DB数据流
概述
数据流中的 ETL 算子运行时一般使用 spark 算力,新增 DB 数据流节点,运行 DB 数据流会将 ETL 计算逻辑转化为数据库支持的 SQL 语言,下推到数据库运用数仓算力计算。
支持的数仓
StarRocks、GuassDB、Doris、SelectDB、Mysql、Postgresql 等数据库。
操作步骤
操作入口
直接拖入 DB 数据流或者将普通数据流转化为 DB 数据流
-
直接拖入 DB 数据流
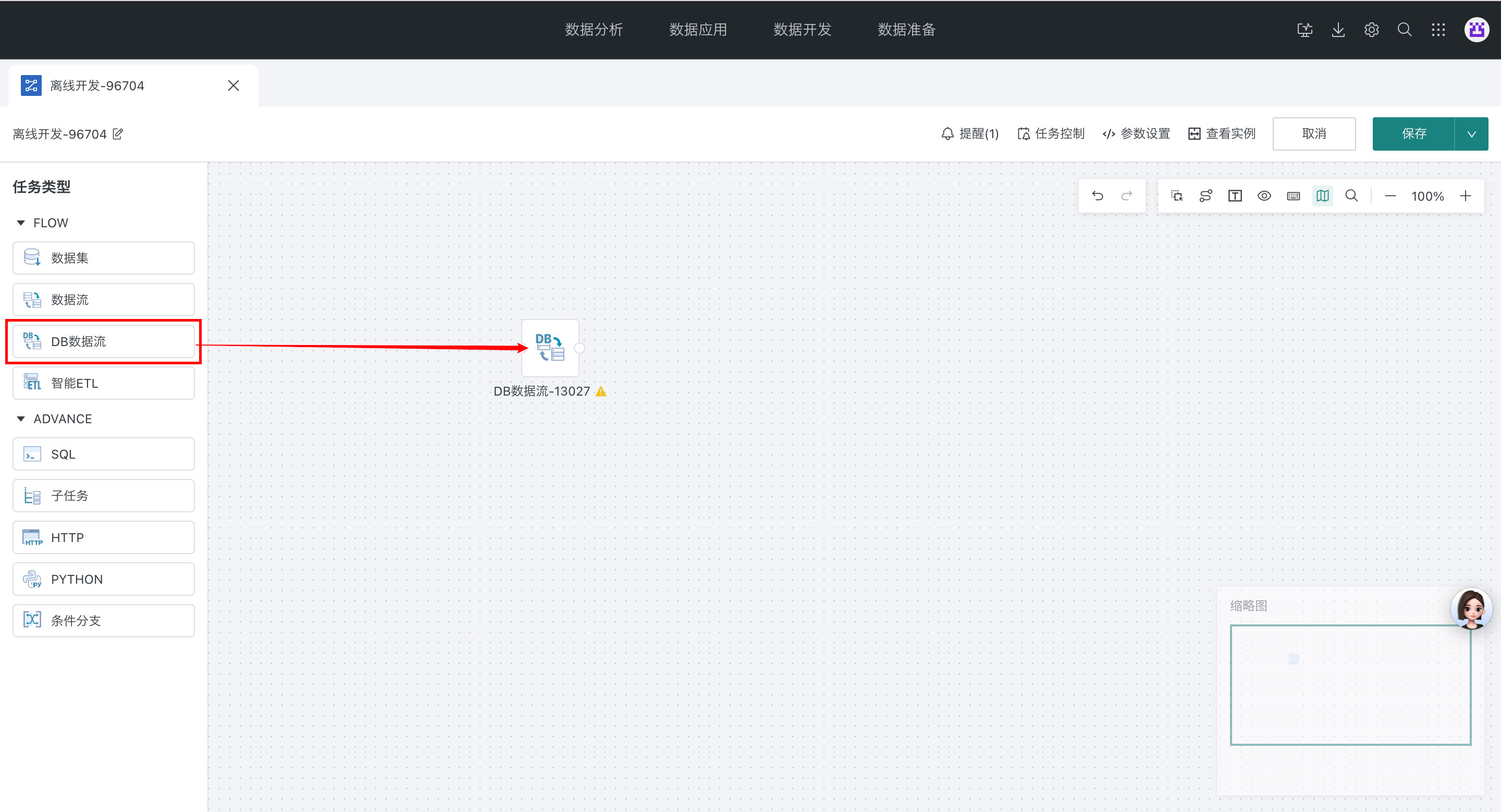
-
普通数据流转 DB 数据流
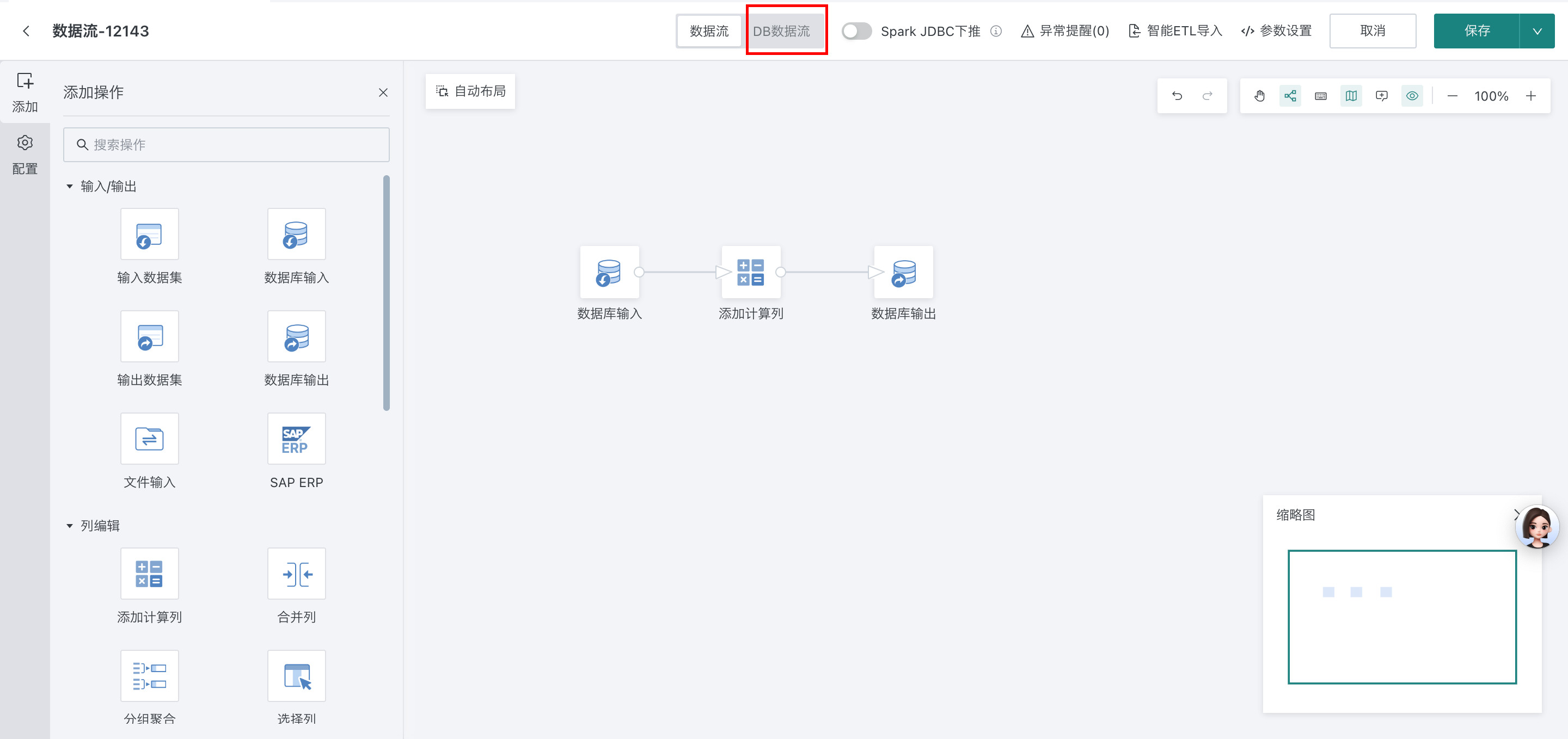
DB 数据流中完成数据开发
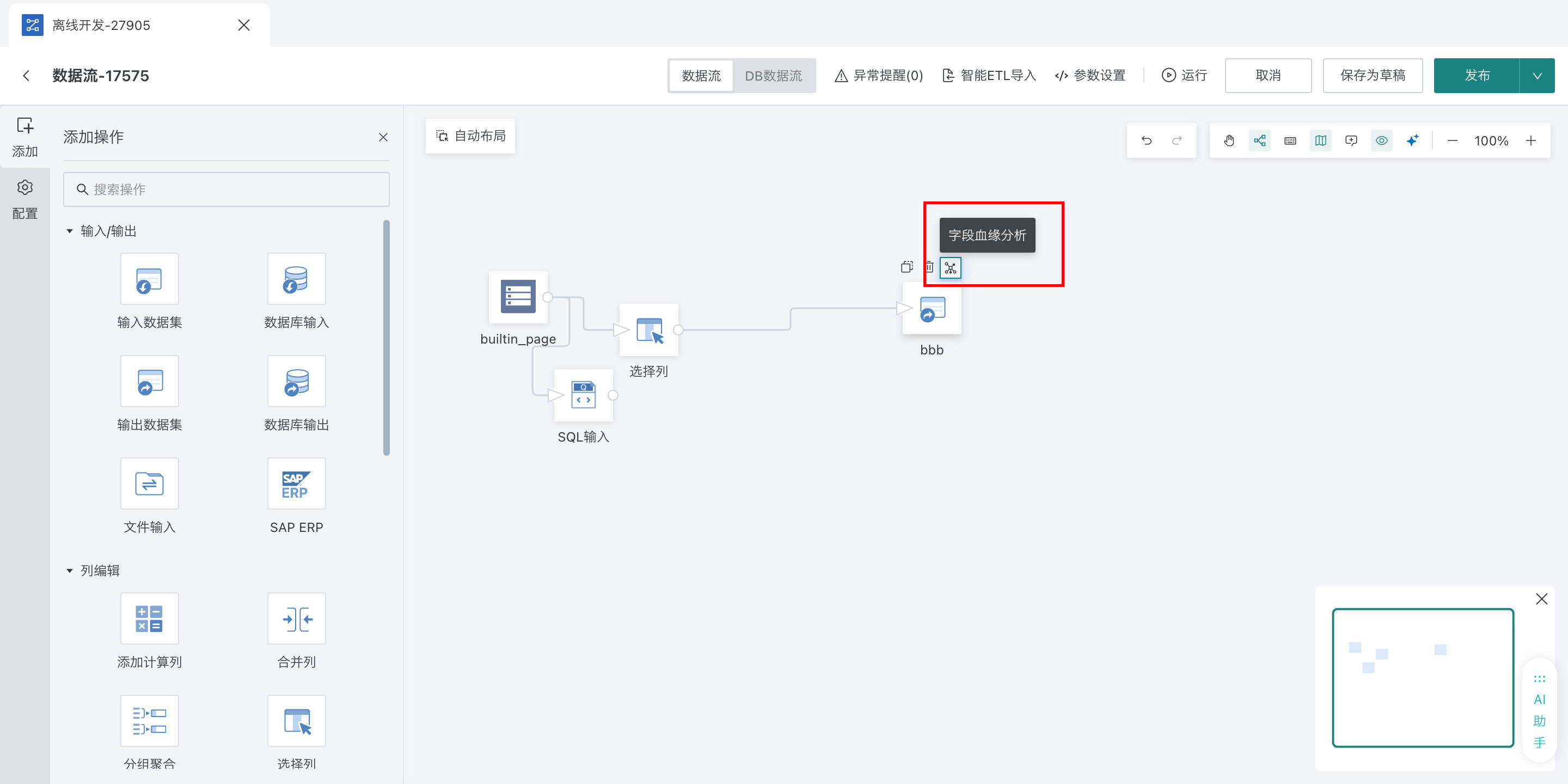
每个ETL算子上点击血缘icon,选择分析的字段,即可追溯这个字段的上游算子。
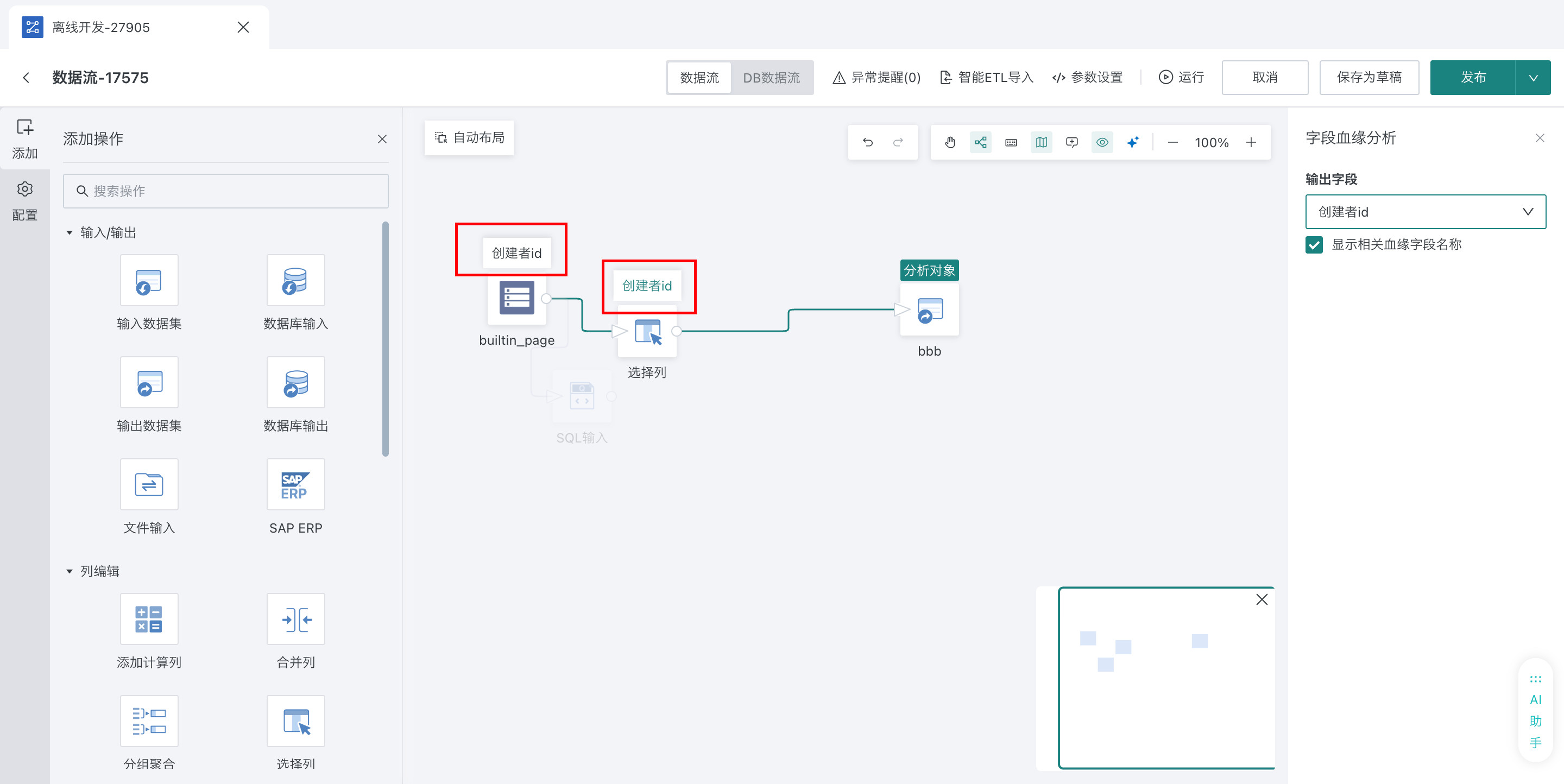
