如何搭建一个高质量数据集智能体
数据集智能体(原主题)目标与适用范围
数据集智能体(原主题)核心目的
构建数据集智能体(原主题)的核心目的,是为普通业务用户,提供一个能够用自然语言提问,系统自动结合某一个业务领域的业务知识;行业黑话后,查询业务数据,最终获得精确数据答案的空间。
结合实际情况,考虑到企业中的业务往往交错复杂,为了更加准确的回答业务数据,避免各业务间的数据、知识、黑话互相干扰、冲突,所以需要从业务的角度,对业务类型进行划分,根据不同的业务类型构建不同的数据集智能体(原主题)。
适用的用户画像
数据集智能体(原主题)管理员
建议是某个业务的小组长、数据分析师、业务专家。
数据集智能体(原主题)管理员需要理解数据集智能体(原主题)相关数据,以及从中可以获得洞察。以零售行业为例,业务数据通常非常复杂,包括商品信息、库存管理、客户购买行为等多种维度,以及总销售额、客单价、退货率等多个指标。因此,我们建议由熟悉零售业务流程且具备 SQL 数据分析能力的用户,定义 ChatBI 数据集智能体(原主题)的核心结构。
数据集智能体(原主题)管理员的首要责任是,能够有效得将业务中,特有的上下文背景、指标计算逻辑、公司行业黑话,翻译成 ChatBI 能够理解的业务知识,帮助 ChatBI 准确回答用户提出的关于销售、库存、客户行为等业务问题。
普通用户
有灵活、机动的数据分析诉求,聚焦于某一个业务领域的普通用户。
适用的业务范围
聚焦,聚焦,再聚焦!在启动首个 ChatBI 数据集智能体(原主题)时,明确数据集智能体(原主题)的目的和目标受众至关重要。
例如,如果零售公司决定将 ChatBI 数据集智能体(原主题)的重点放在销售绩效上,目标用户是公司销售部门的经理,那么就应该专注于分析销售趋势和库存变化,避免涉及跨领域的其他问题,如财务报表分析、库存分析等等。
数据集智能体(原主题)的配置要求
创建 ChatBI 数据集智能体(原主题)时,建议先从一些基础的数据、问题开始,然后根据用户需求逐步扩展。
例如,零售公司可以先关心一些核心的销售问题,如“某个时间段的总销售额”或“某品类的销量”。如果您已经是观远 BI 的资深用户,可以结合这个数据集智能体(原主题)相关的 BI 看板,整理客户常用的业务问题。这些查询简单直接,有助于公司快速测试 ChatBI 的效果,并根据反馈不断扩展问题集。
下表为配置数据集智能体(原主题)的核心规则,本文也将对每个类目展开详细的说明与解释,以及一些最佳实践和原则,帮助您更好的开发数据集智能体(原主题)。
数据集智能体(原主题)配置规则
为了更好的获得智能问数效果与体验,请确保您的配置符合以下规则要求。
| 类目 | 配置项 | 规则说明 |
|---|---|---|
| 基础配置 | 数据集智能体(原主题)名称 | 30 个字符以内 |
| 数据集智能体(原主题)描述 | 无限制 | |
| 关联数据集 |
1. 数据已处理为 ADS 层宽表(可用于业务自助取数)。 2. 避免数仓层表达作为字段名称,例如 ods_sales。请维护成具备业务含义的字段名,例如:销售金额。3. 如果字段名为缩写、业务常用语等特殊表达,请在字段注释中维护相应的业务含义。 4. 避免字段与字段间的歧义或近义,例如,同一张表或多张表中都有字段叫"日期",但日期的含义分别为订单日期和入库日期。 5. 单个数据集智能体(原主题)中,所有的数据表字段总数不超过 300 个,否则准确率会降低(表数量无限制,建议不超过 5 张表)。 6. 建议首个数据集智能体(原主题)的创建和测试,尽量先基于单表。在单表问答准确率达到 80% 后,再扩展其他表进行问答。 |
|
| 权限管理 | 权限配置 |
无限制(注意:权限管理配置对管理员不生效,即管理员能在前后台看到所有数据集智能体(原主题),并对其进行操作)。用户可通过角色配置 ChatBI 权限: - 查看权限:控制是否能查看 ChatBI 问答入口。 - 编辑权限:控制是否能查看 Data Agent管理功能入口。 - 授权权限:控制是否能查看 ChatBI 数据集智能体(原主题)中权限管理模块。 |
