Parsing JSON with ETL
Introduction to JSON
JSON is a subset of JavaScript, an open and lightweight data exchange format. It uses a text format independent of programming languages to store and represent data, making it easy for programmers to read and write, as well as for computers to parse and generate. It is commonly used for data transfer between web clients (browsers) and web servers. JSON is a pure <strong>string</strong> format and does not provide any methods (functions) itself, making it very suitable for network transmission. In JSON, data is represented in the following two ways:
-
Object: A collection of key/value pairs, defined using curly braces { }. Each key/value pair starts with a key, followed by a colon :, and then the value. Keys must be strings enclosed in double quotes " "; values can be any JSON-supported data type (such as string, number, object, array, boolean, null, etc.); multiple key/value pairs are separated by commas, e.g., {"name":"ABC","age":20};
-
Array: An ordered collection of values, defined using square brackets [ ], with values separated by commas.
Guandata BI Usage Scenarios
Web Services datasets (API data) and MongoDB datasets can automatically parse JSON; however, for datasets where only some fields are JSON or for complex nested JSON arrays, after extraction to the BI platform, they are displayed as string format and cannot be directly parsed. It is recommended to use Spark built-in functions in ETL for parsing. The following introduces the standard processing method using Spark SQL built-in functions.
JSON-related Functions in Spark
Category | Purpose | Function | Example | Result |
Conversion | Returns the data structure of a JSON string | schema_of_json(json[, options]) The function must use a direct JSON string, not a field reference | schema_of_json('[{"a": 1, "b": "abc"}, {"b": "d"}]') | ARRAY<STRUCT<a: BIGINT, b: STRING>> |
Converts a JSON string to a struct of the specified schema | from_json(jsonStr, schema[, options]) The schema must be provided directly, not as a field reference | from_json([jsonStr], 'ARRAY<STRUCT<a: BIGINT, b: STRING>>') [jsonStr] value: '[{"a": 1, "b": "abc"}, {"b": "d"}]' | [{"a": 1, "b": "abc"}, {"a": null, "b": "d"}] | |
Converts a struct to a JSON string | to_json(expr[, options]) | to_json([struct]) [struct]: [{"a": 1, "b": "abc"}, {"a": null, "b": "d"}] | [{"a": 1, "b": "abc"}, {"b": "d"}] | |
Query | Extracts the value corresponding to a key from a JSON string | get_json_object(jsonStr, path) | get_json_object ('{"a":"b"}', '$.a') | b |
json_tuple(jsonStr, key) | json_tuple('{"a":"b"}', 'a') | b | ||
Extracts the value corresponding to a key from a struct | . operator | [json_struct].a [json_struct]: {"a":"b"} | b | |
Returns the number of elements in a JSON array string (only the outermost array) | json_array_length(jsonArray) | json_array_length('[{"a": 1, "b": "abc"}, {"b": "d"}]') | 2 | |
Returns an array of all outermost keys in a JSON string | json_object_keys(json_object) | json_object_keys ('{"a":1,"b":2}') | [a, b] | |
Split | Splits an array into multiple rows | explode(expr) | explode([json_array]) [json_array]: [{"a": 1, "b": "abc"}, {"a": null, "b": "d"}] | {"a": 1, "b": "abc"} |
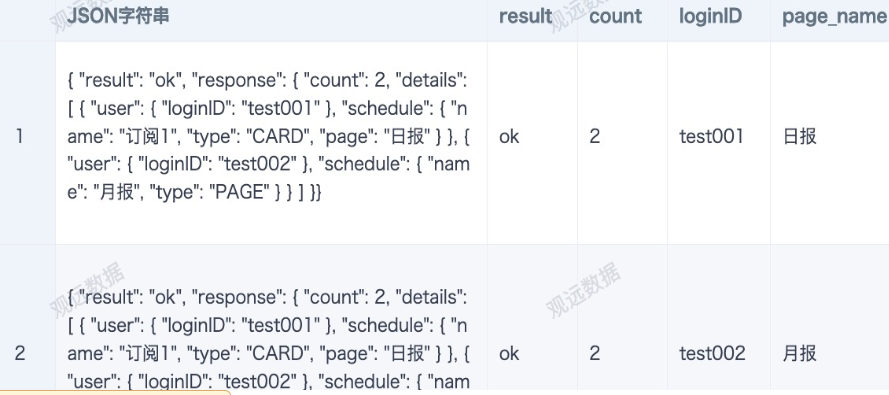
Example: Multi-level Nested JSON Fields with JSON Arrays
Goal: Extract the values of result, count, loginID in user, and page_name in schedule. The logic for page_name: if "type" is "PAGE", take the value of "name"; if "type" is "CARD", take the value of "page".
