Remove Deduplicates
Overview
Remove Deduplicates means detecting and removing duplicate records during data processing to ensure that each record in the result is unique. By deduplicating based on one or more columns, you can avoid analysis errors and inaccurate results caused by duplicate records.
For example, in e-commerce order processing, duplicate order records may exist because of system issues or user misoperations. Deduplication ensures that each order number appears only once and avoids misleading sales statistics and inventory management.

User Guide
Steps
- Drag the
Remove Deduplicatesoperator from the ETL operator area to the canvas on the right. - Click the
Remove Deduplicatesoperator and then clickAdd. - Select one or more
Deduplication Primary Keys (Deduplication Columns). - Click
OKand preview the data result.
Detailed Explanation
The following example shows how to configure Shop ID Deduplication.
Prerequisite: The upstream node is a product demo dataset containing duplicate records.
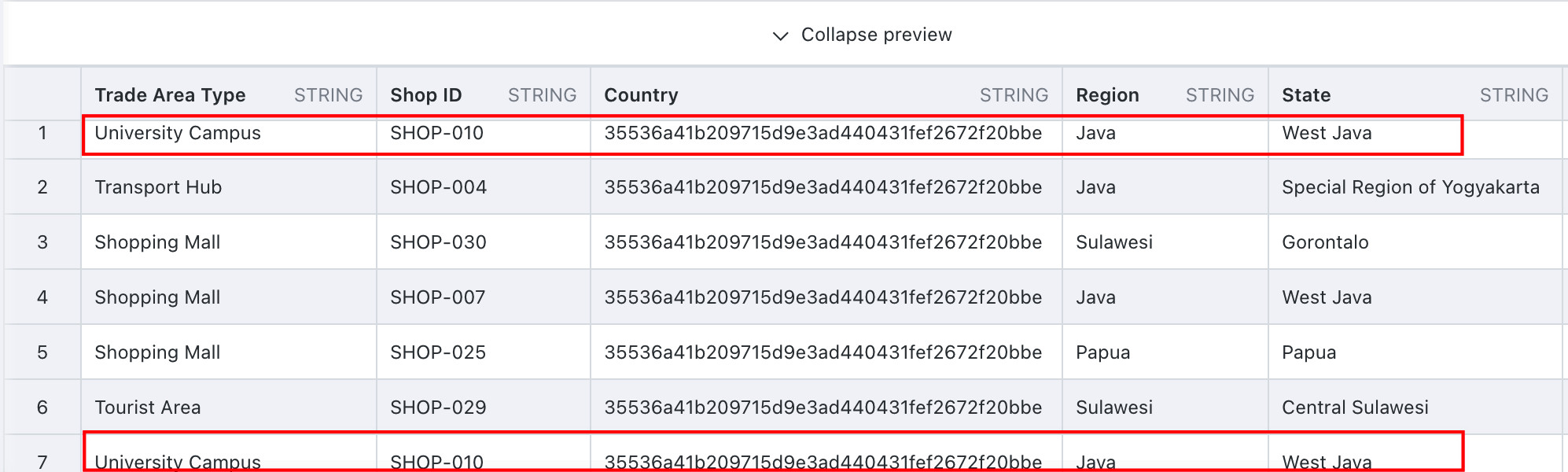
-
Drag the
Remove Deduplicatesoperator from the ETL operator area to the canvas on the right and connect it to the upstream node.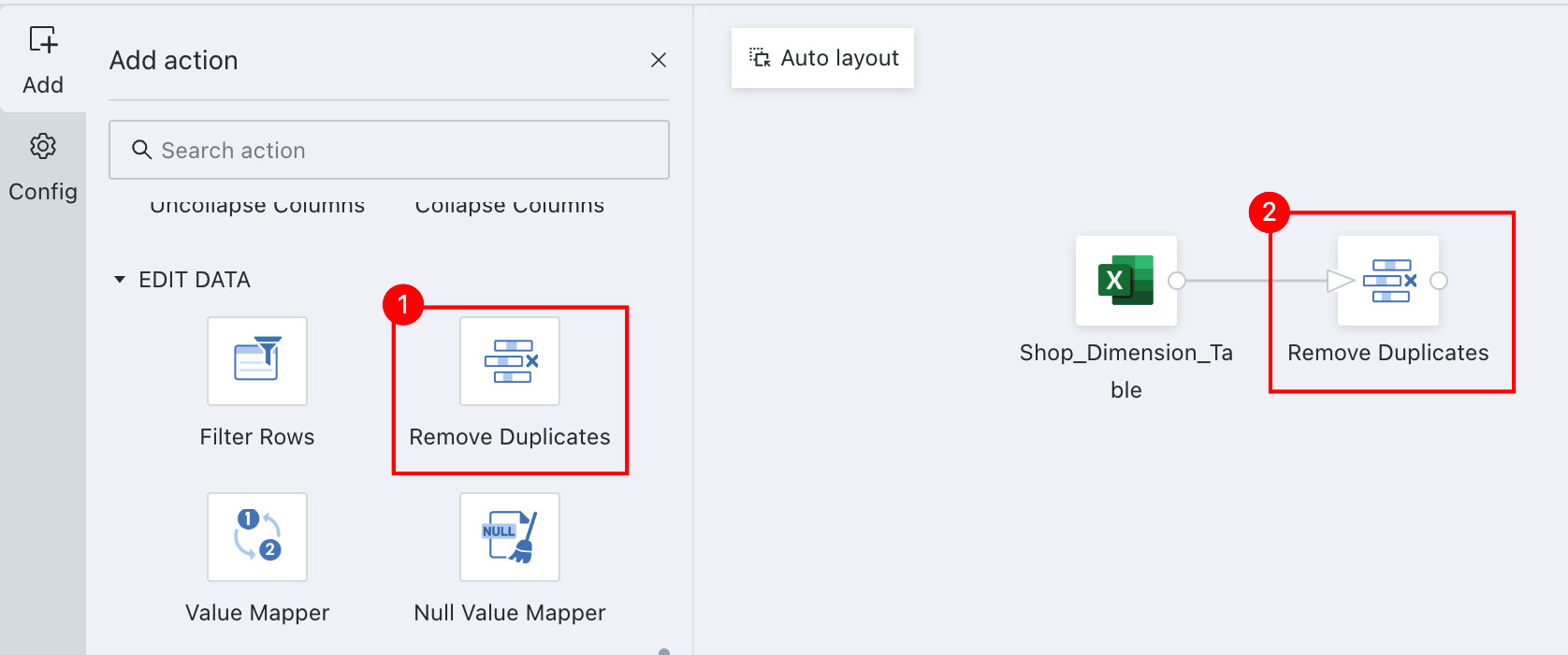
-
Click the
Remove Deduplicatesoperator. The left panel becomes the current operator configuration area. ClickAddand select the target fields for deduplication.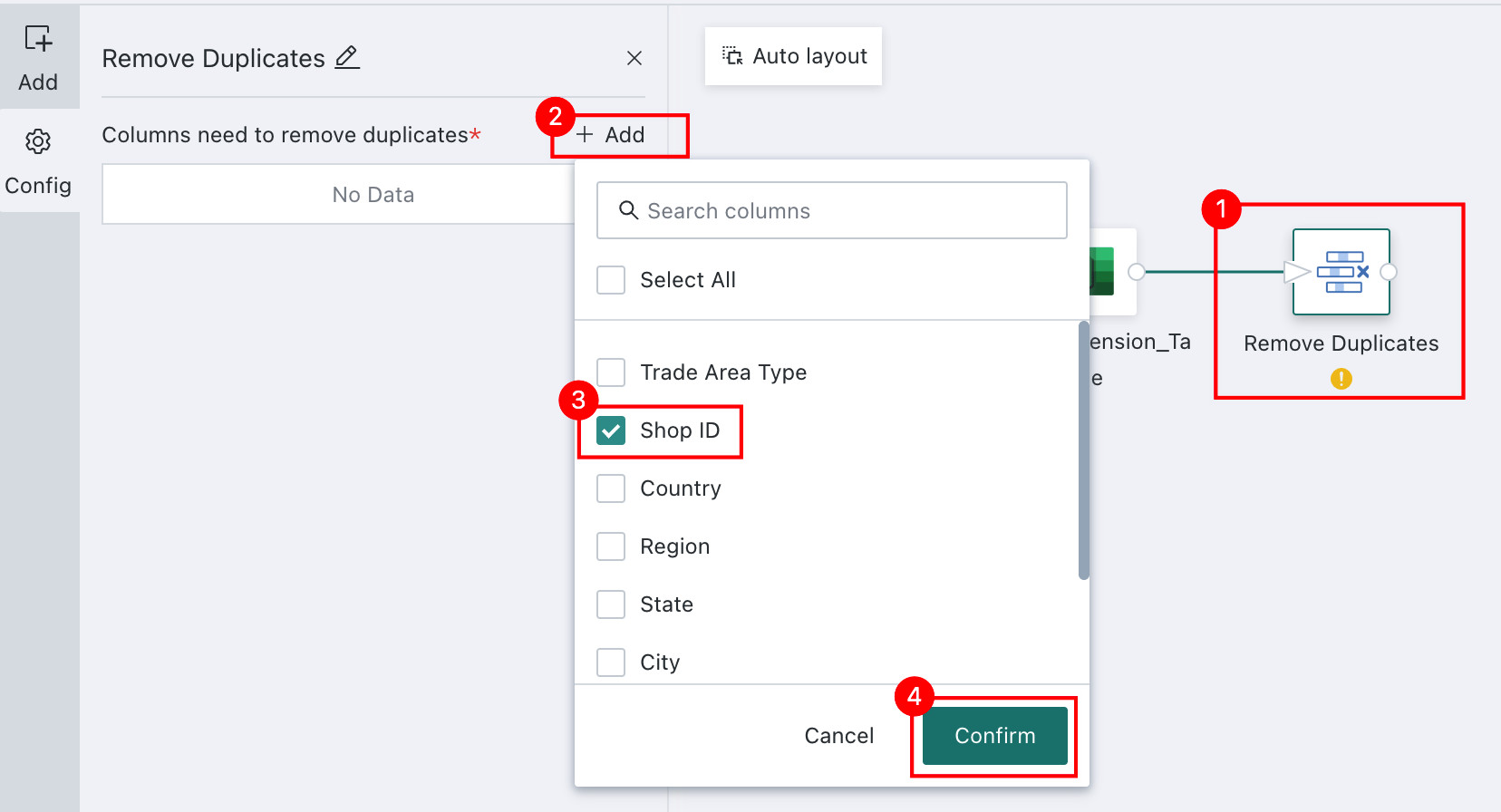 Notes
NotesThe primary key of the Input Dataset is usually used as the deduplication column. A primary key is one or more fields whose values uniquely identify a record in the table.
