数据集常见问题
概述
本文将介绍观远BI多源数据接入模块的数据集常见问题。
数据集
设置的行列权限为何对数据集所有者没生效?
问题原因:用户为数据集的所有者,未勾选底下“以上行列权限设置,是否对数据集所有者和管理者生效”。
解决方案:行列权限是一个控制数据安全的很实用的功能,设置了行列权限后,所有该数据集涉及的资源都会影响, 包括但不限于卡片、数据集、ETL操作等。
直连和guan_index抽取的区别?
-
直连是直接查数据库,适合查询实时性较高的场景;guan_index即抽取, 是先把数据从数据库抽到BI平台上,再直接在BI上进行处理和计算,适合实时性要求不高的场景。
-
直连的数据集的卡片写函数进行计算时使用对应数据库的语法,抽取数据集要用spark语法。
-
直连不能用ETL。
使用BI时应该使用何种语法?
-
创建数据库数据集:创建数据库数据集时使用对应数据库语法。
-
新建计算字段或者设置行列权限:直连数据集/卡片:使用对应数据库语法;抽取数据集/卡片:普通类型使用spark语法;高性能数据集使用clickhouse语法;
-
ETL中新建计算字段/sql输入节点使用spark语法。
SQL查询如何剔除不需要的列
背景:不需要查询出所有字段(select *),并且当有join操作之后创建数据集是无法select *,会有报错某字段 is not unique in Record,因为平台不允许存在同名字段,所以必须要剔除重复的字段,但有时字段会比较多,一一列出来写sql是个繁琐的工作。
解决方案:在数据库连接工具中查询出所有字段;然后仅选择需要保留的字段名复制。
以Mysql为例,使用Navicat工具进行查询,查询语句如下,查出结果会自动按照逗号分隔,方便复制。
SELECT GROUP_CONCAT(COLUMN_NAME SEPARATOR ",") FROM information_schema.COLUMNS
WHERE TABLE_SCHEMA = 'db_name' AND TABLE_NAME = 'tb_name';
db_name:数据库名
tb_name:表名
在数据集模型结构里用SQL修改列名时,为何没生效?
默认了字段关联,将目标字段选为“无关联”就可以了。
数据集id已经获得,哪个表可以关联到数据集的中文名称?
数据集的中文名称在内置数据集builtin_data_source里。
相同的行权限条件设置,从一个数据集拷贝到另一个数据集,为什么就报错了?
问题原因1:行列权限的生效,只在对应数据库中完成的,不同的数据库使用的SQL函数是有区别的。
解决方案:例如,GuanIndex数据集对应的是Spark计算引擎,而直连数据集对应客户的数据库。请根据对应的数据库编辑合适的SQL过滤条件。
问题原因2:目标数据集缺少行权限条件里使用的字段,系统校验失败。
解决方案:修改权限条件,确保字段存在于目标数据集。
API上传数据的数据集,可以指定存放数据集的文件夹吗?
不可以在api上传时指定。默认存放在根目录下,上传成功后可自行移动存放。
手工表追加数据和替换数据的区别?
(1)替换数据分两种:
a. 替换数据之前的字段原来就存在的,当你替换数据,上传数据集的时候,它就是按照之前你要替换的这个字段的位置,弹出替换数据的框,并不会按照你上传数据的excel的顺序来。
b. 替换数据的时候字段不存在,那么新增的这列就会在后面。
(2)追加数据:追加的数据的话是在现有列的字段下增加数据行。
手工表追加数据,使用一模一样的数据集追加,且选择去重主键为何数据量会膨胀?
问题原因:选择为去重主键的字段可能含有null值,对null值无法判断是否是重复所以都会保留下来,导致数据量会膨胀。
解决方案:含有null值的字段一定不能作为去重主键,无论是手工表追加数据还是数据集增量更新主键去重。
在观远BI上上传手工表创建数据集,可以使用excel和csv的压缩文件吗?
(1)在上传时选择Excel文件类型时,无法上传Excel的压缩文件。
(2)上传时选择CSV的文件类型时,选择文件时可以选择Excel的压缩文件,但是会提示上传失败。可以上传成功CSV的压缩文件,CSV支持上传压缩包(zip文件),并支持自动解析。
guan_index抽取数据最短间隔刷新时间是多久?
