Month-End Comparison Issues in YoY and MoM Analysis
Before Optimization
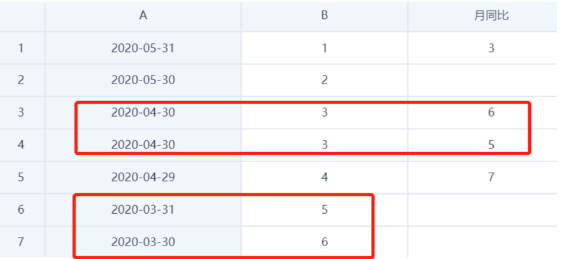
Monthly YoY comparison may produce a one-to-many result. For example, both March 30 and March 31 correspond to April 30, so April 30 appears with two records.
After Optimization
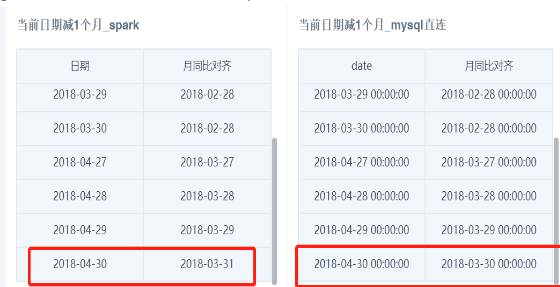
Find the comparison date based on the rule "current date - 1 months".
Note: Under this rule, Spark aligns to month end by default, while MySQL and PostgreSQL align by date. Other databases also have their own rules.
guanindex datasets, file datasets, and similar datasets are processed according to Spark rules. Direct datasets are processed according to the rules of their respective databases.
Summary
The optimized logic is:
Spark aligns to month end by default. Both May 31 and May 30 compare against April 30 data, and April 30 compares against March 30 data. guanindex datasets, file datasets, ETL output datasets, and similar datasets are processed according to Spark rules.
Direct datasets are processed according to the rules of their respective databases. For example, MySQL and ClickHouse align by date: both May 31 and May 30 compare against April 30 data, and April 30 compares against March 30 data.