Input Dataset
Overview
The Input Dataset is an important starting operator in the ETL workflow. It provides the data foundation for the first ETL stage, extraction, and prepares the data for downstream processing.
It supports rapid integration of heterogeneous multi-source data through multiple inputs, allowing users to combine data from different sources and structures easily.
User Guide
Steps
- Drag the
Input Datasetoperator from the ETL operator panel into the canvas editor on the right. - Click the
Input Datasetoperator and choose the target dataset. - Click
Confirmto load the dataset. - Optionally configure preview rules for the input dataset.
- Add other operator nodes as needed to build the full data processing flow.
Detailed Description
- Input datasets can come from file data, database datasets excluding direct connection databases and View Datasets, and output datasets from other Smart ETL flows.
- Make sure you have usage permission and Row- and Column-Level Permissions for the source dataset.
The following example uses an Excel file dataset.
- Drag the
Input Datasetoperator from the ETL operator panel into the canvas editor on the right.
-
Click the
Input Datasetoperator, enter the dataset nameMock Data 6e, and chooseFlat. Select eitherFlatorDirectoryas needed.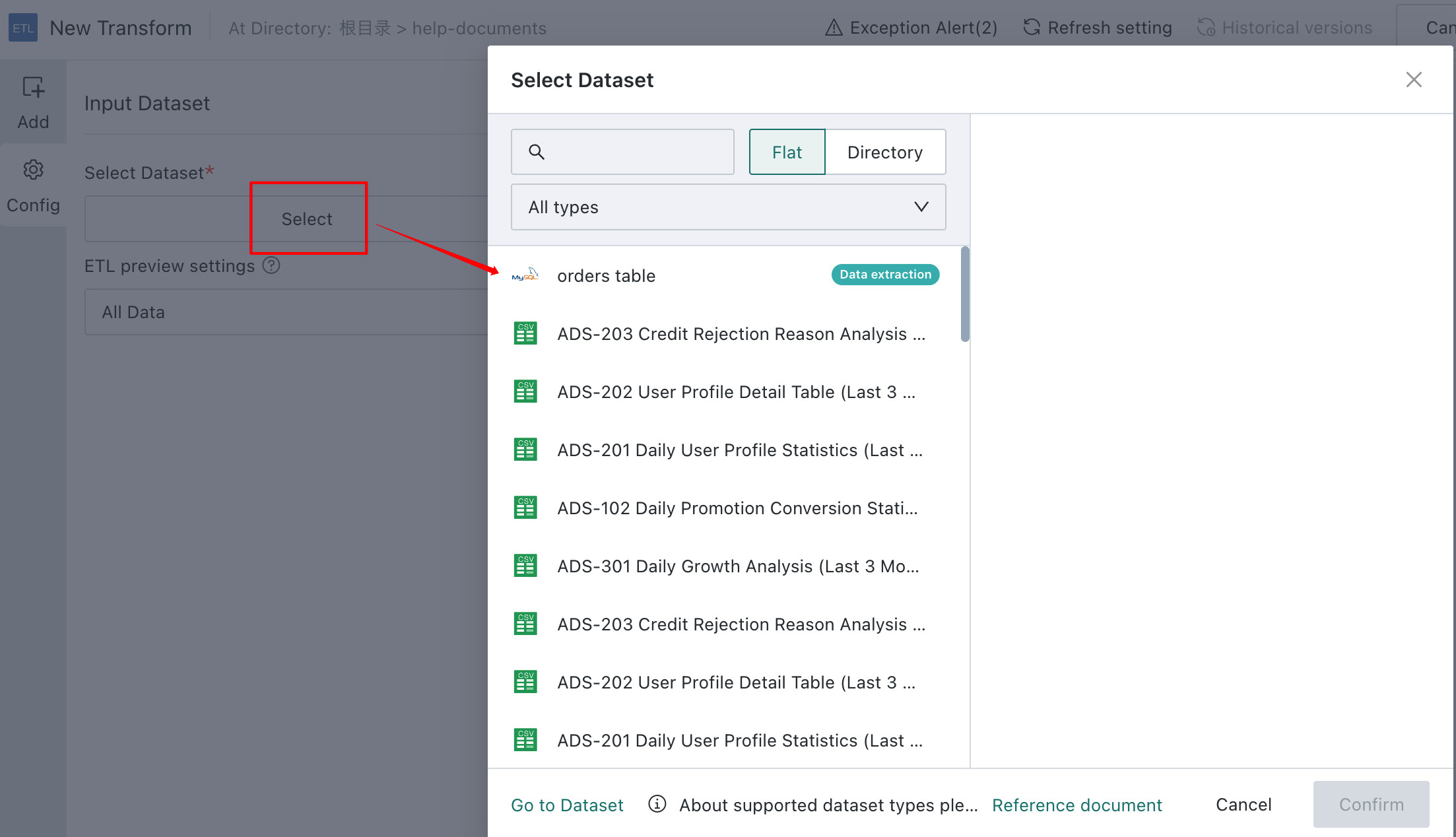
-
Locate the
Orders Tabledataset, and clickConfirm. The full folder path of the dataset is displayed to help users identify the correct dataset more quickly.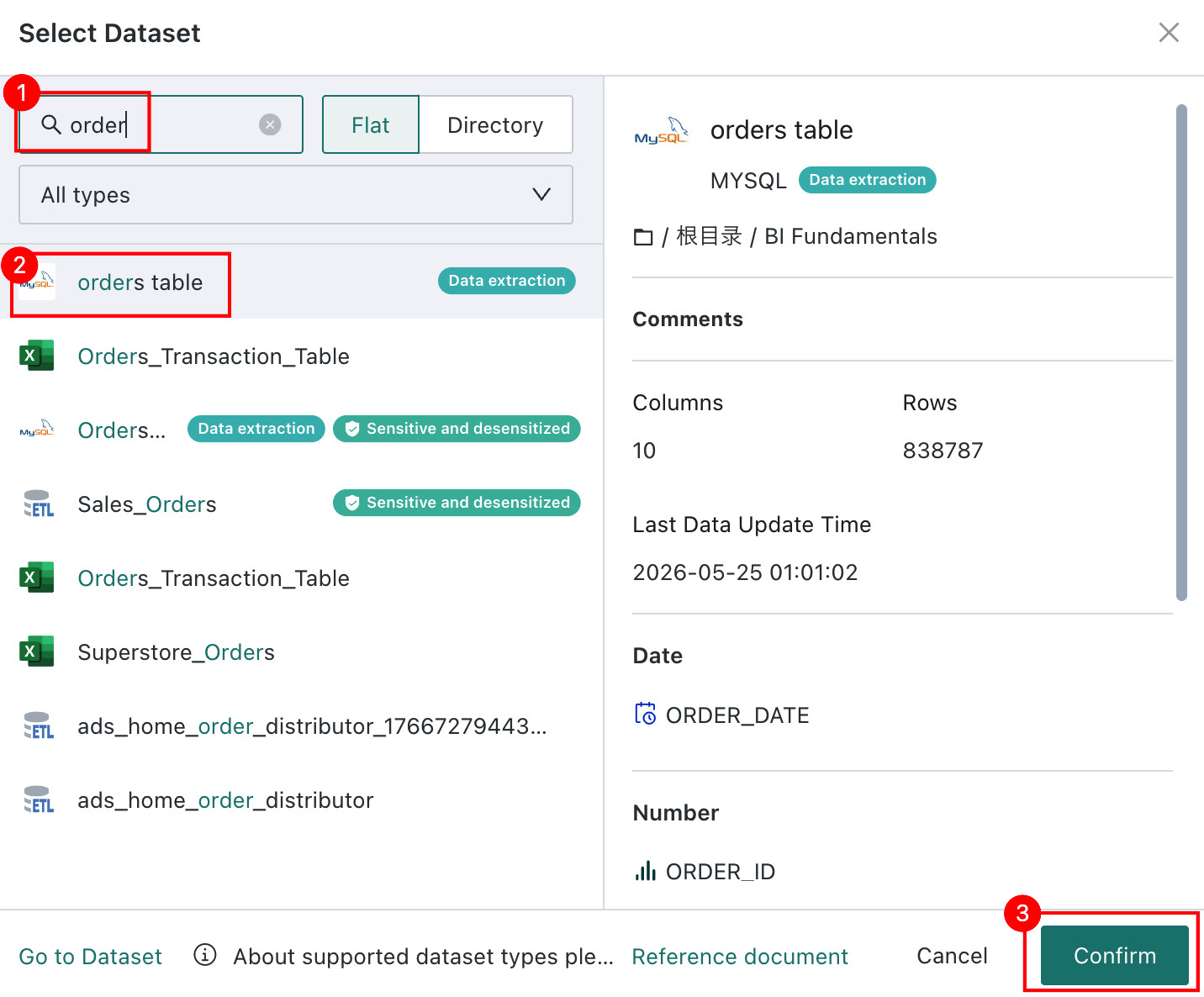 Note
