Append Rows
Overview
Feature Description
Business data of the same type may come from different subsidiaries, stores, or even different data sources within the same organization. For example, a supermarket may support multiple payment methods such as cash, UnionPay, and mobile payment, which results in many source datasets at the downstream end. Append Rows can combine these different sources of the same business data into one dataset.
Use Cases
Sales transaction records from multiple stores or online platforms can be merged into one unified nationwide sales table.
User Guide
In practice, you can first use the Select Columns operator in column editing to standardize a batch of data and keep that result as the standardized reference dataset. Other datasets from the same business domain can then be combined with the Append Rows operator to produce a more standardized and comprehensive dataset.
Example:
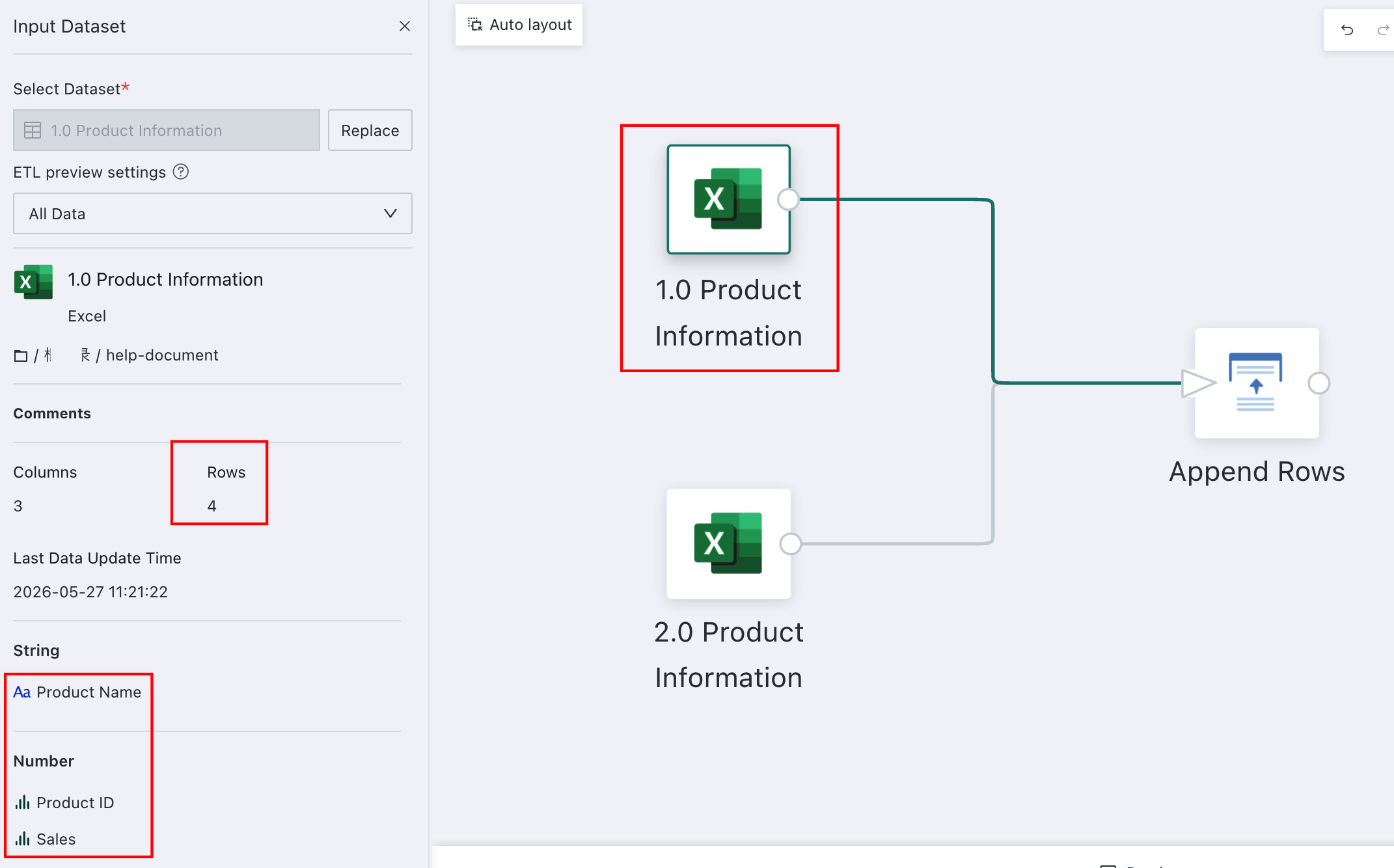
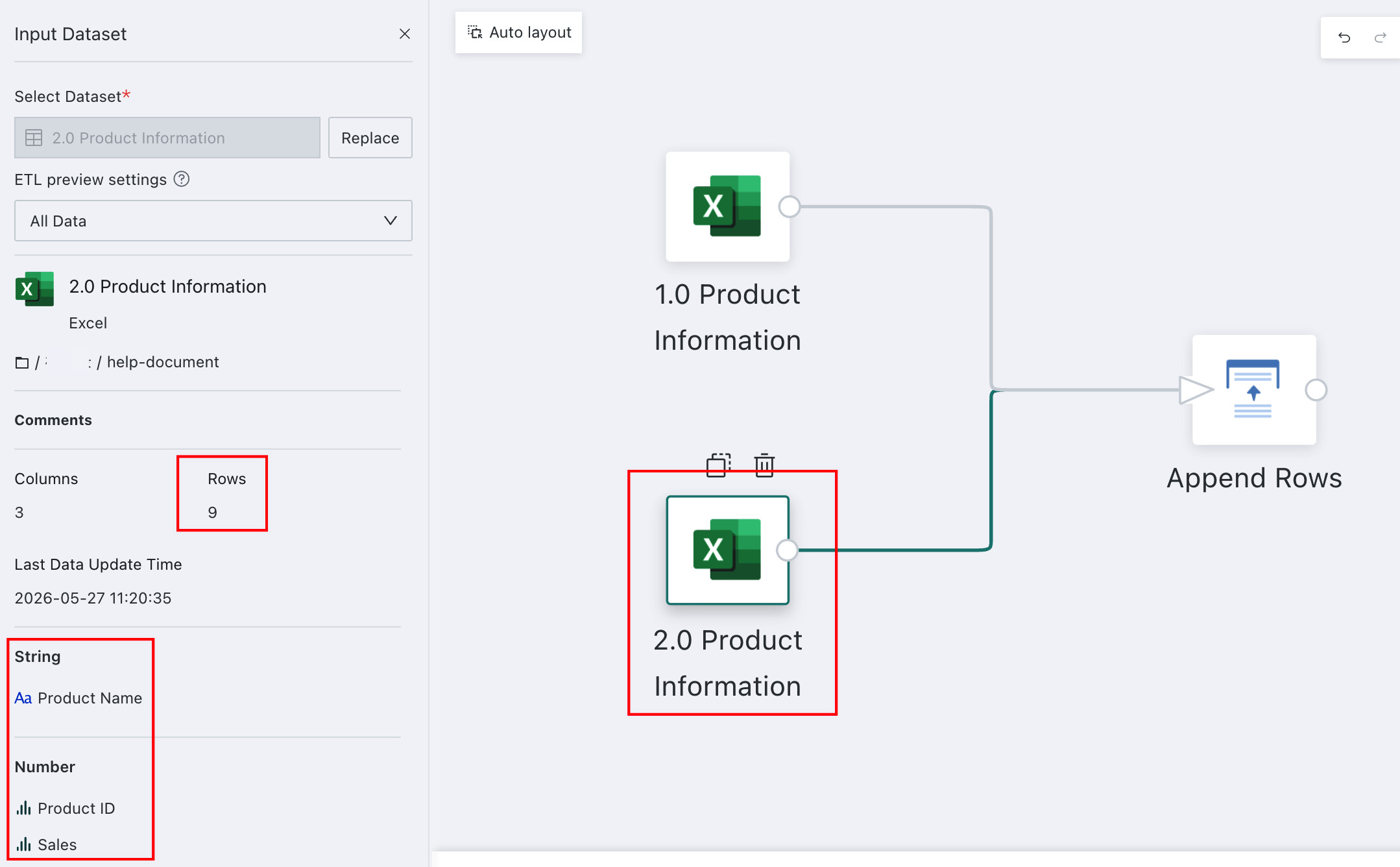
As shown above, the two datasets come from different sources but have exactly the same fields.
