ETL高级设置
概述
本文将为您介绍 Smart ETL 的高级设置的功能说明与具体操作。ETL 高级设置功能支持修改「ETL 中间结果缓存」、「BroadcastJoin」、「Spark 单 job 超时时间(分)」、「自定义 Spark 参数」四个参数。
功能入口: 「数据准备 > 智能 ETL > ETL 详情页 > 高级设置」
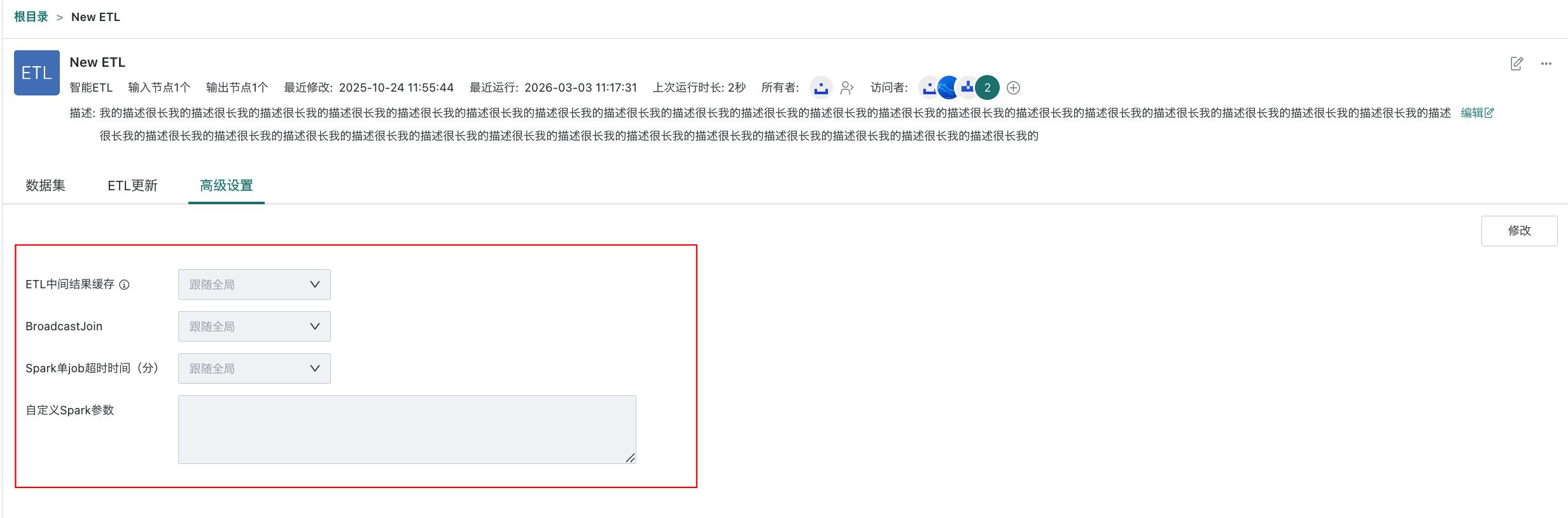
ETL 中间结果缓存
当 ETL 相对较复杂时(至少包含两个输出数据集且超过设置的复杂度阈值),通过启用该配置,系统会自动将中间运算结果进行缓存以加速整个 ETL 的运行效率。特殊情况下,可以在 ETL 粒度上停用该功能。

