Dataset Updates
Overview
To ensure data timeliness, datasets need to be updated regularly. Guandata BI supports scheduled updates, manual updates, URL-triggered updates, and additional control options depending on the dataset type and connection mode. For some datasets, such as Excel, CSV, and Account Datasets, the platform also supports cleaning up specified data to manage dataset size.
After updates are completed, users can use View Update History to inspect detailed execution stages, status, duration, and logs, which improves troubleshooting efficiency.
Automatic Update Configuration
The available update configuration options depend on the dataset connection mode, Direct Connection or Extract, and on the dataset type itself. Users can configure update methods both on the dataset creation page and on the dataset details page.
The following table summarizes the availability of each configuration item on the dataset creation page and the dataset details page.
For most configuration options, refer to Standard Database Connection Guide. The sections below cover only the parts not introduced in that guide.
| Configuration Item | Creation Page | Details Page | |
|---|---|---|---|
| General | Scheduling Status | ✅ | ✅ |
| 24h Scheduled Update Task Density Map | ✅ | ✅ | |
| Retry on Failure | ❌ | ✅ | |
| Direct Connection | Cache Validity Period | ✅ | ✅ |
| Real-time Card Data | ✅ | ✅ | |
| Automatically Update Data Structure | ❌ | ✅ | |
| Extract | Data Update Cycle | ✅ | ✅ |
| Deduplication Primary Key | ✅ | ✅ | |