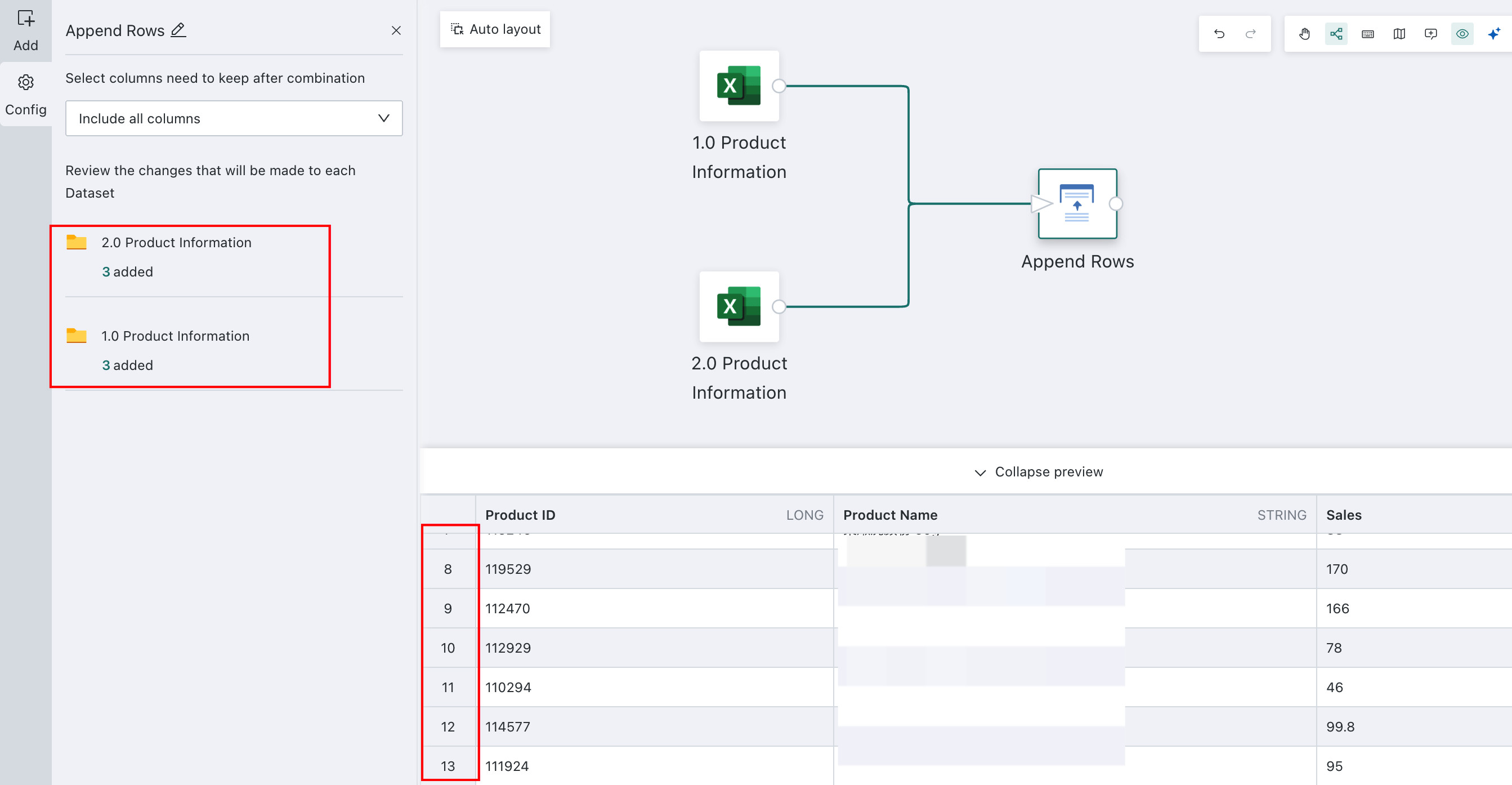
When appending rows, you can choose which columns to retain, such as keeping all columns, only common columns, or all columns from any selected dataset.