| 样例集(原错题集) | 样例集(原错题集) |
无限制。添加业务问题 + 查询 SQL 对,例如之前有取数工单、取数模版等资料,可以添加成为该知识,供大模型举一反三。后续如果发现提问返回的 SQL 回答错误,也可以把问题 + 正确 SQL 加入到样例集(原错题集),起到学习作用。 注意:针对动态时间的表述计算需要用时间函数,如昨天、近 7 天、上个自然周,不要使用写死的时间日期。针对复杂/容易搭错的指标计算,除了业务知识中补充指标计算逻辑,还可增加样例集(原错题集)提升问答稳定性。 |
| 知识库 | 通用知识 | 无限制。每次对话都需要应用到的通用知识。 |
| 业务知识 | 无限制。可以配置"行业术语""业务常用语""指标口径定义"等,以文字版形式给到大模型学习。 | |
| 问数测试 | 准确率要求 | 建议数据集智能体(原主题)测试准确率 90% 及以上后再投入生产。 |
| 其他 | 数据集智能体(原主题)规划 | 配置数据集智能体(原主题)时,一个问数场景配置一个数据集智能体(原主题)。如果多场景(交叉场景等)配置在同一个数据集智能体(原主题)中,会导致数据集过多、业务知识冗余、数据查询分析效果差。 |
| 提问规范 | 提问使用时,一个问题中尽量避免同时包含多个意图,否则会导致意图识别、数据查询分析效果不理想。 错误示例:2024 年利润最高的 TOP10 的产品是哪些?年同比涨幅最大的是哪个?这些产品的利润、销售额分别是多少? |
数据集要求与配置
为什么需要数据集
ChatBI 的核心功能是为普通用户提供数据问答服务,所以需要添加数据来源,以方便系统进行数据查询。
如何添加数据集
步骤和时机
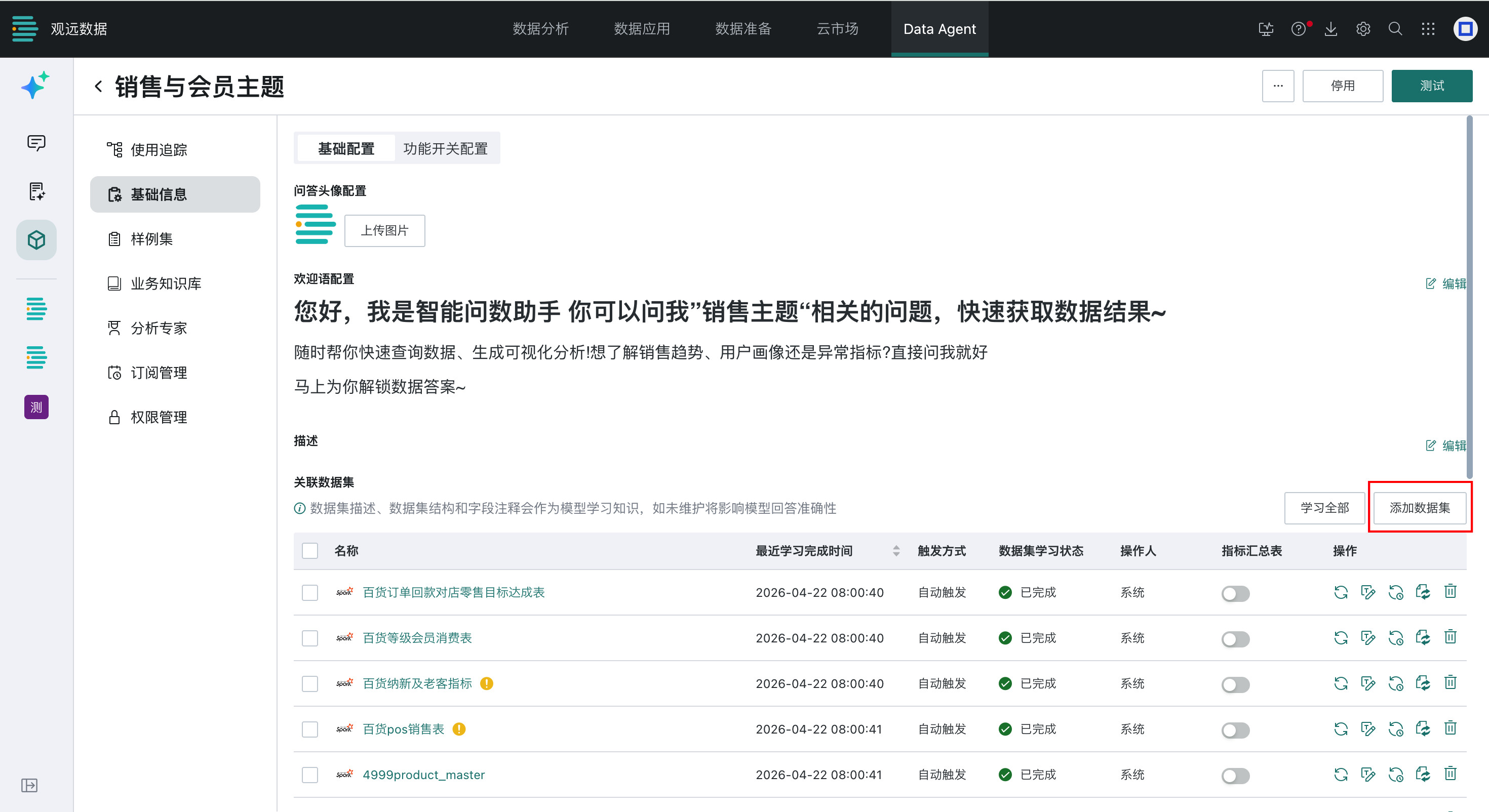