DB 数据流节点包括以下具体算子,请按需参阅具体文档。
为确保任务能正常下推至数据库运行,DB 数据流中的数据来源仅支持数据库类型,且数据库输入和数据库输出节点只能配置相同的数据账户,数据集、文件、ERP 等数据源请在普通数据流中进行配置。
在 DB 数据流编辑 SQL 语句时,请使用符合数据库语法的函数和语句,不要使用 Spark 函数和语句(下推时运行失败)。
输入/输出
| 算子 | 说明文档 |
|---|---|
| 数据库输入 | 数据库输入 |
| 数据库输出 | 数据库输出 |
列编辑算子
| 算子 | 说明文档 |
|---|---|
| 添加计算列 | 添加计算列 |
| 合并列 | 合并列 |
| 分组聚合 | 分组聚合 |
| 选择列 | 选择列 |
| 行转列 | 行转列 |
| 列转行 | 列转行 |
数据编辑算子
| 算子 | 说明文档 |
|---|---|
| 筛选数据行 | 筛选数据行 |
| 去重 | 去重 |
| 值替换 | 值替换 |
| Null 值替换 | Null值替换 |
数据集组合
| 算子 | 说明文档 |
|---|---|
| 行拼接 | 行拼接 |
| 关联数据 | 关联数据 |
高级计算
SQL 算子:SQL算子
DB 数据流计算逻辑切分
使用场景
当 DB 数据流处理逻辑较为复杂时,在未开启 ETL 切分的情况下,会将 DB 数据流解析为一段复杂 SQL 直接推到数据库,SQL 过于复杂时数据库很可能运行不动。
具体操作
这种情况建议开启 ETL 切分配置,系统会将 DB 数据流中的逻辑自动切分为多条 SQL,推到数据库运行,确保任务的顺利运行。