NoteWhen switching between
FlatandDirectoryduring search, the entered search term and dataset type filter are cleared. After directory-based search, entering a subfolder or returning to a parent folder also clears the search term and filter settings.On the
Flatpage, dataset information is display-only and cannot be edited. To edit it, go to the Data Center.
| Search Mode | Description |
|---|---|
| Flat Search | All datasets under the root directory are treated as peers. Enter search content to find the corresponding dataset directly. The panel on the right also shows details such as the folder path of the selected dataset. |
| Directory Search | All folders and datasets in the current directory are treated as peers. Enter search content to search for folders and datasets. After entering a subfolder, the search box is cleared and subsequent searches apply only within the current folder. |
-
After the dataset is imported successfully, the left configuration panel displays the dataset type, storage path, and detailed field information.
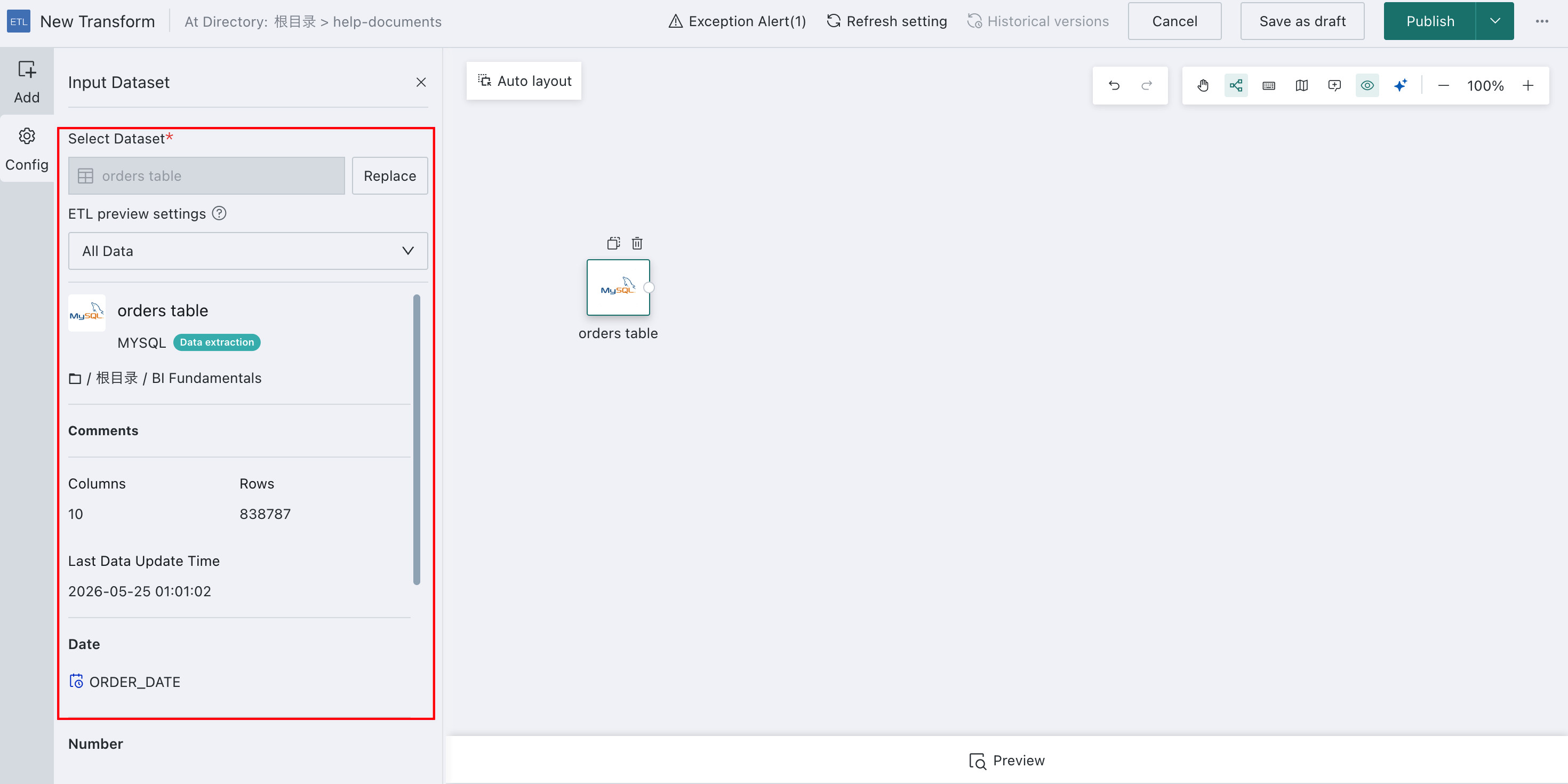
-
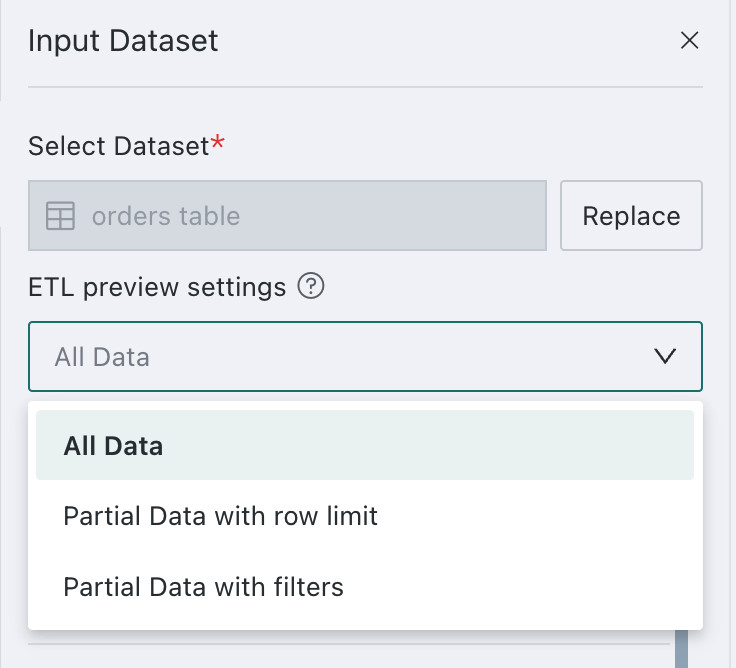
Optionally configure preview rules for the input dataset:
- Full Data
- Partial Data - Limit Row Count
- Partial Data - Set Filter Conditions
NoteTo improve ETL preview performance, it is recommended to use partial data. This setting affects preview data only, not the final result.