- 完成数据集智能体(原主题)创建后,进入「智能体管理 > 智能体详情配置 > 基础信息 > 基础配置」页面,点击「添加数据集」按钮。
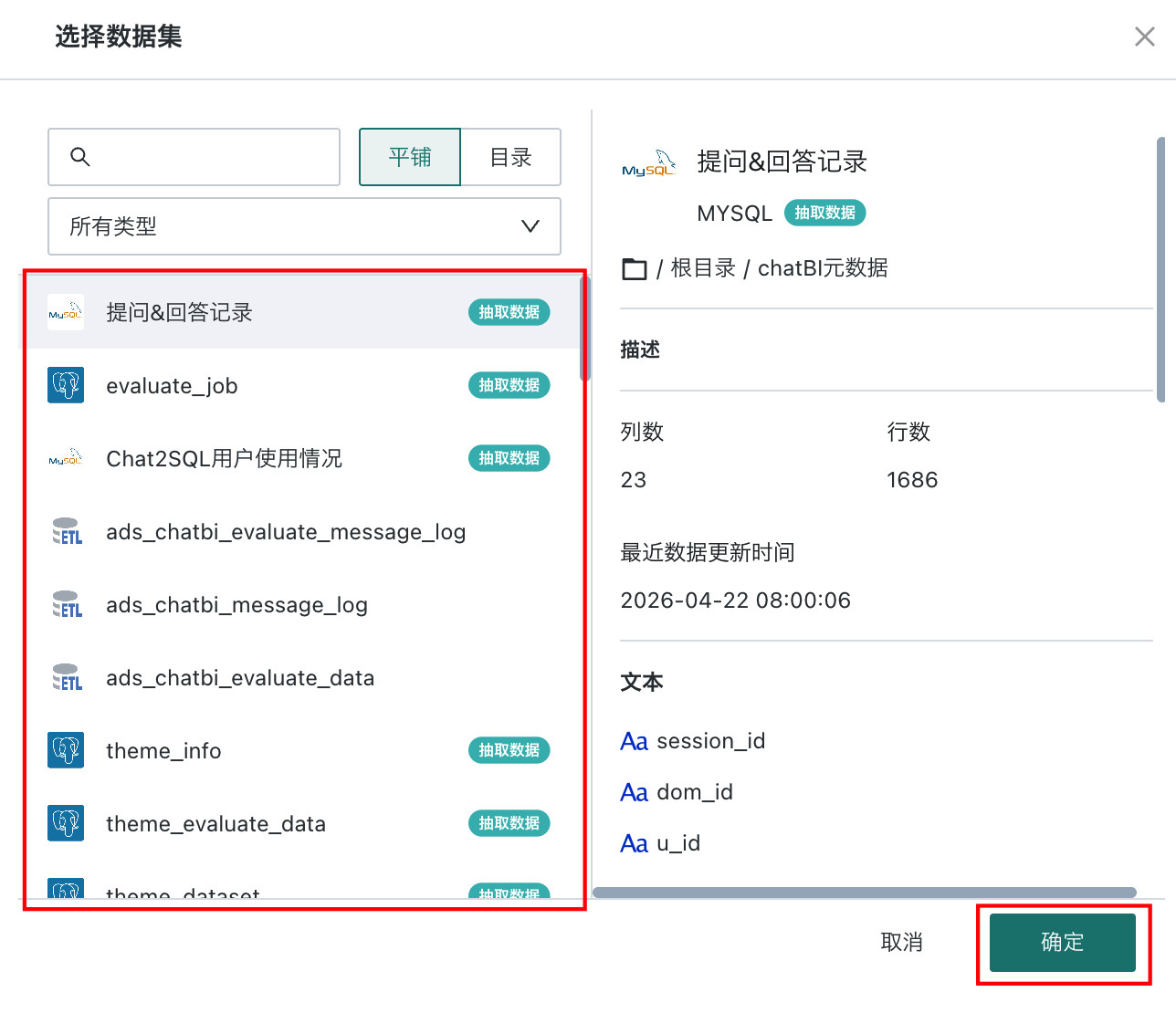
- 在弹出的数据集选择窗口中,勾选需要关联的数据集,点击「确定」完成添加。
操作页面
数据集质量要求
数据集结构相关
- 数据已处理为 ADS 层宽表(可用于业务自助取数)。
- 数据集描述信息:提供数据集的数据背景和数据说明,需说明当前表属于什么类型(维度表/事实表/拉链表/映射表),表的粒度(1 行代表什么业务事件)、主键及唯一索引是什么、更新逻辑是什么(每日全量/每日增量/实时)、覆盖的业务时间范围是什么,以及常用于哪些查询业务场景。
- 明细表必须具备:业务主键(如订单 ID+ 订单行号/交易 ID 等)、业务时间字段(订单日期/交易时间/业务日期等)、入仓时间字段(etl_date/load_time)、数据集智能体(原主题)范围内必需的维度字段(门店/商品/客户等)与核心指标字段(金额/数量/状态等)。
- 字段类型要求:ID/编码类字段统一为字符串;日期/时间字段需明确格式与时区(无法设置类型时需在注释写样例与格式);金额字段建议 decimal 并在注释说明币种与是否含税/含退款等口径;比例/率字段需声明取值范围(0
1 或 0100%);枚举/状态字段如为 0/1/2 等数字必须在注释写清映射含义。 - 明细表与指标表关系:指标表(ADS 宽表/汇总表)应由明细表按固定粒度聚合生成,需在描述中写清来源表、聚合粒度、更新方式与口径版本;同名指标口径必须唯一,如存在多口径需拆分指标名(如实付销售金额/应付销售金额),并在知识库中写明,避免同名不同义。
- 禁止混合粒度:不建议一张表同时存在明细值与汇总值;如历史原因必须混合,需新增“粒度类型”字段标识(DETAIL/DAILY_SUM/MONTH_SUM),并在知识库中写明不同问题类型对应的固定过滤规则,以避免错误聚合。
