Spark窗口函数及应用
窗口函数
定义
窗口函数(Window Function),也叫分析函数(Analytics Function),或者OLAP函数(Online Anallytical Processing,联机分析处理),可以对数据库数据进行实时分析处理。
功能
1)同时具有分组(partition by)和排序(order by)的功能;
2)不减少原表的行数。
窗口函数里的 partition by 和 order by 子句的功能是对分组后的结果进行排序,和普通SQL查询语句中的group by 和 order by类似。区别在于,group by 分组汇总聚合后改变了表的行数,而 partition by 不会减少原表中的行数。窗口函数是对 where 或者 group by 子句处理后的结果进行操作,所以窗口函数原则上只能写在 select 子句中,在观远BI中可以在新建计算字段里使用。
适用场景
场景1:观远BI里自带的聚合计算,或者新建的聚合度量,都是基于维度栏的字段进行分组聚合,如果需要不按照维度栏字段进行分组聚合,那就需要用到窗口函数来计算。
场景2:BI里直接聚合计算得到的数据不能进行筛选和二次计算,如果需要对聚合结果进行筛选和二次计算,需要用到窗口函数来计算。
基本语法
over (partition by
order by )
-----------------------------------------------------------------------------
over (partition by xxx) 按照xxx分组,无分组时写法为over (partition by 1/null) ;
over (partition by xxx order by xx) 按照xxx分组,并以xx排序
<窗口函数> 的位置,可以放以下两种函数:
专用窗口函数:包括 rank, dense_rank, row_number 等专用窗口函数。
聚合函数:如 sum, avg, count, max, min, collect_set 等。
partition by :分组子句,表示窗口函数的计算范围,不同的组互不相干;
order by: 排序子句,表示分组后,组内的排序方式,默认是按照升序(asc)排列;
常见专用窗口函数
以下为Spark SQL的窗口函数使用说明,其他类型数据库可能存在不同使用方式。
案例分享
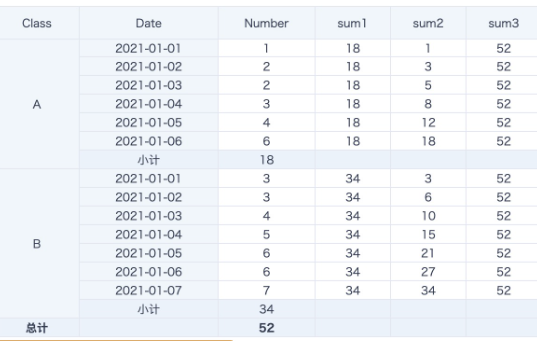
案例1:分组求和以及累计求和
sum1: sum([Number])over(partition by [Class]) 按Class分组求和,等同于小计
sum2: sum([Number])over(partition by [Class] order by [Date]) 按Class分组进行累计求和;
sum3: sum([Number])over(partition by 1)/ sum([Number])over(partition by null) 不分组计算总和,等同于总计。
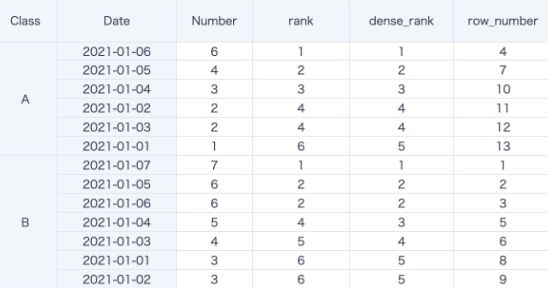
案例2:分组排序
dense_rank() over(partition by [Class] order by [Number] desc)
row_number() over(partition by 1 order by [Number] desc)
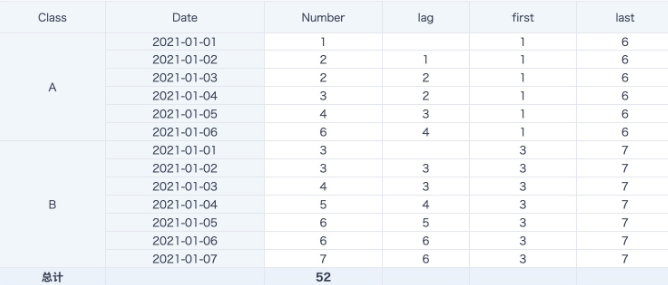
案例3:行偏移
lag([Number])over(partition by [Class] order by [Date] )
--按Class分组日期排序后取上一行数据,取不到值则默认为null.下图中数据相当于环比;
first([Number])over(partition by [Class] order by [Date])
--按Class分组日期排序后取第一行数据,order by [Date],相当于取期初数据;
last([Number])over(partition by [Class])
--按Class分组日期排序后取最后一行数据;
