Field Splitting Case Sharing
Requirement Background
A dataset may contain fields whose structure is a delimiter-joined string. During use, you may need to split it and extract only a string at a fixed position, or split the entire field into multiple columns.
Case Scenarios
Case 1: Create a calculated field and use string extraction functions to locate delimiter positions for splitting
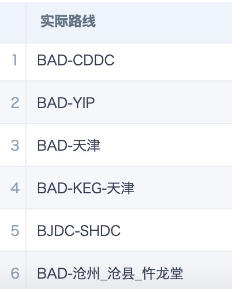
- Actual route start point: Extract the string before the first hyphen.
Syntax 1: SUBSTR([实际路线],0,INSTR([实际路线],'-')-1)
Syntax 2: LEFT([实际路线],INSTR([实际路线],'-')-1)
Syntax 3: SUBSTRING_INDEX([实际路线],'-',1)
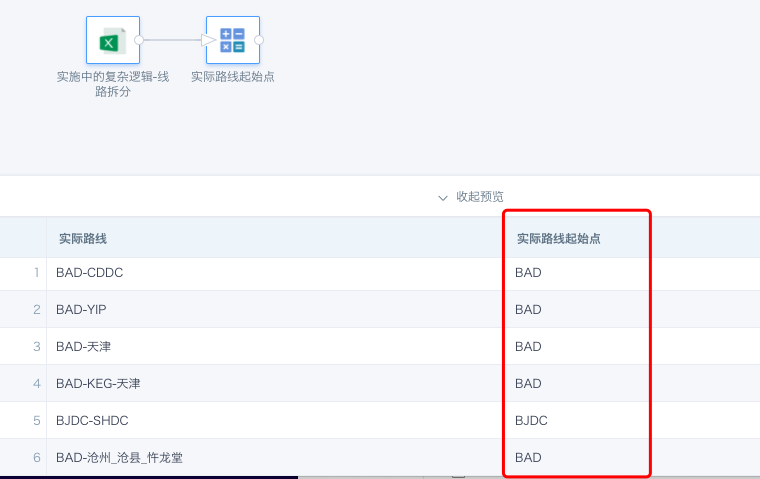
- Remaining part of the actual route: 1 and 2 can be concatenated back into the complete route.
SUBSTR([实际路线],INSTR([实际路线],'-')+1)
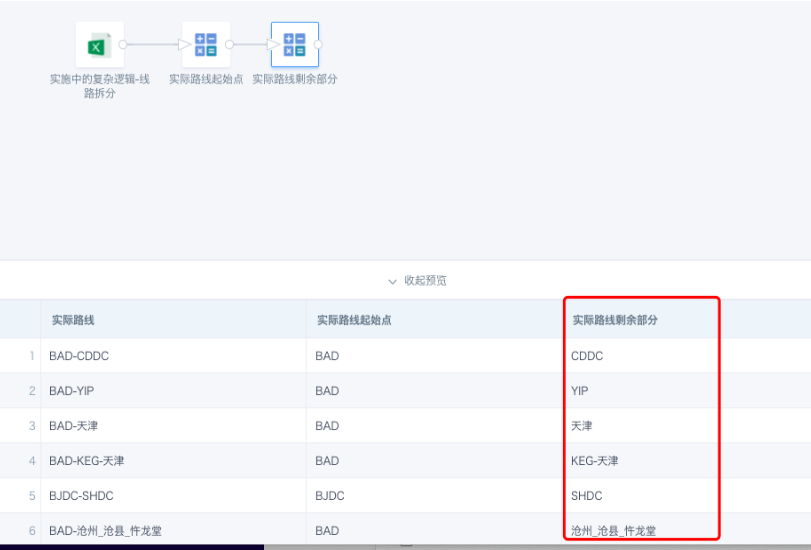
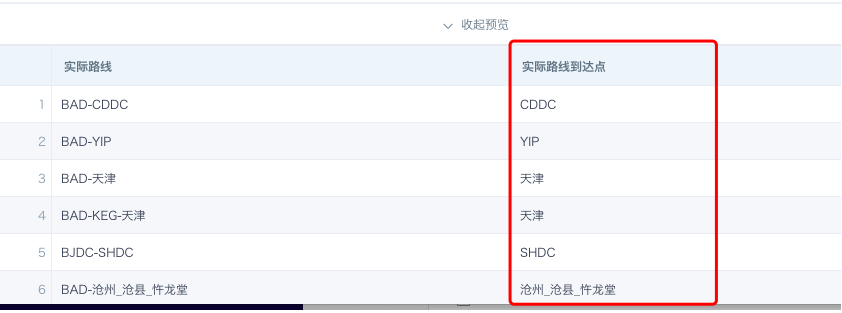
- Actual route destination point
Syntax 1: right([实际路线],instr(REVERSE([实际路线]),'-')-1)
Syntax 2: SUBSTRING_INDEX([实际路线],'-',-1)
- First half of the remaining actual route: 3 and 4 can be concatenated back into the complete route.