表/字段命名相关
- 避免数仓层表达作为字段名称,例如 ods_sales。请维护成具备业务含义的字段名,例如:销售金额。
- 如果字段名为缩写、业务常用语等特殊表达,请在字段注释中维护相应的业务含义。
- 避免字段与字段间的歧义或近义,例如,同一张表或多张表中都有字段叫“日期”,但日期的含义分别为订单日期和入库日期。
枚举值学习相关
- 数据集字段中的注释与枚举值,少量学习 (<10 个)。
- 固定枚举值的字段 (如订单状态、性别),建议将枚举值信息写在字段注释中 (如表示订单最终状态,枚举值:已送达、配送中、待配送)。
- 在提问场景中不会问到的字段,无需勾选枚举值学习,例如门店名称与门店地址,通常都是问题 xx 门店 xx 指标,那么门店名称需要勾选枚举值学习,门店地址则无需勾选枚举值学习。
其他说明
- 单个数据集智能体(原主题)中,所有的数据表字段总数不超过 300 个,否则准确率会降低(表数量无限制,建议不超过 5 张表)。
- 建议首个数据集智能体(原主题)的创建和测试,尽量先基于单表。在单表问答准确率达到 80% 后,再扩展其他表进行问答。
常见数据集样例
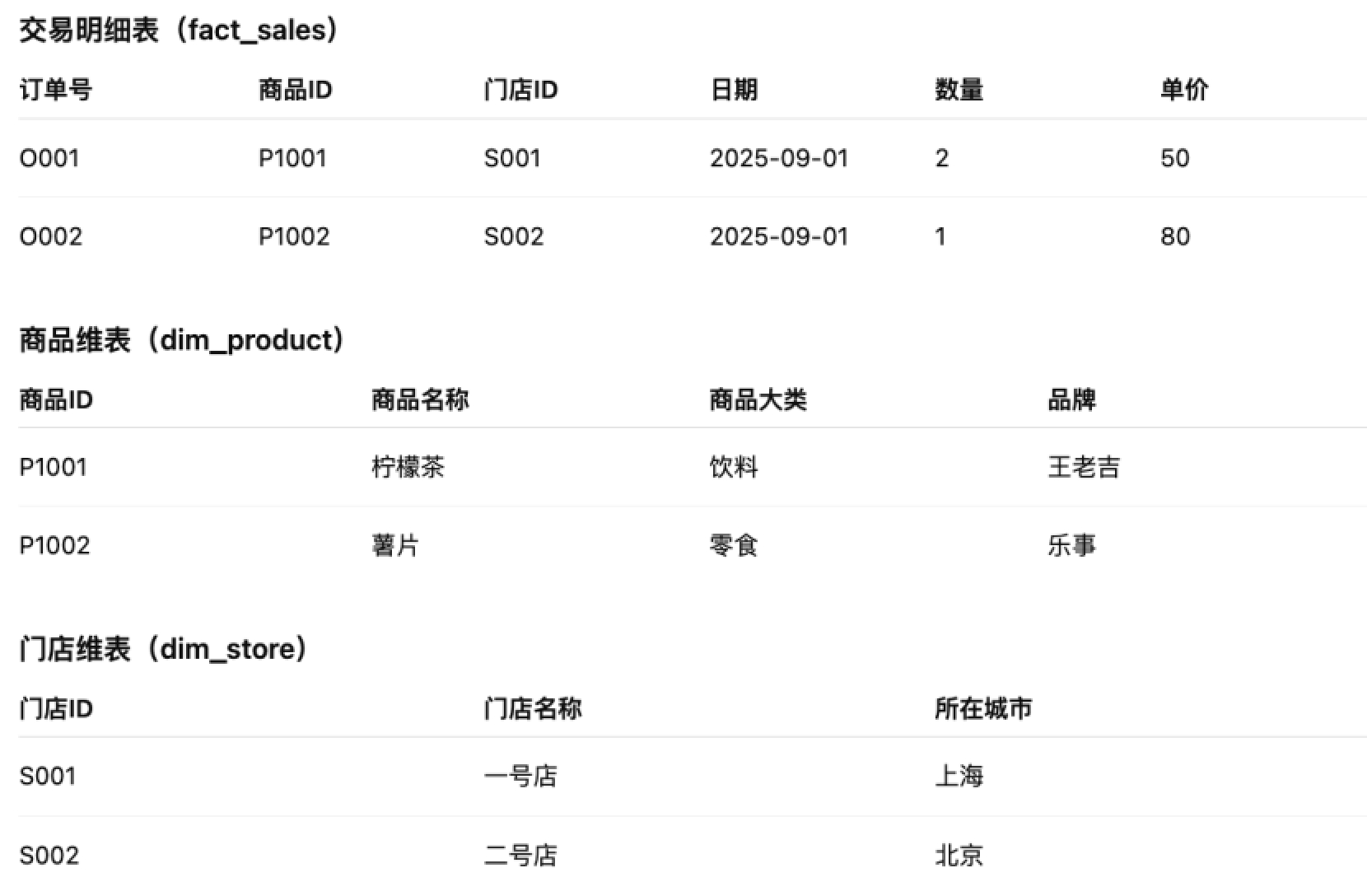
多表「明细表 + 维表」
典型场景:交易明细表 + 商品维表 + 门店维表
挑战点:需要跨表 join,字段来源分散。
单表「维度 + 日期 + 指标名(列名)」
典型场景:宽表,每个指标是单独的一列(如 销售额、销售量、毛利率)。
挑战点:指标很多,名称近似,容易混淆。

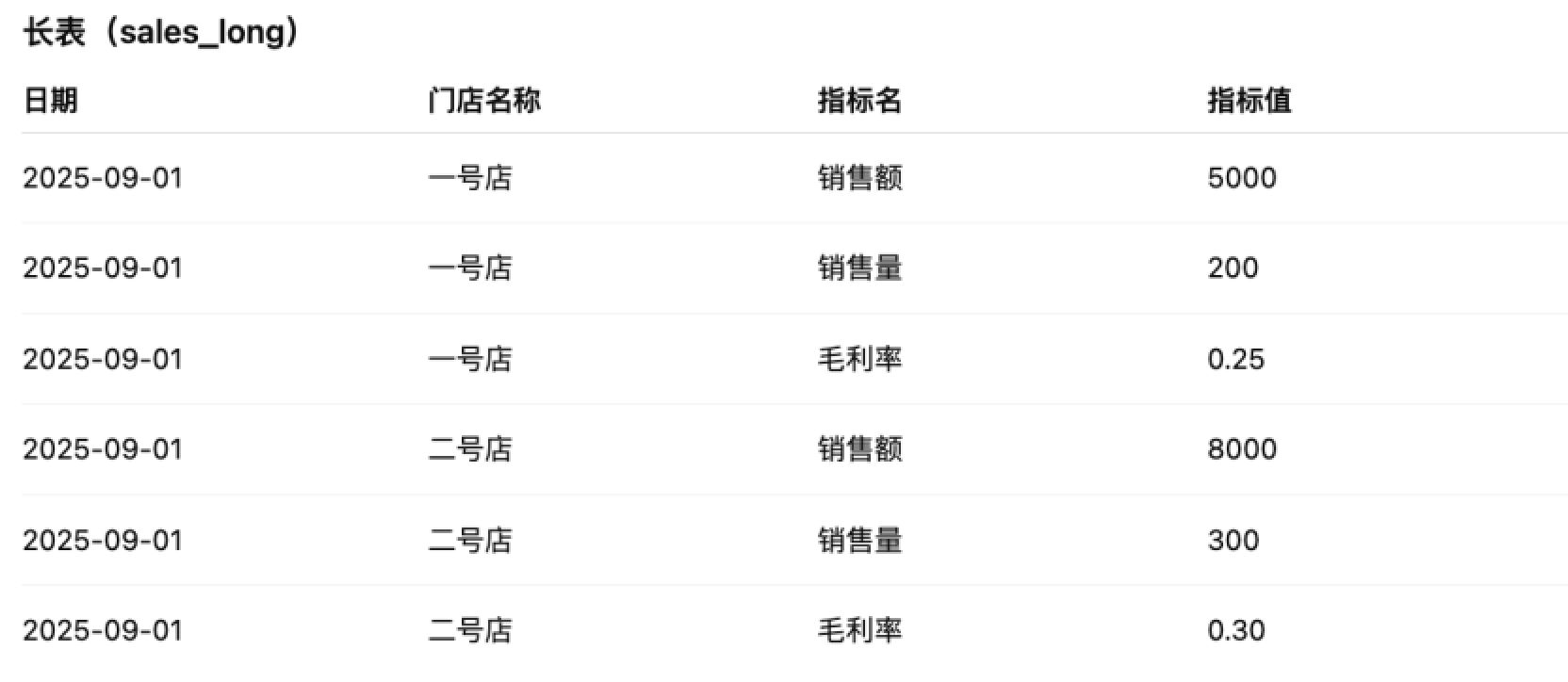
单表「维度 + 日期 + 指标名 + 指标值」
典型场景:长表(指标按行存储,字段如 维度/日期/指标名/指标值)。
挑战点:同一指标不是列而是行,需理解“指标名”字段含义。
常见数据集配置建议
下面将针对以上三类常见的数据集类型,进行配置方法的建议。
数据集配置建议
- 数据集名称,能表达数据集含义,且结合字段信息来看表达没有偏差;避免出现无意义信息,如时间戳、版本号、无意义符号等。
- 数据集描述,说明当前表属于什么类型(维度表/事实表/拉链表/映射表),表主键及唯一索引是什么,更新逻辑是什么,常用于哪些查询业务场景和时间范围、用于哪些用户(可以按照用户属性声明)。
- 参考格式:事实表,主键为订单 ID,每日增量更新,涵盖 2020 年 1 月至今所有门店销售订单。
字段配置建议
- 编号类字段,设置为字符串类型。
- 日期时间类字段,设置为日期或日期时间类型,如无法设置,需在字段注释中维护样例值或格式说明。
- 在多表场景下,尽可能减少表间重复字段(尤其是重复指标),大量冗余信息给到模型,可能会造成上下文过长,导致的响应慢及加重选表错误概率。
- 检查字段枚举值是否有业务含义,如无则需在注释中维护枚举值含义,或提前进行值替换。
字段别名建议
- 如原始字段为英文/缩写,建议直接将别名设置为业务常用名称。
- 字段名称需有实际业务含义(日期、ID 等常见字段除外)。
- 尽可能避免字段名称相似,如两个指标字段仅维度不同,避免用特殊符号标记(示例:销售额 _ 按周/销售额 _ 按月,应维护为每周销售额/每月销售额)。
字段注释建议
- 字段含义,需要描述清楚使用场景(应用于哪些场景分析)、当前字段及其枚举值的同义词和常用筛选条件/规则。
- 如当前字段为文本/数值、实际用于日期,请在字段注释中给出声明:用于日期类筛选与聚合,示例:YYYYMMDD
- 如当前字段为数值,实际用于聚合计算,可给出默认聚合方式,示例:SUM(销售额)。
- 如当前字段为编码类信息,建议在注释中给到固定格式及说明含义。
- 如当前字段枚举值无业务含义(为 0、1、2 等数字),则需在字段注释中对枚举值含义进行维护。
知识库管理与配置
为什么需要知识