last([Number])over(partition by [Class] order by [Date])
--按Class分组日期排序后取当前行数据;
进阶用法
over (partition by
order by
rows/range窗口子句)
rows/range:窗口子句,是在分组(partition by)后,组内的子分组(也称窗口)。
窗口有两种:rows和 range,主要用来限制行数和数据范围。窗口子句必须和order by 子句同时使用,且如果指定了order by 子句未指定窗口子句,则默认为 range between unbounded preceding and current row,从当前分组起点到当前行。行比较分析函数 lead 和 lag 无窗口子句。
窗口子句常用语法
PRECEDING:往前
FOLLOWING:往后
CURRENT ROW:当前行
UNBOUNDED:无界限(起点或终点)
UNBOUNDED PRECEDING:表示从前面的起点
UNBOUNDED FOLLOWING:表示到后面的终点
rows 和 range 区别:
1. rows 是物理窗口,即根据 order by 子句排序后,取的前N行及后N行的数据计算(与当前行的值无关,只与排序后的行号相关)。
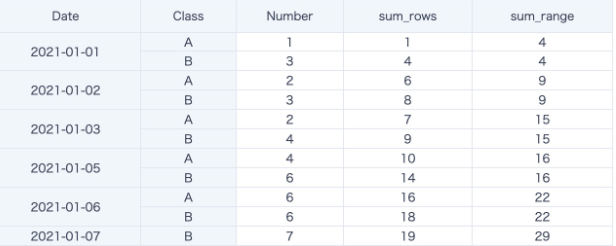
sum([Number]) over (partition by 1 order by [Date] rows between 2 preceding and current row)
如下例中 sum_rows,是按照日期排序后取前2行和当前行数据的求和。尽管很多日期对应的数据不止一行,有两个 Class 存在,但是默认窗口内会对 Class 进行升序排列再选取前2行和当前行进行累计求和计算。
- range 是逻辑窗口,是指定当前行对应值的范围取值,包含子分组(或窗口)里的所有行,和当前行有相同order by值,如果更多的行有同个 order by 值,当使用 range会有更多的行参与计算。
sum([Number]) over (partition by 1 order by [Date] range between 2 preceding and current row)
如下例中 sum_range, 是按照日期排序后取前2天和当前日期(连续3天)数据的求和。卡片里筛除了2021-01-04的数据。
当 Date=2021-01-01时,没有前两天日期数据,仅读取当天2条数据,sum=1+3=4;
当 Date=2021-01-03时,取2021-01-01,2021-01-02和2021-01-03连续3天的6条数据,sum=(1+3)+(2+3)+(2+4)=15;
当 Date=2021-01-05时,没有2021-01-04数据,只取2021-01-03和2021-01-05 两天的4条数据,sum=(2+4)+(4+6) =15; 以此类推下去,结果如下例中所示。
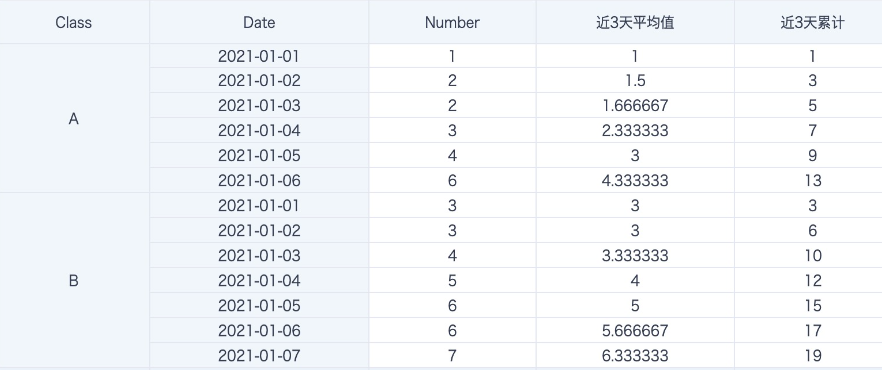
案例:计算移动均值和移动累计
avg([Number]) over (partition by [Class] order by [Date] rows between 2 preceding and current row) --近3天平均值(包含当天)
sum([Number]) over (partition by [Class] order by [Date] rows between 2 preceding and current row) --近3天累计(包含当天)
注意事项
-
筛选条件先于窗口函数生效,被筛除的数据不会参与计算,所以即使over (partition by 1/null) 也不会计算被筛除的数据;
-
Partition by 分组子句里的字段如果用于页面筛选器,则这个筛选器必须一直有选项被选中并联动卡片,全选或者为空的话可能会导致计算结果不正确,因为设定好的分组不能自动取消;
-
数据量大(约超过100万行)的情况下,使用窗口函数计算比较耗资源,请按需谨慎使用。