用时序UDF制作历史拉链表
您还在为动辄十几亿、甚至几十亿行历史快照数据无处安放感到束手无策吗?您还在为历史快照数据慢如蜗牛的查询速度感到生无可恋吗?不用担心,观远数据为您奉上BI黑科技——历史拉链表解决方案,帮您彻底解决以上问题。
“历史拉链表”这个名称不是观远独创的,其实经过数仓建设者多年的实践与总结提炼,历史拉链表早就被用在海量历史数据压缩存储与查询的场景里。但是一般在关系型数据库上构建和维护拉链表,需要包含拉链初始化、开链、封链、增量更新等多个复杂的操作步骤,每个步骤都需要用户对拉链表的操作思路非常清楚,且对SQL使用非常熟悉。因此一般情况下如果不是经验丰富的数仓工程师是很难掌握这套方法的,更不用说在一个BI分析平台内就能来做拉链表的设计。
然而,观远数据分析平台依托于Spark计算引擎,彻底简化了历史拉链表的构建和维护的流程,总结和封装出一套用于构建与查询历史拉链表自定义函数(时序UDF),可以让用户通过简单几个函数便能构建起历史拉链表,并能支持高效查询。
历史拉链表简介
在数仓建设过程中,我们经常会遇到一类大数量问题,具有以下特点:
-
整体数据体量比较大,比如门店+SKU级别的库存信息。
-
表中的部分字段会随着时间的变化被不断更新,但是每一天被更新的数据仅仅是所有数据中的一小部分而已。就以上例子而言,有动销的门店+SKU组合可能只占所有组合的10%甚至更低。
-
用户需要查看任意时间点历史快照信息。
以上问题最直接的解决办法是把每一天的全量快照数据都存下来,提供日期主键,然后开放给用户去查询,但这样实际上会保存很多不变的信息,对存储是极大的浪费。再者,设计不当还非常影响查询效率,拖垮数据库。
我们举个例子,一家连锁药店企业,门店数3000,SKU数1000,如果存库存快照数据,每天就是300万,一年就是10个亿。如果要求能够查询5年的历史数据,那么就需要保存近50亿的历史快照数据。
为了解决这个问题,历史拉链表应运而生。历史拉链表是维护了历史状态,以及最新状态数据的一种表。拉链表存储的数据实际上相当于快照,只不过做了优化,去除了一部分不变的记录而已,通过拉链表可以很方便的还原出拉链时点的客户记录。拉链表既能满足反应数据的历史状态,又可以最大程度的节省存储,提高查询效率。接下来我们来看一下,观远数据分析平台是如何帮你快速构建历史拉链表,并提供快照查询的。
库存拉链表构建
前提
-
我们需要一份历史库存快照表,它一般会包含日期、商品基本信息、以及库存数据(例如库存金额)。如果需要在BI里创建快照表,请参考用ETL制作数据快照的方法。 如果我们拿到的是出入库明细(库存流水),也可以跳过数据快照步骤,从库存流水的日汇总表制作得到库存拉链表。
-
需要使用观远拉链表自定义函数,最新版时序UDF函数列表如下。
类型 | 函数 | 参数 | 输出数据类型 | 说明 |
构建查询表字段 (ETL用) | date_range_build_v2 | (struct_array) | dateRangStruct | 无压缩时间序列值。参数中 struct_array 数组,需要通过 collect_list(struct(date, value)) 等函数来聚合得到。 |
date_text_range_build_v2 | (struct_array) | dateTextRangStruct | ||
date_range_zipper | (dateRangStruct) | dateRangStruct | 相邻等值压缩的时间序列值。对缺省日期添加一条值为 null 的记录并压缩(若有缺省日期且前一个日期值不为 null,则添加与前一个日期相邻日期且值为 null 的记录,当前日期是否压缩与新添记录做比较;同时对相邻等值记录进行去重,仅保留第一条)。 | |
date_text_range_zipper | (dateTextRangStruct) | dateTextRangStruct | ||
date_range_merge | (dateRangStruct_1, dateRangStruct_2) | dateRangStruct | 合并时间序列,合并后不压缩相邻等值。 | |
date_text_range_merge | (dateTextRangStruct_1, dateTextRangStruct_2) | dateTextRangStruct | ||
date_range_period_to_date | (dateRangStruct, period:string) | dateRangStruct | period: 'week','month','year' 1. 原始日期保留,值按指定周期累加;2. 为缺省周期补齐期初日期,值补零;同时对补齐的相邻等值进行压缩,仅保留第一条。适用于周期内累计值的计算和查找,例如周/月/年累计销售额。 | |
查找数据 (卡片用) | date_range_lookup | (dateRangStruct, lookup_date) | Number value | 滚动向上查找,即无对应日期数据就向前查找最近日期的数据,适合库存类数据或者会员状态的查找。 |
date_text_range_lookup | (dateTextRangStruct, lookup_date) | String value | ||
date_range_get | (dateRangStruct, lookup_date) | Number value | 精确查找,适合销售类数据查找;找不到则返回null。 | |
date_text_range_get | (dateTextRangStruct, lookup_date) | String value |
- 函数使用说明
-
-
数据集里需要有日期格式字段来作为主键,用日期时间(timestamp)的话时分秒信息不会被保留。
-
名称中带有text的函数用来处理日期主键和文本字段,其他函数用来处理日期主键和数值字段。
-
以上函数中 date_range_build_v2 和 date_text_range_build_v2 先把原始日期主键date和要查询的结果字段value(数值字段或文本字段)先处理成 struct_array 数组,需要通过 collect_list(struct(date, value)) 等函数来聚合得到。
-
struct 函数用来把两列数据合并为字段名和字段值一一对应的一列数据(key-value键值对),同时会把日期转换成计算机默认计时Unix date, 即起始时间1970-01-01会被转换为数值0, 之后按天累加;
-
collect_list 函数用来按照分组把多行数据合并成一行,转换后为数组array格式,使用时需要结合group by (或者窗口函数over(partition by ))来使用;
-
date_range_build_v2 和 date_text_range_build_v2 函数把得到的struct_array重新组合,得到一个k-v键值对,其中k是一个升序排列的日期数组,v是相应的库存数数组。
-
- 分步骤处理结果和格式可参考如下:
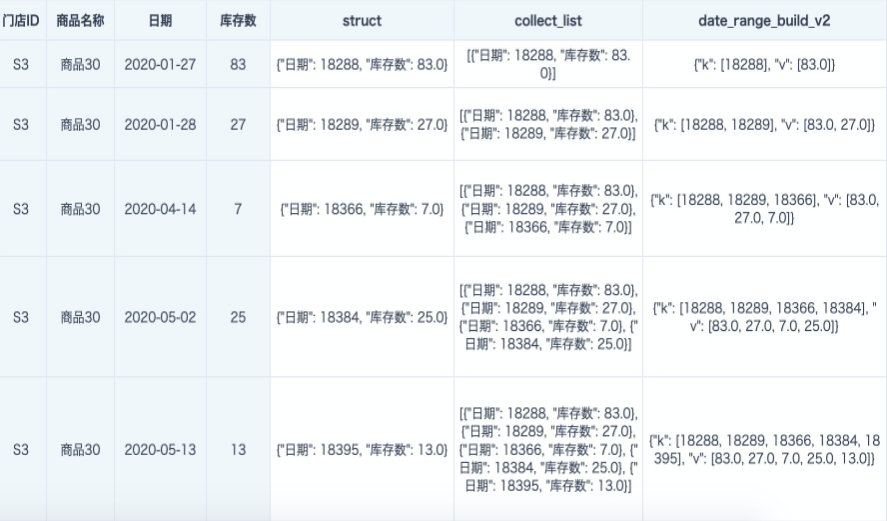
-
经 date_range_build_v2 和 date_text_range_build_v2 处理得到的 dateRangStruct/ dateTextRangStruct,可以继续使用其他时序UDF函数进行压缩、合并、按周期累计或者查询。
-
旧版函数 date_range_build(date_array, value_array),date_text_range_build(date_array, text_array) 依然可以使用,但是只适用于date和value字段里没有null值(如有null需要提前替换null值)的场景。因为 collect_list 会将 null 值丢弃,若日期或数值中含有 null,会造成对应关系错位和部分数据丢失(如数值中有个 null,其对应的日期会对应到下一个日期的值,且最后一个日期被丢弃),所以现在使用 date_range_build_v2(dateRangStruct) 和date_text_range_build_v2替代旧版函数。同理,原来的 date_range_remove_adjacent_same_values(dateRangStruct) 与 date_text_range_remove_adjacent_same_values(dateTextRangeStruct) ,现在被 date_range_zipper(dateRangStruct) 和 date_text_range_zipper(dateTextRangStruct) 所代替。一般我们都建议使用新版函数。
实现步骤:以库存快照表为例
- 把已经准备好的快照表导入到观远数据平台中,创建一个Smart ETL,先把数据聚合到需要的颗粒度。
