创建原子指标
概念
原子指标是业务定义中不可再拆分的指标,是最基础的指标,后续的复合指标和衍生指标都可基于原子指标来创建。原子指标通常是某⼀业务事件⾏为下的度量,用于量化统计产品或业务的表现,⽅式通常是做聚合计算,例如净利润 = sum(订单净利润)、总交易量 = count(distinct 订单编号)。
操作步骤
-
在导航栏选择「指标中心 > 指标主题」,点击「新建指标」按钮,并选择「原子指标」。
-
在「新建原子指标」对话框中,设置原子指标的基础属性、计算属性以及管理属性。
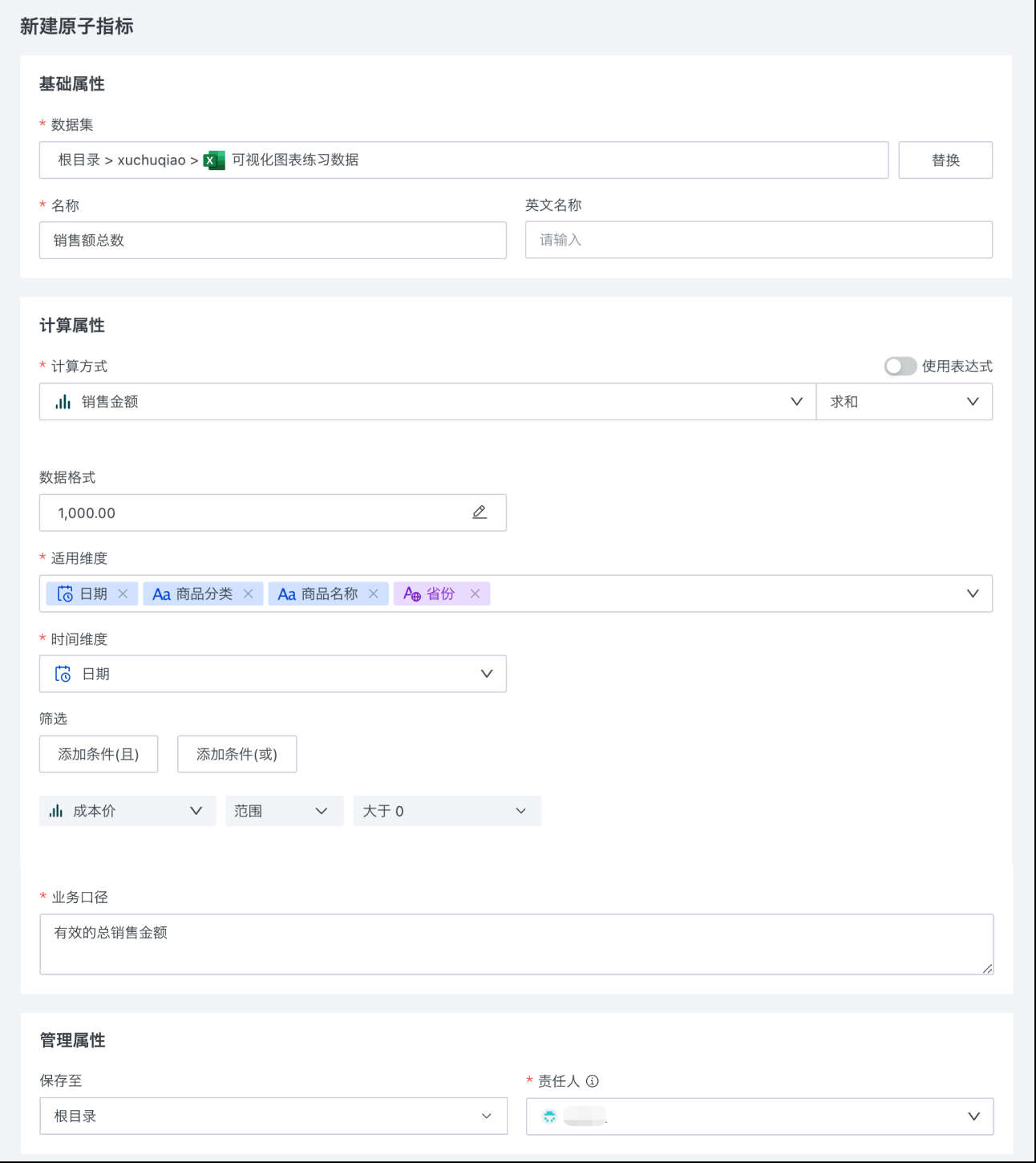
基础属性:
| 参数 | 说明 |
|---|---|
| 数据集 | 选择有使用权限的数据集,使用该数据集的内容创建指标。 |
| 名称 | 设置指标的中文名称,一个主题下不可重复。 |
| 英文名称 | 设置指标的英文名称,一个主题下不可重复。 |
计算属性:
| 参数 | 说明 |
|---|---|
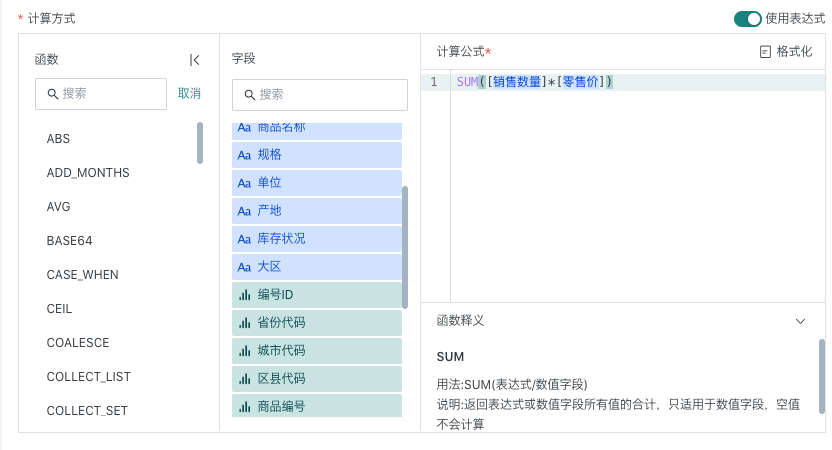
| 计算方式 |
|
| 数据格式 | 设置指标结果的展示格式。 |
| 适用维度 | 选择数据集中的字段作为维度,后续可进行不同维度下的指标分析。 适用维度中有时间字段时,可被选为时间维度,用于后续进行时间相关的衍生配置。  |