| Incremental Update | ✅ | ✅ | |
| Automatically Update Data Structure (Incremental Update Mode) | ❌ | ✅ | |
| Pre-Cleanup Rules (Incremental Update Mode) | ❌ | ✅ | |
| Task Priority | ✅ | ✅ |
Retry on Failure
Dataset updates may fail because of task exceptions. Users can enable Retry on Failure to improve timeliness and accuracy by retrying failed tasks as soon as possible. The retry interval can either follow the global configuration or be customized at the dataset level, and can be set to 5, 10, or 15 minutes.
Retry on Failureapplies only to automatic updates, including scheduled updates and URL-triggered updates, and does not apply to manual updates.- Only one retry attempt is supported.
There are two modes:
-
Follow Global Settings: Configure
Retry on FailureinAdmin Center > System Settings > General Settings > Run-time Parameters. After configuration, all datasets follow the global setting by default.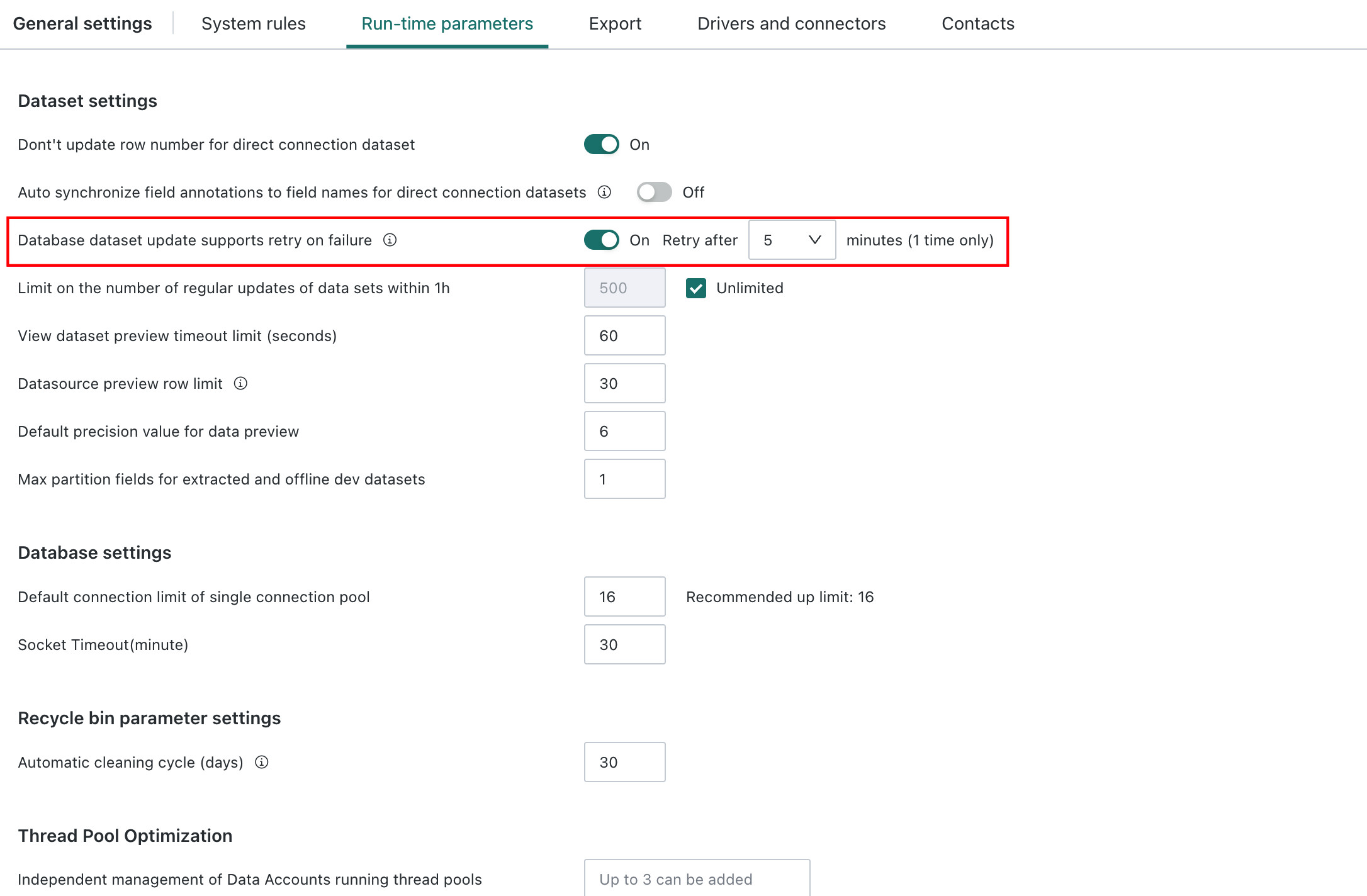
-
Custom: If retry behavior needs to be configured for only one dataset, users can enable
Retry on Failureon the dataset details page and define the retry interval there. Dataset-level configuration takes priority over the global setting.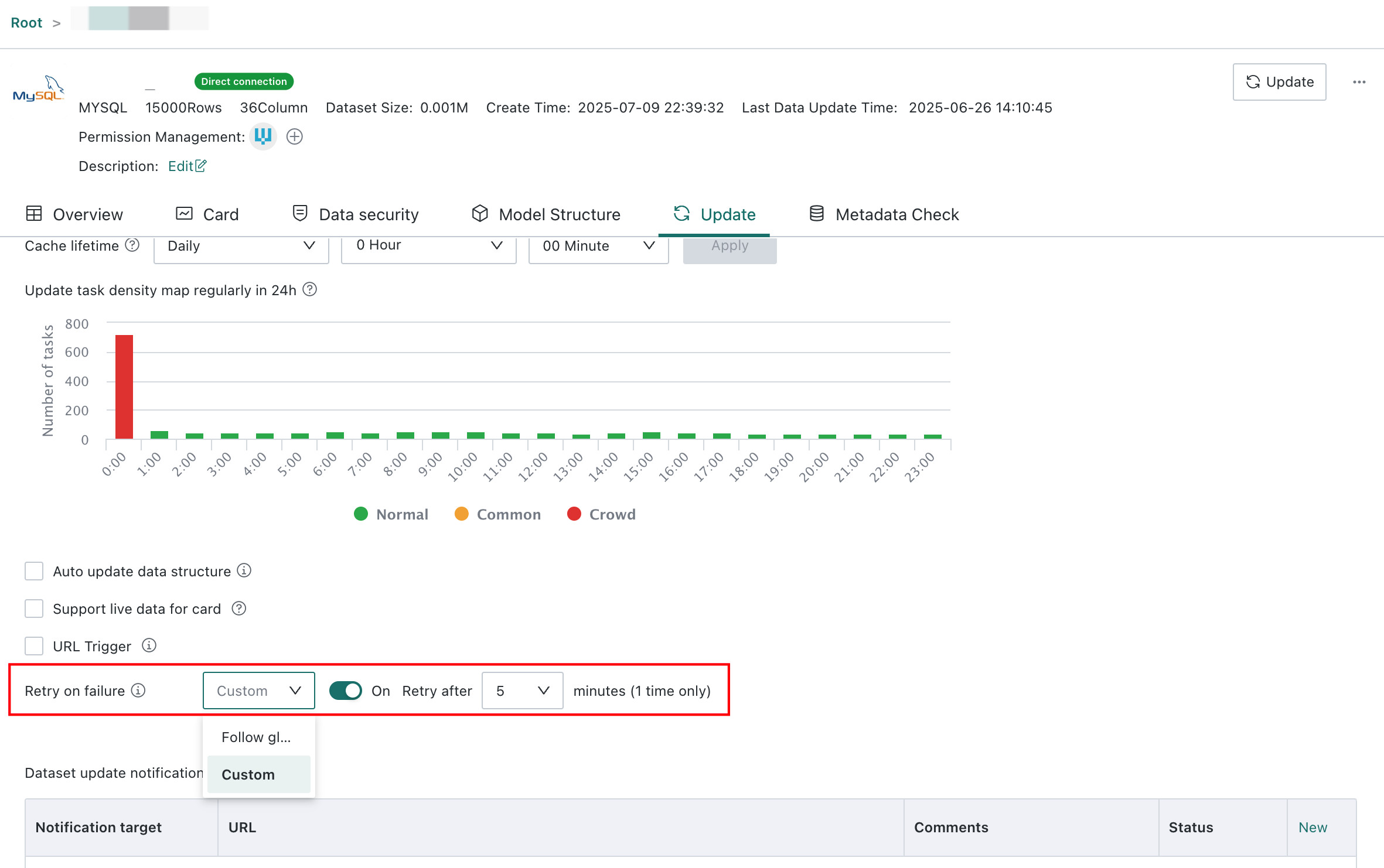
Automatically Update Data Structure
Direct Connection Datasets
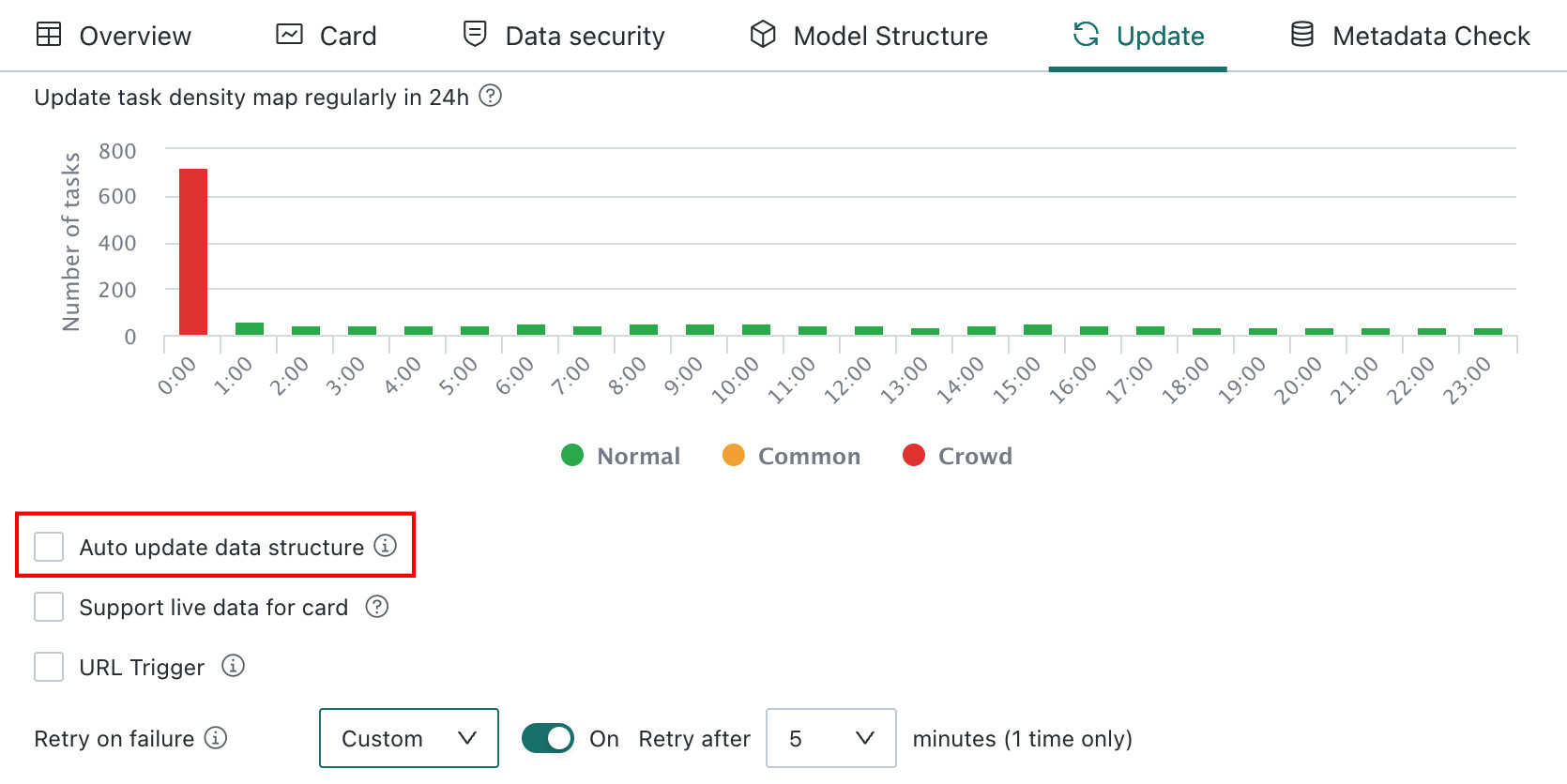
For Direct Connection datasets, users can choose whether to enable Automatically Update Data Structure. When enabled, the dataset structure is refreshed before each scheduled cache refresh.