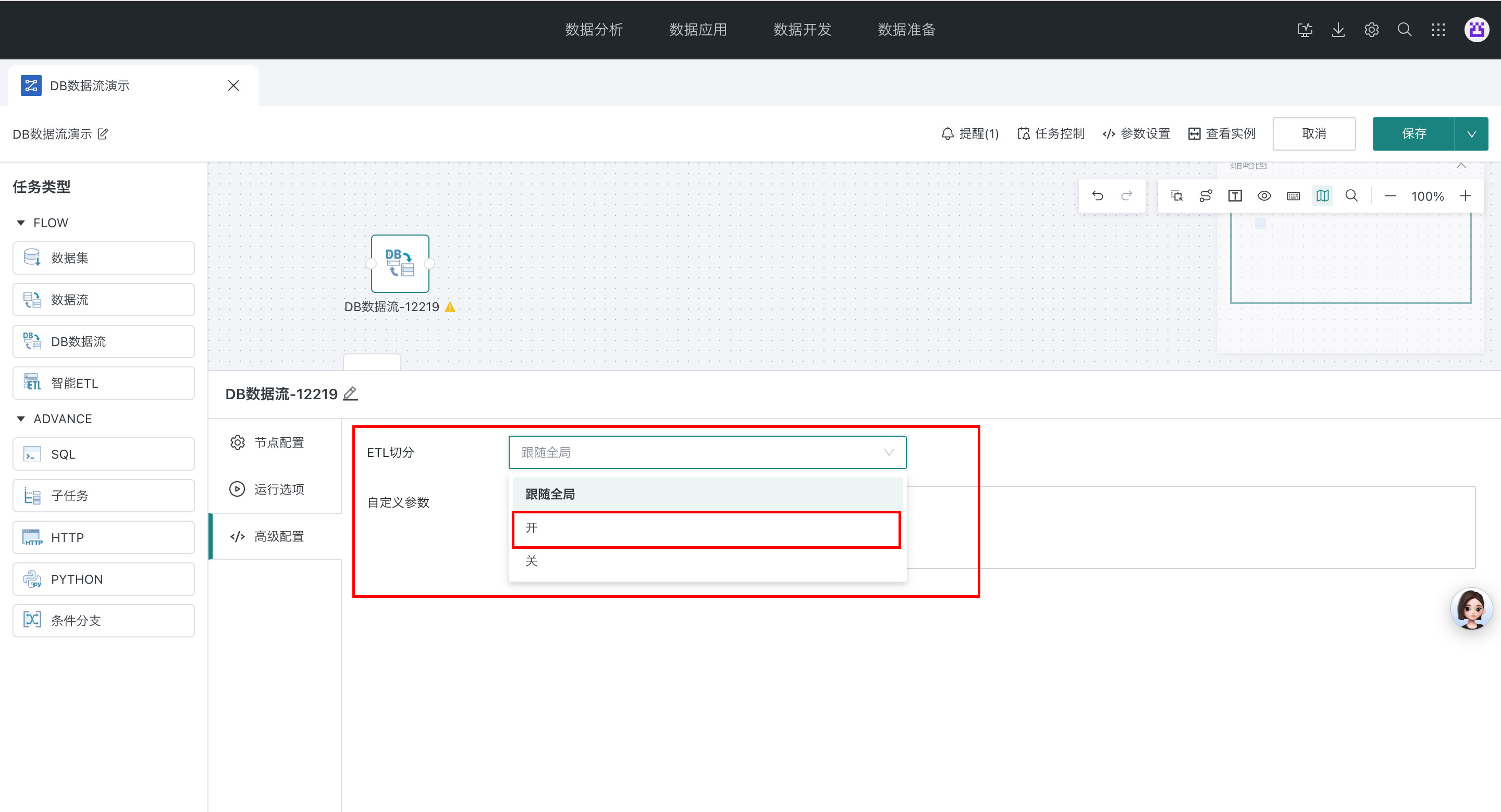
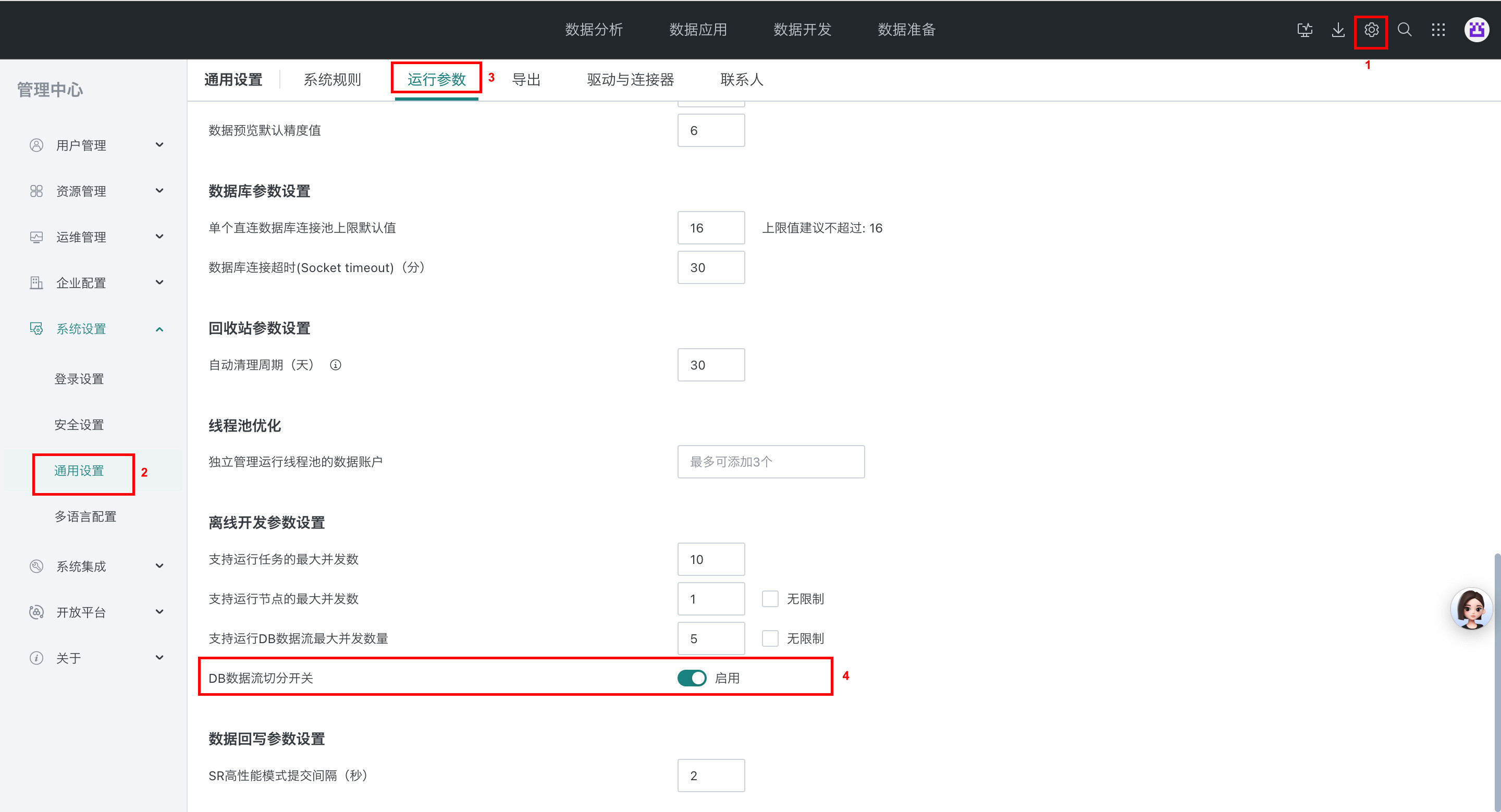
ETL 切分在管理中心可进行全局配置:
高阶操作
手动配置切分点
适用场景
对于一些复杂的 DB 数据流或者处理较大数据量的情况,运行时数据库内存溢出,导致任务报错。
解决方案
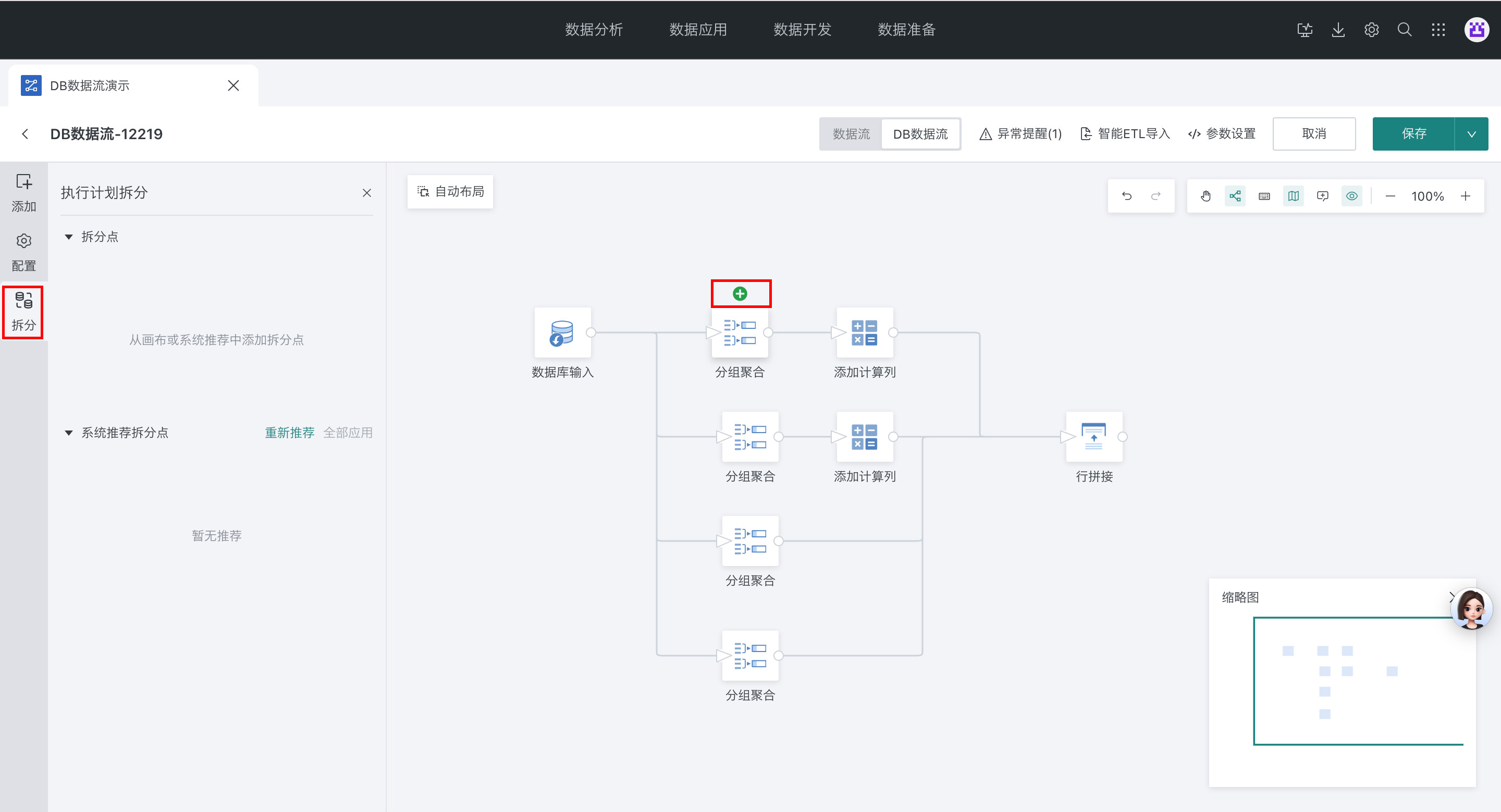