-
Click
Confirm. After configuration is complete, preview the processed data result to confirm that deduplication has succeeded.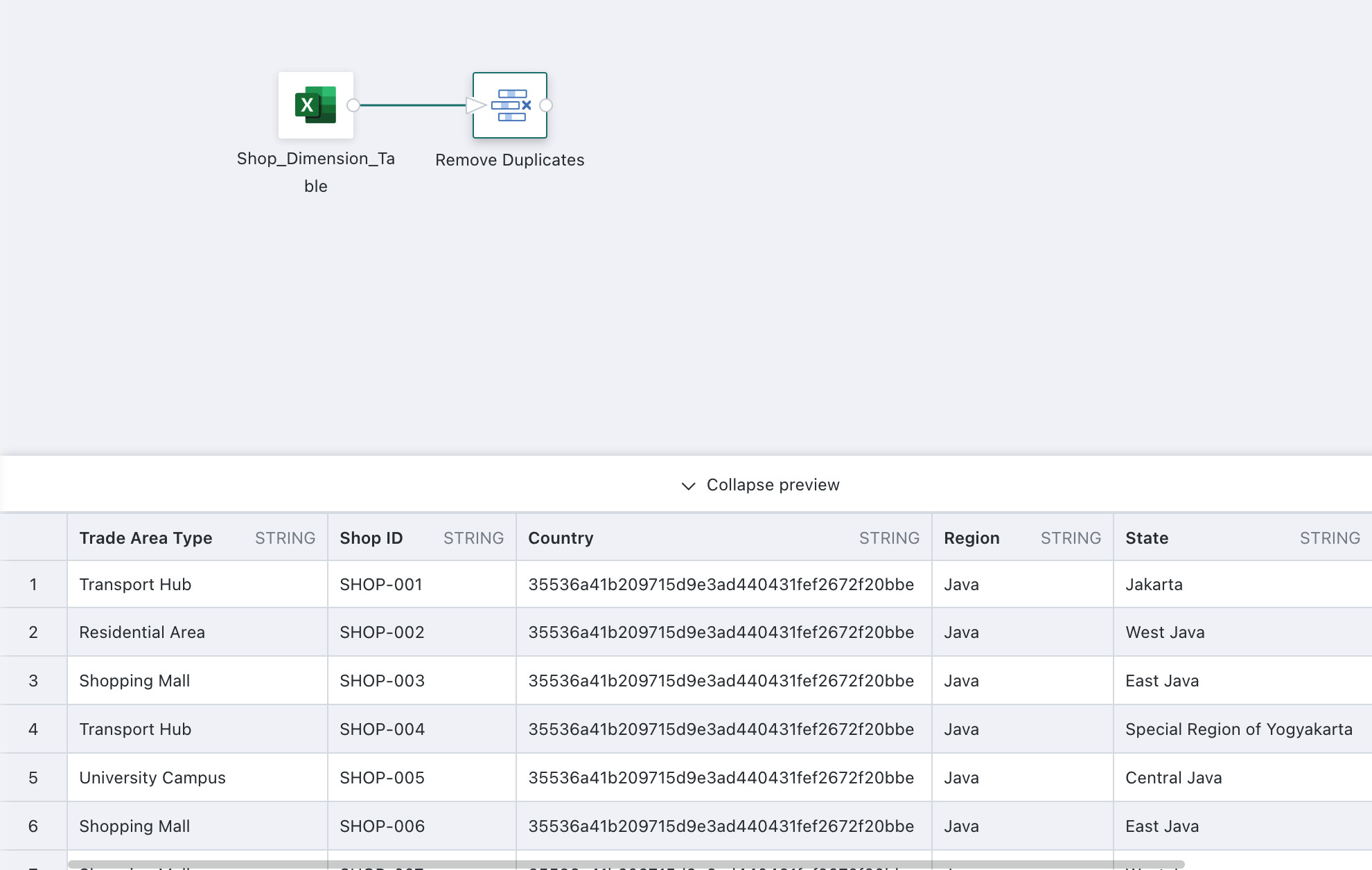
Only one record is retained for identical values in the deduplication field. If multiple identical records exist, one is retained at random. Therefore, if you need to control which row is retained, process the data in advance, for example through filtering or group aggregation.
For other data processing operators used later, see Getting Started.