If new columns are detected in the source database, the platform automatically adds them to the dataset structure. If some source columns are missing, the current structure remains unchanged.
Supported only for standard databases, not for MongoDB or SAP BW.
Extract Datasets
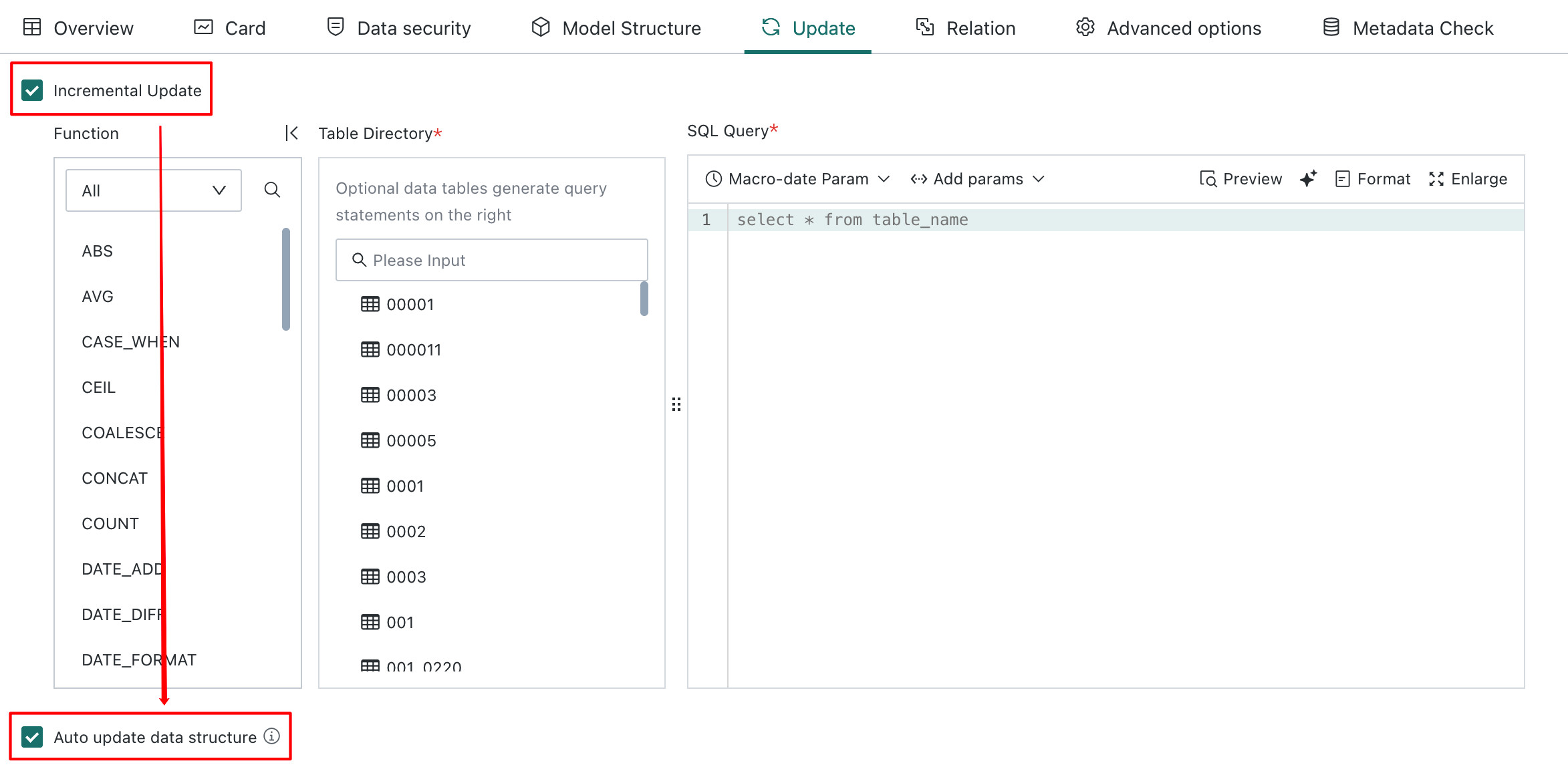
For Extract datasets, users can enable Incremental Update, and then optionally enable Automatically Update Data Structure. After it is enabled, the dataset structure can evolve together with changes in the source database structure.
- To support
Automatically Update Data Structure, three conditions must be met: the dataset must be sourced from a database, use Extract mode, and have Incremental Update enabled. - At present,
Automatically Update Data Structureonly supports adding new fields to the dataset when the source adds fields. It does not remove dataset fields when source fields are deleted.
