从数据库接入数据概述
1. 从数据库接入数据概述
从数据库接入数据,是指观远数据提供的从多种数据库(包含存储过程)进行数据源接入的功能服务,观远数据目前支持通过两种途径接入各类数据库。
-
支持35+种标准数据库接入:包括但不限于MySQL、PostgreSQL、 Greenplum、 SQL Server、 Oracle、Presto、Amazon Redshift、MaxCompute、SAP HANA、Teradata、BW、TiDB、Doris、Vertica、Netsuite、ClickHouse、Hive、IBM DB2、HAWQ、AnalyticDB、Gbase 8t、Informix、Kylin、Impala、Sybase、MangoDB、Druid、Trino、DAMENG、Snowflake、StarRocks、CirroData、Access等。
-
自助式对接外部数据库:支持用户自助式对接云厂商、国产化等各类外部数据库,具体详见《自助式数据库连接使用指南》。
2. 从数据库接入数据操作步骤
2.1 选择连接器
进入“数据中心”后,点击右上角的“新建数据集”,随后点击“数据库”按钮。

创建数据库连接前,选择一种数据库连接器,进入到数据库连接配置界面。

2.2 选择账户
您可以选择一个已有的数据库连接账户,或者新建一个账户。
数据账户的创建方式有2种,第一种是先行在数据中心的“数据账户”管理界面进行创建;第二种是于创建数据集的过程中,点击“新建账户”来创建。数据库账户可以在数据中心—数据账户页面进行集中管理。
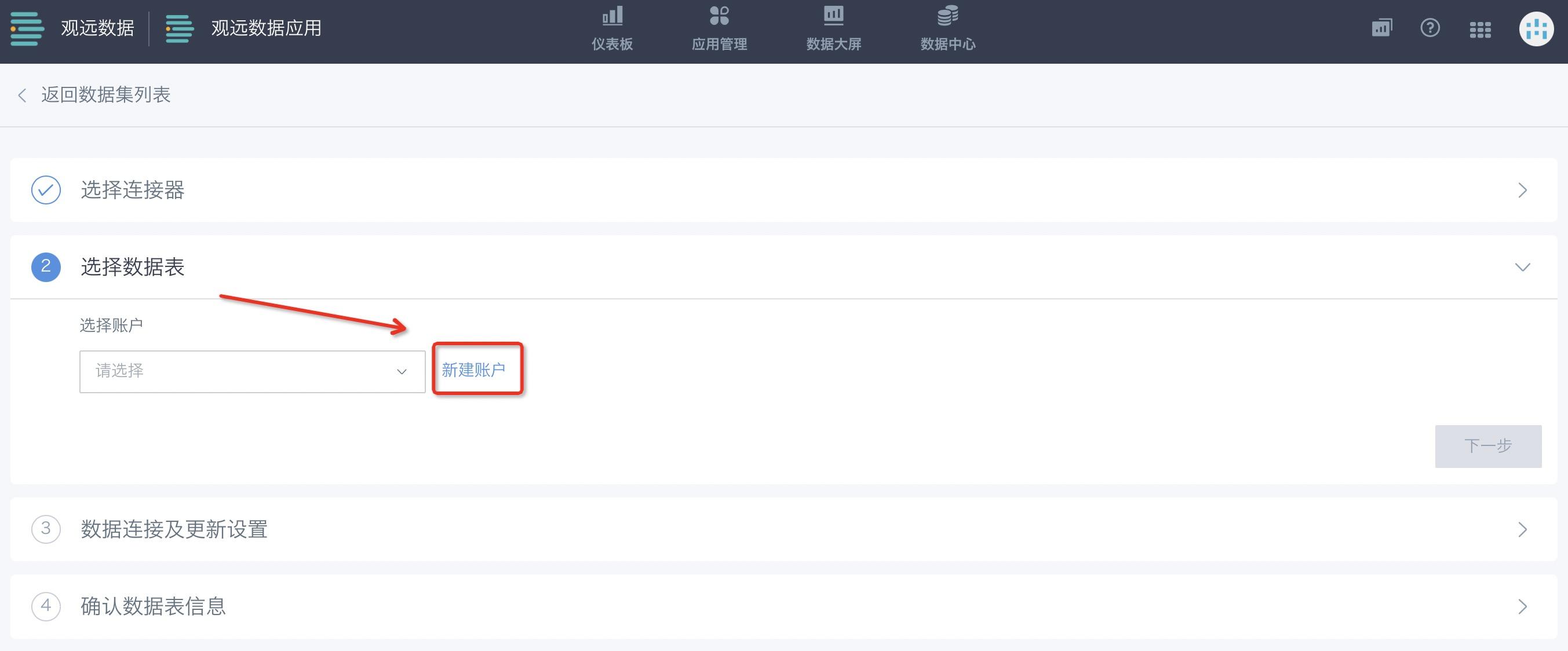
新建账户时,您需要提供数据库地址、用户名、密码、数据库名称、端口号等信息。测试连接成功后,便可以创建新的账户。
2.3 数据库查询
模式一:SQL 查询
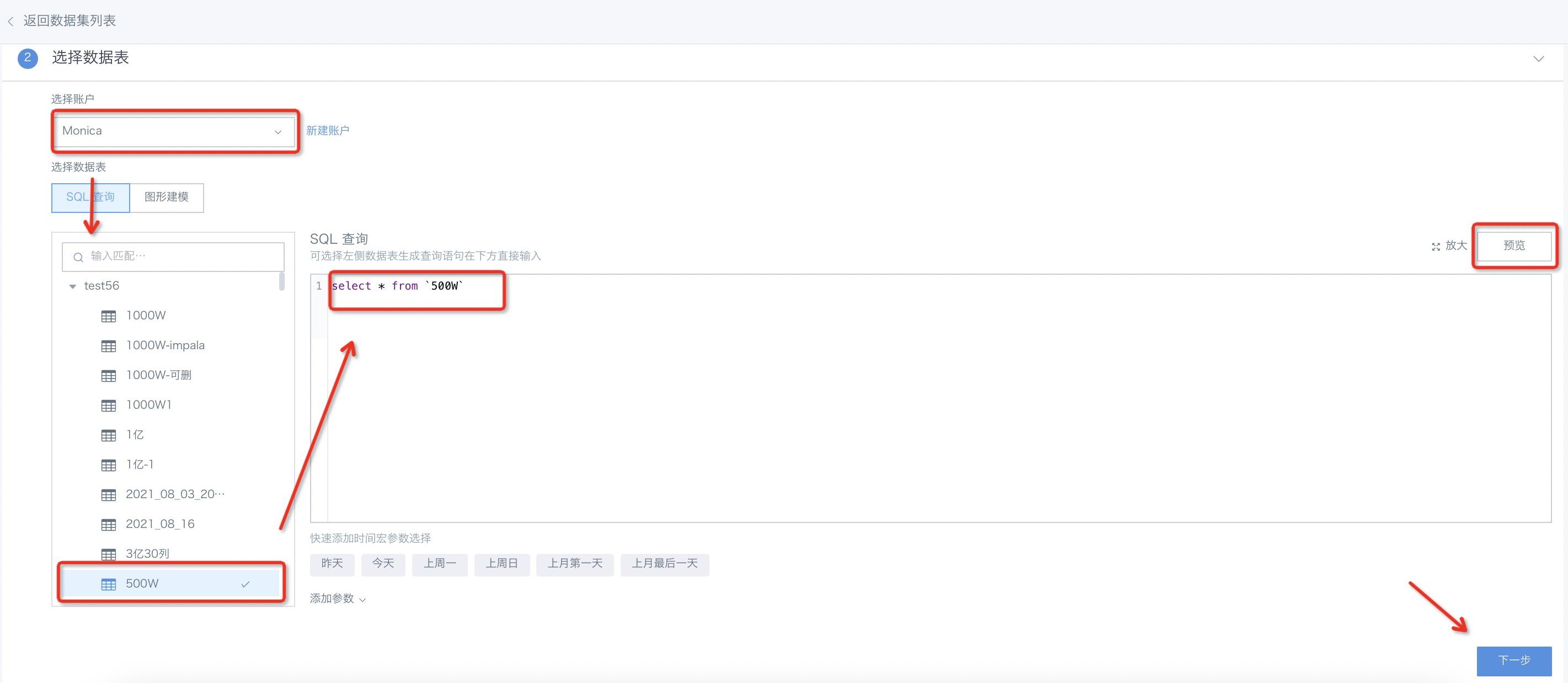
左侧为当前连接数据库中的数据表,选择数据表可快速输入SQL语句。您也可以根据自己的需要在中间“SQL 查询”区域填写查询语句。
输入框下方有“时间宏”供您选择,为数据更新与动态分析设置时间要求。观远数据的SQL时间宏,可以帮助您根据当前日期生成动态SQL,在定时刷新数据与增量更新时,非常有用。例如我们可以输入这样的SQL语句:
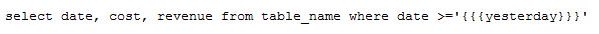
更多使用方式可具体查看《动态时间宏》文档。点击“时间宏”下方的“添加参数”功能,可以使用参数来实现数据分析维度的切换。更多使用方式可查看《全局参数》文档。
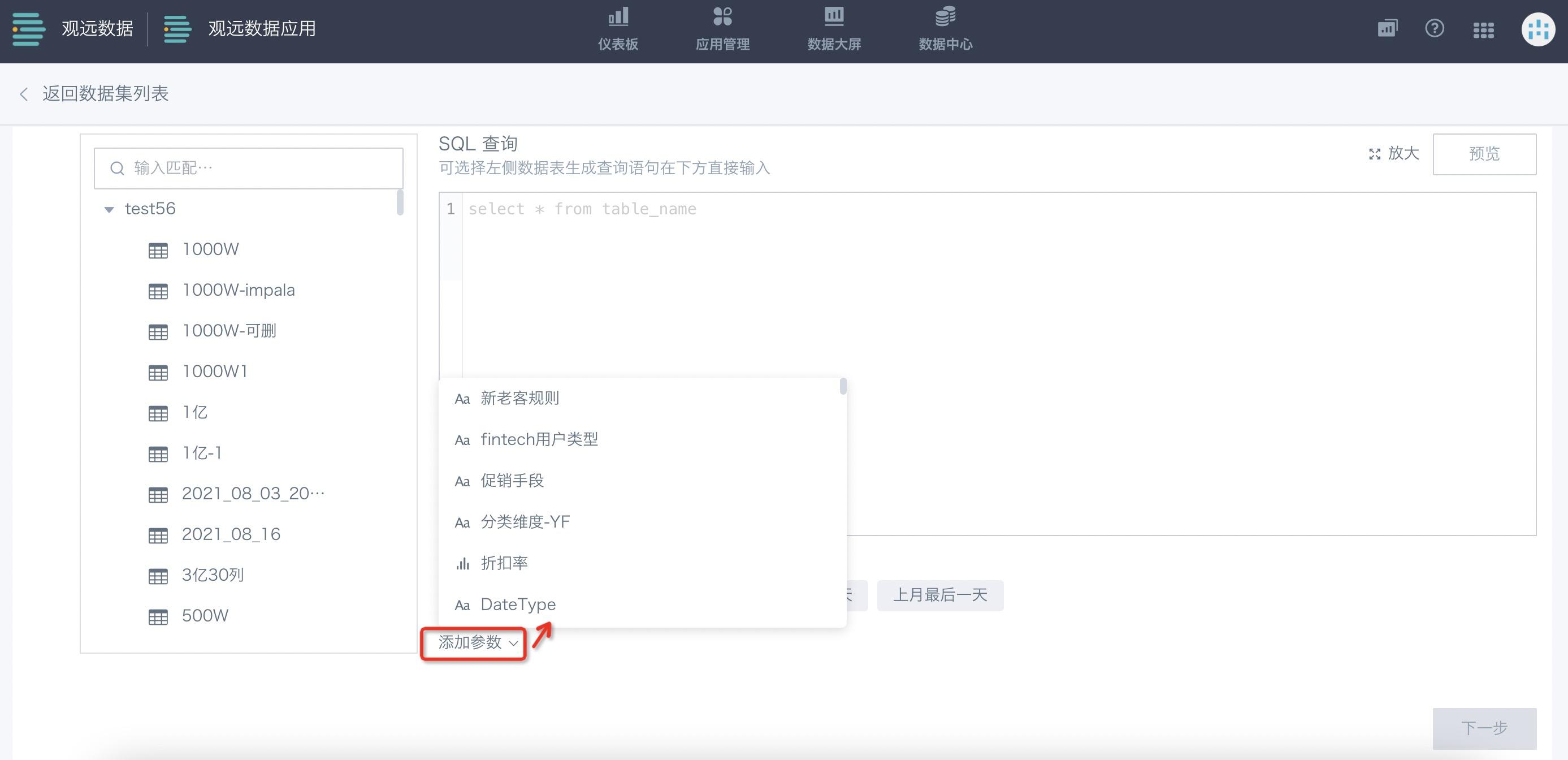
数据预览成功后,可进入到下一步。
报错详见 column ambiguously defined
模式二:图形建模
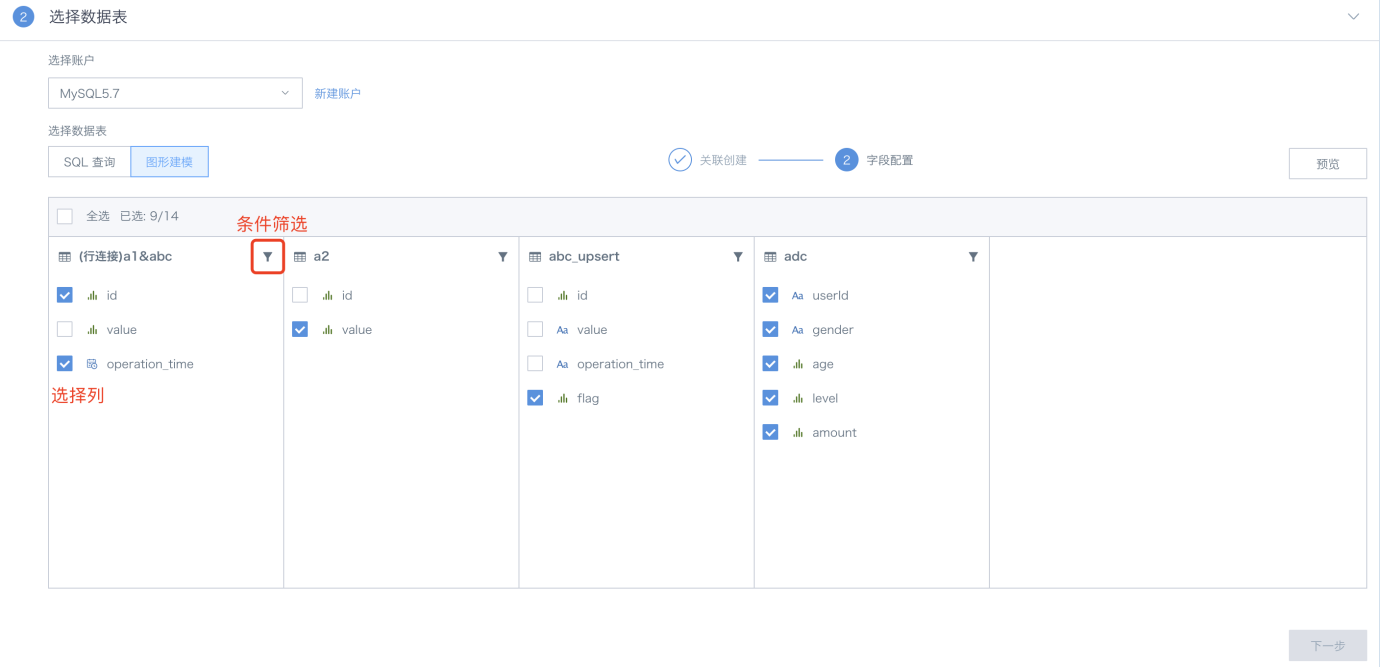