支持用户手动配置切分点,根据切分点分段解析 sql,避免复杂 sql 或者大数据量情况导致运行报错
操作步骤
- 编辑 DB 数据流 -> 拆分 -> 选择节点点击 + 号作为拆分节点
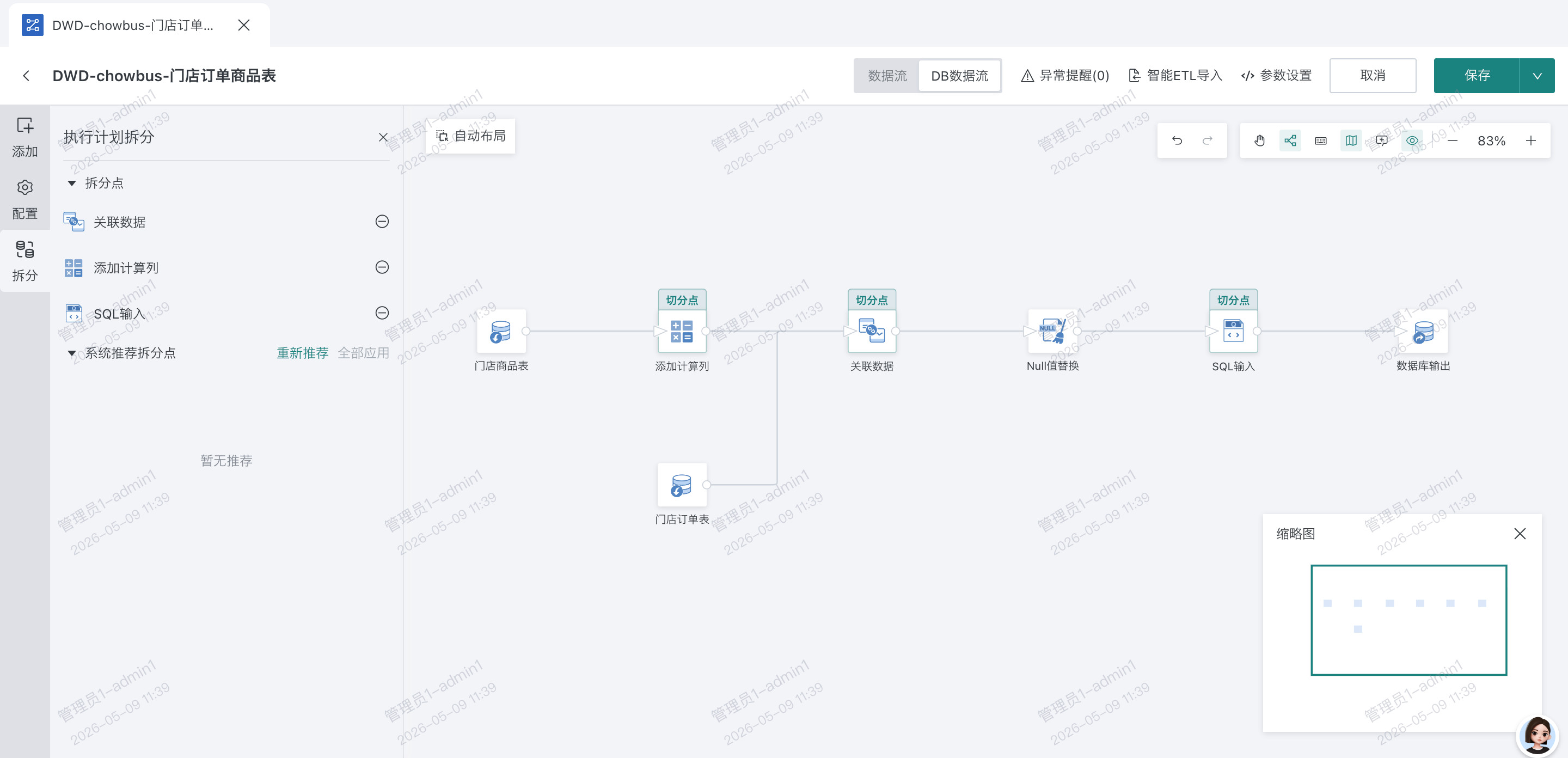
- 运行 DB 数据流,查看实例,进入 DB 数据流,可以看到每个切分点生成的 sql,以及提交到数据库运行的状态和报错
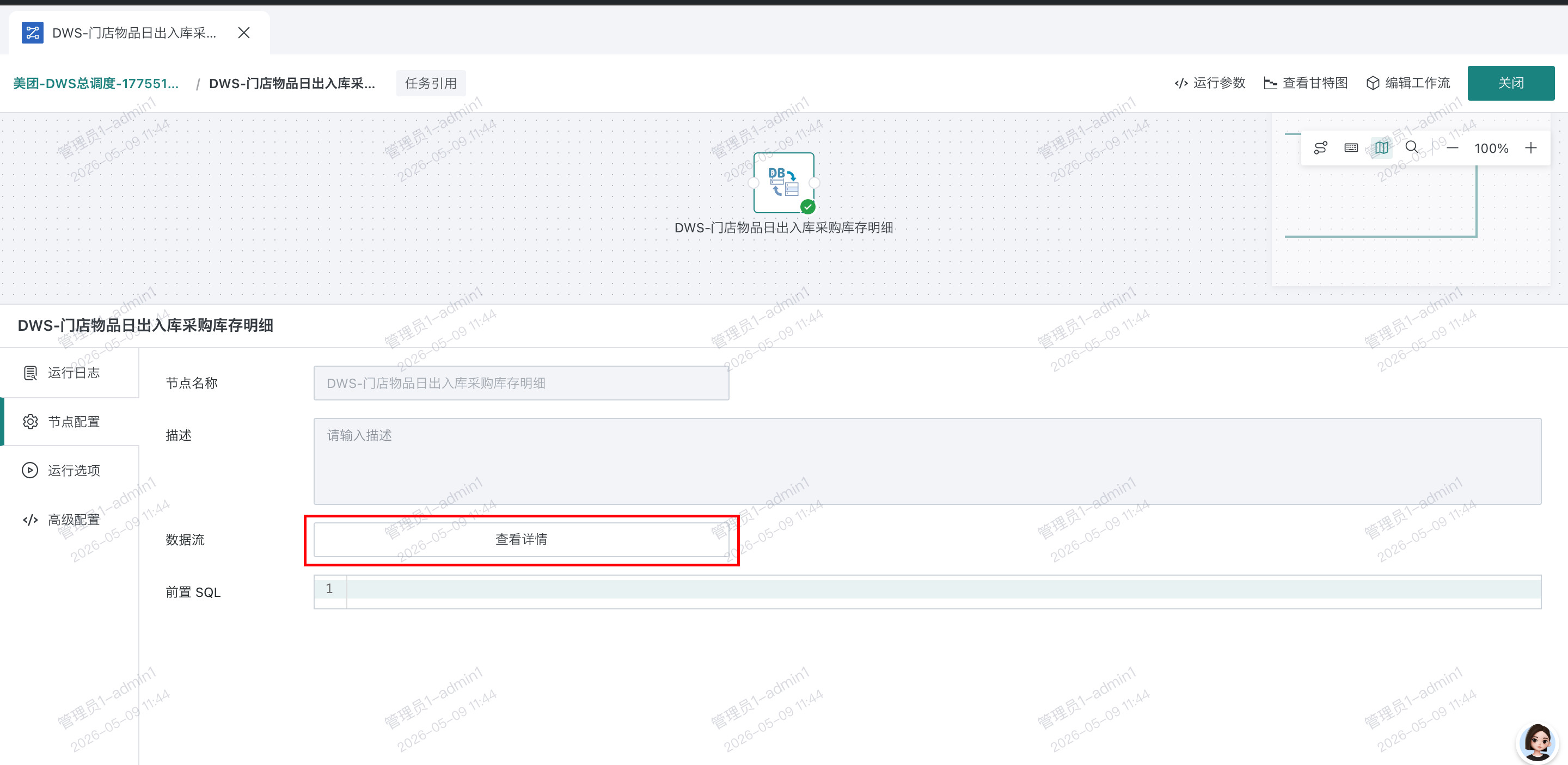
