前置清理规则使用说明
场景
考虑到企业的数仓中的事实表在抽取至BI平台后可能会发生变化,比如修正了数据或去除了脏数据等,因此往往需要将BI抽取的事实表先按照一定的规则做清理,比如删除最近7天的数据,再重新抽取最近7天的数据,以保证BI抽取的数据与企业内部的数仓数据保持一致性。而这类事实表通常数据量都大,在千万级别,如果是全量重新抽取耗时又耗资源。因此我们针对Guan-index类型数据集数据更新新增了前置清理规则编辑器,方便数据管理者们在抽取前按照指定的规则定时清理数据。
或者,抽取数据集长时间增量更新后数据量越来越大,导致后续ETL运行时间也越来越长,但是其实只需要固定时间范围内的历史数据。以前只能通过“数据清理”功能来手动清理历史数据,现在也可以通过设置前置清理规则,来实现数据集瘦身,例如自动清除1年前的历史数据,使当前数据集一直都只保存最近1年的数据。
路径
抽取数据集「数据更新」标签页,勾选「增量更新」后下面自动出现「前置清理规则」。
使用方法
- 先设置好去重主键,和增量更新的SQL语句并预览,确保数据正确无误。
例如,需要每天定时增量更新最近7天的数据。如果日期字段本身就是date/datetime格式,那可以在where条件里直接和时间宏作对比,参考下图:
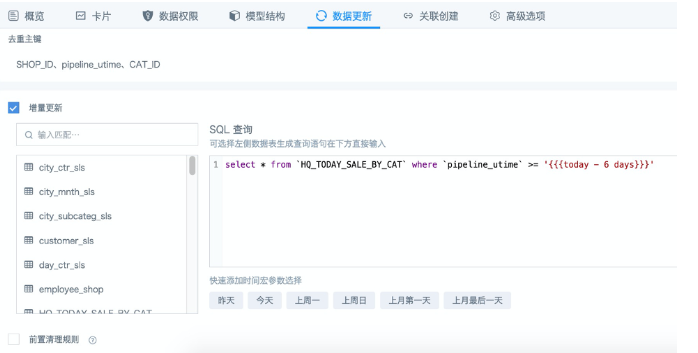
- 勾选「前置清理规则」,在弹出的设置框里写如和增量更新里相同的时间过滤条件,预览确保数据无误,点击「确定」,再点击页面右下角的「应用」保存设置。
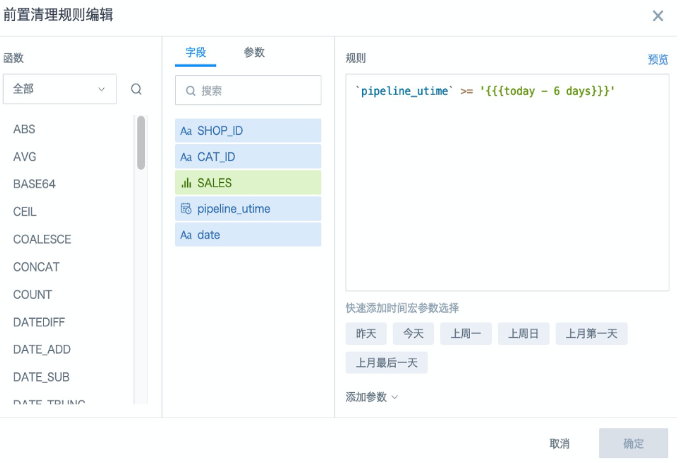
注意事项
上述场景里,日期字段是 date/datetime 格式,日期时间判断使用了时间宏,没有用到任何函数,所以前置清理规则可以直接复制粘贴where后的条件语句。
但是在需要用到函数公式的时候,不能原样粘贴条件语句。因为:「增量更新」是直接从用户数据库查询数据,必须使用对应数据库的SQL函数;「前置清理规则」是删除已经存储到BI服务器的数据,必须使用 Spark SQL 函数。「数据清理」、「行列权限」、「新建计算字段」等同理,都是处理已经存储到BI服务器的数据,需要使用 Spark SQL 函数。
例如,MySQL抽取数据集中的字段「date」是格式为20220228的文本类型字段(String)。增量更新里可以使用 DATE_FORMAT(`date`,'%Y-%m-%d') 或者STR_TO_DATE(`date`,'%Y%m%d')** 来转换日期格式和时间宏作比较。

但是在「前置清理规则」里,Spark SQL 写法是这样的:to_date(`date`,'yyyyMMdd') >= '{{{today - 6 days}}}' 。不同数据库函数不同,即使同一个函数多数据库通用,具体用法也会有差别,例如代表年月日的字母 y/m/d 在不同数据库中大小写代表的含义也有区别,不能随便混写。