| 筛选条件 | 支持添加多条筛选条件,计算指标值时将根据筛选条件来进行最终结果计算。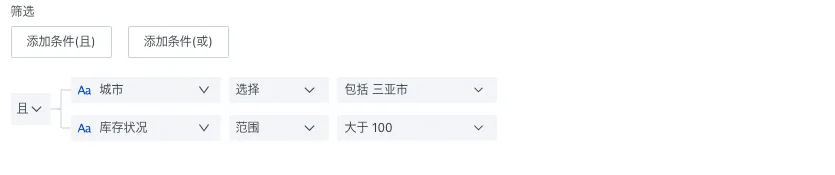 |
| 业务口径 | 维护指标的业务含义,便于后续进行指标的应用。 |

管理属性:
| 参数 | 说明 |
|---|---|
| 保存位置 | 设置该指标的保存位置。 |
| 责任人 | 业务口径的解释对象,为业务口径的合理性和准确性负责。 |
查询加速
原子指标详情页中增加配置查询加速,支持配置多组指标的来源数据集、来源字段和聚合方式(仅支持 sum 和 count)。并支持进行优先级排序,查询指标数据时优先从优先级高的数据集中查询。
原则上指标在明细表上创建,配置足够全的适用维度。关联查询加速的表为该表的汇总表/降维表。
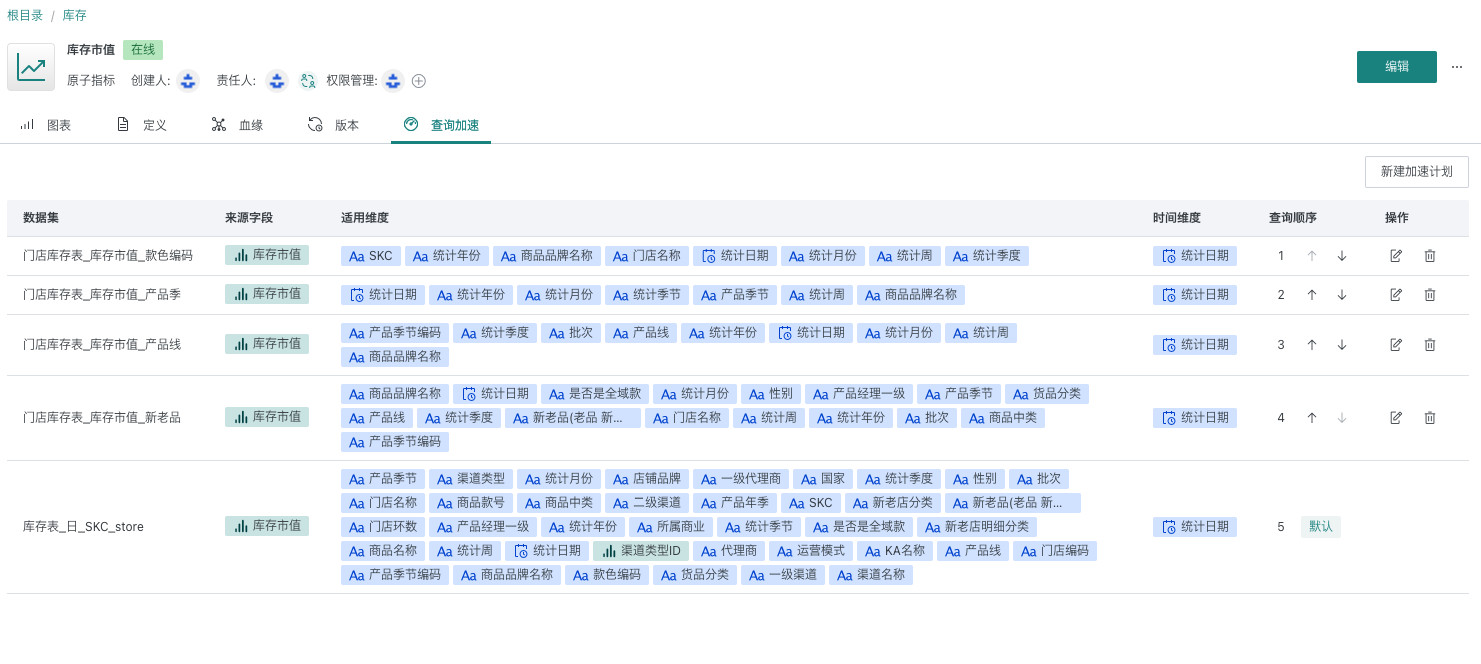
例:原子指标 sum(销售额),指标定义时的来源数据集是表 1,维度为 省 市 区 门店。关联表为 表 2 和 表 3。优先级设置为表 3 > 表 2 > 表 1。
表 1
| 省 | 市 | 区 | 门店 | 销售额 |
|---|---|---|---|---|
| A | A | A | a | 1 |
| A | A | A | b | 2 |
| B | B | B | c | 3 |
| C | C | C | d | 4 |
| C | D | D | f | 5 |
表 2
| 省 | 市 | 区 | 销售额 |
|---|---|---|---|