图形建模,是观远数据为了降低数据对接过程中的操作门槛,方便非技术同事也能更快更好进行数据连接工作,而提供的进行表和表之间关联操作的功能。在创建数据集的开始,选择MySQL或Impala后,即可在数据库查询环节,选择“图形建模”方式(目前仅支持MySQL与Impala对接)。针对已创建的数据集,在修改模型结构时,也支持图形建模方式,操作方式不变,具体如下:
a. 从数据集列表中采用拖拽的方式将数据集添加进入“关联创建”画布中:选择需要的一张或多张数据表,若选择多张数据表,则需要关联或者拼接成一张宽表;
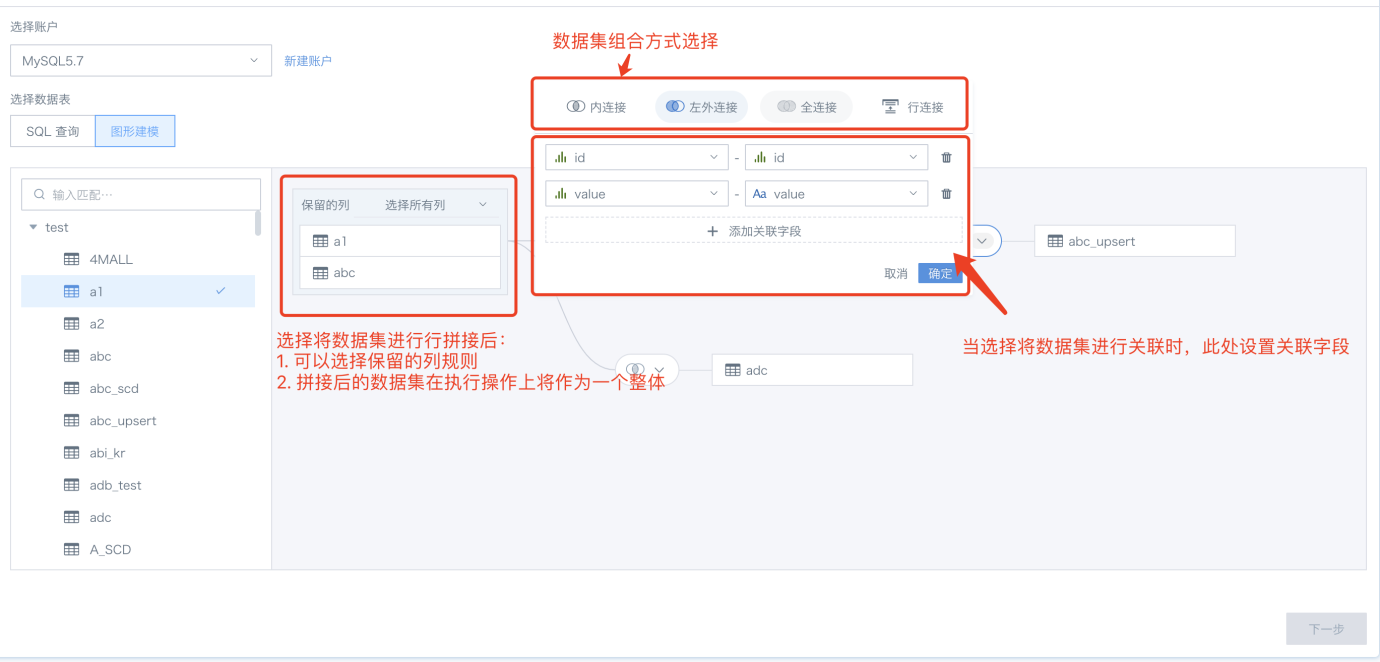
b. 当拖入2张表时,默认选择内连接方式,若两张表存在同名字段,会优先自动将同名字段作为外键进行关联;用户也可通过手动方式增减以及设置关联条件;
c. 关联创建支持内连接、左外连接、全连接以及行拼接(支持的操作会协同数据库本身,如MySQL本身不支持全连接在关联创建中也不支持全连接);
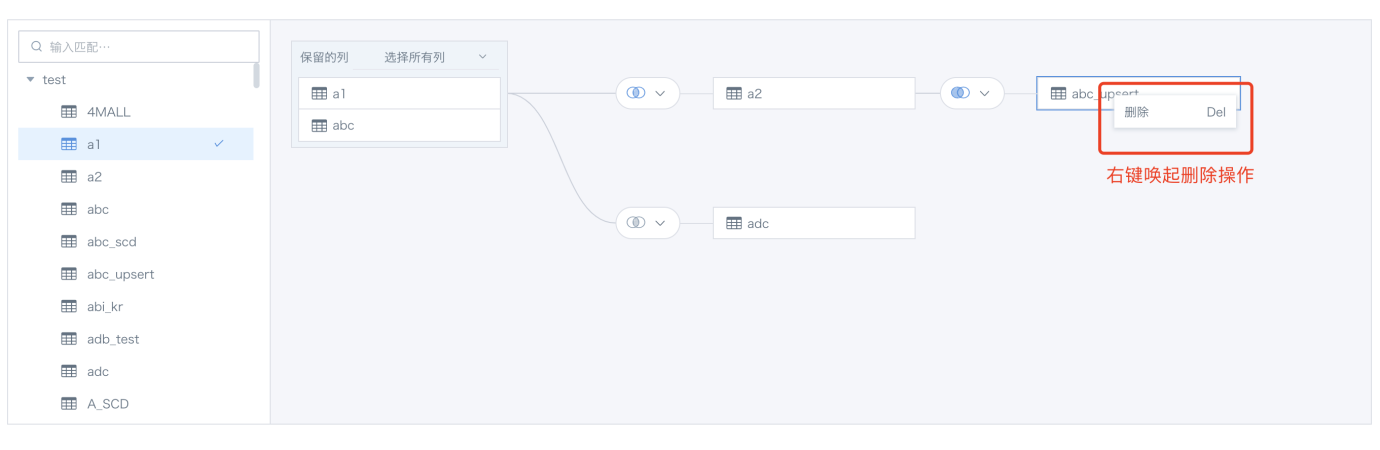
d. 当不再需要该数据集时,可右键唤起删除操作进行删除;
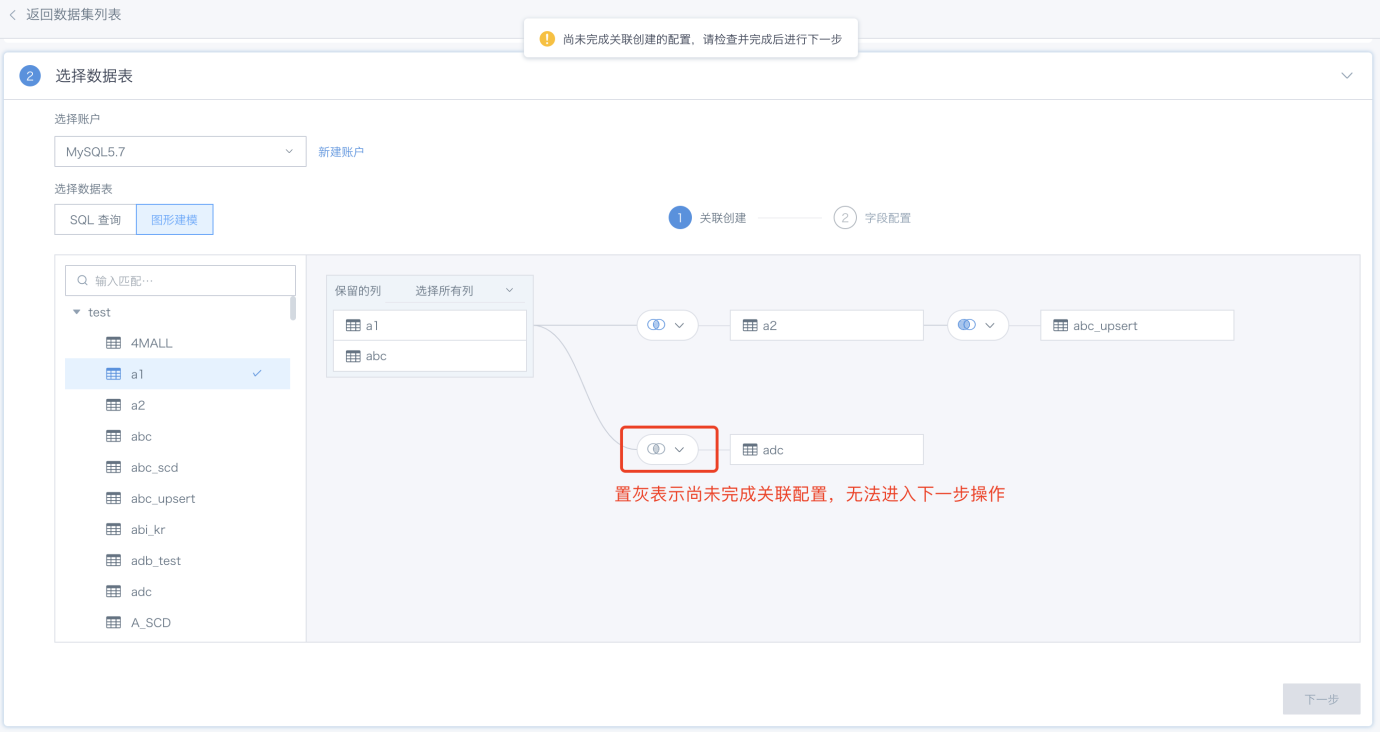
e. 需要设置完成所有关联关系,才可以进入到第二步“字段配置”;
f. 完成关联创建后,进入到字段配置,进行选择列以及条件筛选环节;
g. 预览数据集无问题后,可进入下一步操作。
2.4 选择数据库连接方式与更新周期
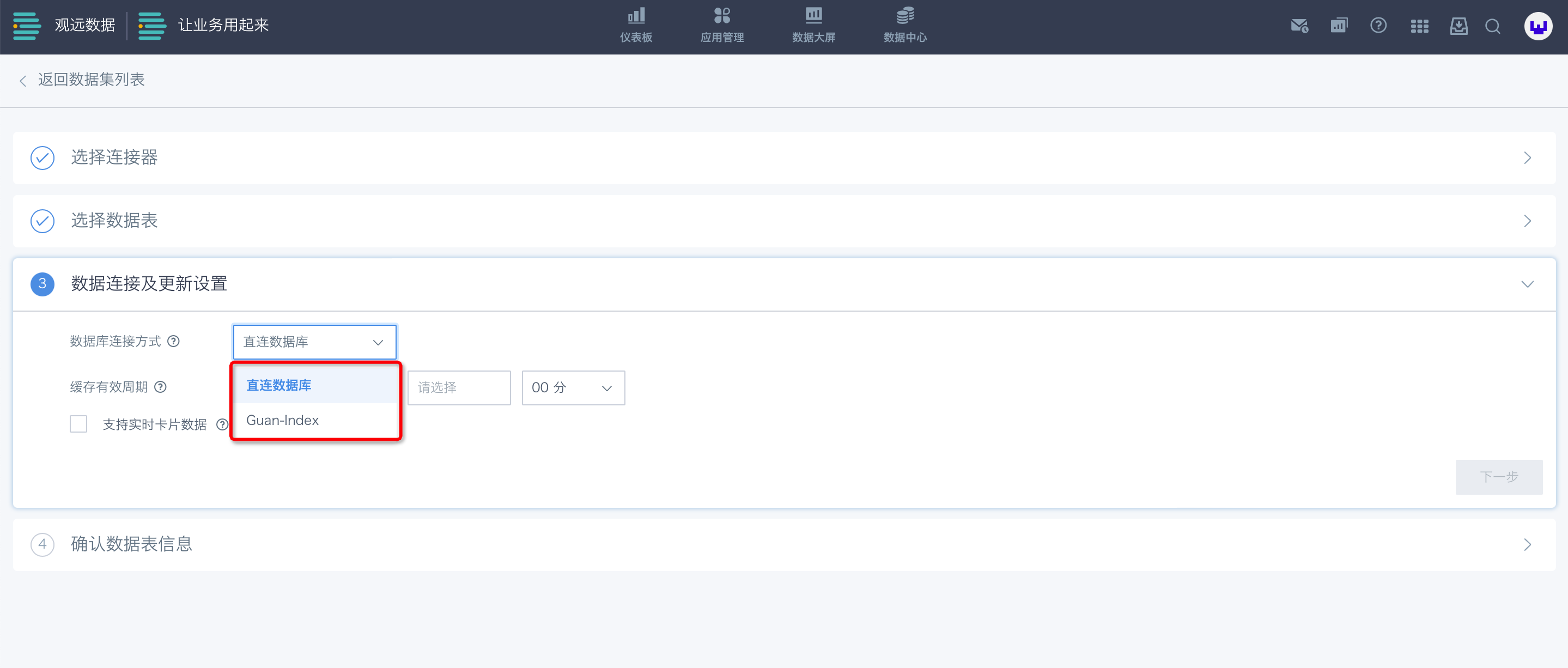
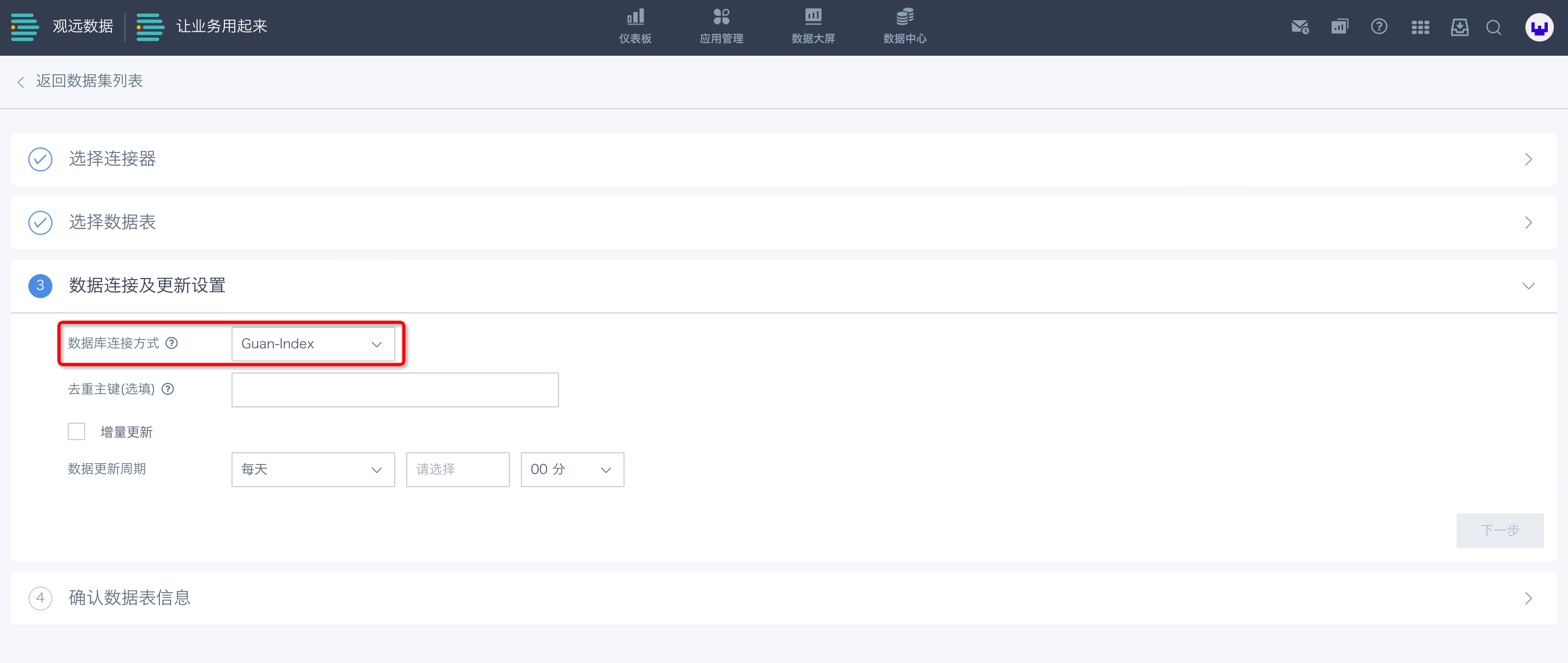
观远数据支持“直连数据库”与“Guan-Index”两种数据库连接方式。
点击数据库连接方式的选择框,选择“直连数据库”或“Guan-Index”,并设置数据更新的周期,以及是否支持实时卡片数据。
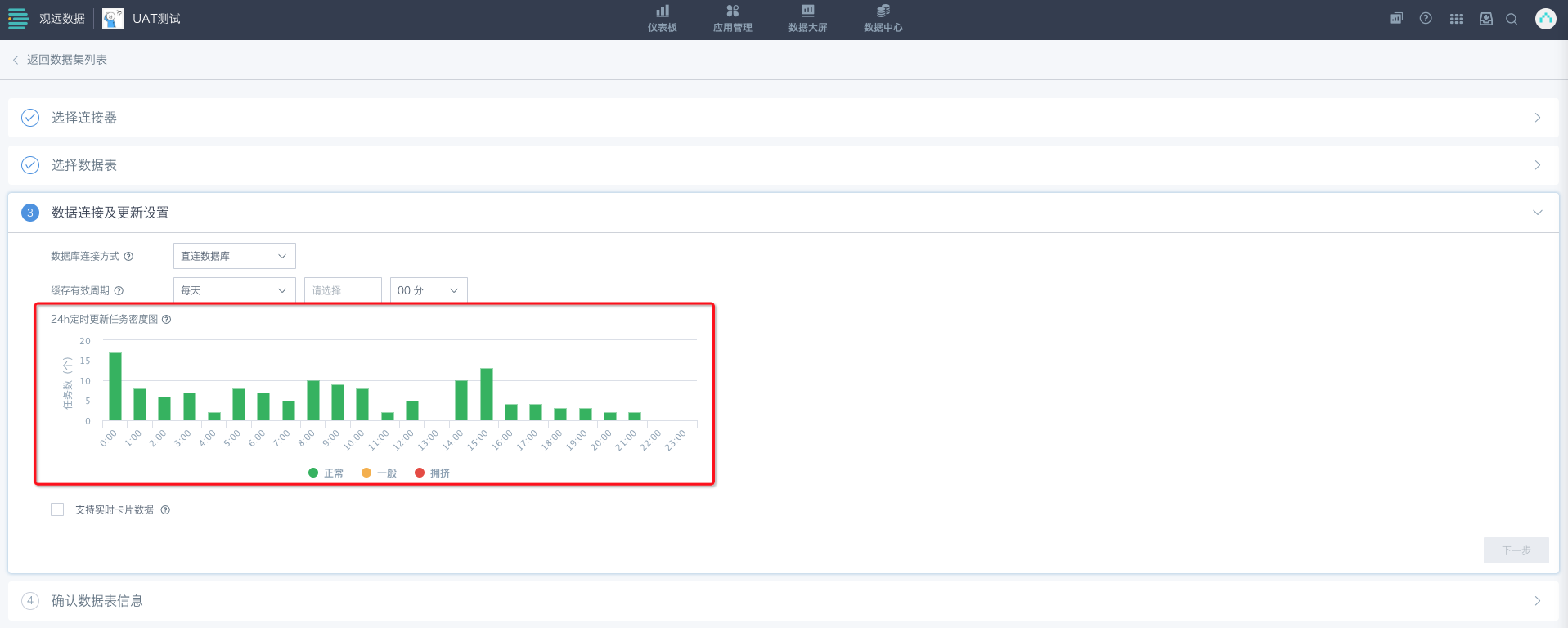
如果开通了“24h定时更新任务密度图功能”,功能开启后,缓存有效周期选择每天/每周/每月,则会展示定时更新任务密度图(如需使用该功能,请联系观远人员协助开启)。
直连数据库
直连数据库,是指选择“直连数据库”时,卡片数据将直接从数据库获得。
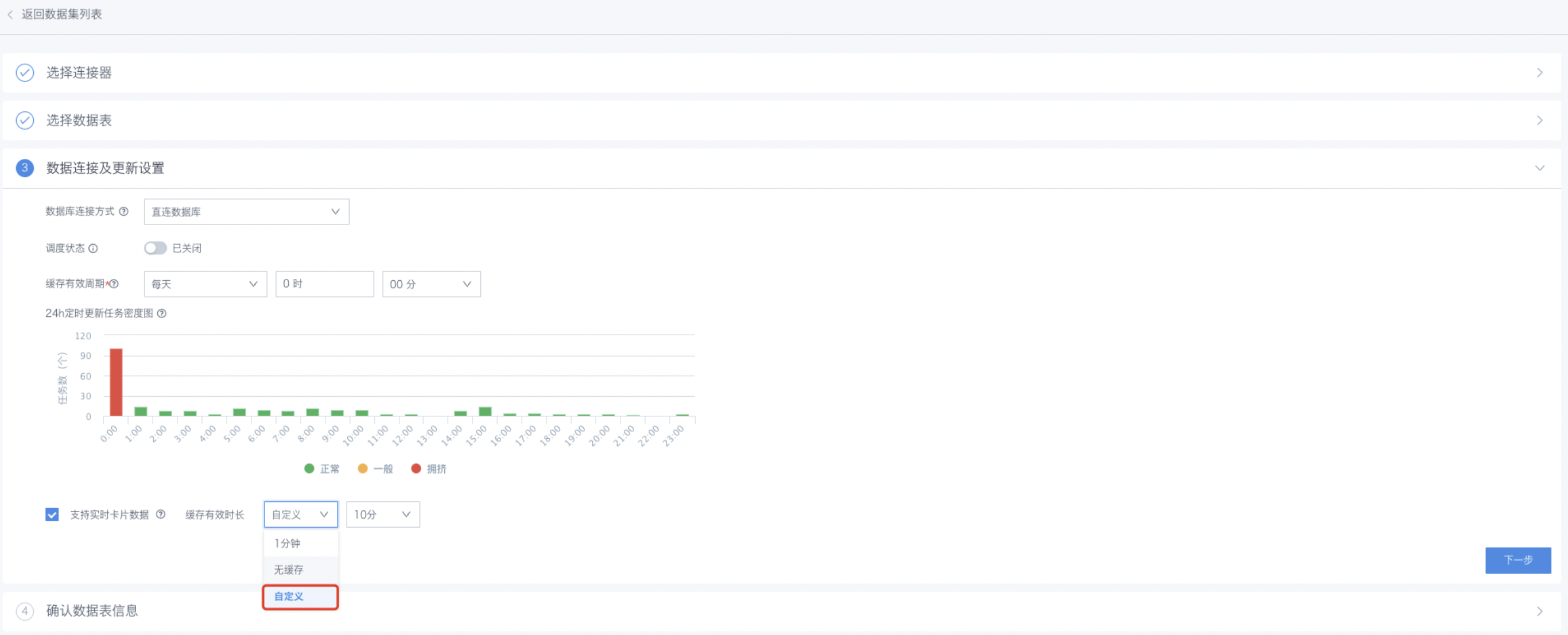
您需要配置数据更新周期,以及选择是否支持实时卡片数据。设置数据更新周期,即“缓存有效周期”,作用是定时更新与该数据集相关的所有卡片、卡片数据集、ETL、JOIN等的数据。“支持实时卡片数据”是指建在该数据集上的卡片,可支持更短周期的数据更新,当前默认为1分钟;也可支持自定义有效周期,可选范围为1分-30分。
Guan-Index
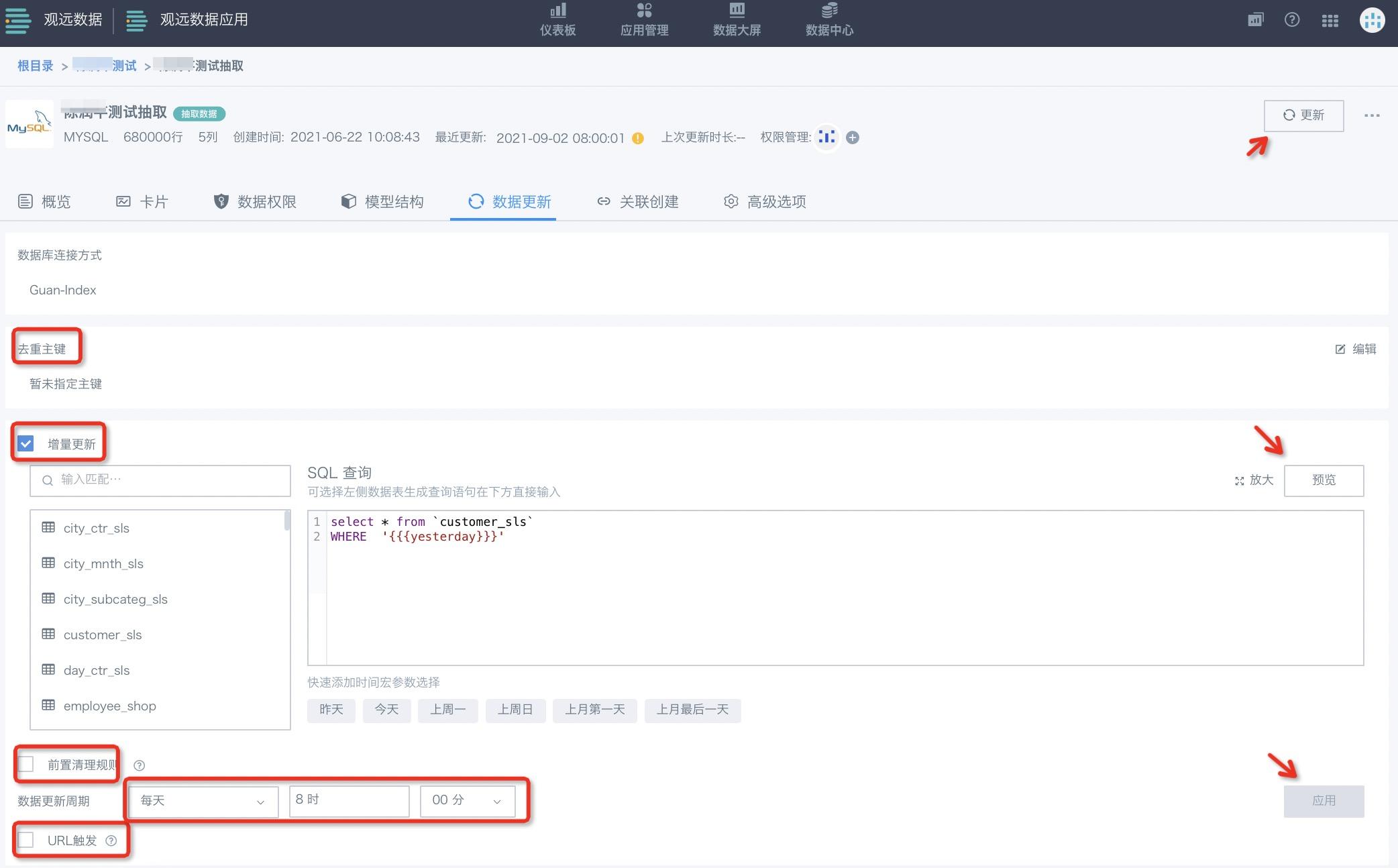
