Database Output
Overview
Feature Description
Database Output writes processed data from a Dataflow Node directly into a database.
Multiple Database Output operators can be configured at any node in the ETL dataflow, each with its own target storage location.
Prerequisites
At least one Input Dataset or Database Input node is required in the Dataflow Node before you can configure a Database Output.
Procedure
-
Drag the
Database Outputoperator from the dataflow operator panel into the canvas on the right and connect it with links.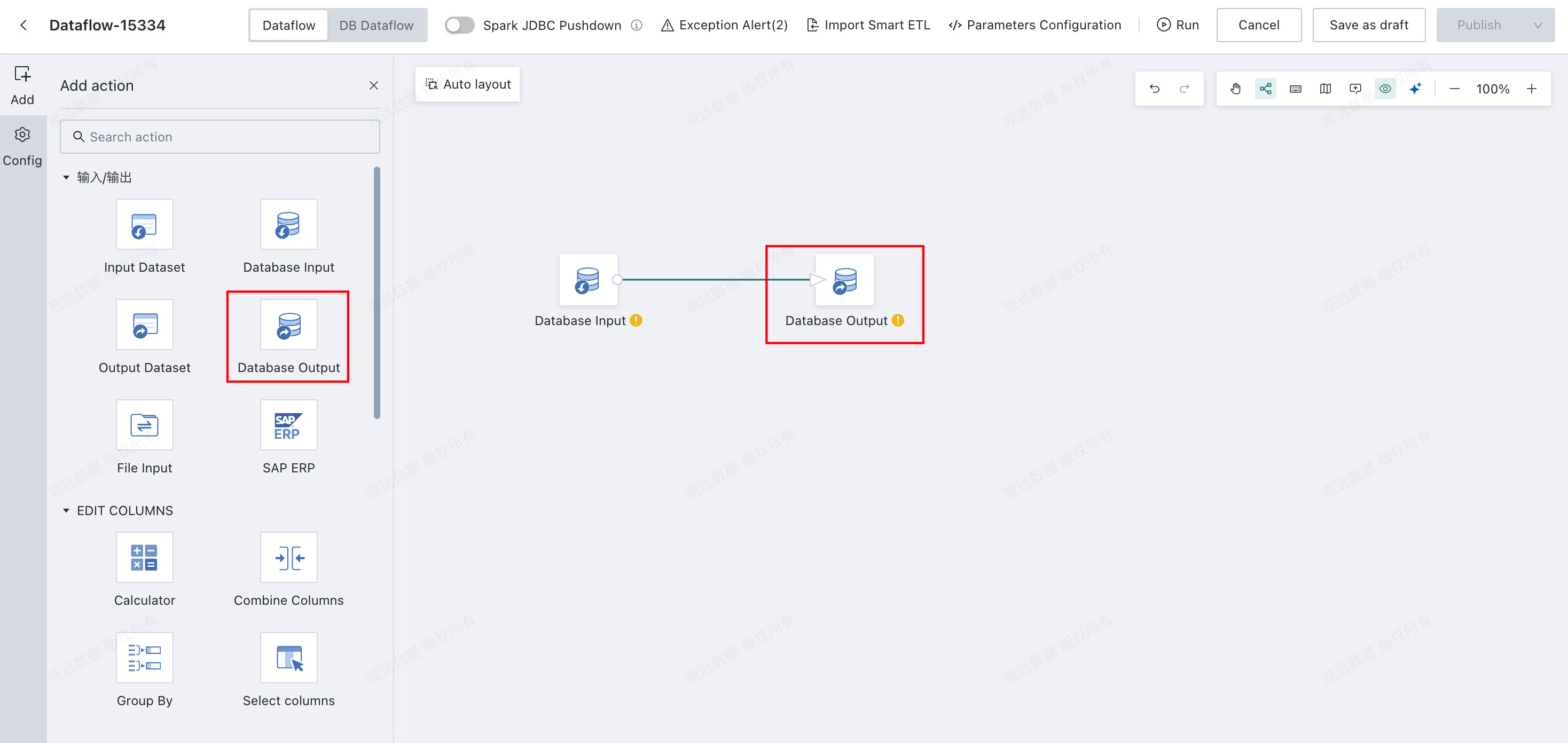
-
Click the
Database Outputoperator and choose the update mode.