自动的定时更新一天最多4次,可根据业务需求,设置数据集的更新频率。
若实时性要求更高(如15分钟看一次数据),可以考虑用直连,实时性比较高,但是需要注意ETL无法使用。
如果过于频繁更新数据集,可能会存在以下风险:
(1)数据质量:频繁更新数据可能导致数据质量下降,短时间内进行大量的数据更新,可能会导致数据出现错误或缺失,需确保数据的准确性和完整性;
(2)系统性能:频繁更新数据可能会对系统性能产生负面影响,每次更新都需要消耗系统资源。如果更新频率过高,可能会导致系统运行缓慢,甚至崩溃,要评估系统的性能和资源消耗情况;
(3)数据库自身压力:频繁更新数据会消耗大量数据库的计算资源、计算时间、响应时间,要减轻对数据库的压力,进而减轻对系统整体的影响。
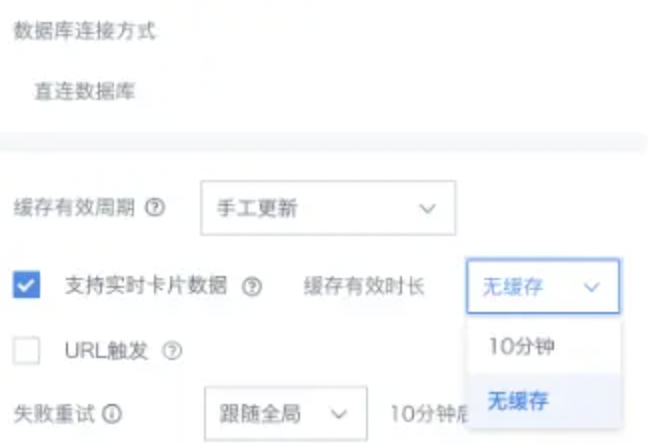
直连数据库也是以缓存有效周期为准的,要勾选url触发吗?
(1)直连一般都是直接去查数据库的,但每次都去查库的话,数据库压力会很大,所以我们有缓存的机制。
(2)缓存的机制是在卡片有相同的查询sql,且缓存版本没有过期的情况下,才可能命中缓存。
(3)url触发只是一种外部触发更新的机制。不论是哪种更新方式触发的更新,数据集更新的话就会刷新缓存的版本号。
(4)对实时性要求比较高的话,可以勾选上支持实时卡片数据。选择支持实时卡片的情况下,如果需要减少一部分数据库压力,可以调整一下默认缓存有效时间。
两个数据账户的表进行join可以吗?
相同数据账户跨库的表可以在数据集模型结构里实现关联,跨数据账户不可以,建议分别抽取后使用ETL进行表关联。
手工表(csv、excel)替换数据操作后多余的列为什么一直存在?
问题原因:原来存在的数值列不会被直接删除,替换新的表之后如果设置了关联,原来的列就会直接被新的关联字段取代,但如果没有关联的话,该列会变成null值。暂时不支持直接删除列。
如果把计算字段逻辑写到数据集SQL里能缩短查询时间吗?
例如场景:
目前有张不到100万条记录的数据集查询超过10秒,数据集SQL在大数平台查询不到1秒,观远里加了几十个同比计算字段,用了sum等函数;
数据应该是使用直连数据集,时间方面包涵三部分:去数据库中取数,在BI里计算(比如加了几十个同比计算字段,用了sum等函数)的时间,再加卡片样式的渲染时间。
假如将复杂计算放在sql里,那么在数据库中取数的过程时间就会延长,想要根本解决这个问题的话这个要在这边最底层数仓中将这些复杂计算的指标提前就算好,这边直接取数操作。(有点此消彼长)
想要批量获取数据集中的所有表名
数据集的模型结构中可以查看数据集的sql信息,这里能看出是用来数据集是用的哪张表。
批量可以通过api获取,数据集对应的数据库表要看相当于是看数据集的query信息,方法可以参考:
如何判断一张数据集表是不是“全量更新” ?
更新方式到数据集更新页面可以看到的,只要没有勾选增量更新,SQL 语句里没有限定时间条件,那就是全量更新的。
若全量更新:需要注意⚠️客户方ERP里数据结构没变的话会更新到,万一字段名称或者数量变动了,那改动部分就更新不到;
全量更新只是基于原来已经抽取到的字段来全量更新,新加的列不会自动更新;
(1)如果字段有变动,需要重新更新。
(2)如果没有字段更新,只有内容的话不需要重新更新。
只读用户数据集是没有导出CSV文件功能的吗?
只读用户只支持导出excel,不支持导出csv,另外, 普通用户和所有者的直连数据集的卡片也是只能导出excel。
数据集设置列权限,在数据集概览页面,没有权限的人只能看到该列下的数据为null,能否直接隐藏看不到的列?
