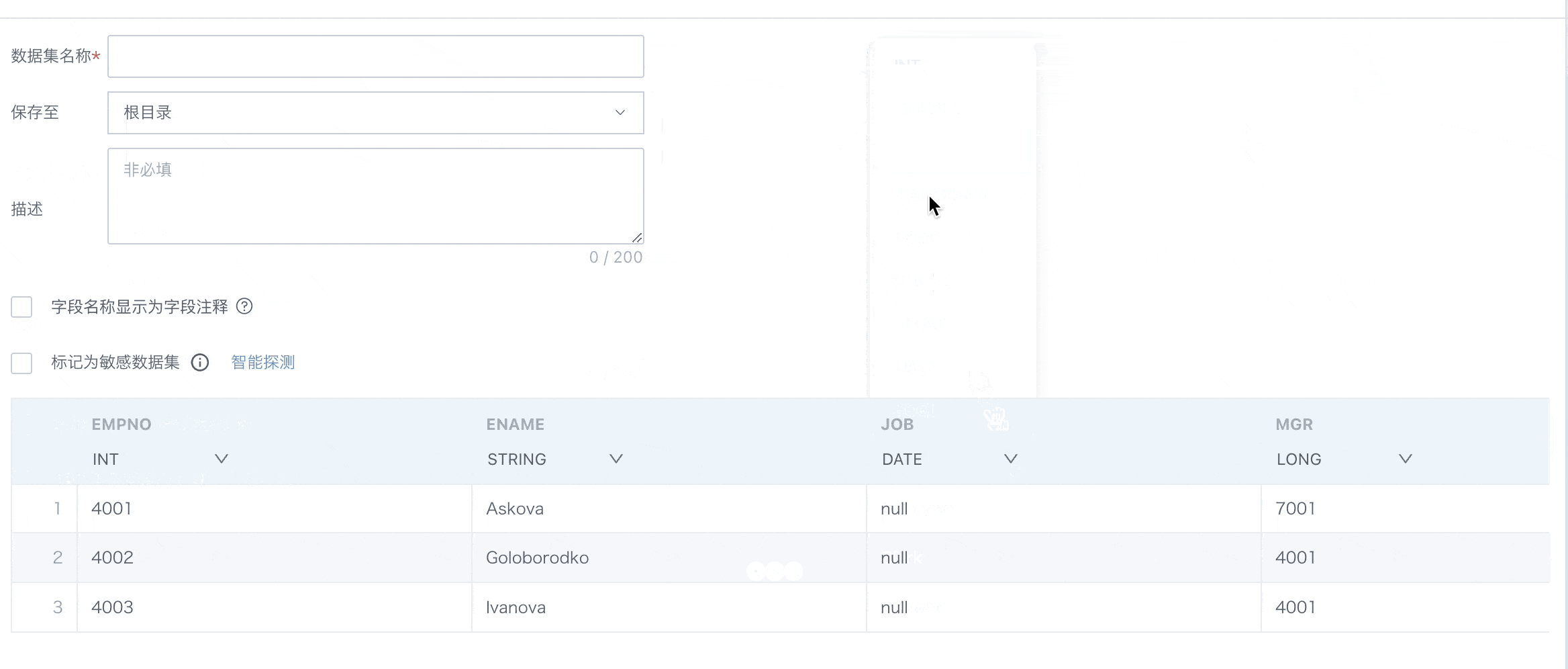
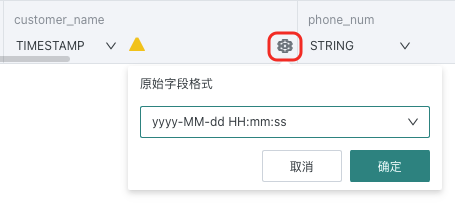
- 仅抽取模式下,支持字段类型切换。
- 数据集抽取过程中,某列类型不一致,任务不失败。
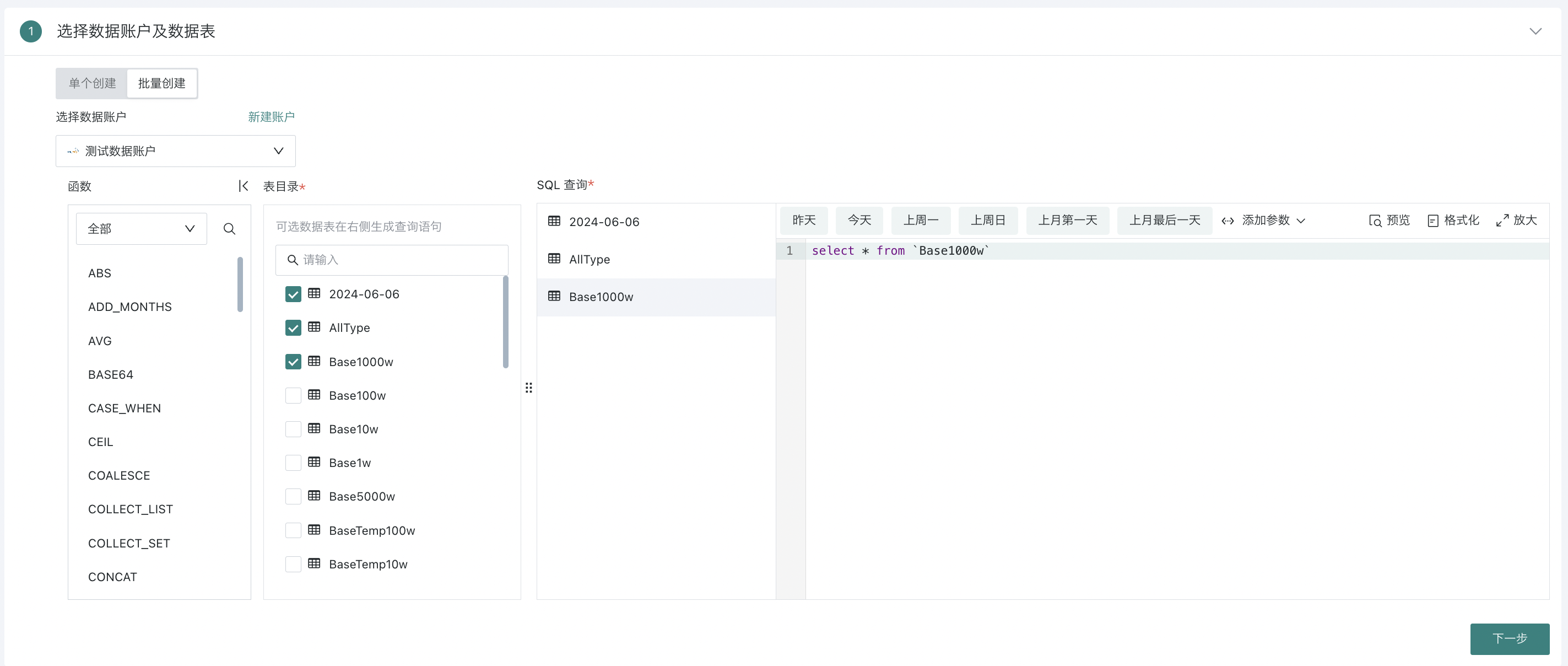
批量创建数据库
同数据账户数据库表支持批量创建,当用户需要将单一数据库中的数据表批量全部抽取至BI时,可通过此功能来实现。
-
当创建数据库选择批量创建时,可以勾选多张数据库中的数据表,并在SQL查询下方选择不同表进行SQL编辑。所有SQL编辑完成后,点击下一步。
-
在数据连接与更新设置中,配置每个数据集的连接方式与更新方式。
-
最后逐一确认每个数据集的表信息,点击确定创建数据集。
MongoDB、Sap BW类型数据库不支持批量创建。