Replace ETL Datasets
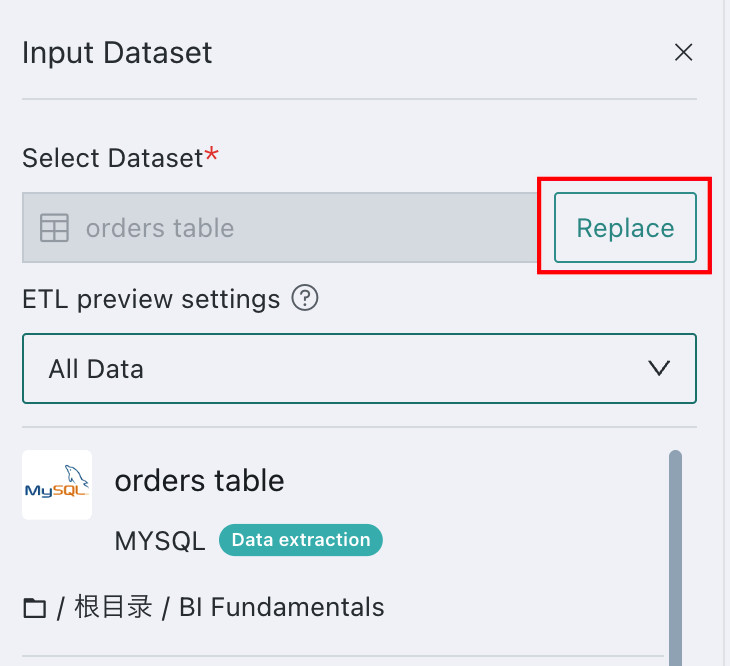
Replace a Single ETL Dataset
Click the imported dataset, then click Replace in the left information panel. Select the new dataset and click Confirm.
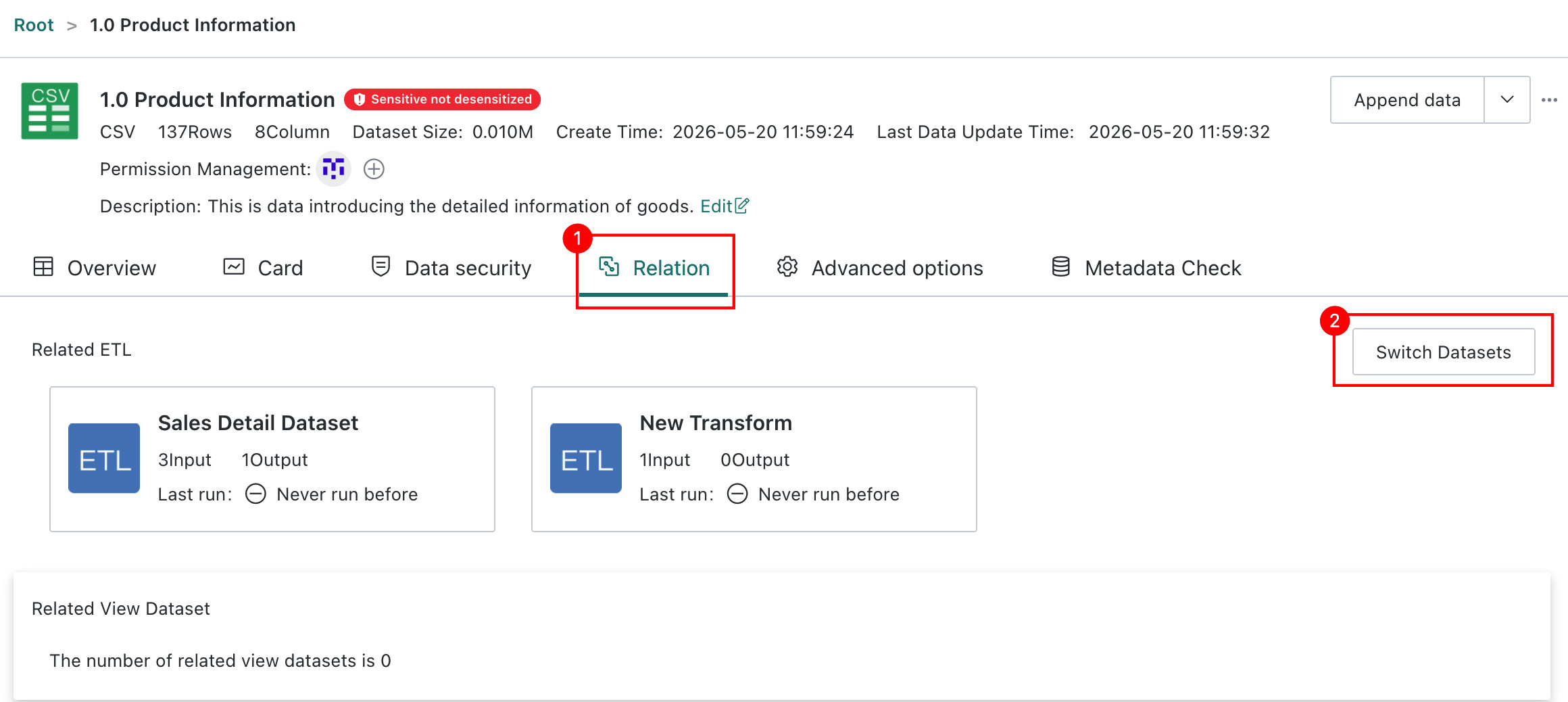
Replace ETL Datasets in Batch
During data development, when datasets need to be replaced with new ones, ETL supports batch replacement, making the process as convenient as switching datasets on Cards.
-
On the details page of a non-direct-connection dataset, open the
Associated Creationtab and chooseSwitch Dataseton the right. Multiple ETL flows can be selected, up to 200 at a time. -
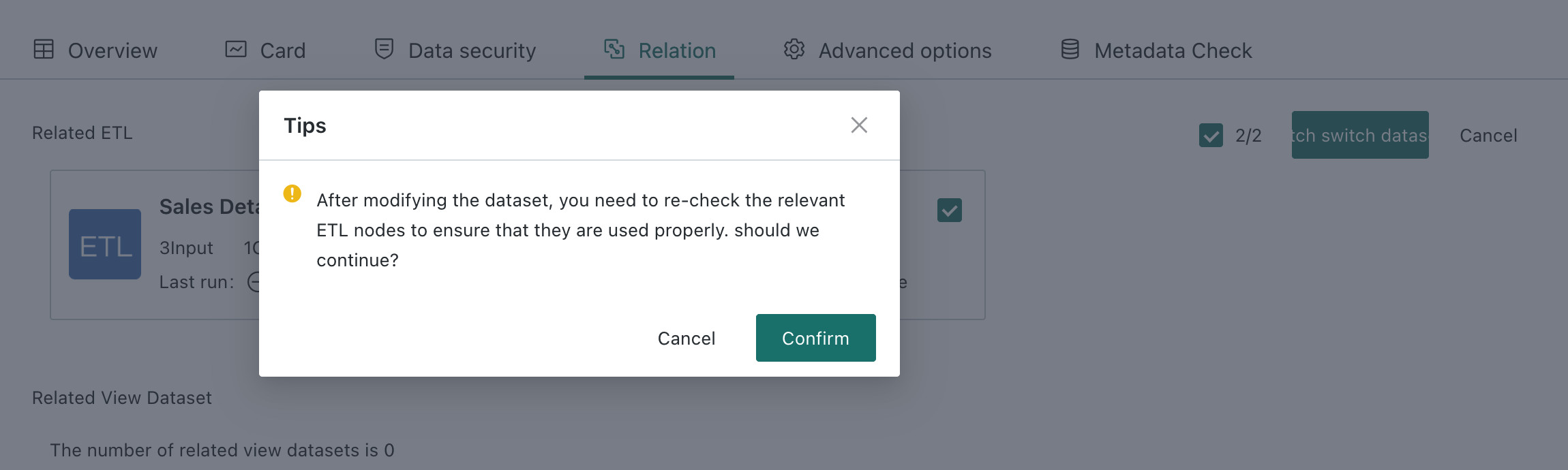
After switching datasets, you still need to check whether ETL node field names remain consistent and correct them manually if needed.
-
After the switch, the system returns a success or failure notification, and you can jump to the new dataset details page for review.
If you plan to use other data processing operators afterward, see Getting Started.