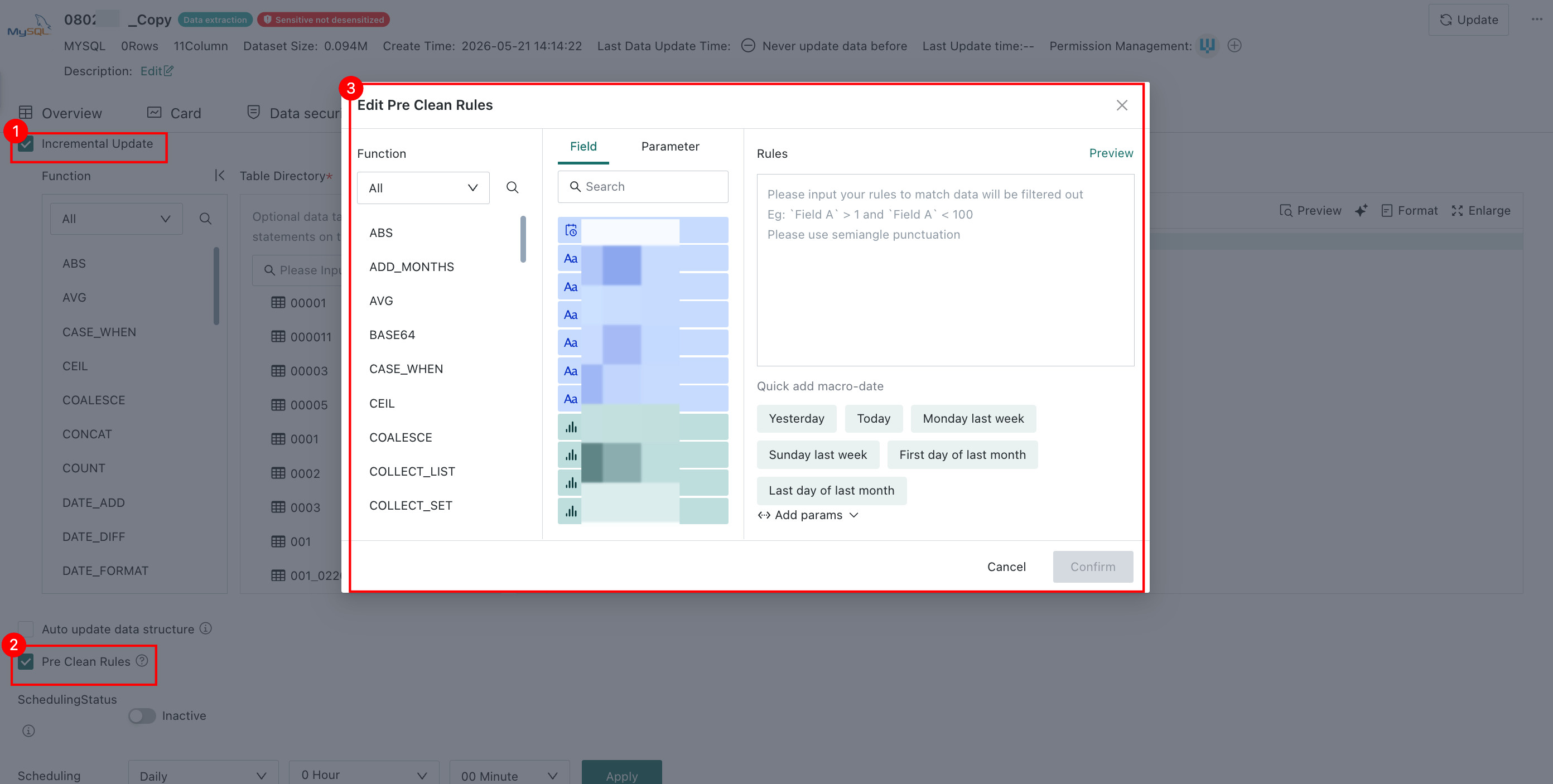
Pre-Cleanup Rules
For Extract datasets with Incremental Update enabled, users can optionally enable Pre-Cleanup Rules. When enabled, data that matches the rule is automatically deleted from the dataset before the update runs.
For built-in incremental-update datasets, except builtin_user, builtin_data_source, and builtin_data_flow, Pre-Cleanup Rules are also supported.
Manual Update Configuration
In addition to automatic updates, users can also update datasets manually.
For most datasets, clicking Update on the dataset details page triggers an immediate update. For Excel and CSV file datasets, manual updates are handled through Append Data or Replace Data.
Update Data, Non-Excel and Non-CSV
For most dataset types except Excel and CSV, users can click the Update button in the upper-right corner of the dataset details page to trigger an immediate update.
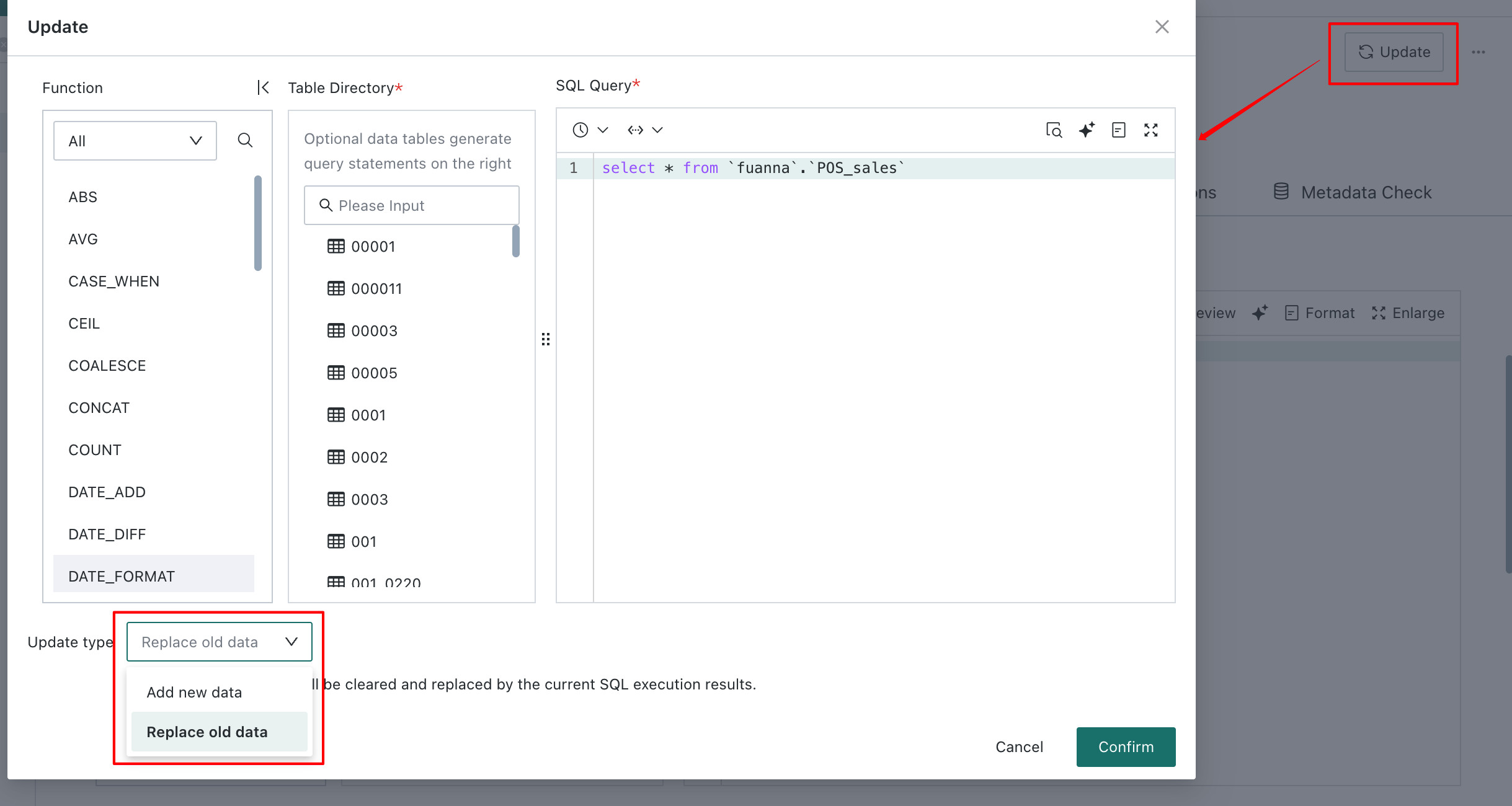
For Extract datasets, two update modes are supported:
- Append New Data: The result is appended to the existing dataset. If a primary key is configured, deduplication is performed based on that key.
