Basic Usage of Regular Expressions
Common Regular Expression Syntax
Category | Character | Description |
Ordinary Characters | [ ] | Match all characters in [ ], for example [aeiou] matches all e o u a letters in the string "google runoob taobao". |
[^ ] | Match all characters except those in [ ], for example [^aeiou] matches all letters except e o u a in the string "google runoob taobao". | |
[A-Z][a-z] | [A-Z] represents a range, matching all uppercase letters, [a-z] represents all lowercase letters. | |
. | Match any single character except newline characters (\n, \r), equivalent to [^\n\r]. To match ., use \. . | |
[\s\S] | Match all. \s matches all whitespace characters, including newlines, \S non-whitespace characters, including newlines. | |
\w\W | \w matches letters, numbers, underscores. Equivalent to [A-Za-z0-9_]; \W matches non-letters, numbers, underscores. Equivalent to '[^A-Za-z0-9_]'. | |
\d\D | \d matches digits 0-9, equivalent to [0-9]; \D: matches any non-digit character | |
Non-printable Characters | \cx | Match control characters indicated by x. For example, \cM matches a Control-M or carriage return. The value of x must be one of A-Z or a-z. Otherwise, c is treated as a literal 'c' character. |
\f | Match a form feed. Equivalent to \x0c and \cL. | |
\n | Match a newline. Equivalent to \x0a and \cJ. | |
\r | Match a carriage return. Equivalent to \x0d and \cM. | |
\s | Match any whitespace character, including spaces, tabs, form feeds, etc. Equivalent to [ \f\n\r\t\v]. Note that Unicode regular expressions will match full-width space characters. | |
\S | Match any non-whitespace character. Equivalent to [^ \f\n\r\t\v]. | |
\t | Match a tab. Equivalent to \x09 and \cI. | |
\v | Match a vertical tab. Equivalent to \x0b and \cK. | |
Special Characters | $ | Match the end position of the input string. If the Multiline property of the RegExp object is set, then $ also matches '\n' or '\r'. To match the $ character itself, use \$. |
( ) | Mark the beginning and end positions of a subexpression. Subexpressions can be captured for later use. To match these characters, use \( and \). | |
[ | Mark the beginning of a bracket expression. To match [, use \\[. | |
\ | Mark the next character as a special character, literal character, backreference, or octal escape. For example, 'n' matches the character 'n'. '\n' matches a newline. The sequence '\\' matches "\", while '\(' matches "(". | |
^ | Match the beginning position of the input string, unless used in a bracket expression, when this symbol is used in a bracket expression, it means not accepting the character set in that bracket expression. To match the ^ character itself, use \^. | |
{ | Mark the beginning of a quantifier expression. To match {, use \{. | |
| | Specify a choice between two items, equivalent to "or". To match |, use \|. | |
Quantifiers | * | Match the preceding subexpression zero or more times. For example, zo* can match "z" as well as "zoo". * is equivalent to {0,}. |
+ | Match the preceding subexpression one or more times. For example, 'zo+' can match "zo" as well as "zoo", but cannot match "z". + is equivalent to {1,}. | |
? | Match the preceding subexpression zero or one time. For example, "do(es)?" can match "do" in "do", "does" in "does", "do" in "doxy". ? is equivalent to {0,1}. | |
{n} | n is a non-negative integer. Match exactly n times. For example, 'o{2}' cannot match 'o' in "Bob", but can match the two o's in "food". | |
{n,} | n is a non-negative integer. Match at least n times. For example, 'o{2,}' cannot match 'o' in "Bob", but can match all o's in "foooood". 'o{1,}' is equivalent to 'o+'. 'o{0,}' is equivalent to 'o*'. | |
{n,m} | m and n are non-negative integers, where n <= m. Match at least n times and at most m times. For example, "o{1,3}" will match the first three o's in "fooooood". 'o{0,1}' is equivalent to 'o?'. Please note that there cannot be spaces between the comma and the two numbers. |
Spark Regular Functions
Category | Purpose | Function | Example | Result |
Validation | Determine whether a string matches a regular expression, returns true/false/null | regexp(str, regexp) | regexp('abcde12345','D|d') | true |
rlike(str, regexp) | rlike('abcde12345','^A') | false | ||
regexp_like(str, regexp) | regexp_like('abcde12345','\\d+') | true | ||
Extraction | Extract the first substring matching the regular expression from the string according to the group index value | regexp_extract(str, regexp[, idx]) | regexp_extract('ABCDE/ab(cde)','[A-Za-z]+',0) | ABCDE |
Extract all substrings matching the regular expression from the string according to the group index value, returns an array | regexp_extract_all(str, regexp[, idx]) | regexp_extract_all('100-200, 300-400', '(\\d+)-(\\d+)',1) | [100, 300] | |
Replacement | Replace all substrings matching the regular expression with the target string | regexp_replace(str, regexp, rep[,position]) | regexp_replace('ABCDE/ab(cde)','[\/()]','.') | ABCDE.ab.cde. |
Split | Use substrings matching the regular expression to split a long string into an array. limit can specify the upper limit of elements after splitting. | split(str, regexp[, limit]) | split('ABCDE/ab(cde)','[\/()]') | [ABCDE, ab, cde, ] |
Special Note: Spark uses Java regular expressions, escape characters \ need to be escaped with . For example, to match digits, use \d, not \d. Official documentation please refer to Spark SQL .
Application Scenarios
Extract Numbers
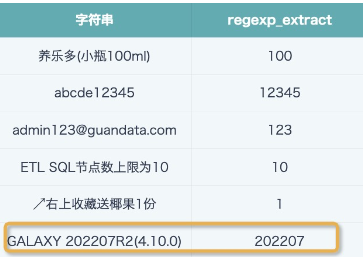
- Note: REGEXP_EXTRACT can only extract the first substring that meets the conditions. If there are multiple places in the string that meet the conditions, they cannot all be accurately extracted. Effect reference figure below.
REGEXP_EXTRACT([String],'\\d+',0)
Comment: \d matches digits 0-9; + matches 1 or more characters;
REGEXP_EXTRACT ([String],'\\d+\\.?\\d*',0)
Comment: \d+ means extract digits before decimal point; \.? means match 0 or 1 decimal point; \d* means extract digits after decimal point, may be none, or may be multiple digits;