{
"result": "ok",
"response": {
"count": 2,
"details": [
{
"user": {
"loginID": "test001"
},
"schedule": {
"name": "Subscription 1",
"type": "CARD",
"page": "Daily Report"
}
},
{
"user": {
"loginID": "test002"
},
"schedule": {
"name": "Monthly Report",
"type": "PAGE"
}
}
]
}
}
1. First, extract directly accessible fields
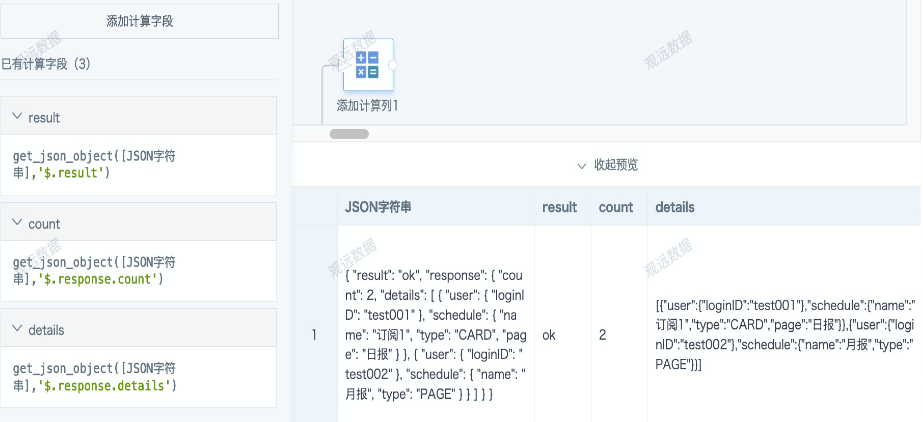
In the JSON string, objects inside {} (including nested objects) can be directly extracted using the get_json_object function, such as result and count; objects inside arrays [] cannot be directly extracted, so the entire array corresponding to details should be extracted first. The formulas and preview results are as follows.
get_json_object([JSON string],'$.result')
get_json_object([JSON string],'$.response.count')
get_json_object([JSON string],'$.response.details')
2. Convert the JSON array string back to a struct (or array) format
Since the [] and its contents in the data source are actually stored as text strings, not as real arrays, the format must be converted before they can be correctly split. Here are two ways to convert the format:
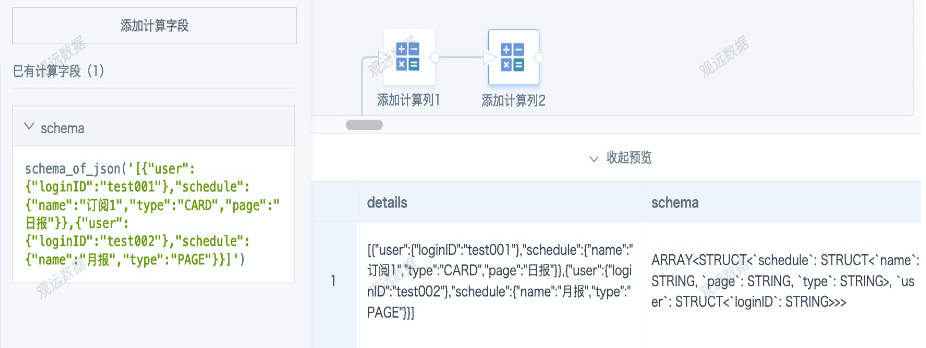
A. Determine the schema of the JSON string and convert it to a struct format
from_json([details], schema_of_json('[{"user":{"loginID":"test001"},"schedule":{"name":"Subscription 1","type":"CARD","page":"Daily Report"}},{"user":{"loginID":"test002"},"schedule":{"name":"Monthly Report","type":"PAGE"}}]')) --schema_of_json should use a complete row of data as an example, not a field reference.
from_json([details], 'ARRAY<STRUCT<schedule: STRUCT<name: STRING, page: STRING, type: STRING>, user: STRUCT<loginID: STRING>>>') -- The schema comes from the result of schema_of_json. Experienced users can input the schema manually; except for key names, backticks ` can be omitted, and case is not sensitive.
Schema preview result:
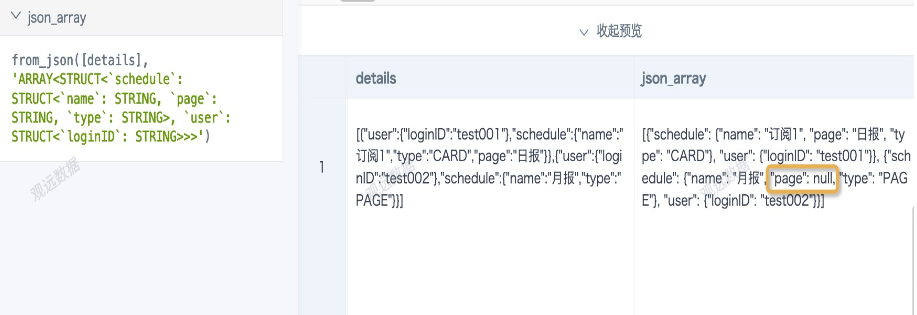
from_json preview effect:
Notes:
-
JSON data is unstructured, and there may be cases where elements in the array contain different fields. For example, in the above example, the schedule part contains name, type, and page in one object, and only name and type in another. After schema conversion, missing fields will be filled with null, and the order of JSON objects may change (which does not affect subsequent data parsing).