REGEXP_EXTRACT([实际路线],'(.+)(-{1}.+)',1)

- Whether the destination point is a factory: The rule for identifying a factory is pure letters, and the string does not end with DC.
when SUBSTR([实际路线到达点],-2)<>'DC' and (SUBSTR([实际路线到达点],0,1) <='Z' AND 'A'<= SUBSTR([实际路线到达点],0,1))
then '是'
when [实际路线到达点] is null or [实际路线到达点] = ''
then '否'
else '否'
end
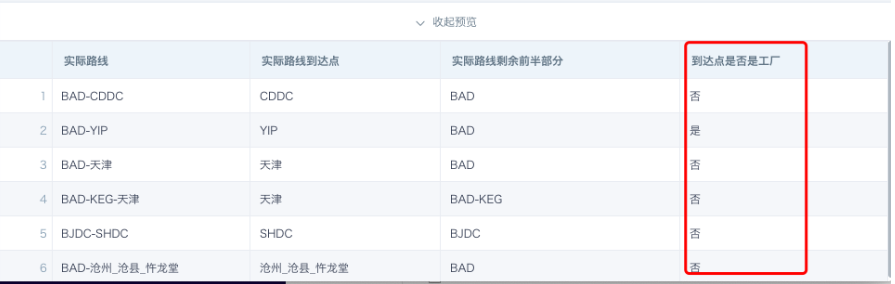
- Whether the destination point is WS: The rule for identifying WS is pure Chinese characters with no other letters or numbers.
when SUBSTR([实际路线到达点],-2)='DC' or (SUBSTR([实际路线到达点],0,1) <='Z' AND 'A'<= SUBSTR([实际路线到达点],0,1))
then '否'
when [实际路线到达点] is null or [实际路线到达点] = ''
then '否'
else '是'
end
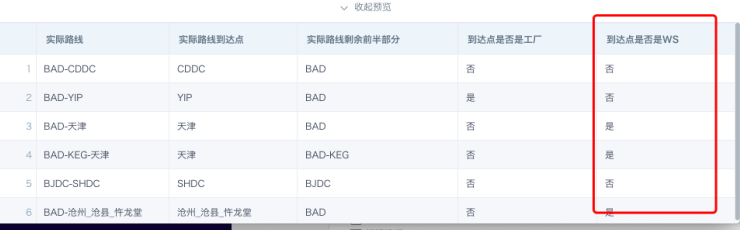
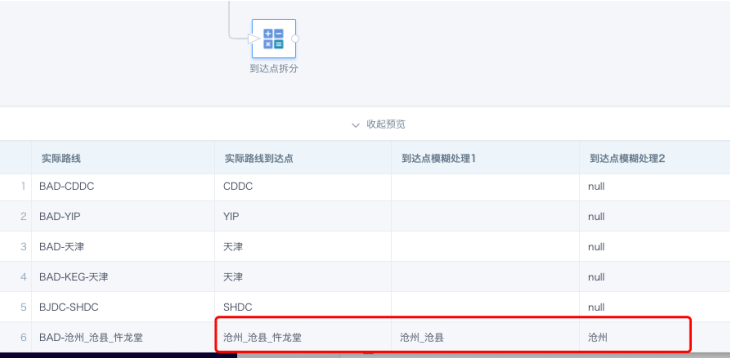
- Split destination point
Example:
Actual route = BAD-沧州_沧县_忤龙堂
Actual route destination point = 沧州_沧县_忤龙堂
Destination point fuzzy processing 1 = 沧州_沧县
Destination point fuzzy processing 2 = 沧州
-- Destination point fuzzy processing 1
REGEXP_EXTRACT([实际路线到达点],'(.+)(_{1}.+)',1)
-- Destination point fuzzy processing 2