Guan-Index,是指数据被抽取到观远服务器后将构建物理数据集,支持增量更新。具体使用步骤如下:
-
首先,当您选择Guan-Index模式时,支持添加全局参数;详见《全局参数》
-
其次,若您要对数据集进行增量更新或未来有设置增量更新的可能,可以通过点击选择“去重主键”,对未来需要增量更新的字段进行设置。
-
再次,如点击“增量更新”,您可以填写SQL来设置增量更新的条件,通常与时间宏参数配合进行。
-
最后,设置数据更新周期,即可进入“下一步”。
2.5 确认数据集信息
确定数据集名称与保存位置
为您的数据集提供一个方便辨识的名字,以及指定保存位置。点击确认后,数据集创建成功,可以在“数据中心”-“数据集”中找到它。需要注意的是,若创建的是Guan-Index数据集,您可能需要等待一段时间,等数据抽取完成后可以在“数据中心”看到正确的数据集信息。
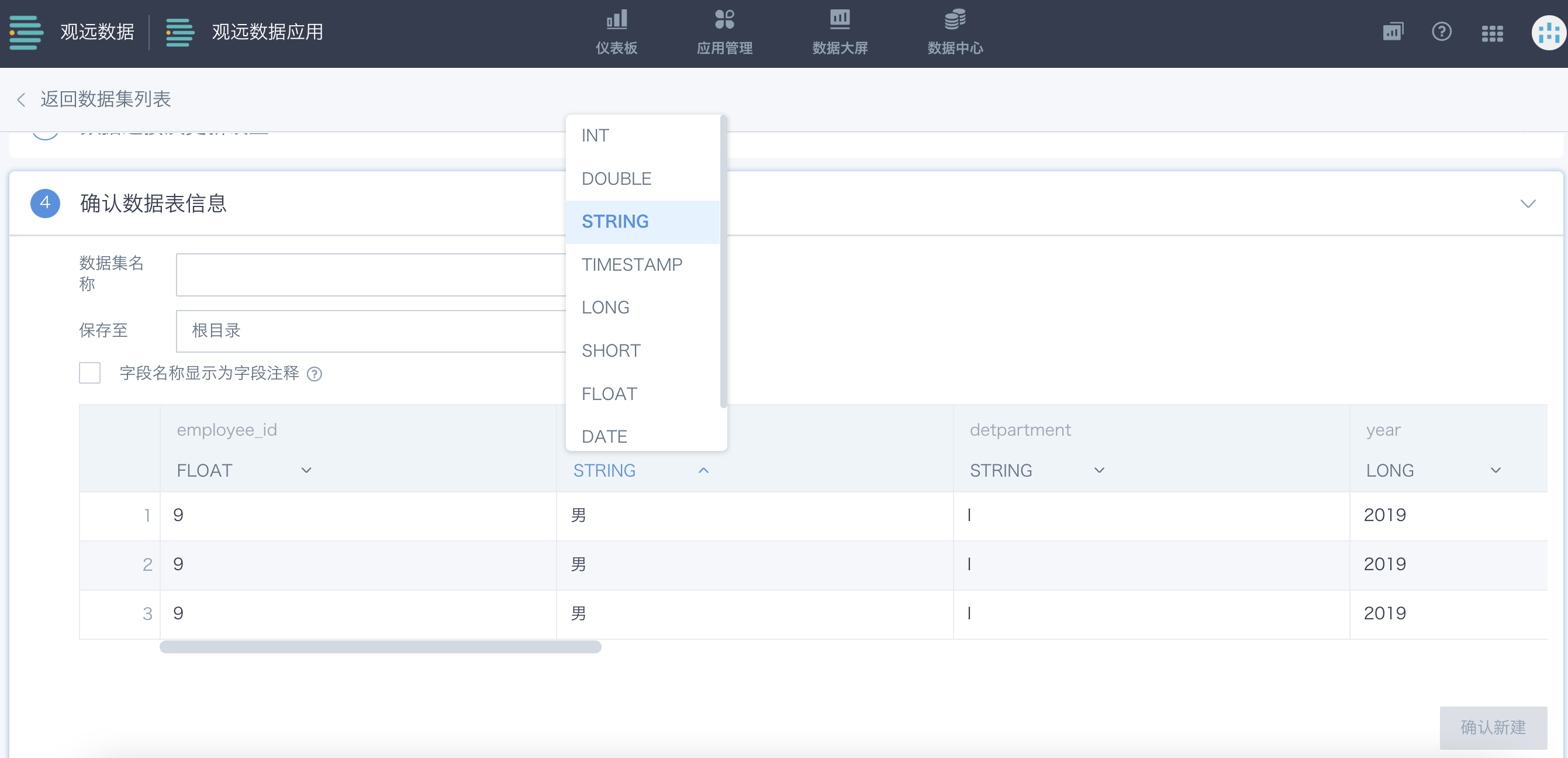
支持字段重命名
当字段名需要修改时,点击字段名右侧的小箭头,即可打开下拉框,修改字段名。修改好之后,下游引用此数据集的计算字段、ETL节点将会自动继承修改好的字段名。
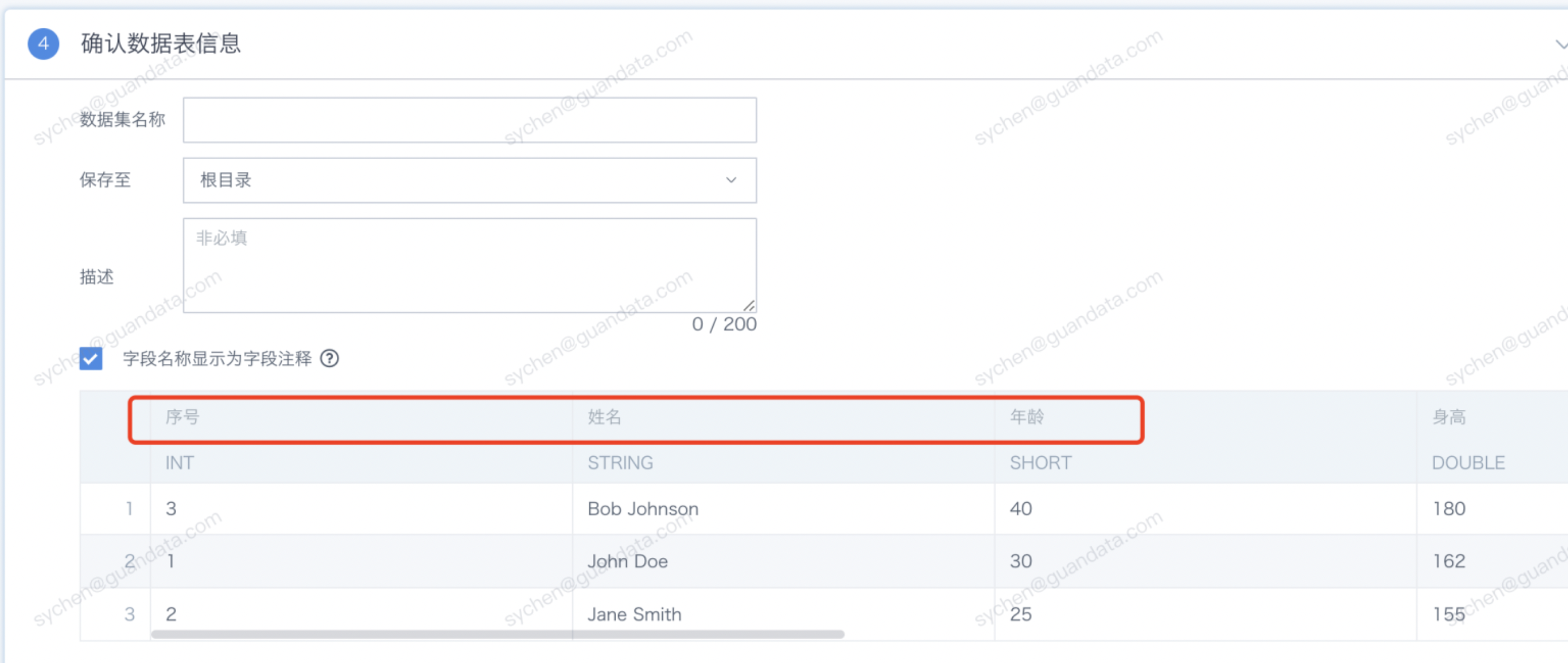
字段名称显示为字段注释