After the append result is generated, you can click the number under a specific dataset in the upper-left area to view which fields are retained for that dataset.
Node Count Configuration
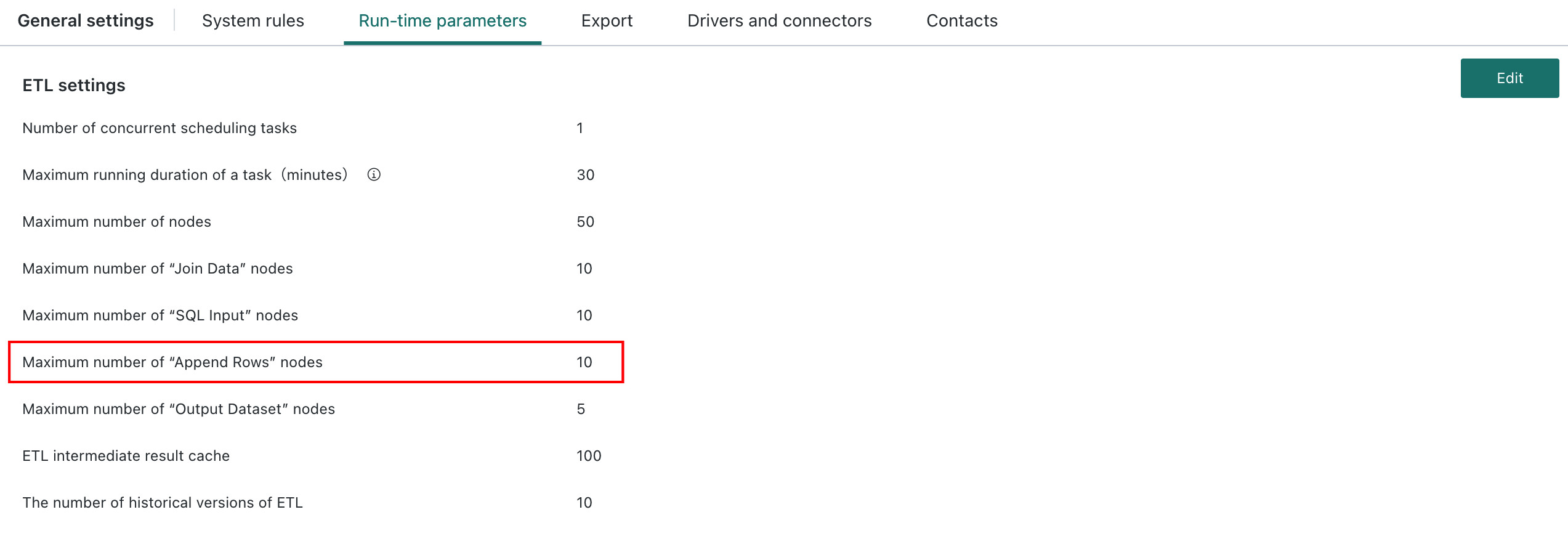
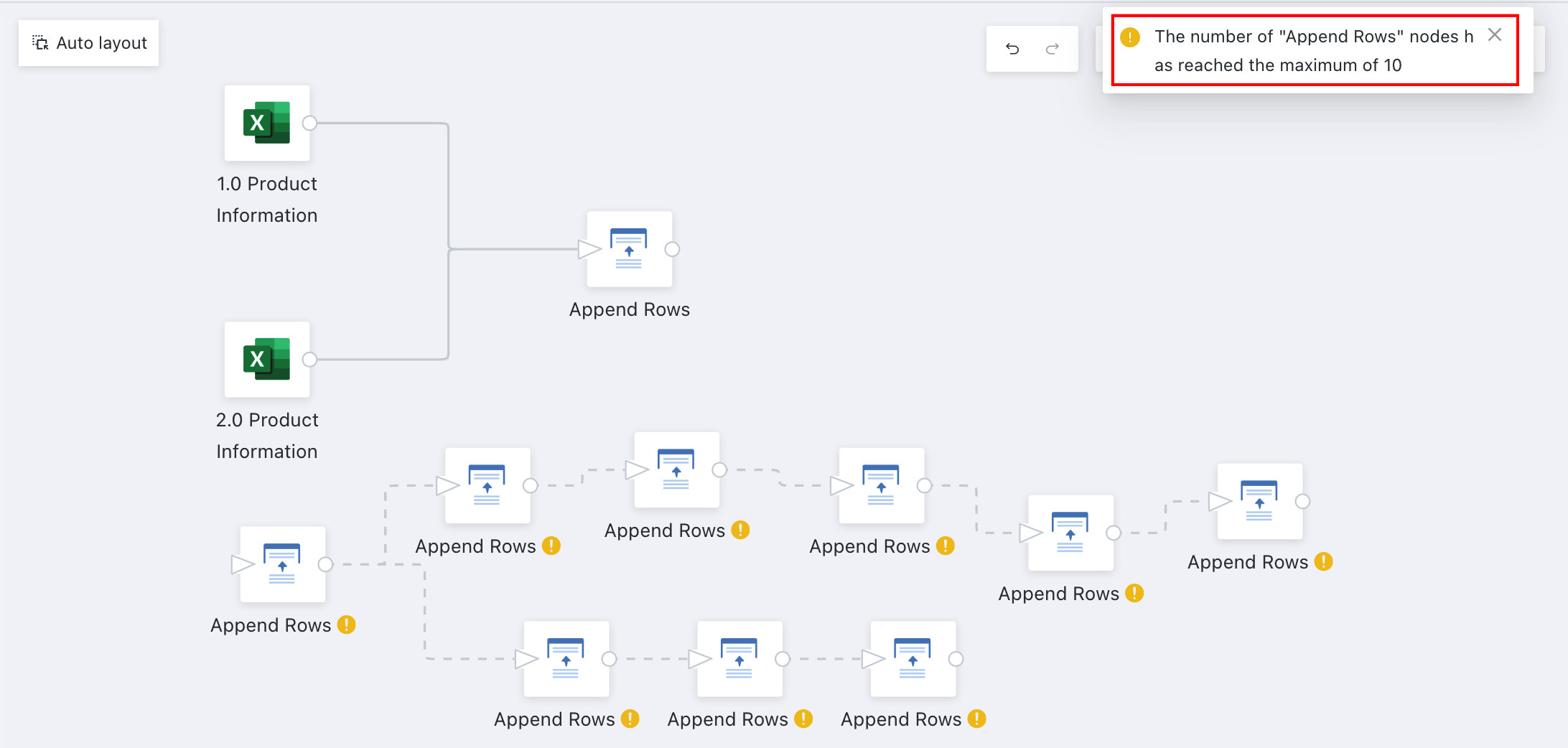
During ETL creation, the platform provides a node count configuration for Append Rows. Standardizing ETL creation helps avoid system runtime issues caused by improper operations.
How to configure: Go to Admin Center > System Settings > General Settings > Runtime Parameters, click Edit in the upper-right corner, and configure ETL Parameter Configuration > Maximum Supported "Append Rows" Node Count. The configurable range is 1-50. For new customers, the default is 10; for existing customers, the default is unlimited. If the limit is exceeded during creation, the system displays a prompt.
For other data processing operators used later, see Getting Started.