-
Choosing different JSON objects for parsing will result in different schemas and processing results. For example, for the "details" field, if processed as "array<struct<user: struct>>", only loginID-related data will be retained.
[
{
"user": {
"loginID": "test001"
},
"schedule": {
"name": "Subscription 1",
"type": "CARD",
"page": "Daily Report"
}
},
{
"user": {
"loginID": "test002"
},
"schedule": {
"name": "Monthly Report",
"type": "PAGE"
}
}
]
[
{
"user": {
"loginID": "test001"
}
},
{
"user": {
"loginID": "test002"
}
}
]
B. Use string functions to convert the JSON string to a string array
split(replace(translate([details],'[]',''),',{','~{'),'~')
-- translate: remove square brackets []
-- replace: replace ',{' with '~{' to use ~ as a separator for the outermost JSON objects
-- split: split the string by ~, returning an array

Difference between the two methods: from_json returns a struct or struct array, which may add, delete, or modify the original data values. After splitting, use struct-related functions to parse; split returns a string array, does not modify the original data values, and after splitting, use text functions to process. Note: If there are multiple levels of nested arrays (i.e., [] within []), the second method may destroy the original hierarchy. It is recommended to use the first method.
3. Use explode to split the array into multiple rows
explode([json_array])

4. Extract the value corresponding to a key from JSON
A. For structs obtained by from_json, use the struct access method, i.e., the . operator, struct.wanted_key, to get the key-value result from the previous result.
[explode].schedule.name
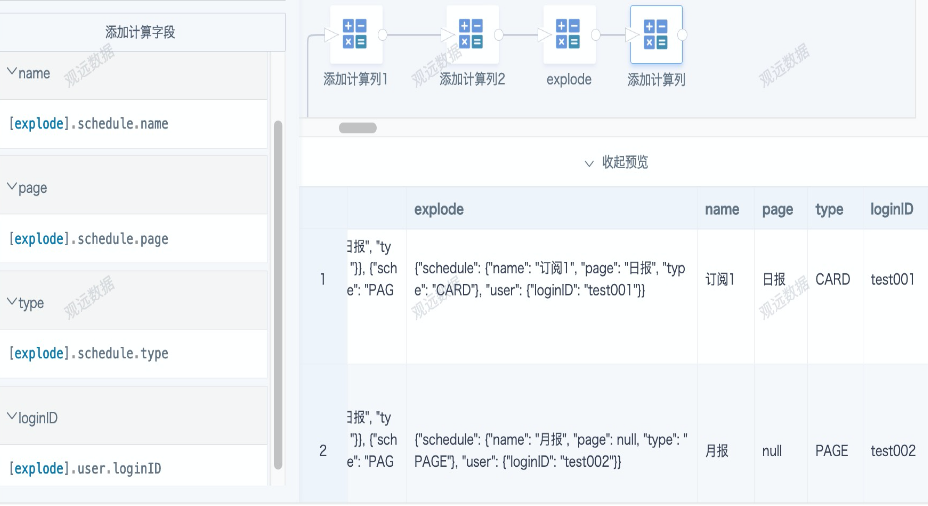
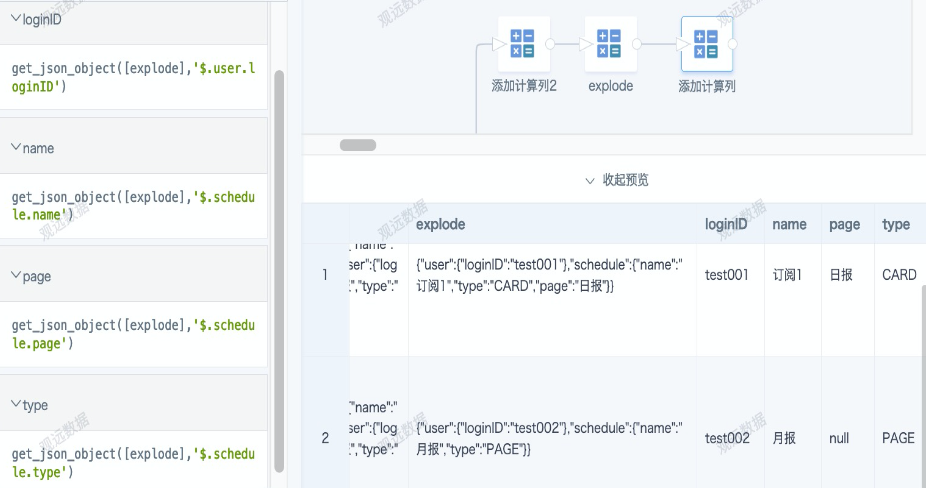
B. For JSON strings (including those obtained from split), use get_json_object for parsing (same as step 1). The parsing result is the same as the struct method.
get_json_object([explode],'$.user.loginID')
5. Create a calculated field and use case when logic to get page_name
case when [type]='PAGE' then [name]
when [type]='CARD' then [page]
end
-- If "type" is "PAGE", take the value of "name"; if "type" is "CARD", take the value of "page".
The final output is as shown below.