- Replace Existing Data: The result replaces the existing dataset content, and all historical data is cleared.
For Card Datasets, if Dataset A is used to create Card B, and Card Dataset C is created based on Card B:
- Regarding structure: if Card B changes, Card Dataset C does not sync automatically. C must be updated manually to synchronize its structure.
- Regarding data content: if the original dataset A is updated, the data in Card Dataset C is updated accordingly.
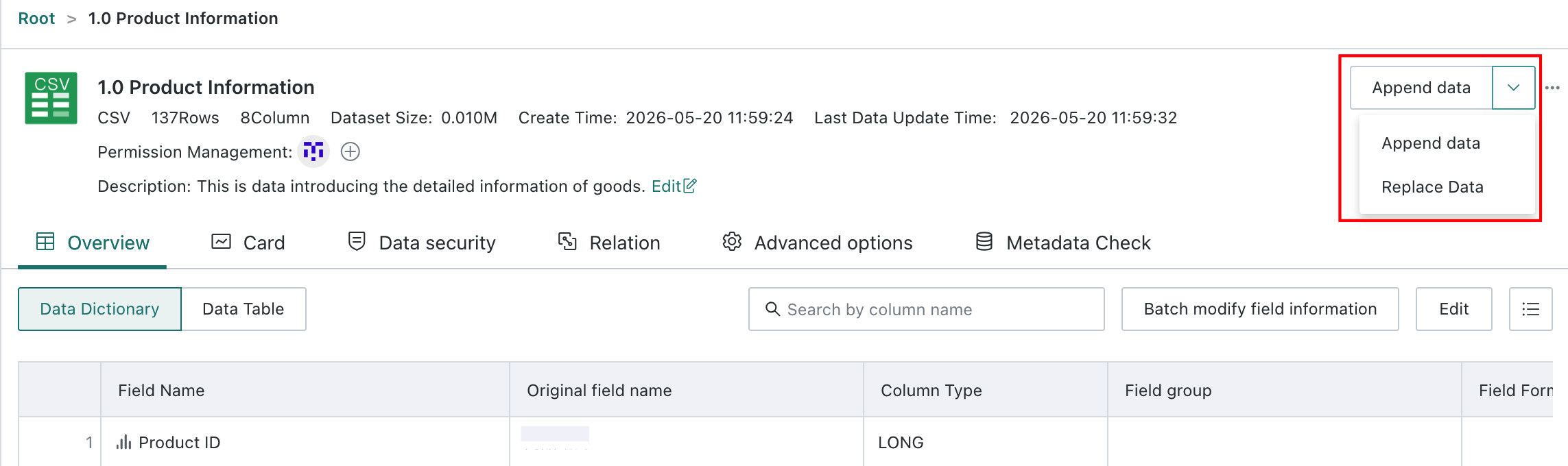
Append or Replace Data, Excel and CSV
For datasets imported from files, Excel, or CSV, users can choose Append Data or Replace Data in the upper-right corner of the dataset details page. For detailed steps, see Local Files.
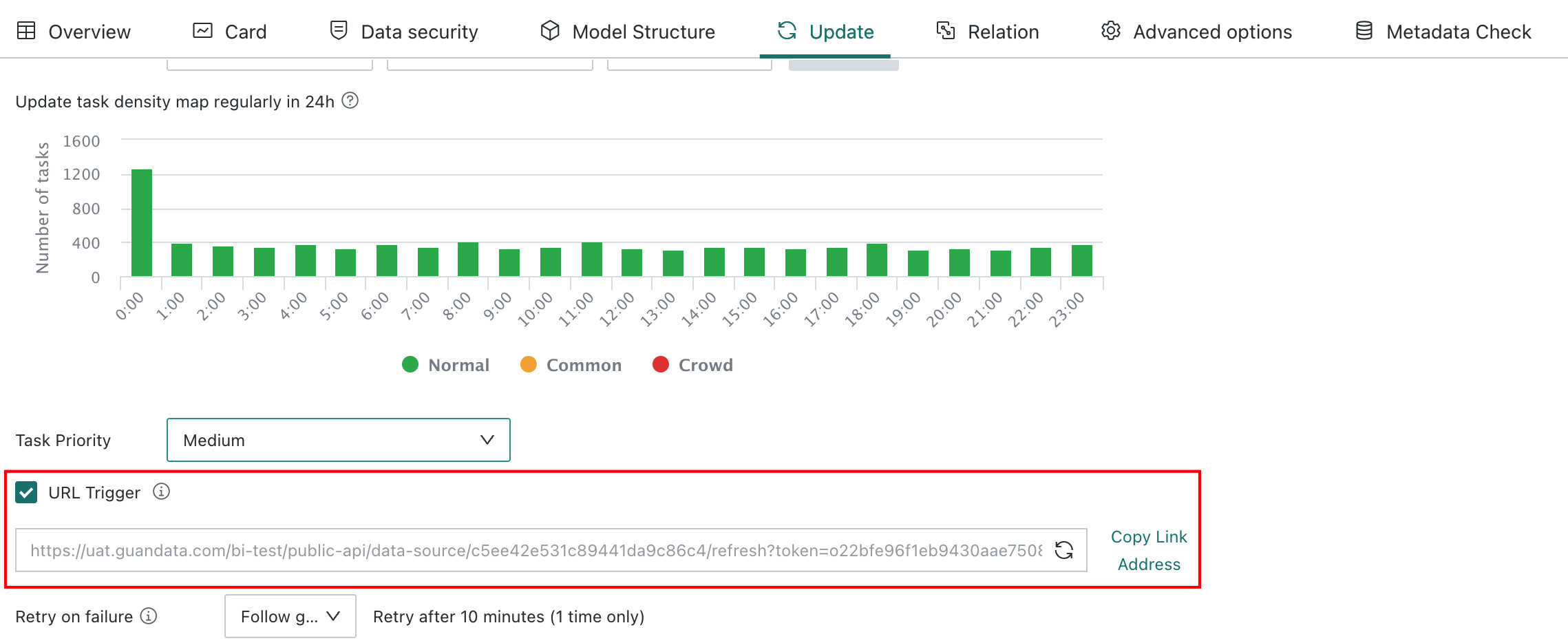
URL-Triggered Updates
The URL-triggered update mechanism allows external systems to notify Guandata BI and trigger dataset updates after source data has been refreshed. This is especially useful for datasets connected through databases, Direct Connection datasets, Extract datasets, or FTP datasets.
On the dataset details page, users can choose whether to enable URL Triggered Update. After it is enabled, the dataset can be updated directly from an external system through the generated URL, without requiring user authentication. See Dataset Update URL Trigger Mechanism.
- URL-triggered dataset updates are not affected by Scheduling Status, whether enabled or disabled.
- For example, a dataset can be updated manually through the BI UI, or by sending a URL request containing specific parameters to trigger the update process.
Data Cleanup
Users can use Data Cleanup to define cleanup rules that keep only the required data and remove data that does not meet business needs.
- View Datasets and Direct Connection datasets do not support Data Cleanup.
- Other datasets imported from files or databases do support Data Cleanup.
- Built-in datasets also support Data Cleanup.
-
Click the
...action area in the upper-right corner and chooseData Cleanup. In the dialog that appears, clickNewto enter theRule Editor.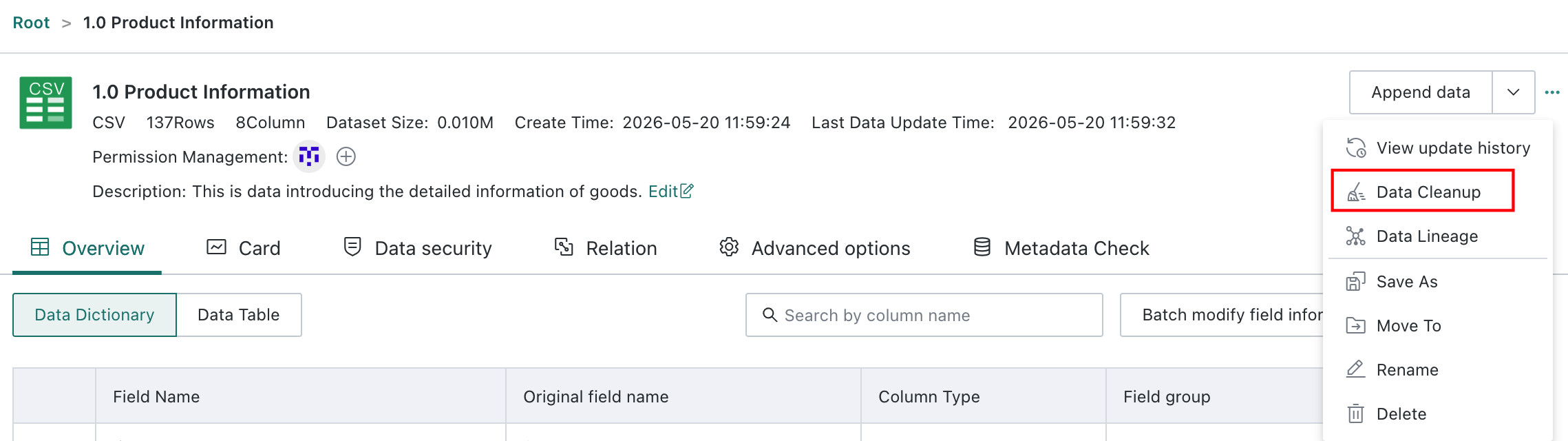
-
In the
Rule Editor, choose a field, then choose the rule type and define the cleanup rule. In the example below, data related toShanghai Wanda StoreandShanghai Guomao Storeis cleaned up.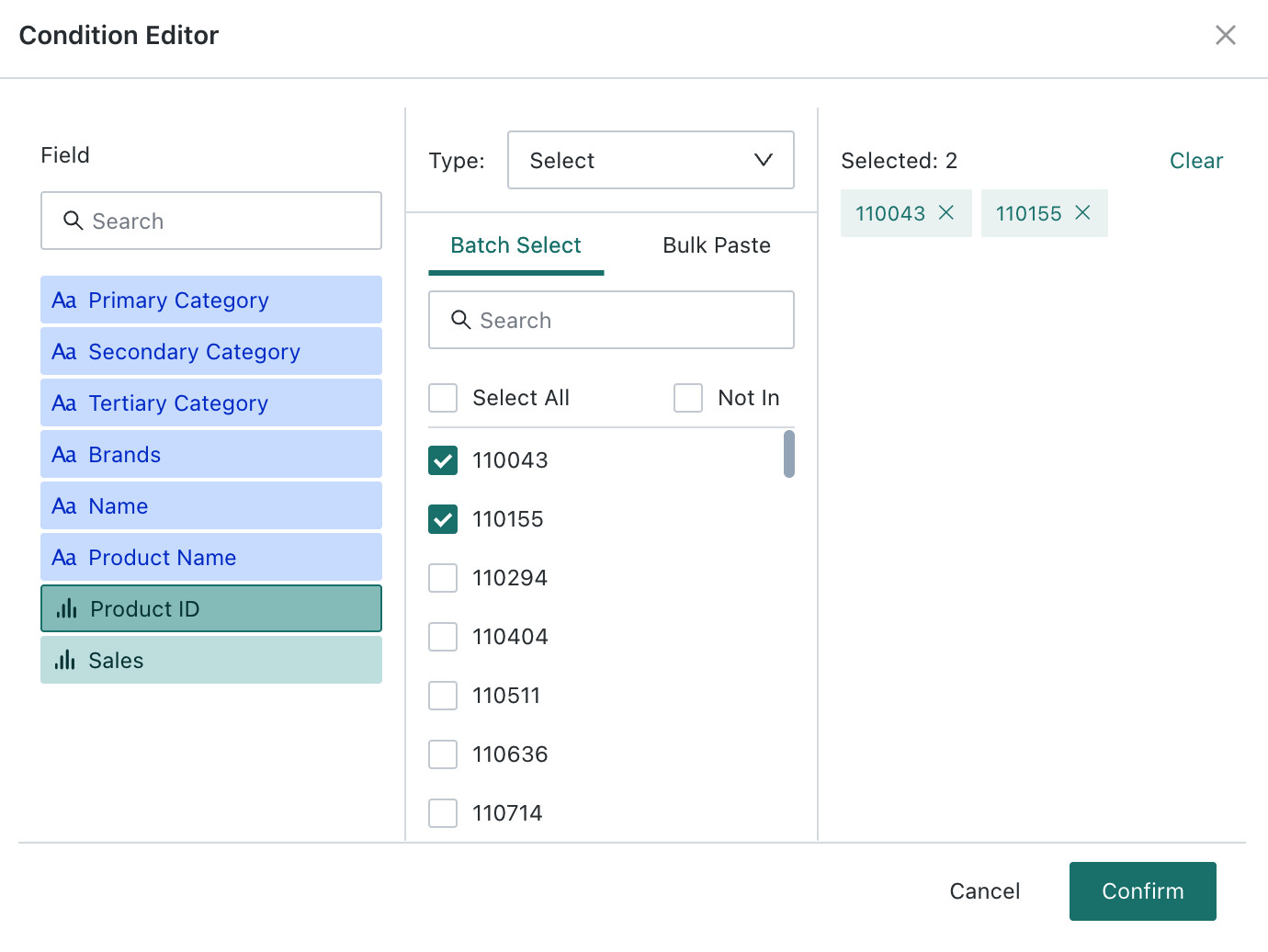
-
Click
Previewto viewData to Be Cleaned, and after confirmation click `Clean up.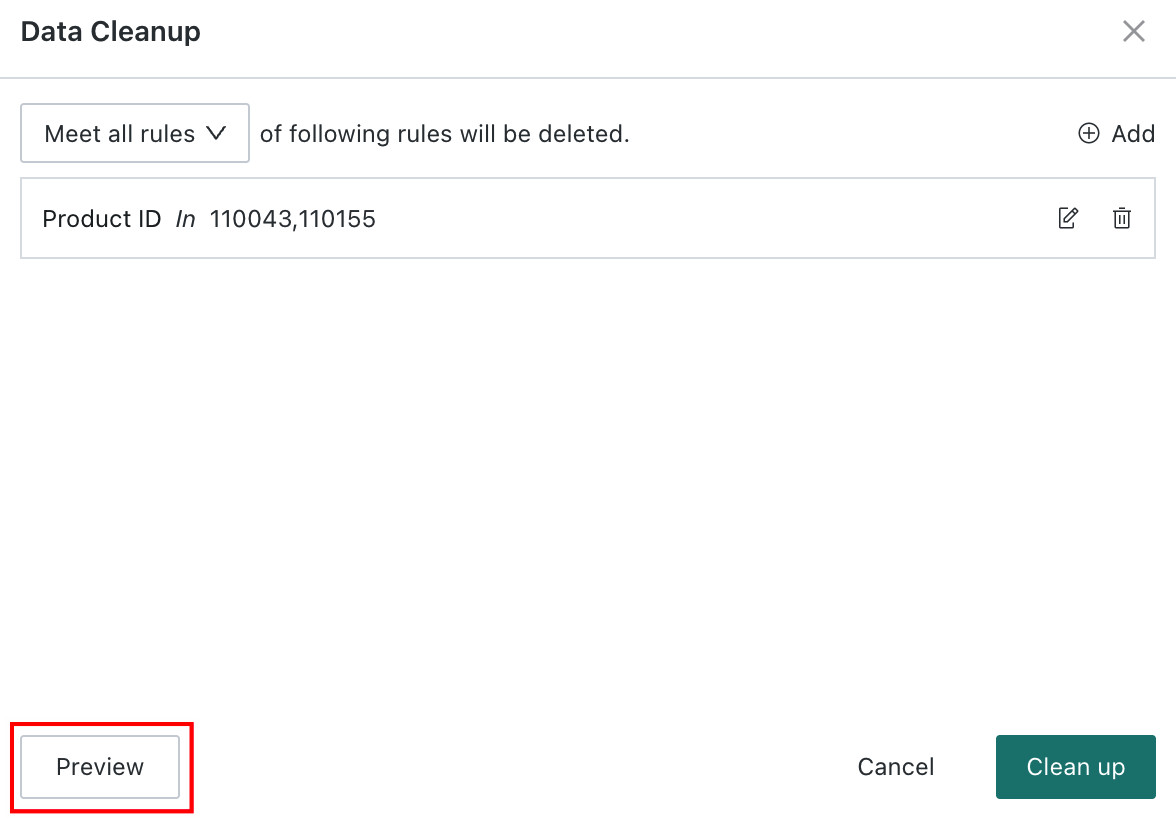
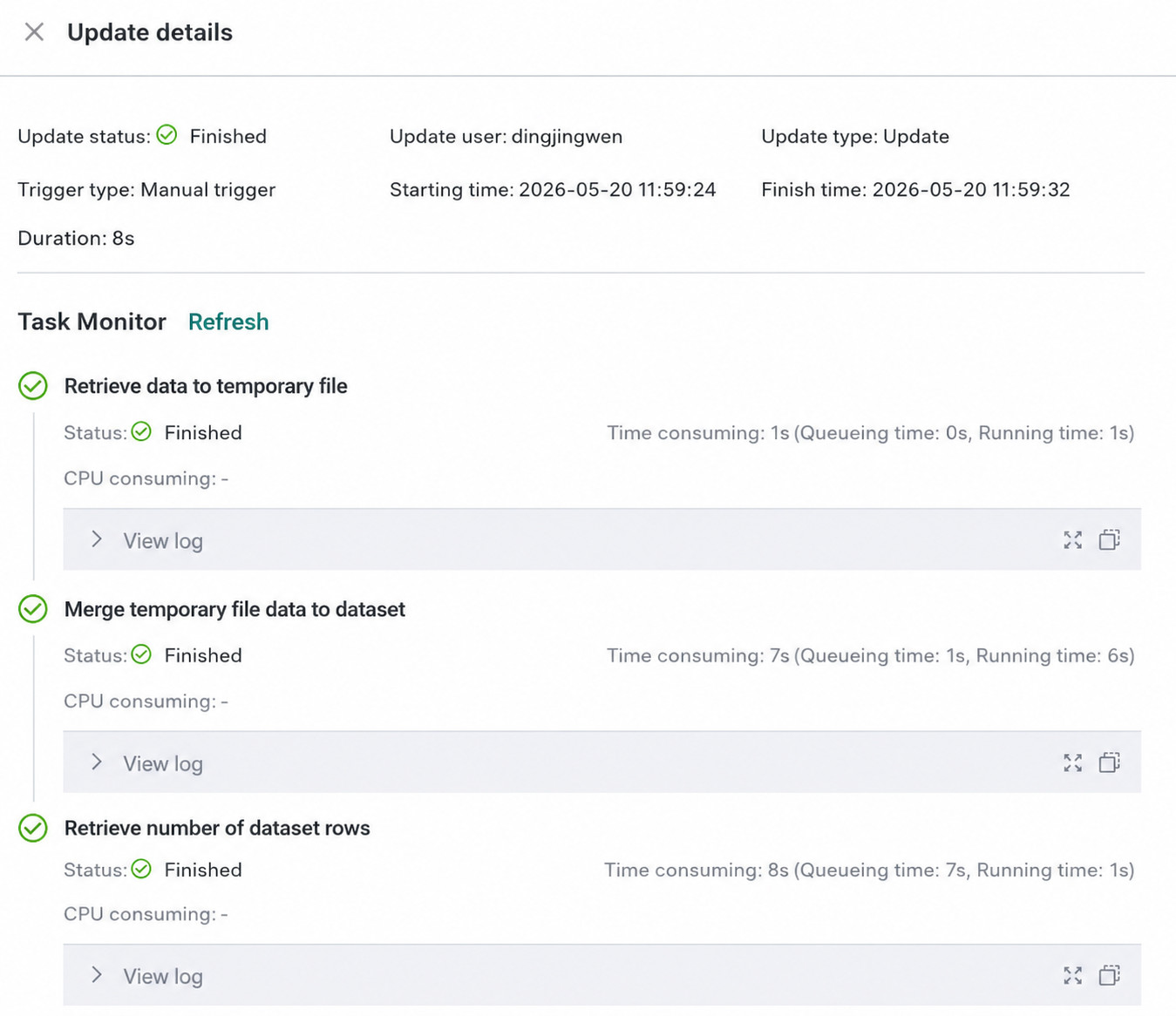
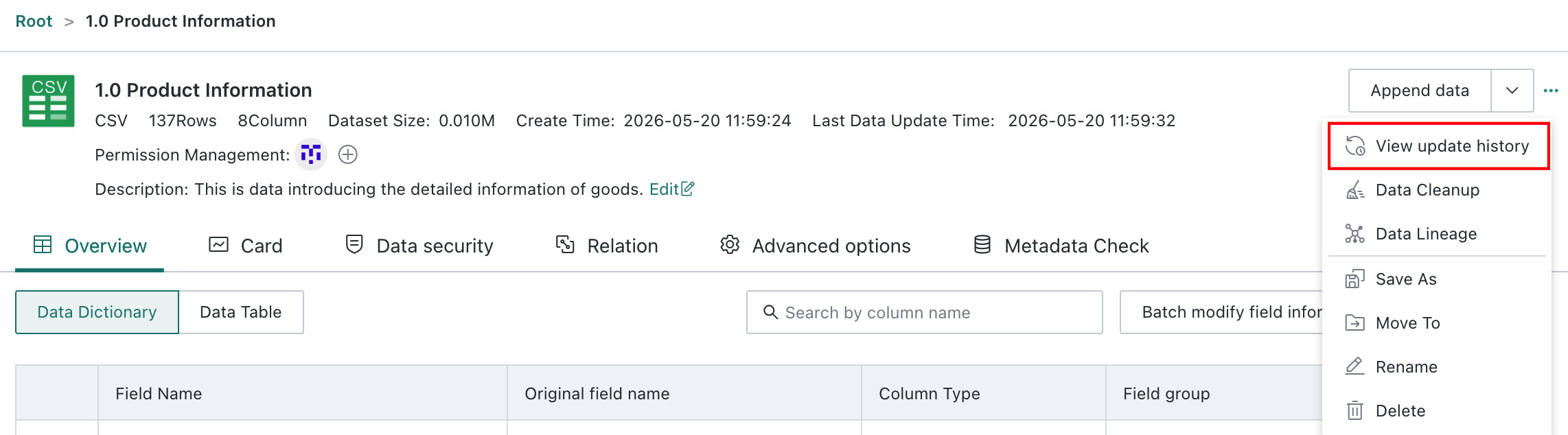
View Update History
Users can view dataset update history on the dataset details page, including execution stages, status, duration, and complete logs. By default, records are retained for 3 months. If longer retention is needed, contact Guandata staff.
The dataset update history log mechanism was restructured in version 6.3. Historical tasks that ran before the upgrade point do not support the new log view. For those, users can go to Admin Center > Task Operations.
The monitoring list supports fields such as Updated By, Update Method, and Actions.

-
Update user: Records the operator of the dataset update task. For manually triggered updates, this is the current user. For scheduled and advanced scheduling tasks, it is recorded as
-. For API-triggered updates, it is the user from the token. -
Trigger type: Includes API, manual, scheduled, and advanced scheduling.
-
Actions: Clicking
Detailshows the execution stages, status, duration, and complete logs. ClickingView Loginside each stage opens the log in full-screen mode and supports copying all log content to the clipboard.