数据集详情页本身就是要展示完整数据结构的, 如果隐藏了,那有信息不对称问题(上面写着10列,下面因为没有列权限,只能看到5列,那更容易造成误解,以为系统有bug),如果是做成表格卡片,那么如果没有这列的列权限,该列字段会隐藏,所以,实际使用起来是不影响的。
直连数据集实时无缓存的卡片预警为何没被触发?
问题原因:勾选了“支持实时卡片数据”,但页面上没有打开“实时数据”开关,如果没有访问页面,页面数据是不会更新的,也就不会触发预警。
数据集支持另存为吗?
支持,可以在“管理员设置/系统设置/高级设置/是否允许数据集另存为”打开开关。
添加主键,数据获取量跟原数据里的数量对不上?
问题原因:主键里是否有大量是null的行,如果去重主键有null并且该列是数值类型的话,会把所有null的行丢掉,导致数据变少。
解决方案:建议先把null处理掉再抽取,或者全量更新。
传数据集的时候,重名的能传上去吗?
同个文件夹下是不支持相同名称的数据集上传的,不同文件夹下是允许两个相同名称的数据集存在的。
数据集创建好之后是否可以更改连接方式?
不能。
新建数据库数据集时,用了IF嵌套函数,为何会预览失败?
问题原因:由于IF嵌套时间复杂度太高,是幂次增长的,如果在预览界面使用了多个嵌套IF的sql,很有可能会导致预览超时。
解决方案:建议使用case when替代IF嵌套函数。
ETL、卡片、数据集默认并发数是多少?
ETL自动任务默认并发为1;数据集自动任务为4;卡片并发:抽取默认并发为10,直连无限制;
这是默认情况下的设置,如果您之前申请调整过并发数,那以实际修改后的数值为准。管理员可以进入管理员设置--运维管理--参数配置 页面修改ETL并发数;如果想调整卡片、数据集并发数,可以反馈给售后支持同学,待研发和运维评估后操作执行修改,该参数不支持客户自定义修改。
BI系统数据集更新排队量很大,无法加载页面
这种一般都是有大的任务在运行,堵住了其他任务,您可以看下任务管理页面,看下运行时间最长的任务是什么,取消运行时间最长的任务后系统一般会自动恢复。
数据集预览时有数据,更新成功后没有数据,但是数据集又显示有n行n列
建议从以下方面进行排查:
(1)数据集有没有设置筛选条件进行过滤;
(2)数据集的数据权限模块,是不是设置了权限管控,开启了行权限;
(3)如果开启了行/列权限,并且打开了是否对数据集所有者和管理员生效了的开关,那么即使是管理员,没有行列权限,也是看不到数据的。
视图数据集的更新,是自动依赖所选的数据集更新了就自动更新吗?这个需要另外设置吗?
视图数据集的更新主要是指更新模型结构sql,上游数据集更新了,数据视图也会更新。
卡片数据集的更新方式
前提:数据集a创建了卡片b,根据卡片b创建了卡片数据集c。
(1)关于卡片数据集的结构:如果卡片b修改,卡片数据集c不会自动同步,需要手动更新才会同步。
(2)关于卡片数据集的数据内容:原始数据集a更新,会触发卡片数据集c 的数据更新。
直连数据库的实时卡片数据与付费模块的实时数据有何区别?