REGEXP_EXTRACT([String],'\\d{1,2}\/\\d{1,2}\/\\d{2,4}',0)
Comment: \d{1,2} means 1 to 2 digits, used to match month, day; \d{2,4} means 2 to 4 digits, match year; / matches forward slash.

Extract Chinese Characters
REGEXP_EXTRACT([String],'[\u4e00-\u9fa5]+',0)
But this method is not applicable in the situation shown in the yellow box in the figure below. The REGEXP_EXTRACT function stops matching subsequent characters after being interrupted by symbols or other characters during extraction. In this case, you can try using the REGEXP_REPLACE function, comparison effect reference figure below.
REGEXP_REPLACE([String],'[^\u4e00-\u9fa5]+','')

Comment: The ^ symbol means matching characters at the beginning position of the string when outside [], and when the ^ symbol is placed inside [], it means not, here it means replacing non-Chinese characters with empty strings.
Extract/Delete Specific Position Content
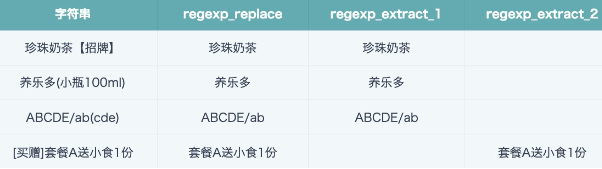
REGEXP_REPLACE([String],'[\\[(【]\\S*[\\])】]','')
Comment: [\[(【] matches 3 types of opening brackets, [\])】] matches 3 types of closing brackets; \S* matches 0 or more non-whitespace characters.
If the bracket part is fixed at the front or back of the string, you can also use the following writing method.
REGEXP_EXTRACT([String],'(\\S+)([\\[(【])',1)
REGEXP_EXTRACT([String],'([\\])】])(\\S+)',2)
Comment: Each () is a group; (\S+) matches 0 or more non-whitespace characters, as 1 group; ([\[(【]) is the 2nd group, matching 3 types of opening brackets; index value 1 means take the 1st group, i.e., all characters before the brackets; index value 2 means take the 2nd group, i.e., all characters after the brackets.
The comparison effect of 3 usage methods is shown in the figure below, returns empty string if no match result. Achieving the same effect may have multiple solutions, you can choose the appropriate method according to the actual scenario.
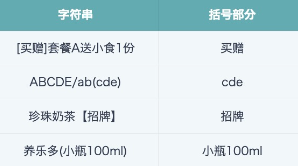
Extract characters inside brackets
REGEXP_EXTRACT([String],'([\\[(【])(\\S*)([\\])】])',2)
Practical Case
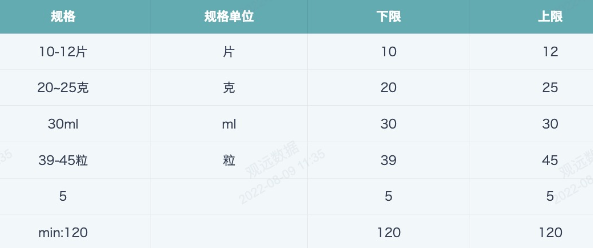
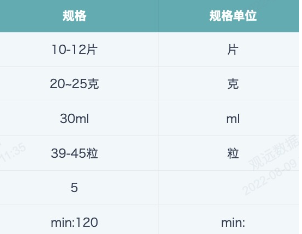
【Requirement】Extract the unit, upper limit and lower limit from drug specifications.
【Approach】
Specification Unit: If the specification units are uniformly Chinese, you can use the method mentioned above to extract Chinese characters, but if English specification units appear, it won't work, so use the following method (not the only solution).
REGEXP_EXTRACT([Specification],'[^-~\\s\\d]+',0)
Analysis: [^ ] means not containing all characters listed in the [] set, -~ means matching symbols '-' and '~', \s means matching spaces, \d means matching digits, finally + means repeat matching 1 or more times. Combined, it means excluding '-', '~', spaces and digits, take all remaining characters, result as shown in the figure below. At this time, it can be found that "min:" in the last row string is not a specification unit, and needs to be removed with additional REGEXP_REPLACE or REPLACE function.
Lower Limit: Extract the upper and lower limits of each record, for example 10-12 tablets, then the lower limit is 10, upper limit is 12. Just use \d+ to extract the first numeric string.
REGEXP_EXTRACT([Specification],'\\d+',0)
Upper Limit: First use .+[-~] to extract all - and ~ symbols and the characters before them, then replace with empty value, then use \d+ to extract the remaining digits.
REGEXP_EXTRACT(REGEXP_REPLACE([Specification],'.+[-~]',''),'\\d+',0)
Final effect: