Spark SQL Text Functions and Applications
Basic String Operations
Purpose | Function | Example | Result |
Determine whether the value is null | isnull() | true/false | |
Determine whether the value is not null | isnotnull() | true/false | |
Check for a null value and replace it | ifnull(expr1, expr2) | ifnull(null,0) | 0 |
Return the first non-null value | coalesce(expr1, expr2, ...) | coalesce(NULL, 1, NULL) | 1 |
Return the string length | length() | length('ABC DE') | 6 |
Convert an English string to title case | initcap() | initcap('ABC DE') | Abc De |
Convert an English string to lowercase | lcase()/lower() | lcase('ABC'); lower('ABC') | abc |
Convert an English string to uppercase | ucase()/upper() | ucase('abc'); upper('abc') | ABC |
Reverse a string | reverse() | reverse('abc') | cba |
Convert other types to strings | string() | string(123) | 123 |
cast( expr as string) | cast(123 as string) | 123 |
String Search
Purpose | Function | Example | Result |
Return the position of the first matched string | locate(substr, str[, pos]) [, pos] specifies the starting search position and can be omitted. | locate('n','Ann',3) | 3 |
instr(str, substr) | instr('Ann','n') | 2 | |
find_in_set(str, str_array) The searched string is a comma-separated string. | find_in_set('ab','abc,b,ab,c,def') | 3 | |
Return the first substring matched by a regular expression | regexp_extract(str, regexp[, idx]) | regexp_extract('*A1B2*C3**','[A-Z]+',0) | A |
Fuzzy match a string with the specified pattern and return true/false. Use it with wildcards. | like | 'A&B' like '%&%'; 'A&B' like '&%' | true; false |
Fuzzy match a string with the specified pattern and return true/false. Use it with regular expressions. | rlike | 'PURE&MILD' rlike '[A-Z]+\&[A-Z]+' | true |
String Extraction
| Purpose | Function | Example | Result |
| Extract a string. If extraction length [, len] is omitted, all characters starting from the specified position are extracted. | substr(str, pos[, len]) ; substring(str, pos[, len]) | substring('123abcABC', 2, 3); substr('Spark SQL', -3) | 23a; SQL |
| Return the substring before the nth occurrence of the delimiter in the string. If n is negative, return all characters to the right of the -nth delimiter from the right. | substring_index(str, delim, n) | substring_index('a.b.c.d.e', '.', 2); substring_index('a.b.c.d.e', '.', -2) | a.b; d.e |
| Extract a fixed-length string from the left start | left(str, len) | left('Spark SQL', 3) | Spa |
| Extract a fixed-length string from the right end | right(str, len) | right('Spark SQL', 3) | SQL |
| Remove spaces at the start (left side) of a string | ltrim(str) ; trim(LEADING FROM str) | ltrim(' Spark SQL') | Spark SQL |
| Remove spaces at the end (right side) of a string | rtrim(str) ; trim(TRAILING FROM str) | rtrim('Spark SQL ') | Spark SQL |
| Remove spaces at both the start and end of a string | trim(str) ; trim(BOTH FROM str) | trim(' Spark SQL ') | Spark SQL |
| Remove specified characters from the start and end of a string | trim(trimStr FROM str) removes both sides; trim(LEADING trimStr FROM str) removes the left side; trim(TRAILING trimStr FROM str) removes the right side | trim('*' from 'ABC**') | ABC |
String Replacement
| Purpose | Function | Example | Result |
|---|---|---|---|
| Replace all matched characters. If [, replace] is omitted, all matched characters are removed. | replace(str, search[, replace]) | replace('ABCabc', 'abc', 'DEF') | ABCDEF |
Multi-character replacement. For input, replaces each character in from with the corresponding character in to. If from is longer than to, extra characters in from are deleted. | translate(input, from, to) | translate('AaBbCc', 'abc', '123'); translate('AaBbCc', 'abc', '12') | A1B2C3; A1B2C |
| Replace characters at a fixed position; replacement length can be specified | overlay(input, replace, pos[, len]) | overlay('Spark SQL' ,'tructured' ,2,4); overlay('Spark SQL' PLACING 'tructured' FROM 2 FOR 4) | Structured SQL |
| Use regular expression matching to replace all matched characters | regexp_replace(str, regexp, rep) | REGEXP_REPLACE('A1B2C3**','[\\d\*]','') removes all digits and * | ABC |
String Splitting and Concatenation
Purpose | Function | Example | Result |
Split a string by one or more characters and return an array. Delimiters support regular expressions. `limit` controls the number of elements after splitting. If omitted, all parts are split. | split(str, regex, limit) | split('A1B2C','\\d'); split('A1B2C','\\d',2); split('A-B-C','-') | [A, B, C]; [A, B2C]; [A, B, C] |
String concatenation | concat | concat('Spark', 'SQL') | SparkSQL |
expr1 || expr2 | 'Spark' || 'SQL' | SparkSQL | |
Concatenate strings or arrays with a delimiter | concat_ws(sep[, str | array(str)]+) | concat_ws('-', 'Spark', 'SQL') | Spark-SQL |
Return a new string generated by repeating the string the specified number of times | repeat(str, n) | repeat('ABC', 2) | ABCABC |
Application Case
Requirement: For the text field "Sprint", extract the following values separately:
- The middle part "Schedule", a 6-to-8-character string composed of digits and letters.
- The content in parentheses, "Test Version".
- Derive "Release Version" based on "Test Version".
Logic: The number after the last decimal point is the minor version number. If it is 0, the preceding part is the release version number. If it is not 0, add 1 to the middle number.
Final Result:
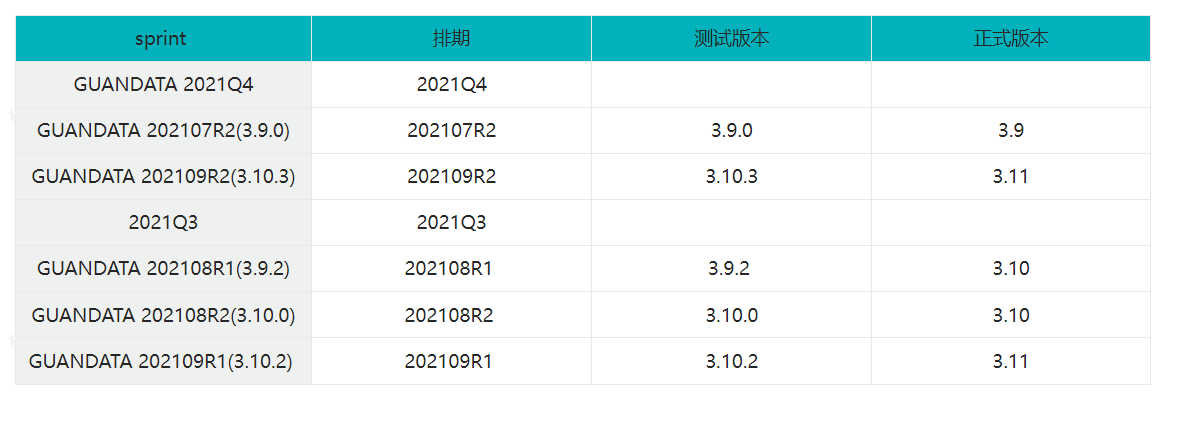
Implementation methods for "Schedule" (choose any one):
1. substr([Sprint],8,8)
2. left(replace([Sprint],'GUANDATA'),8)
3. regexp_extract([Sprint], '(\\d{4,6}\\w{2})', 1)
4. element_at(flatten(sentences([Sprint])),2)
Implementation methods for extracting "Test Version" in parentheses (choose any one):
1. regexp_extract([Sprint], '(\\d\\.\\d{1,2}\\.\\d)', 1)
2. case when instr([Sprint],'(')>0 then replace(substr([Sprint],instr([Sprint],'(')+1),')') end
3. case when [Sprint] like '%(%' then substring_index(translate([Sprint],'()','-'),'-',-1) end
4. element_at(flatten(sentences([Sprint])),3)
Implementation method for deriving "Release Version" based on "Test Version":
case when right([Test Version],1)=0 then substring_index([Test Version],'.',2)
else concat(left([Test Version],2),int(substr(substring_index([Test Version],'.',2),3)+1))
end