「跟随全局」设置路径:管理员可以在「管理中心 > 系统设置 > 通用设置 > 运行参数」界面配置「ETL中间结果缓存」参数,默认推荐的系统统一复杂度阈值为 100,可以修改复杂度阈值范围为50-999。设置过低,可能造成更多 ETL 运行过程中自动缓存中间结果。
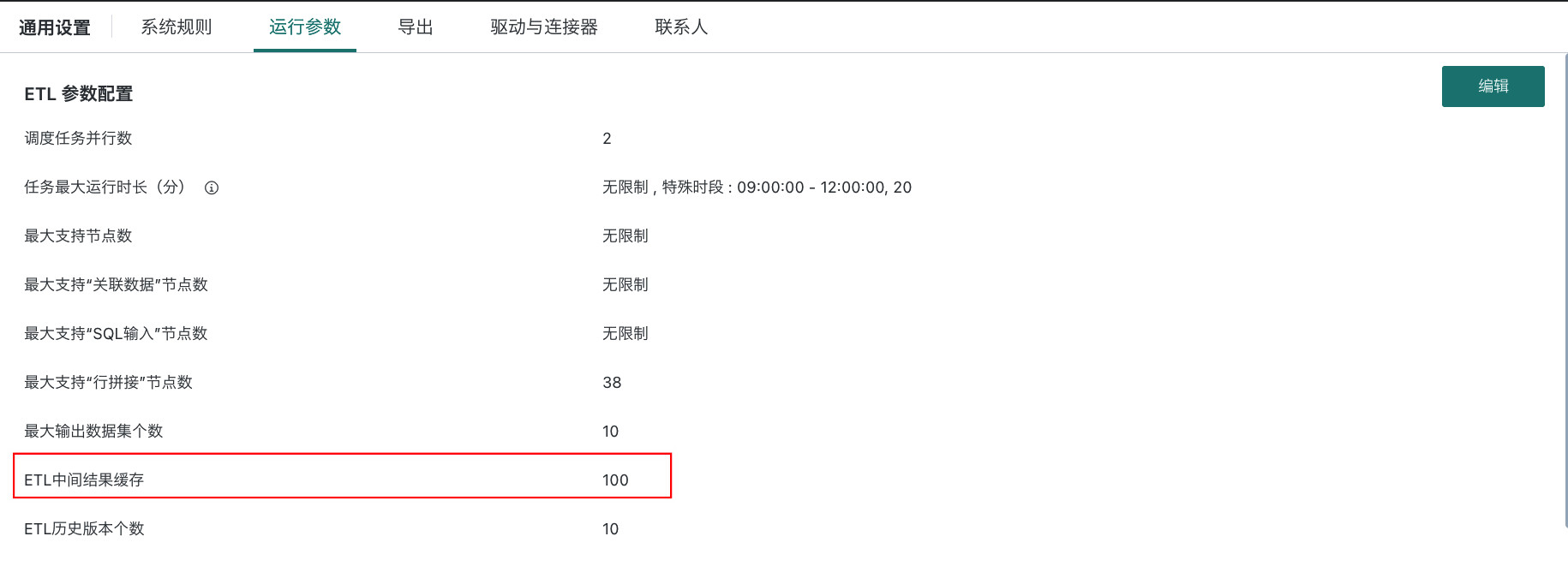
ETL复杂度计算详见ETL中间结果缓存
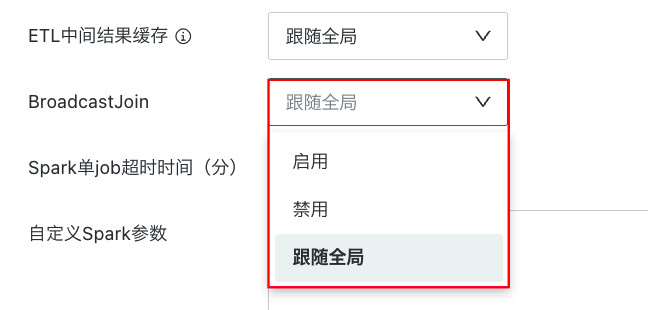
BroadcastJoin
Spark 是观远ETL默认语言,当两张关联表的数据量都较大时,并不适合启用 Spark 的 BroadcastJoin 功能,对此,您可以通过配置「BroadcastJoin」选项,将其禁用,从而降低风险。 针对特殊情况,是否启用,可以联系观远数据技术支持。
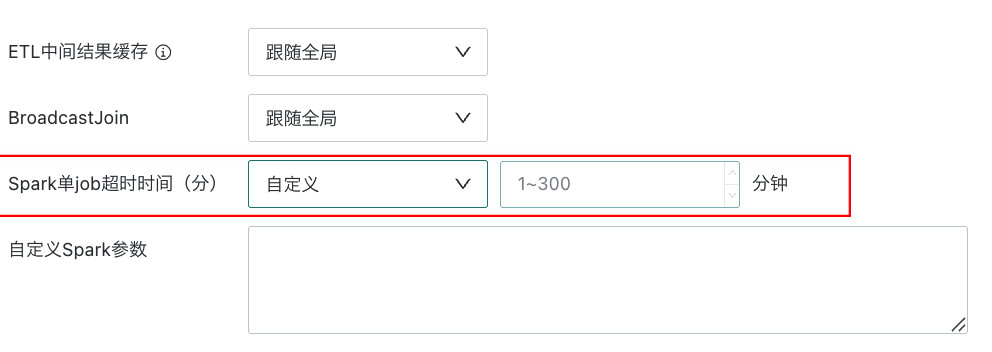
Spark 单 Job 超时时间(分)
通过设置 Spark 运行超时时长,可以限制任务的执行时间,确保任务在合理的时间范围内完成,避免因任务执行时间过长导致延迟和资源浪费,从而提升数据分析与处理的效率。用户可以选择「跟随全局」或者「自定义」,默认设置为「跟随全局」。

-
跟随全局 管理员可以在「管理中心 > 系统设置 > 通用设置 > 运行参数」界面,根据需要修改「Spark 单 job 超时时间(分)」

-
自定义 ETL 所有者可以修改时长范围为 1-300 分钟。
自定义 Spark 运行参数
:::note[说明]6.5 版本开始生效
:::
ETL 的计算引擎预置了部分 Spark 运行规则,极端情况下,一些规则会使部分 ETL 运行异常,此时可以针对这些 ETL 进行参数与规则的配置,使其在运行中使用特定的参数。支持配置多个规则,多个规则通过换行来区分。
目前支持的参数如下:
| 配置项 | 参数 | 单位 |
|---|---|---|
| shuffleBytes | guandata.jobLimit.shuffleBytes=200 | G |
| 输出数据集行数 | guandata.jobLimit.numOfOutputRows=1 | 亿 |
| shuffleDisk 阈值 | guandata.shuffleDisk.threshold=0.85 | |
| tableExpansionRate | guandata.jobLimit.tableExpansionRate=100 | |
| broadcast join 阈值 | spark.sql.autoBroadcastJoinThreshold=10Mb | Mb |
设置示例:

如果对具体的参数设置不熟悉,请勿自行配置。可以提前联系观远数据对接人员。
停用特定Spark优化规则
6.5版本之前生效,6.5版本后不生效。
ETL的计算引擎预置了部分Spark运行优化规则,如OptimizeRepartition、ColumnPruning等。非常特殊情况下,一些规则会使部分ETL运行异常,此时可以针对这些ETL进行配置,使其在运行中不采用预制的优化规则。
支持同时剔除、停用多个规则,不同规则之间采用英文逗号分割即可,如下所示。
CombineUnions,ConstantPropagation
若您在配置过程中遇到问题,可联系观远数据对接人员。