| Update Mode | Description |
|---|---|
| Append | Keep existing data in the target table and append new data. |
| Overwrite | Clear historical data from the target table before writing. |
| Upsert | If the comparison fields match existing records in the target table, update the data; otherwise append the data directly. |
-
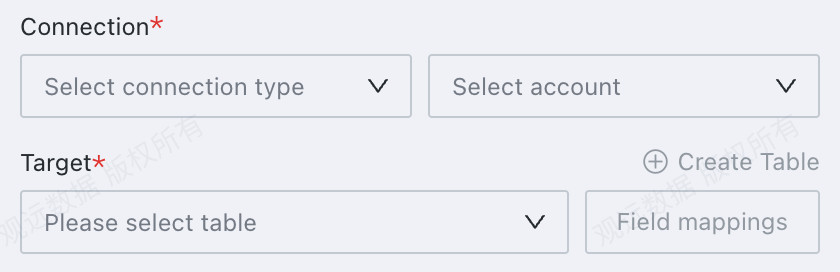
Select the database type, data account, and target table name. If the table does not exist, it is created automatically.
-
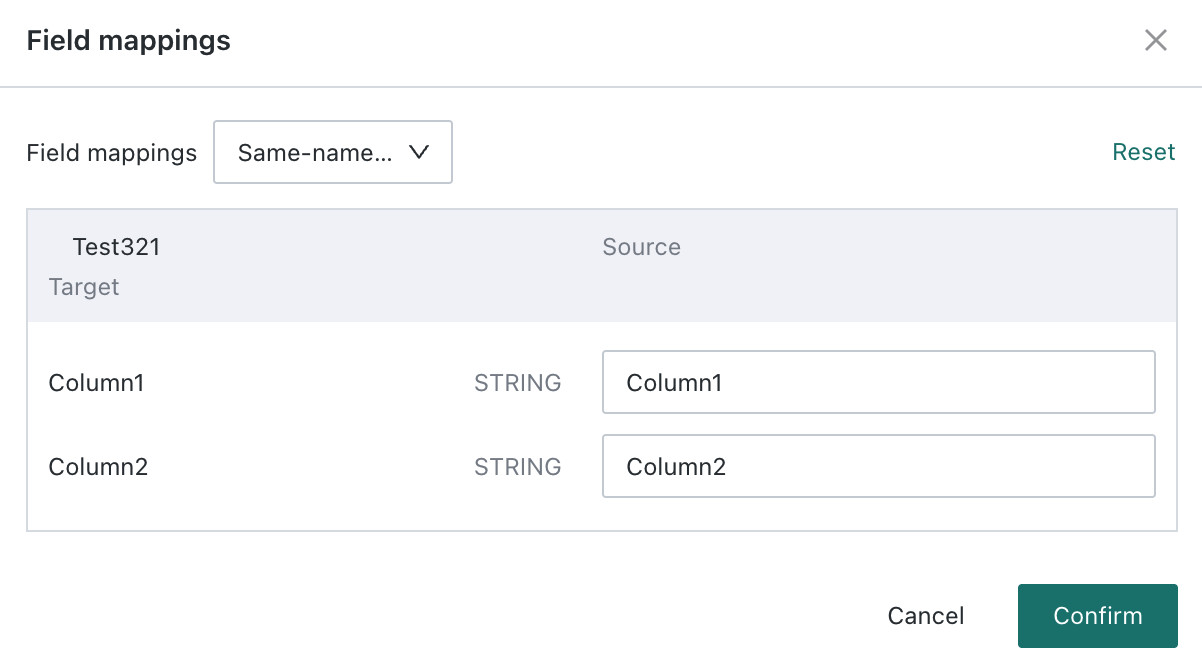
Configure field mapping for the target table.
