正则表达式的基本使用
正则表达式常用语法
分类 | 字符 | 描述 |
普通字符 | [ ] | 匹配 [ ] 中的所有字符,例如 [aeiou] 匹配字符串 "google runoob taobao" 中所有的 e o u a 字母。 |
[^ ] | 匹配除了 [ ] 中字符的所有字符,例如 [^aeiou] 匹配字符串 "google runoob taobao" 中除了 e o u a 字母的所有字母。 | |
[A-Z][a-z] | [A-Z] 表示一个区间,匹配所有大写字母,[a-z] 表示所有小写字母。 | |
. | 匹配除换行符(\n、\r)之外的任何单个字符,相等于 [^\n\r]。要匹配 . ,请使用 \. 。 | |
[\s\S] | 匹配所有。\s 是匹配所有空白符,包括换行,\S 非空白符,包括换行。 | |
\w\W | \w匹配字母、数字、下划线。等价于 [A-Za-z0-9_];\W匹配非字母、数字、下划线。等价于 '[^A-Za-z0-9_]'。 | |
\d\D | \d匹配数字0-9,等价于[0-9];\D:匹配任意非数字字符 | |
非打印字符 | \cx | 匹配由x指明的控制字符。例如, \cM 匹配一个 Control-M 或回车符。x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 'c' 字符。 |
\f | 匹配一个换页符。等价于 \x0c 和 \cL。 | |
\n | 匹配一个换行符。等价于 \x0a 和 \cJ。 | |
\r | 匹配一个回车符。等价于 \x0d 和 \cM。 | |
\s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。注意 Unicode 正则表达式会匹配全角空格符。 | |
\S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 | |
\t | 匹配一个制表符。等价于 \x09 和 \cI。 | |
\v | 匹配一个垂直制表符。等价于 \x0b 和 \cK。 | |
特殊字符 | $ | 匹配输入字符串的结尾位置。如果设置了 RegExp 对象的 Multiline 属性,则 $ 也匹配 '\n' 或 '\r'。要匹配 $ 字符本身,请使用 \$。 |
( ) | 标记一个子表达式的开始和结束位置。子表达式可以获取供以后使用。要匹配这些字符,请使用 \( 和 \)。 | |
[ | 标记一个中括号表达式的开始。要匹配 [,请使用 \\[。 | |
\ | 将下一个字符标记为或特殊字符、或原义字符、或向后引用、或八进制转义符。例如, 'n' 匹配字符 'n'。'\n' 匹配换行符。序列 '\\' 匹配 "\",而 '\(' 则匹配 "("。 | |
^ | 匹配输入字符串的开始位置,除非在方括号表达式中使用,当该符号在方括号表达式中使用时,表示不接受该方括号表达式中的字符集合。要匹配 ^ 字符本身,请使用 \^。 | |
{ | 标记限定符表达式的开始。要匹配 {,请使用 \{。 | |
| | 指明两项之间的一个选择,相当于“或”。要匹配 |,请使用 \|。 | |
限定符 | * | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 "z" 以及 "zoo"。* 等价于{0,}。 |
+ | 匹配前面的子表达式一次或多次。例如,'zo+' 能匹配 "zo" 以及 "zoo",但不能匹配 "z"。+ 等价于 {1,}。 | |
? | 匹配前面的子表达式零次或一次。例如,"do(es)?" 可以匹配 "do" 、 "does" 中的 "does" 、 "doxy" 中的 "do" 。? 等价于 {0,1}。 | |
{n} | n 是一个非负整数。匹配确定的 n 次。例如,'o{2}' 不能匹配 "Bob" 中的 'o',但是能匹配 "food" 中的两个 o。 | |
{n,} | n 是一个非负整数。至少匹配n 次。例如,'o{2,}' 不能匹配 "Bob" 中的 'o',但能匹配 "foooood" 中的所有 o。'o{1,}' 等价于 'o+'。'o{0,}' 则等价于 'o*'。 | |
{n,m} | m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。例如,"o{1,3}" 将匹配 "fooooood" 中的前三个 o。'o{0,1}' 等价于 'o?'。请注意在逗号和两个数之间不能有空格。 |
Spark正则函数
分类 | 用途 | 函数 | 举例 | 结果 |
校验 | 判断字符串是否匹配正则表达式, 返回true/false/null | regexp(str, regexp) | regexp('abcde12345','D|d') | true |
rlike(str, regexp) | rlike('abcde12345','^A') | false | ||
regexp_like(str, regexp) | regexp_like('abcde12345','\\d+') | true | ||
截取 | 根据分组索引值截取字符串中第一个匹配正则表达式的子字符串 | regexp_extract(str, regexp[, idx]) | regexp_extract('ABCDE/ab(cde)','[A-Za-z]+',0) | ABCDE |
根据分组索引值截取字符串中所有匹配正则表达式的子字符串,返回一个数组 | regexp_extract_all(str, regexp[, idx]) | regexp_extract_all('100-200, 300-400', '(\\d+)-(\\d+)',1) | [100, 300] | |
替换 | 把所有匹配正则表达式的子字符串替换为目标字符串 | regexp_replace(str, regexp, rep[,position]) | regexp_replace('ABCDE/ab(cde)','[\/()]','.') | ABCDE.ab.cde. |
拆分 | 用匹配正则表达式的子字符串,把长字符串拆分为数组。limit可指定拆分后的元素数上限。 | split(str, regexp[, limit]) | split('ABCDE/ab(cde)','[\/()]') | [ABCDE, ab, cde, ] |
Spark 使用的是Java正则表达式,转义符\ 需要用 \ 进行转译。例如匹配数字,要用 \\d,不能是 \d。官方文档请参考 Spark SQL 。
应用场景
截取数字
:::note[说明]REGEXP_EXTRACT只能截取第一个符合条件的子字符串,如果字符串中有多处符合条件,则不能全部准确提取。
:::
REGEXP_EXTRACT([字符串],'\\d+',0)
注释:\d为匹配数字0-9;+为匹配1次或多次字符;
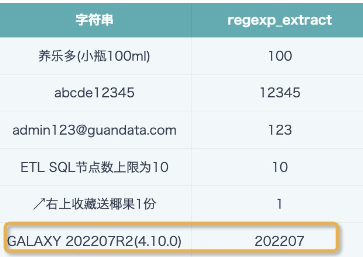
REGEXP_EXTRACT ([字符串],'\\d+\\.?\\d*',0)
注释:\\d+表示截取小数点前的数字;\\.?表示匹配0或者1位小数点;\\d*表示截取小数点后的数字,可能没有,也可能有多位;

REGEXP_EXTRACT([字符串],'\\d{1,2}\/\\d{1,2}\/\\d{2,4}',0)
注释:\\d{1,2}表示1到2位数字,用来匹配月、日;\\d{2,4}表示2至4位数字,匹配年份;\/匹配左斜杠。

截取中文
REGEXP_EXTRACT([字符串],'[\u4e00-\u9fa5]+',0)
但是这样的方法在下图黄框内的情况中并不适用,REGEXP_EXTRACT函数在截取过程中被符号或其它字符打断以后就不再匹配后面的字符了。在这种情况下可以尝试使用REGEXP_REPLACE 函数,对比效果参考下图。
REGEXP_REPLACE([字符串],'[^\u4e00-\u9fa5]+','')

注释:^符号在[ ]外的时候意义为匹配字符串开始位置的字符,而当^符号放在[ ]内则表示not,此处表示将非中文字符替换为空字符串。
截取/删除特定位置内容
REGEXP_REPLACE([字符串],'[\\[(【]\\S*[\\])】]','')
注释:[\\[(【] 匹配3种前括号,[\\])】] 匹配3种后括号;\\S* 匹配0或多个非空字符。
如果括号部分固定在字符串前面或后面,也可以采用如下写法。
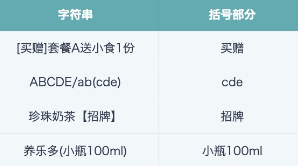
REGEXP_EXTRACT([字符串],'(\\S+)([\\[(【])',1)
REGEXP_EXTRACT([字符串],'([\\])】])(\\S+)',2)
注释:每组()为一个分组;(\\S+) 匹配0或多个非空字符, 为1个分组;([\\[(【]) 为第2个分组,匹配3种前括号;索引值1代表取第1个分组,即括号前面的所有字符;索引值2代表取第2个分组,即括号后面的所有字符。
3种用法效果对比如下图, 无匹配结果则返回空字符串。实现同一种效果可能会有多种解决方法,可根据实际场景选择合适的方法即可。
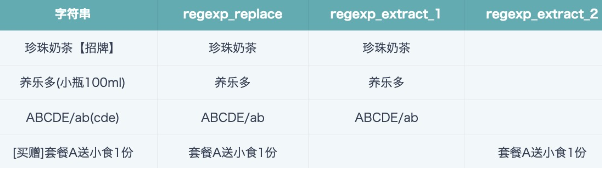
截取括号内的字符
REGEXP_EXTRACT([字符串],'([\\[(【])(\\S*)([\\])】])',2)
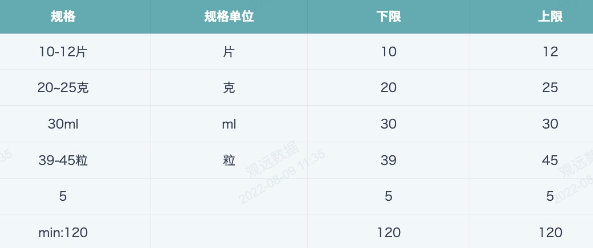
实际案例
【需求】取药品规格中的单位、上限和下限。
【思路】
规则单位:如果规格单位统一是中文的话则可使用上面说的提取中文的方法进行提取,但是如果出现了规格单位为英文的情况就不行了,所以使用以下的方法(非唯一方案)。
REGEXP_EXTRACT([规格],'[^-~\\s\\d]+',0)
解析:[^ ]表示不包含[] 集合内的所有列出来的字符,-~ 表示匹配符号‘-’和‘~’,\s表示匹配空格,\\d 表示匹配数字,最后+表示重复匹配1次或多次。综合起来,即排除‘-’、‘~’、空格和数字,取剩下的所有字符,结果如下图。此时可发现最后一行字符串里的“min:”不是规格单位,需要另外用 REGEXP_REPLACE或者 REPLACE 函数去掉多余字符。
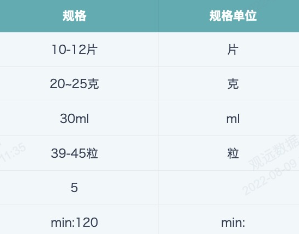
下限:取出每个记录的上下限,比如10-12片,则下限为10,上限为12 。直接用 \\d+ 截取第一个数值串即可。
REGEXP_EXTRACT([规格],'\\d+',0)
上限:先用.+[-~]截出所有-和~符号以及前面的字符,然后替换为空值,再通过\\d+截取剩余的数字。
REGEXP_EXTRACT(REGEXP_REPLACE([规格],'.+[-~]',''),'\\d+',0)
最终效果: