ETL Optimization Suggestions
ETL performance optimization mainly focuses on two aspects: reducing the amount of data processed and reducing computational complexity.
I. Reduce the Amount of Data Processed
1. Choose the Appropriate Source Data
Usually, there are multiple data sources available for a report. You should use the smallest dataset based on a thorough understanding of the data.
For example, to analyze store sales in the ads layer, the source data can come from "dm_product sales inventory daily summary table" (data volume: 1 billion * 62), "dm_sales detail wide table" (data volume: 200 million * 101), or "dm_sales daily summary table" (data volume: 6 million * 23). Using "dm_sales daily summary table" alone saves more than 2 minutes in data reading compared to "dm_product sales inventory daily summary table".
2. Remove Unnecessary Rows and Columns
For reports displayed directly on the frontend, you can remove unnecessary rows and columns to reduce data throughput and speed up execution. Use Select Columns and Filter Data Rows as early as possible in the ETL process (this not only reduces computational complexity but also data reading volume).
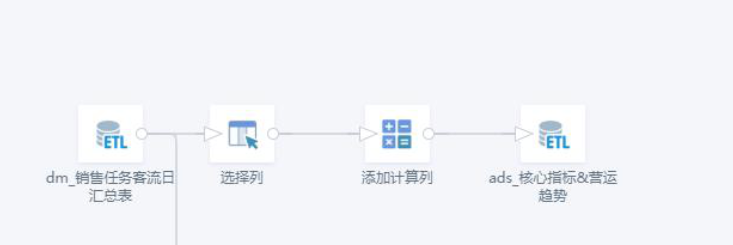
3. Pre-aggregate Operations
You should aggregate data to the required granularity as early as possible in ETL to avoid unnecessary large-scale joins, filters, or calculated fields at finer granularity. Especially, add group aggregation before join nodes to avoid data expansion.
4. Pre-calculate Fields
Fields that depend only on dimension tables should be calculated before joining dimension tables; fields that can be calculated from existing fields should be calculated before data expansion.
II. Reduce Computational Complexity
1. Avoid Redundant Composite Keys
The complexity of aggregation operations is directly related to the number of primary keys. For 100 rows of data, aggregating by 1 key requires 100 calculations; by 2 keys, 200 calculations. More keys increase time complexity linearly.
In the figure below, organization-related fields depend only on "organization id", and card type - membership level, registration date depend only on "membership card number". It is recommended to put them in the value bar (aggregation: max or none). The recommended approach is shown in the second figure, which is efficient and helps verify our understanding of dataset keys, reducing errors.

2. Pre-branching
When calculating peer data or aggregating by different dimensions, ETL may need to branch. Since Guandata's smart ETL does not retain intermediate node values, each branch must recalculate from the start. If there are complex nodes before branching, efficiency is low. Branching should be done as early as possible if logic allows.
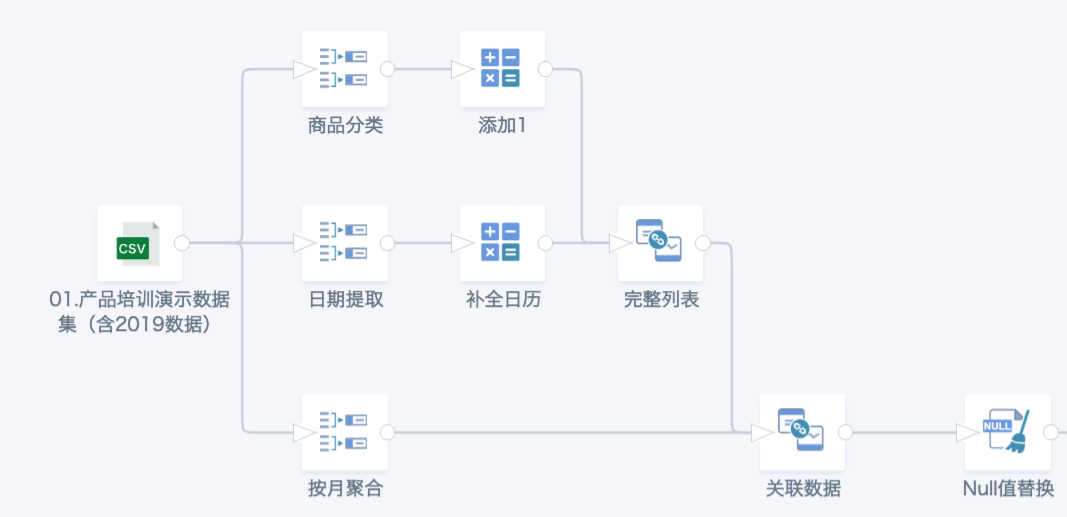
3. Avoid Multiple Outputs in One ETL
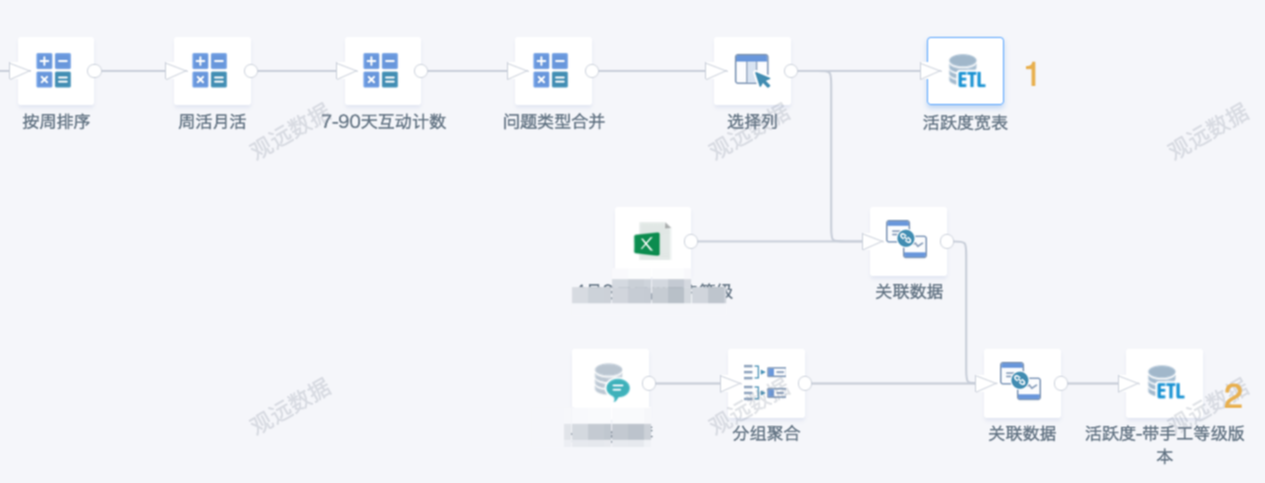
ETL does not save intermediate node values, so outputting multiple datasets in one ETL does not optimize time and may interfere with logic. It is better to save as a new ETL or split into multiple ETLs.
In the example below, the second output dataset is based on the first. Instead, output only one dataset "activity wide table" in this ETL, then create a new ETL using it as input for the second dataset.
III. From Full Calculation to Incremental Calculation
ETL runtime consists of data read/write time and computation time. Since full data must still be concatenated and written, incremental updates in ETL do not optimize read/write time. However, incremental updates are still suitable in some scenarios:
-
If ETL computation is simple (e.g., matching a few fields in a dimension table), incremental updates improve efficiency by about 50%.
-
If ETL computation is complex (e.g., out-of-stock rate calculation), incremental updates can greatly reduce the range of products and time, and the output dataset is small, so efficiency improves significantly.
For details, see: "[How ETL Achieves Incremental Update](5-How ETL Achieves Incremental Update.md)".
IV. Improve Efficiency and Reduce Maintenance Costs
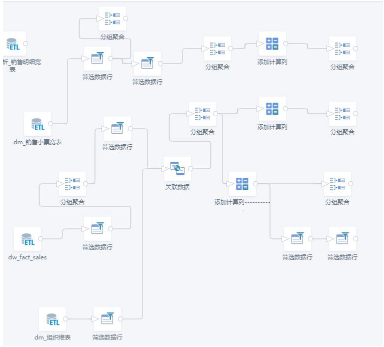
1. Use ETL Connections to Clarify Logic
Data flow should be clear and visible in ETL. Avoid random ETL layouts. Use "Auto Layout" and "Add Comments" to clarify logic.
2. Use Strong Rules to Ensure Keys Meet Expectations
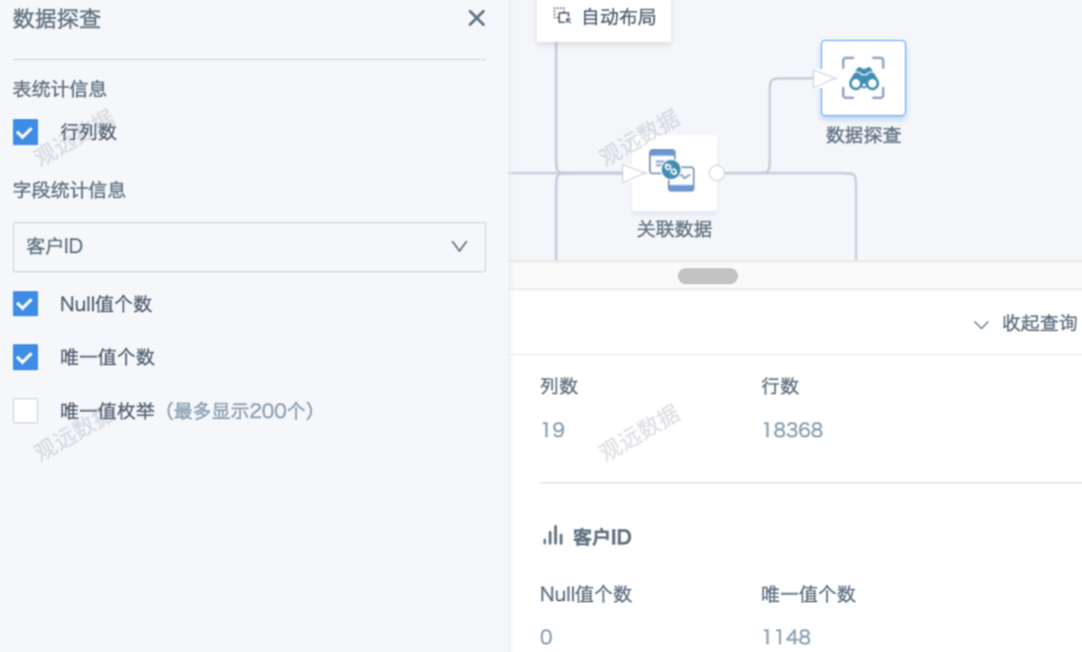
It is strongly recommended to have expectations and validation for each node's keys (aggregation dimensions). For operations that may change keys, estimate in advance and validate afterwards. Joins (non-key joins or not using all keys), row concatenation (inconsistent keys), group aggregation, select columns (not selecting all keys), and some calculated fields (e.g., explode) may change keys. Distinguish whether this is intended.
Use Data Exploration to check row count, unique values, and nulls to judge if keys have changed and if data volume is as expected. You can also use group aggregation, SQL, or filter data rows to validate data.
3. Use Precisely Storable Data Types as Keys
double and timestamp types may have errors in storage. To avoid errors or missing data (e.g., dirty data or match failures in joins/concatenations), convert them to string, int, or date, or use other fields. Ensure key types match exactly in joins/concatenations.
4. Use Functions Properly
1) Avoid Deeply Nested Functions
If SQL functions are deeply nested, especially window functions, computation complexity increases and may cause server resource issues. Split complex calculations into multiple nodes for easier validation.
Example: sum(case when [Area]='A' then [sales] else 0 end) over (partition by date_format([FILDATE],'yyyy-MM'))
Suggestion: In ETL, first create two fields: [YearMonth]: date_format([FILDATE],'yyyy-MM'), [Sales]: case when [Area]='A' then [sales] else 0 end; then sum([Sales]) over (partition by [YearMonth])
2) Set Partition for Window Functions Properly
Improper partition settings (e.g., partition by 1 or too many fields) can cause data skew and high CPU usage, leading to failures or server crashes. Prefer "group aggregation + self-join" instead.
3) Use collect_set, collect_list with Caution
Windowed deduplication: size(collect_set([A]) over(partition by [B])). collect_set generates lots of intermediate data and may cause disk/performance issues. For deduplication, use group aggregation + self-join. For string concatenation, control the number of rows per group (max 500,000), and reduce data volume.
4) Use Functions to Change Field Types
Do not change field types by selecting a different type in the dropdown or using mismatched functions. This only changes the display type, not the actual data type, and may cause errors in later calculations. Use appropriate database functions to convert types and ensure consistency.

Note: String functions like substr() are slow for date/timestamp fields. concat returns string, not suitable for date/time fields.
5. Combine Multiple Conditions and Filters in One Step
For example, create multiple calculated fields to check if a field contains a, b, c, then filter out data not containing these values.
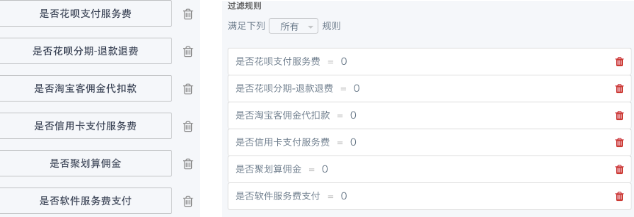
Suggestion:

6. Prefer Built-in Operators over SQL Operators
SQL operators in ETL scan the entire table and re-evaluate field types, which is resource-intensive. If there is dirty data in previous nodes, SQL nodes may not correctly determine field types. After modifying previous nodes, SQL nodes must be resubmitted to preview correct data. Previews may time out, and maintaining SQL logic is harder. Sorting in SQL is not supported in Guandata BI.
Suggestion: Use built-in operators whenever possible. Split logic into multiple nodes for clarity and easier validation/maintenance. Use SQL only when built-in operators cannot achieve the logic, and keep SQL simple. For example, for fuzzy matching between two datasets; also, control the number of SQL nodes in ETL.
SELECT input2.*,input1.`Customer ID`
from input2
left join input1 on array_contains(split(input2.`name_list`,','),input1.`Customer Short Name`)
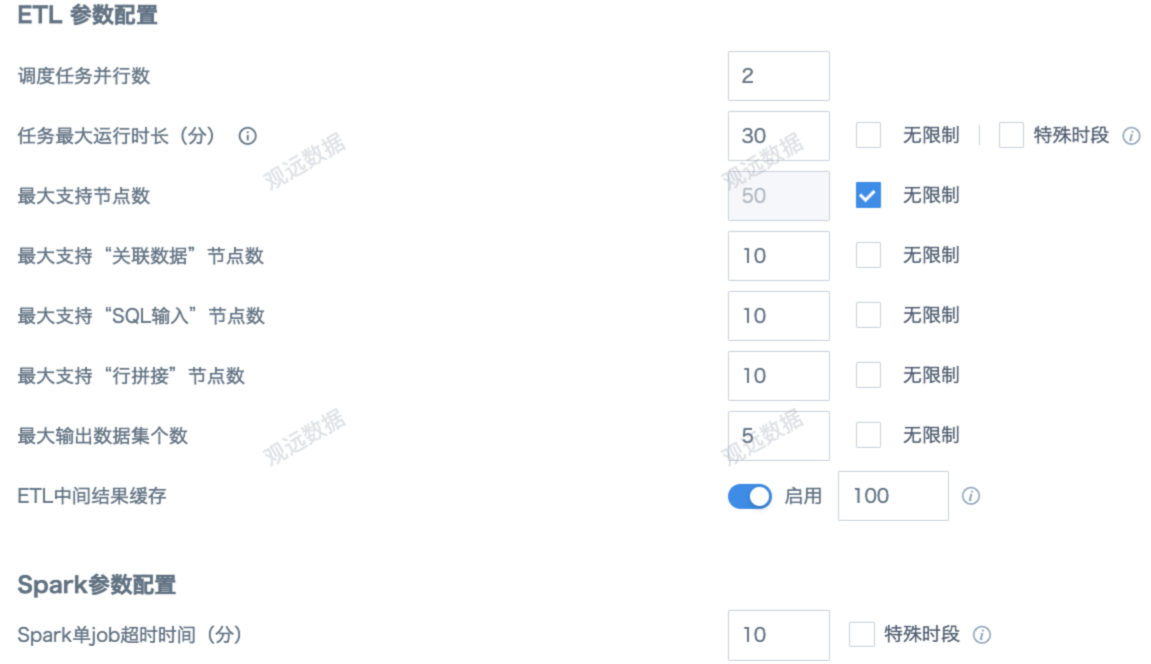
7. Use ETL Parameter Configuration Effectively
With many ETL developers, it's hard to ensure everyone follows the above optimizations. Admins can globally restrict ETL in Admin Settings > Operation & Maintenance Management > Parameter Configuration. For example, restrict join data, SQL input, and row concatenation nodes as they consume more resources.