(1)直连数据库的实时卡片数据是准实时:选择“支持实时卡片数据”,数据集缓存有效时间支持无缓存,可达到页面卡片数据准实时的效果。但这种处理方式对业务库会造成较大压力,且无法实现多源数据融合。
(2)付费模块的实时数据是Lambda架构,并且可以支持简单的同环比等预制的计算:将历史数据与实时数据进行分开处理,既能够实现多源数据的融合,又可以支持增量更新且占用较少的计算资源。
从操作层面来说,观远自带的“直连数据“配置比较方便,付费的“实时数据”模块会有一定的学习成本。
使用API上传数据后提示成功但数据集中并无数据
问题原因:"batchFinish": false /* 可选,默认为false,分批上传时,表示是否是最后一批。设置为false时,不更新行数,也不刷新card缓存 */
解决方案:请求参数中加上"batchFinish": true 即可,不加默认不更新。
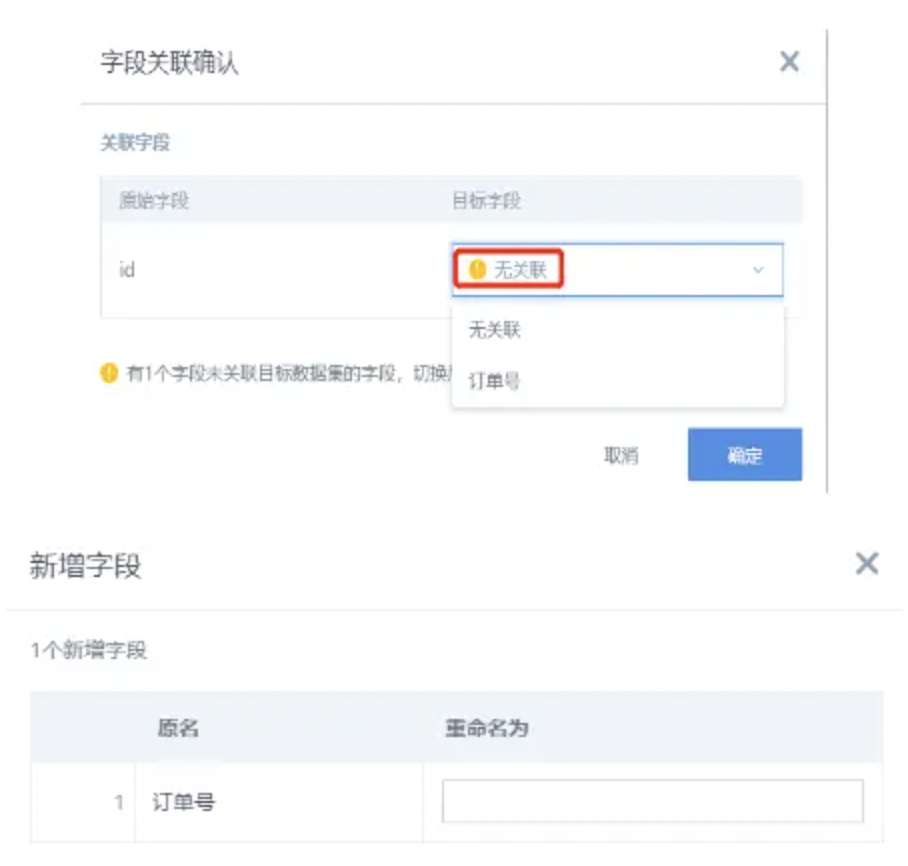
模型结构里面用sql修改列名,但是没有生效
问题原因:在数据结构中有对字段进行重命名。
解决方案:
(1)【推荐】在数据结构中对字段进行重命名/或者是改为空(默认是模型结构语句中的字段命名)
(2)在修改完模型结构后,在关联弹窗中选择“无关联”,然后在下一个弹窗中对字段进行重命名。
不同增量更新方式的区别
增量更新的前提条件:
-
数据源(数据库)中存储了每条记录的创建时间或者更新时间;
-
有不重复的主键列。
(1)未设置去重主键时
添加新数据:增量更新抽取到的数据会全部作为新增数据。
覆盖旧数据:会清空原有的数据,更新后的数据即为增量更新语句查询到的数据。
(2)设置了去重主键时
添加新数据:增量更新抽取到的数据若与已存在的数据主键重复,则增量更新抽取到的数据会进行覆盖。其他抽取到的数据作为新增数据。
覆盖旧数据:会清空原有的数据,更新后的数据即为增量更新语句查询到的数据。
创建数据集中,通过excel上传相关数据最大支持多大的文件
在7.1版本中,新建数据集时上传的Excel(xlsx)文件大小不能超过500M, xls等老版本Excel文件大小不能超过5M(同时最大行数不得超过1048576行数据);CSV文件(可压缩成zip)文件大小不能超过500M 。
ETL数据集支持在数据概览-数据结构里修改字段名称、字段类型嘛?
etl数据集的字段名称和类型需要修改时,建议直接在ETL内编辑;可以新建计算字段/分组字段,新建的字段可以编辑。
Web Service数据集怎么提取字段?
(1)先肉眼观察(或者借助JSON工具),检查数据返回数据的结构,识别出要查询字段所在的具体子节点。例如下图中可以了解到refund_order是在data下,在BI中路径可以这么写$.data.refund_order[*],即可获取到refund_order中的字段。

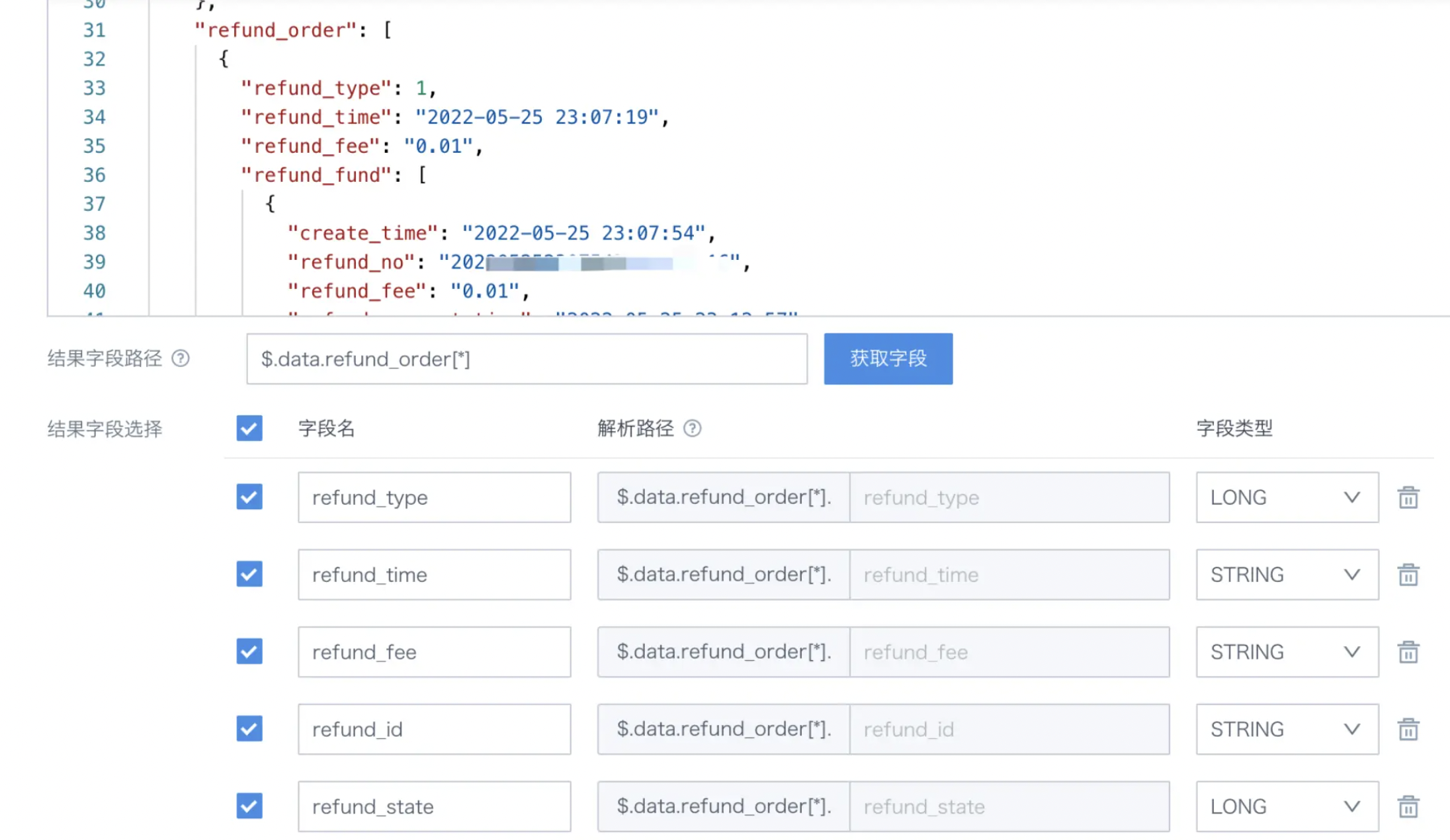
(2)如何获取到refund_fund里的字段
暂时观远BI还不支持直接拆分JSON里的嵌套数组,所以这里在通过$.data.refund\_order\[*]对refund\_order内的字段进行获取时,会发现refund\_fund被当做一个文本字段完整进行抽取。数据集创建后可以再通过ETL,使用函数提取出refund\_fund中各个字段的值,具体请参考用ETL解析JSON 。
表格卡片中主键不存在空值,但通过反馈填报/知识反馈输出的数据集中,存在主键字段为空值的历史数据
问题原因:该填报记录的填报者当时缺少数该主键的数据权限。也就是说,表格卡片依赖的数据集,启用了列权限,并对该填报用户设置了不可见字段。
解决方案:修改数据集列权限;或者通过ETL处理空值。
数据集里的文本字段为什么显示为乱码?