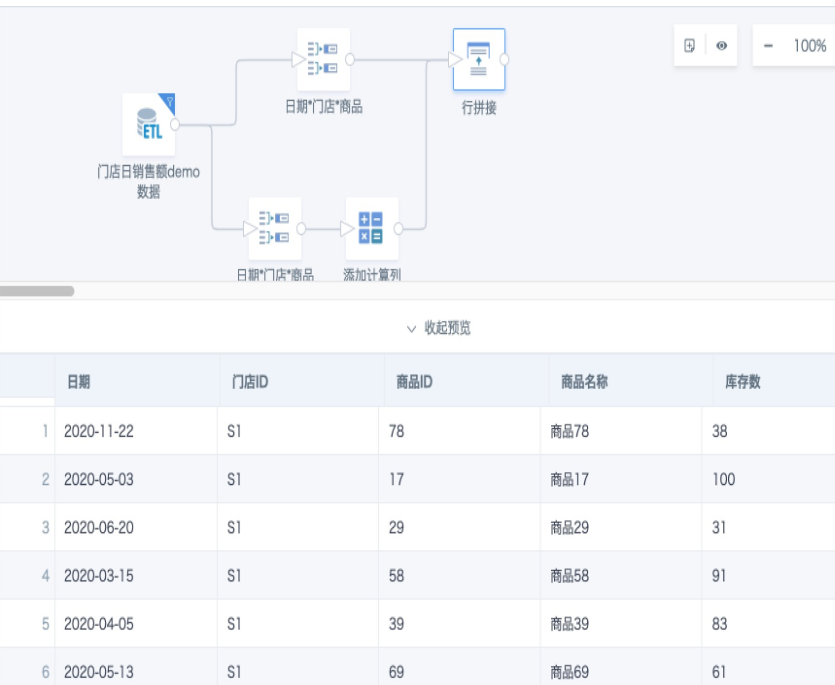
- 新加一个分组聚合节点,并添加一个聚合字段“库存查询”,字段类型为“文本”,然后把需要的维度字段拖入维度区域,聚合字段“库存查询”拖入数值区域,进行分组聚合计算。该字段的表达式为:
--方法1:(推荐方法)
date_range_build_v2(collect_list(struct([日期],[库存数])))
--方法2:如果您更习惯用SQL来处理数据,您也可以使用“SQL输入”节点来处理该过程。SQL表达式为:
select `门店ID`,`商品ID`,`商品名称`,
date_range_build_v2(collect_list(struct(`日期`,`库存数`))) as `库存查询`
from __THIS__
group by 1,2,3
--方法3:也可以尝试新建多个新建字段(字段类型都选“文本”)
分步骤使用函数 struct(), collect_list()over(partition by ), date_range_build_v2()逐步得到计算结果,然后用一个分组聚合节点对数据进行聚合
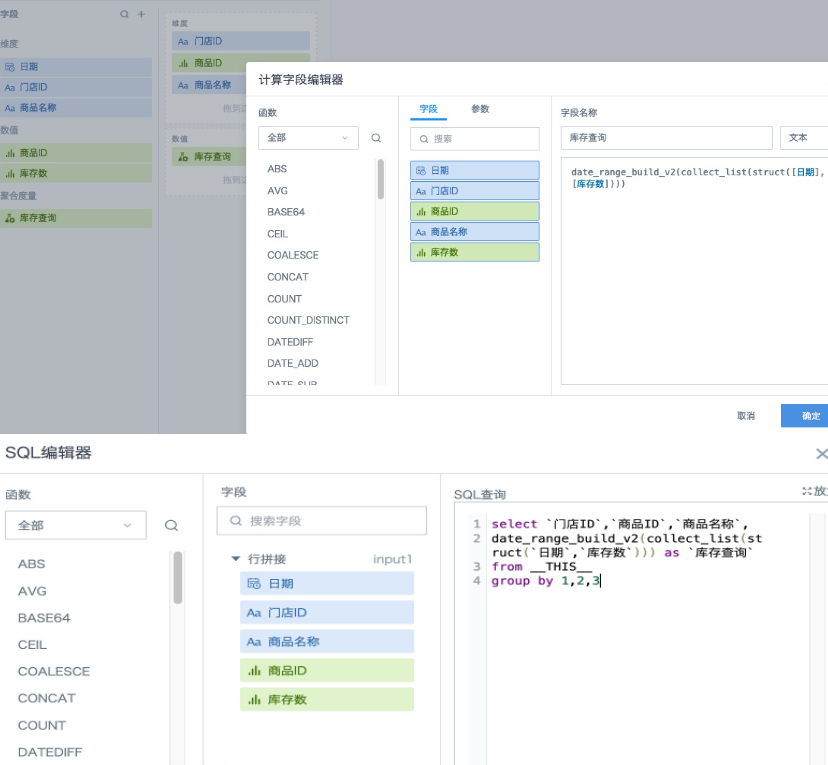
到这一步,我们就可以得到一个库存拉链字段,其实已经对快照数据进行了大幅的压缩。
- 进一步我们知道,对于库存数据来说,有些商品可能很长时间内库存都不会发生变化,也就是说上面的库存数数组里可能会存在大量连续重复的数据。于是我们添加计算列使用date_range_zipper函数对库存快照键值对再度进行压缩,构建库存拉链字段。压缩方式为:对缺省日期添加一条值为 null 的记录并压缩。若有缺省日期且前一个日期值不为 null,则添加与前一条记录相邻的日期且值为 null 的记录,当前日期是否压缩与新添记录做比较;同时对相邻等值记录进行去重,仅保留第一条。简单来说,它有两个效果:去除重复的数据,把空缺的时间段填充为null。
基于这两个效果,使用快照表制作拉链表时,建议使用date_range_zipper函数去重;使用流水表制作拉链表时,不需要也不应该使用date_range_zipper函数去重。
使用date_range_zipper([库存查询]) 数据压缩后效果如下:

图例解释:
2021-01-01至2021-01-05期间,库存数都是100。5条数据被压缩后仅剩2021-01-01(18628,100)一条数据,2021-01-06至2021-01-16期间数据缺失,自动补齐日期,库存数填充为null,然后被压缩为 2021-01-06(18633,null)一条数据,以此类推直到完成。
- 如果需要对库存数做月累计(MTD)统计,可以添加计算列“MTD库存查询”。
--除了月累计,还支持年累计('year') 和周累计('week')