若勾选“字段名称显示为字段注释”,字段名称将自动同步成数据库中已设置的字段注释。当企业的IT部门构建应用层宽表时,通常在数仓或者数据库环境会将宽表的数据集字段中文名称标注在表结构的 comments 中。当 BI 在对接宽表时,可通过此功能直接将原表 comments 中的字段注释直接覆盖成字段名称,减少手动修改的重复工作。(*注意:该功能现只支持单表数据集,当前支持的数据库包含:MySQL、Hive、Impala、Presto、ADB、ClickHouse、MaxCompute、GaussDB、StarRocks、GBase)
2.6 数据更新
数据更新设置
数据集创建完后,您可以在创建的数据集详情中,点击“数据更新”。
对于直连数据库数据集(简称直连数据集)类型,可以设置“缓存有效周期”(即更新周期)为手动更新/每天/每周/每月4种方式,如为定时更新还可具体设置几时几分。勾选“支持实时卡片数据”,默认时长为1分钟。勾选“URL触发”后即可点击“复制链接”来复制URL。
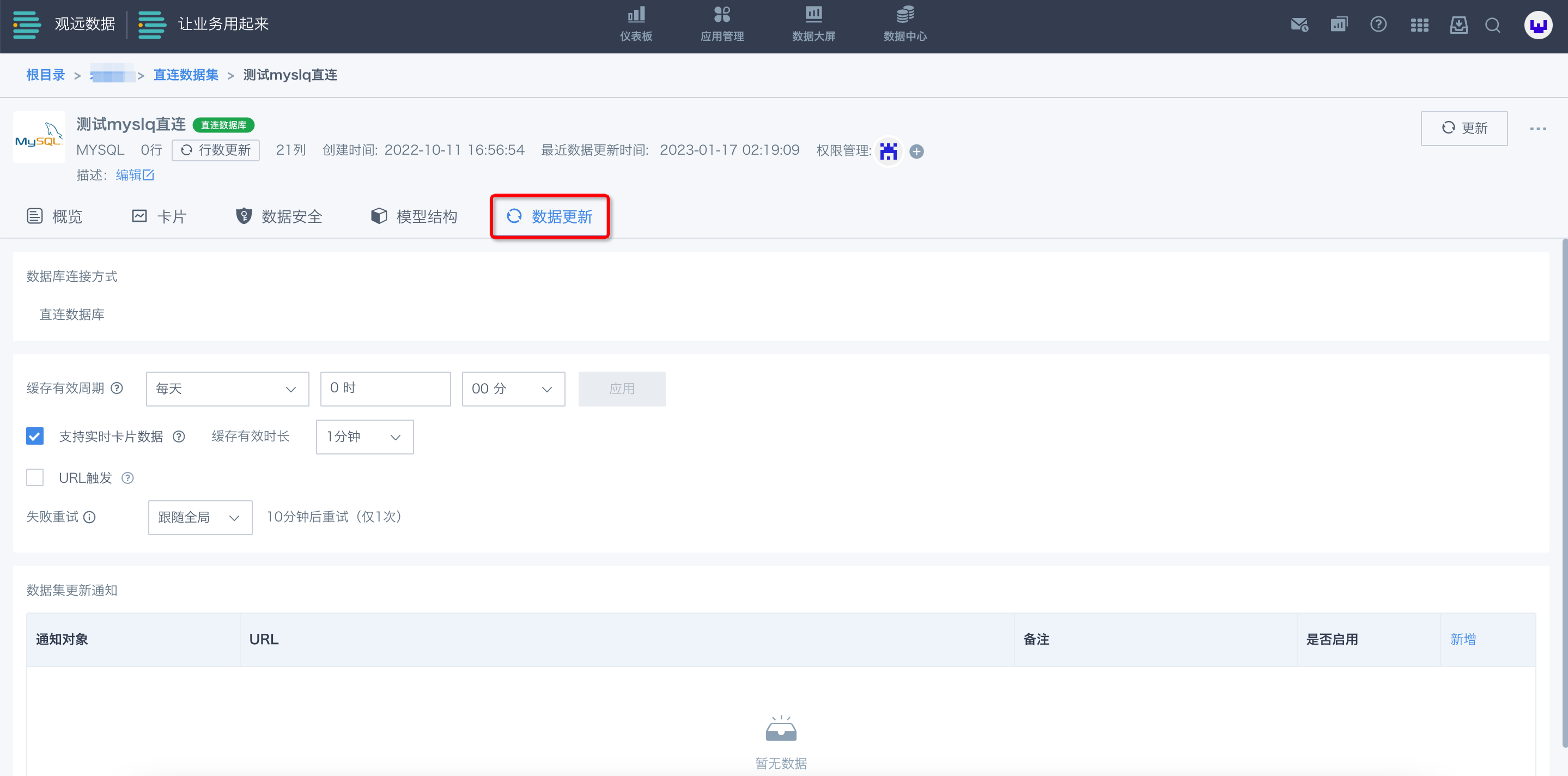
在更改“数据更新”的相关配置之外,您也可以手动触发数据集的更新,点击右上角的“更新”按钮即可(更新方式分为添加新数据、覆盖旧数据两种模式)。
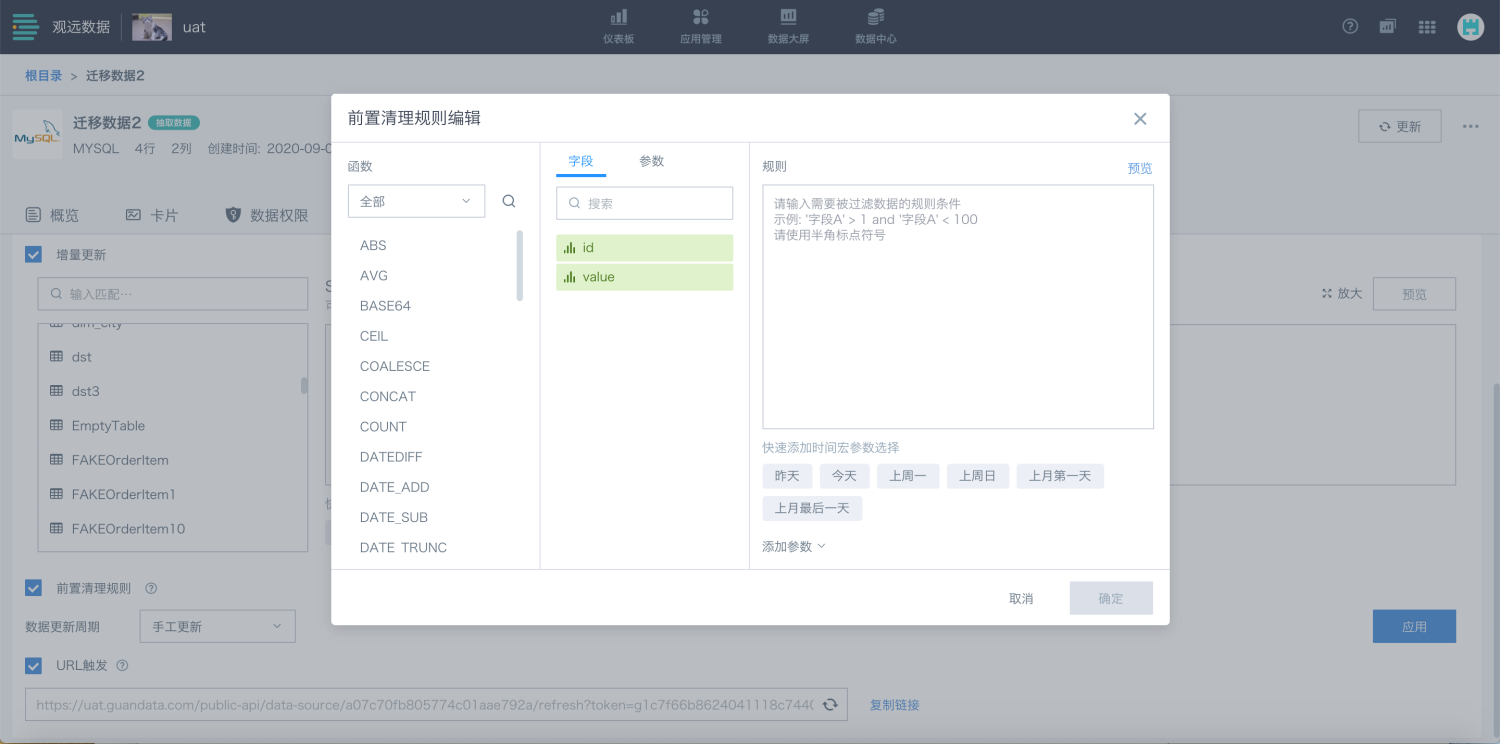
前置清理规则