【原因】:用户数据库使用的字符编码不是BI默认用的UTF-8编码,数据集更新后BI直接读取了这部分编码错误数据。以下为4种常见的中文字符乱码出现的场景:
| 乱码示例 | 产生原因 | 特点 |
| ¹ÛÔ¶Êý¾Ý | 以ISO-8859-1读取GBK编码文字 | 通常为带有上标的英文字母 |
| ��Զ���� | 以UTF-8读取GBK编码文字 | 通常为带有黑色方框的问号 |
| 瑙傝繙鏁版嵁 | 以GBK读取UTF-8编码文字 | 通常为生僻的繁体字 |
| è§è¿æ°æ® | 以UTF-8读取ISO-8859-1编码文字 | 包含有小写的西文字母和一些符号 |
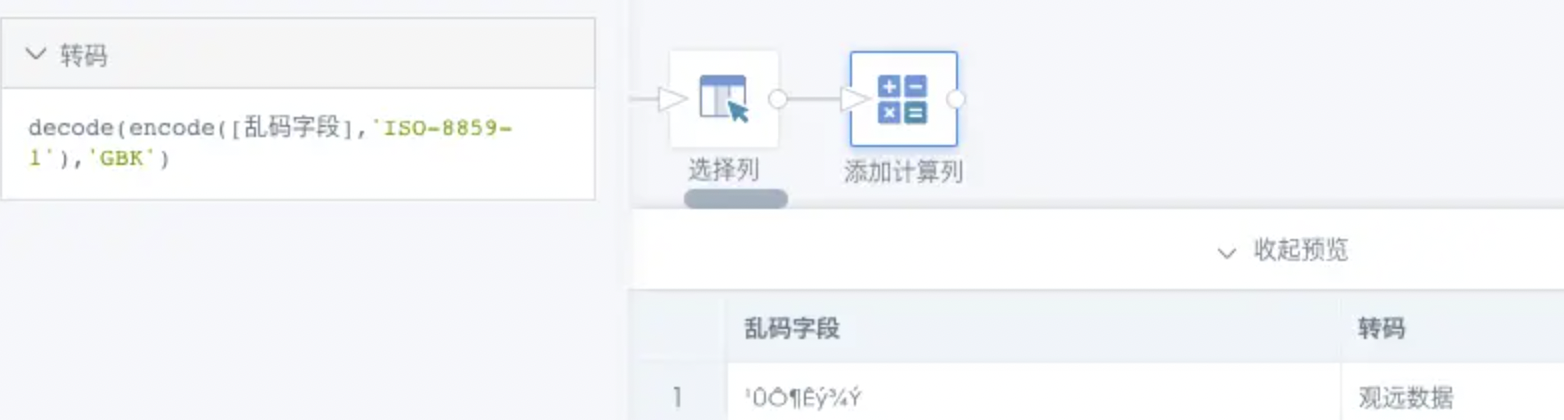
解决方案:修改源数据库的字符编码为UTF-8;如果定位和修改数据源比较困难,也可以在BI中把这部分数据重新编码:首先筛选出有问题的数据;定位到这部分数据是哪种错误的乱码;然后在新建字段中使用decode(encode([字段名], '类型1'), '类型2')来重新编码数据。
示例:以"¹ÛÔ¶Êý¾Ý"为例,它是以ISO-8859-1读取GBK编码的方式产生错误,那就需要把对应字段重新编码成ISO-8859-1的编码格式,然后再以GBK格式进行解码,那对应的新建字段类型就为decode(encode([字段名],'ISO-8859-1'),'GBK'),如图:
数据账户是否支持SSL证书访问
出于安全考虑,观远支持部分数据库挂载SSL证书访问。如有需求可联系专属的观远售后工程师或客户经理进一步沟通处理。
更新License后所有定时任务没有自动运行
问题描述:
旧的License到期之后,更新License,然后所有定时任务(例如数据集、ETL、订阅)都没有自动触发;环境迁移,激活新环境License后,定时任务都失效了。
问题原因:
License到期失效后,BI服务会终止,所有定时任务都会终止,即使重新激活License,定时任务也不会自动触发。BI 5.3.0 以及之后所有版本迁移,在激活新BI环境后,必须重启 guandata-server,否则定时任务失效。
解决方案:
重新激活License后,联系观远服务人员重启整个BI服务即可。