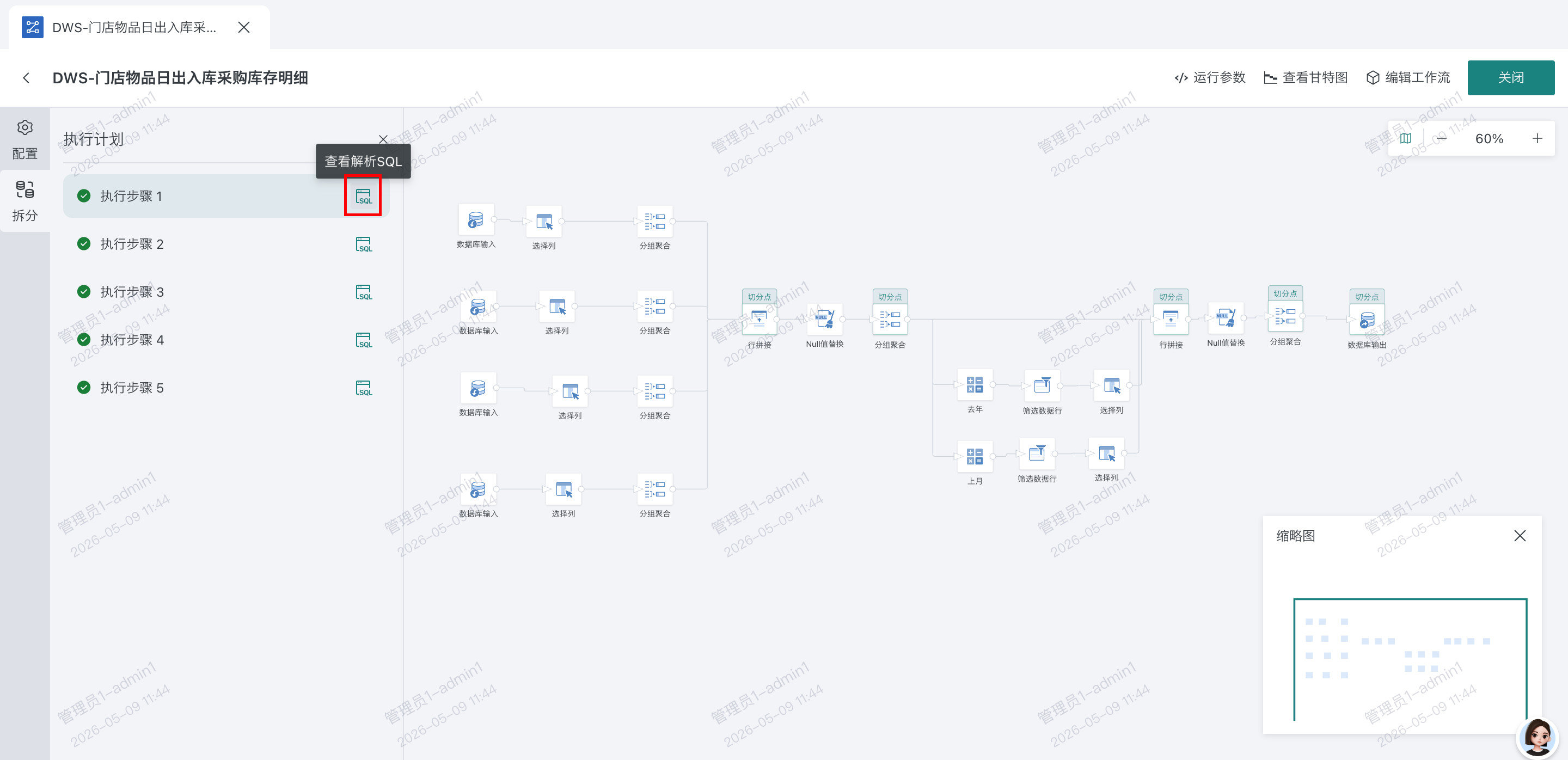

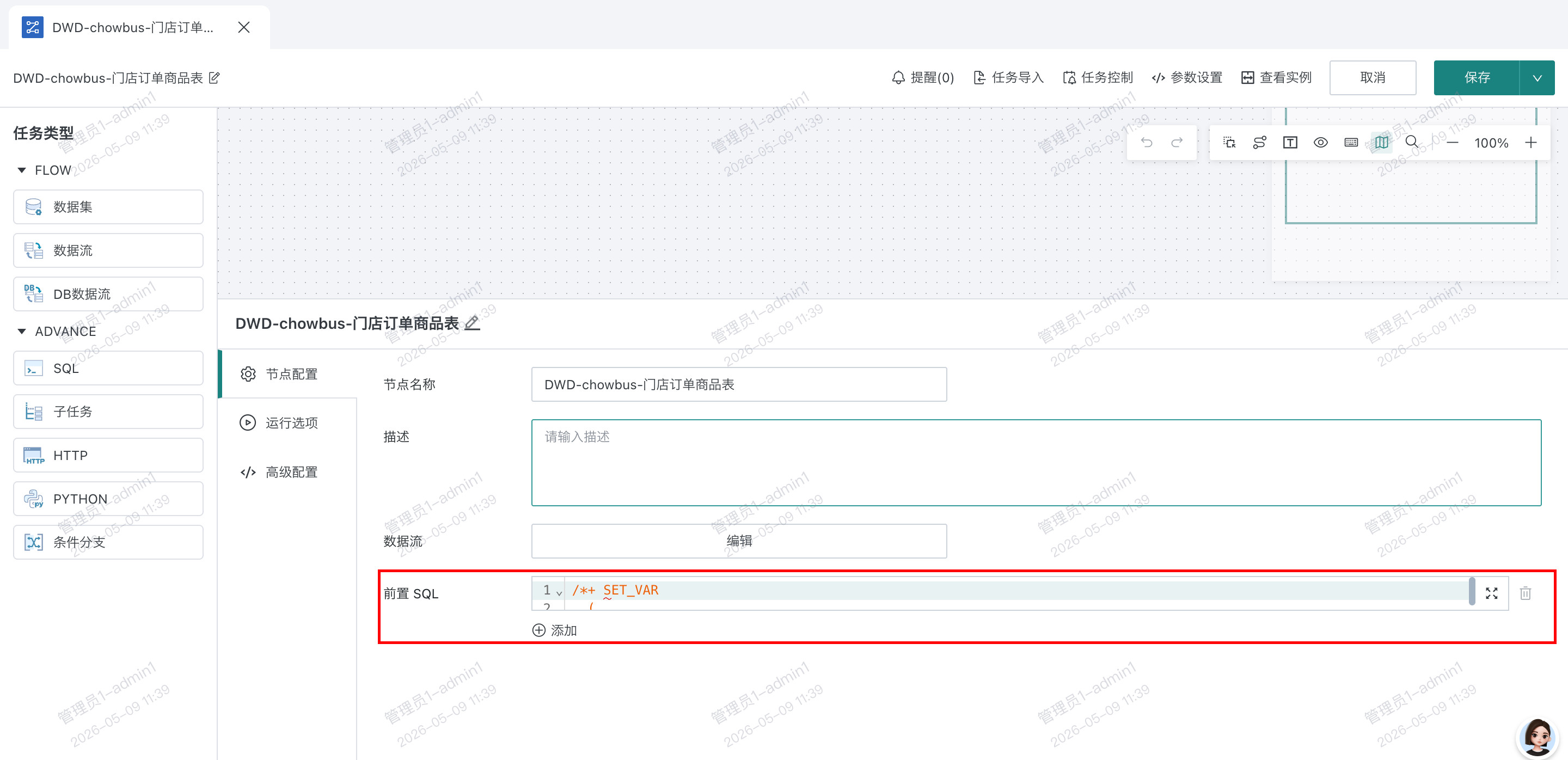
前置 sql
适应场景
某一个关联节点或者分组聚合节点处理数据量过高,即使将此节点单独拆分解析也会导致数据库内存溢出。
解决方案
在 DB 数据流节点配置前置 sql,限制并发数或者强制落盘,减少内存的使用。
操作步骤
DB 数据流 ->前置 sql->配置 sql 运行的 set 参数,可联系 DBA 提供建议。