-
If
Upsertis selected, confirm the comparison fields.
-
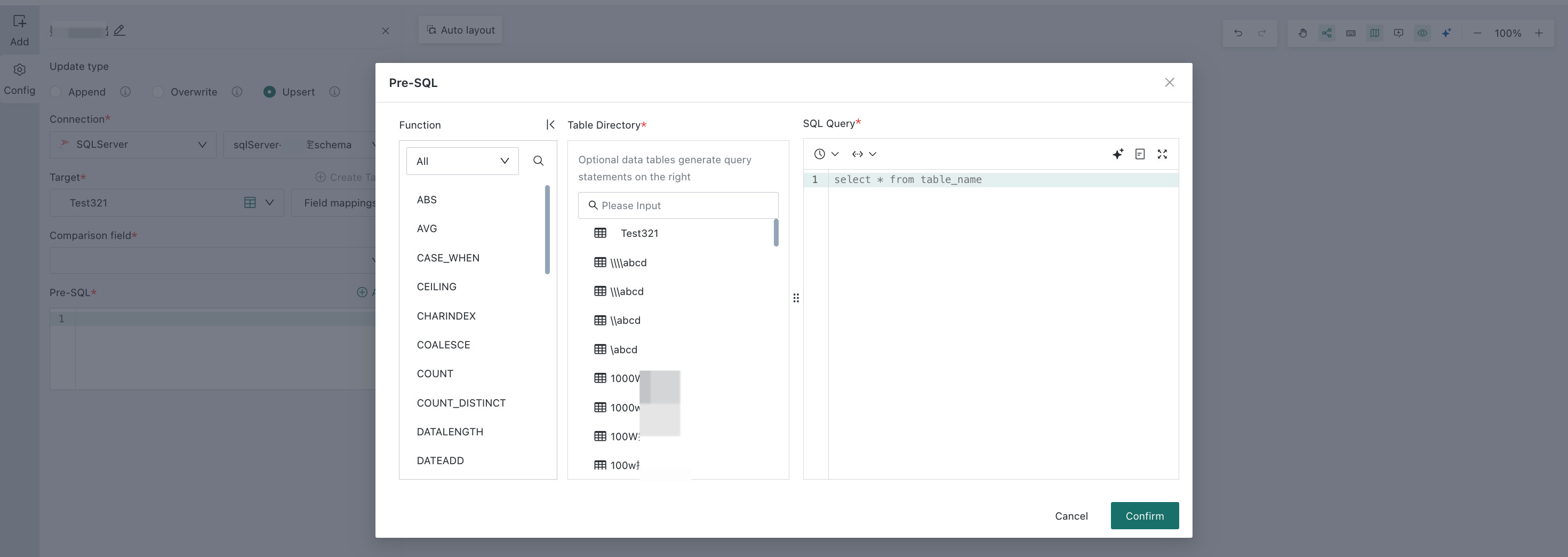
If you need to clean the target table before writing, enter a script in
Pre-SQL. It supports time macro parameters, global parameters, and workflow parameters. For workflow parameter creation, see Workflow Parameter.
High Performance Mode
The following databases support High Performance Mode to improve data synchronization performance:
| Database Type | Notes |
|---|---|
| StarRocks | Append Directly and Full Update support the high-performance model. When enabling it, note the following:1. Configure the HTTP port for the StarRocks data account, otherwise the task will fail.2. If incoming data length exceeds the target field length, the value is automatically set to null, so field length should be planned in advance.3. Tables created automatically by the platform are detail tables by default. Detail tables do not support Upsert, so if you need Upsert, create the table manually in the database first. |
| GaussDB | Simply enable the high-performance switch. |