count_if函数用法说明
场景
在Excel里,COUNTIF 函数是比较常用的一个统计函数,用于统计满足某个条件的单元格的数量,函数语法为 =COUNTIF(查找区域,查找条件)。观远BI内使用的 Spark SQL里也有一个类似的 count_if 函数,返回满足某个条件的字段值个数,但是用户直接使用该函数系统会弹出如下报错。那是观远不支持该函数,还是用法错误呢?
It is not allowed to use an aggregate function in the argument of another aggregate function. Please use the inner aggregate function in a sub-query.
正确用法
观远非直连、非加速数据集概览页面、卡片和ETL(所有使用 Spark SQL 的场景)里均支持 count_if 函数,不过,需要配合窗口函数使用。窗口函数请参考窗口函数使用介绍。
官方用法说明: https://spark.apache.org/docs/latest/api/sql/#count_if

示例
按照商品分类,计算零售价超过100元的商品数。字段拖到数值栏,聚合方式选“最大值”,小计总计计算方式选择“以聚合数据计算—求和”。公式和计算效果如下图。
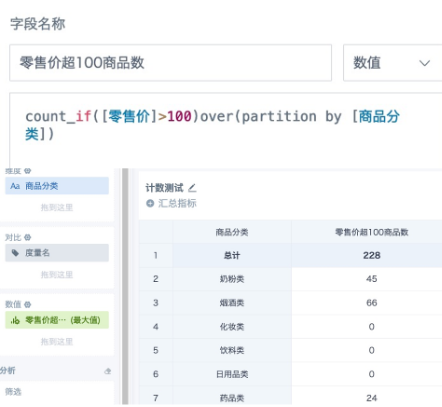
count_if 函数是对数据不去重计数,如果需要去重计数,建议使用以下替代方案。
替代方案
1. 新建计算字段,使用 case when/if 来筛选出符合条件的数据;把字段拖入数值栏,聚合方式选“计数”(需要去重计数的话选择“去重计数”),小计总计计算方式选择“以原始数据计算”或者“以聚合数据计算— 求和”都可以。
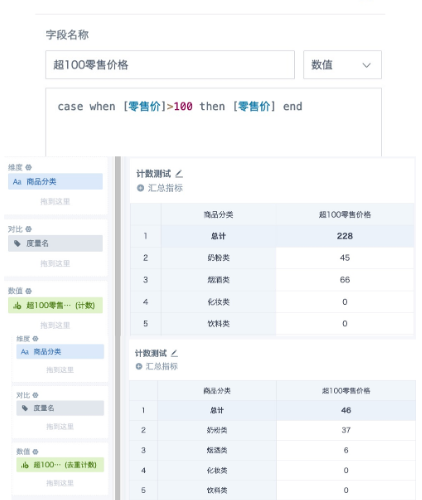
2. 如果需要用去重计数后的结果数据做二次计算或者筛选,需要新建计算字段使用窗口函数 size(collect_set()over(partition by )) 来计算。需要在报表里显示的话,拖入数值栏,计算方式选“最大值/无处理”,但是需要注意采用此种方式,小计总计无法正常计算;且数据量大的情况下窗口函数比较耗资源,加载较慢,须谨慎使用。