case when INSTR([实际路线到达点],'_')>0 then SUBSTR([实际路线到达点],0,INSTR([实际路线到达点],'_')-1) end
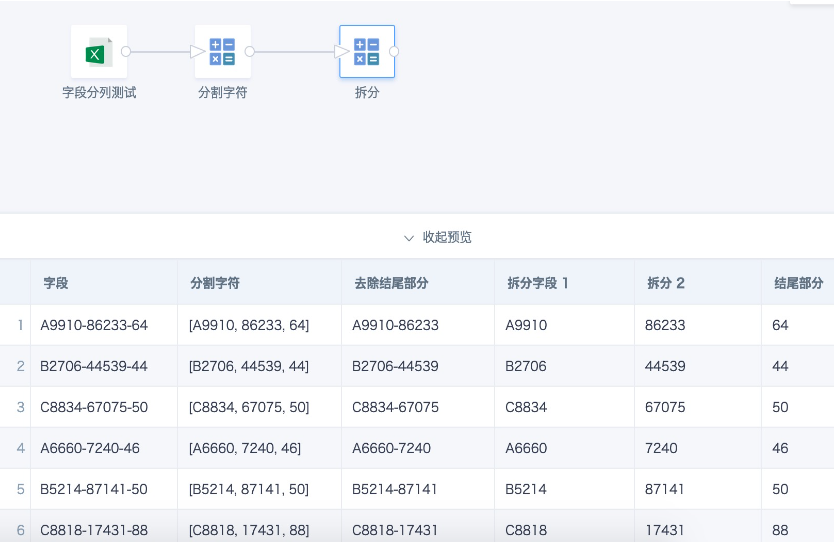
Case 2: Create a calculated field, split the original field into an array by delimiter, and locate array element positions for splitting
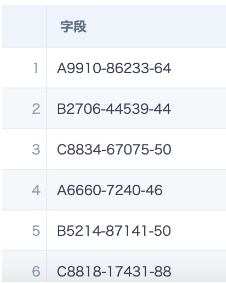
- Split into an array: split([字段],'-')**
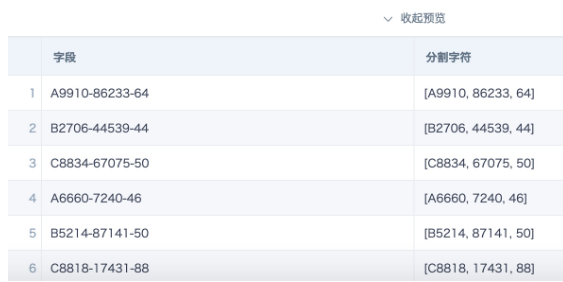
- Remove the ending part: array_join(slice([分割字符],1,size([分割字符])-1),'-')
Split field 1: [分割字符][0]
Split field 2: [分割字符][1]
Ending part: array_join(slice([分割字符],size([分割字符]),1),'')
Case 3: Extract Chinese or English parts from a string
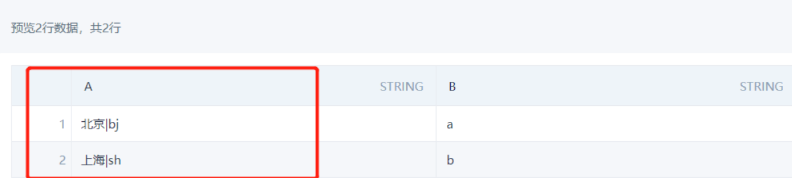
Implementation: Create a field and use regular expressions.
- Keep Chinese:

- Keep English:

Final result:

Note: The functions above can be used in ETL and non-direct, non-accelerated datasets. For direct datasets, use the corresponding database functions. For high-performance, or accelerated, datasets, use ClickHouse functions. For more text processing functions and cases, see Spark SQL Text Functions and Applications.