| A | A | A | 1+2 |
| B | B | B | 3 |
| C | C | C | 4 |
| C | D | D | 5 |
表 3
| 省 | 销售额 |
|---|---|
| A | 1+2 |
| B | 3 |
| C | 4+5 |
-
维度和筛选的字段 都存在表3中时,走表3查询;
-
表3中没有适用维度则看表2中是否存在,走表2查询;
-
表3和表2都没有适用维度则再直接走表1查询。
样例
(1)库存市值
计算逻辑:统计日期内,各门店库存市值=商品吊牌价* 库存量
表结构:日期、门店、品类、SKC、价格、库存数量
- 计算口径:
sum(价格 * 库存量)
- 适用维度:门店、品类、日期
(2)在手款色数
计算逻辑:统计门店有库存的商品款色个数
表结构:日期、门店、SKC、在手库存量
- 计算口径:
count(distinct concat(`门店`, '_', `SKC`)
- 适用维度:日期、门店
- 筛选:在手库存量 > 0
(3)研发人天统计
计算逻辑:研发人天=总工时/标准工作小时。2025 年以前每天标准工作小时为 7 小时,2025 年以后每天标准工作小时为 8 小时,统计日期内平均人天
表结构:日期、总工时
- 计算口径:
SUM(CASE
WHEN ([日期] < '2025-01-01') THEN ([总工时])/7
ELSE [总工时]/8
END
)
- 适用维度:日期