对于Guan-Index数据集类型,在设置“缓存有效周期”与勾选“URL触发”以外,可以设置去重主键(去重主键相关信息可参考《从文件导入数据》)。以及在开启增量更新下,设置前置清理规则,在过滤规则编辑器中自定义提前过滤掉指定时间范围/指定ID范围内的数据(等于删除操作),随后再进行增量更新操作。
在前置清理规则编辑框中,您可以根据需要,选择更新的字段,用“时间宏”设置动态时间,以及添加参数,设定规则。
查看更新历史
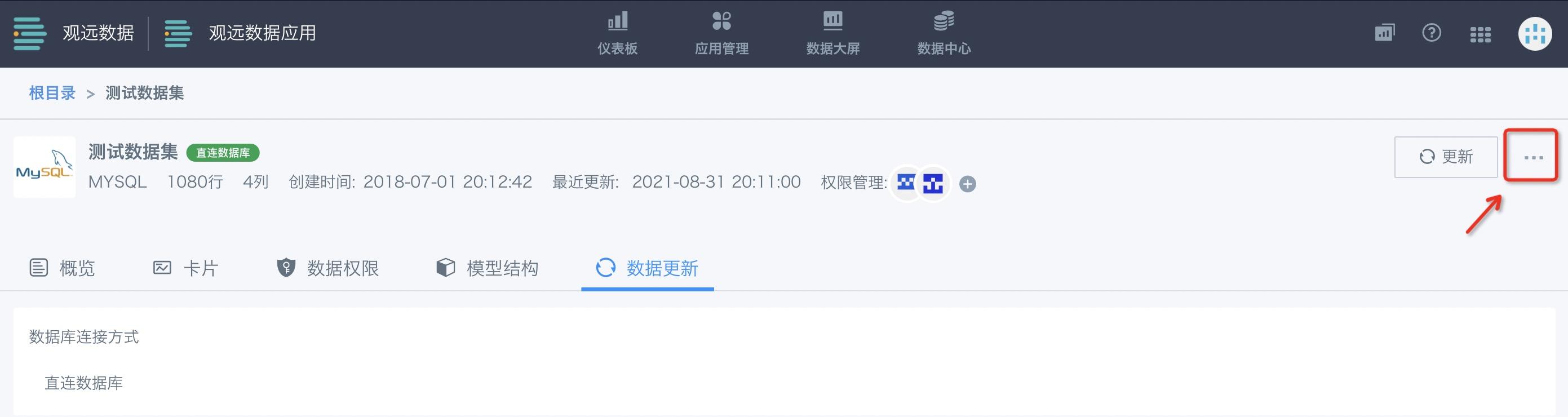
点击数据集详情页的右上角“更新”右侧的操作栏,即可找到“查看更新历史”的入口,点击进入更新历史详情页。

3. 名词解释
3.1 数据库
通常,人们在提起数据库时,是指其作为一个按数据结构来存储和管理数据的计算机软件系统。数据库的概念实际包括两层意思:第一,数据库是一个实体,它是能够合理保管数据的“仓库”,用户在该“仓库”中存放要管理的事务数据,“数据”和“库”两个概念结合成为数据库;第二,数据库是数据管理的新方法和技术,它能更合适的组织数据、更方便的维护数据、更严密的控制数据和更有效的利用数据。
4. 常见问题
连接数据库时,数据库版本要求是什么?
在连接数据库时,观远数据对于数据库的最低版本有一定的要求。当前支持的数据库及其最低版本号清单如下:
| 数据库 | 最低版本要求 |
| MySQL | ≥5.5 |
| PostgreSQL | ≥12.5 |
| Greenplum | ≥4.3 |
| SQL Server | ≥2008R2 |
| Oracle | ≥11g |
| Presto | ≥0.198 |
| Amazon Redshift | ≥1.2.7 |
| MaxCompute | ≥1.0 |
| SAP HANA | ≥2.0 |
| Teradata | ≥13 |
| 星环 TransWarp | ≥4.6.3 |
| SAP BW | ≥7.5 |
| TiDB | ≥2.1.0 |
| Doris | ≥0.8.0 |
| Vertica | ≥9.1.1 |
| Netsuite | ≥1.0 |
| ClickHouse | ≥19 |
| Hive | ≥2.1 |
| IBM DB2 | ≥10.2 |
| HAWQ | ≥2.4.0.0 |
| AnalyticDB | ≥0.8.0 |
| Gbase 8t | ≥12.10 |
| Informix | ≥12.10 |
| Kylin | ≥2.6.2 |
| Impala | ≥2.1.2 |
| Sybase | ≥12.10 |
| MongoDB | ≥4.4.1 |
| Druid | ≥1.9.0 |
| GaussDB | ≥8.1.3 |
| DLI | \ |
| Trino | ≥358 |
| 达梦 DAMENG | ≥7 |
| Snowflake | 6.29.1 |
| StarRocks | ≥2.3.0 |
| CirroData | \ |
| Access | \ |