[MTD库存查询]:date_range_period_to_date([库存查询],'month')

图例解释:
2021年1月、2月、4月都有数据,库存数按月累计,如1月最终累计值为1488。从2月开始自动补齐每个月的1日作为期初日期,2021-02-01对应18659,库存数补0, 2021-03-01对应18687,库存数为0;4月也自动补齐期初日期和库存数,但是因为3月无其他有效数据,和 2021-03-01数据(18687,0)为相邻等值数据,所以2021-04-01的数据被压缩去重了。
【注意】:
date_range_period_to_date 函数只能对 date_range_build_v2 后的库存数值进行累加计算,不能处理date_text_range_build_v2 里的文本数据,也不能对 date_range_zipper 压缩后的数据进行计算(存在补数的null值,null值不能参与计算;且数据被去重不适合累计)。
- 如果有两个不同年份的库存拉链表,希望合并到一起支持跨年查询,那需要先把两张库存拉链表先按照主键关联起来,然后用 date_range_merge() 函数来对两个库存拉链字段进行无压缩合并。
date_range_ merge ([zipper2020], [zipper2021])

- 给ETL添加输出数据集,保存并运行,得到数据量急剧缩减的历史库存拉链表。
库存拉链表查询
历史库存拉链表构建完成后,如何在仪表板查询任意日期的库存数呢?因为表里已经没有独立的日期字段,所以需要用函数date_range_lookup 或者date_range_get 并配合全局参数一起使用来进行数据查询。
实现步骤
- 新建或者直接使用系统里已经存在的日期类型全局参数。
- 创建卡片,新建计算字段,从左侧参数列表里直接点击引用日期参数“查询日期”,字段类型为“日期”,然后拖入维度栏。
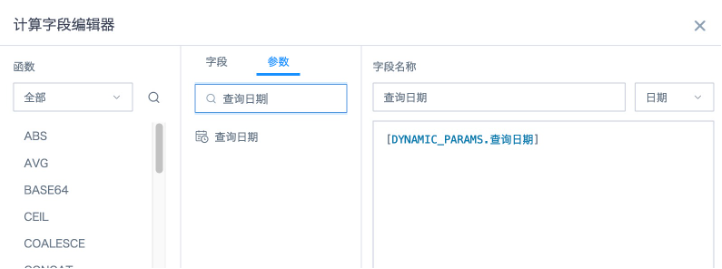
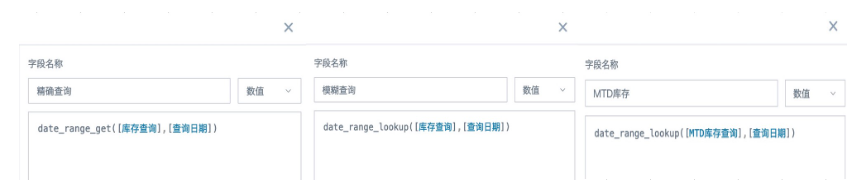
- 根据需求新建计算字段“精确查询”“模糊查询”和“MTD查询”,字段类型为“数值”,然后拖入数值栏,聚合方式选“无处理”。
- 保存卡片回到页面上。新建日期类型筛选器,联动卡片时勾选卡片使用的全局参数“查询日期”保存即可。或者也可以新建参数筛选器,引用全局参数“查询日期”保存即可,参数筛选器会自动联动当前页面使用同一全局参数的卡片。其他维度字段筛选使用普通选择筛选器联动即可。查询效果如下图。
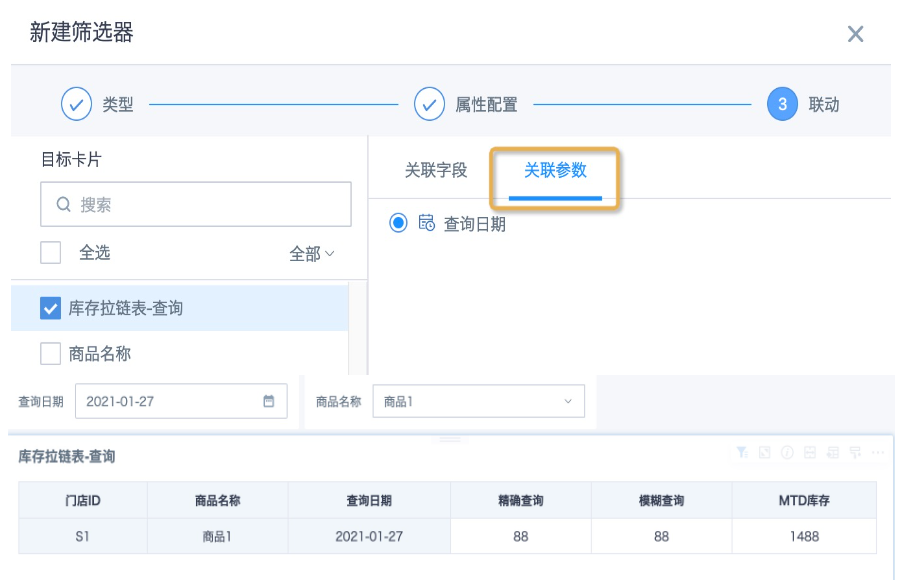
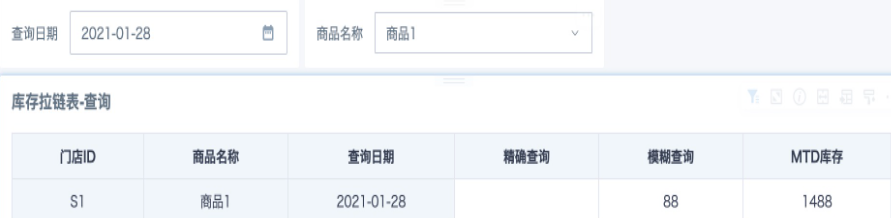
图例解释:
2021-01-27有数据,精确查询和模糊查询都可以查到对应库存数88,MTD库存1488;2021-01-28无数据,精确查询无结果,向上滚动查询得到2021-01-27的库存数88和MTD库存1488。