仅根据有限的信息(几张数据集),大模型无法得知更多的业务信息,也无法按具体(隐性)的要求完成问答。
现实场景中,即便是资深数据分析师,也需要经历业务学习的阶段;即便是“懂业务”的分析师,在业务逻辑或规则动态变化的情况下,同样需要不断更新业务知识,才能更准确地应对最新的数据分析、取数需求。
因此,在数据完备的基础上,添加知识来训练大模型学习,是提升准确率至关重要的环节。
如何添加知识
步骤和时机
- 完成数据集智能体(原主题)创建、添加数据集后,进入「智能体管理 > 智能体详情配置 > 业务知识库」页面,点击「新建」按钮。
- 在知识编辑窗口中,将企业内部的知识条目(业务逻辑定义、指标计算逻辑)添加到知识库。
- 如没有现成的知识条目,可以先进行初步问答,在回答不正确或报错的过程中,逐步补充、完善知识库。
基本规范
- 表达清晰:用逻辑清晰的自然语言描述需要注意的业务逻辑、处理方式。
- 层层递进:保证当前描述中的复杂词汇在前面已经有所说明
- 管理统一:相同或类似概念、范畴的知识放一起维护,避免散落各处,方便排查和管理
- 避免冲突:检查前后知识是否矛盾,避免产生歧义、混淆或矛盾的知识干扰 GPT
操作页面
知识如何分类与编写
按使用类型分类
-
数据集说明(对数据集中的字段含义、业务知识进行说明)。
- 举例:「主键」:“<xxx 资产明细表>的主键是
月份、客户编号。” - 举例:「字段含义」:“<商品维表>中的
商品状态用于判断是否在售。” - 举例:「关联关系」:“<订单明细表>用
货号关联<商品维表>,<订单明细表>用店铺编码关联<门店维表>。” - 举例:「业务场景」:“<xxx 资产明细表>的数据包含了客户信息(开户日期、所属营业部/分公司、客户类型等)以及客户在该月份的资产、创收情况。”
- 举例:「表选择、查询优先级」当表名接近容易歧义时,可以添加知识:“涉及“商品”相关问题时,查询<门店 _ 商品销售日表>,否则都查询<门店销售日表>。”
- 举例:「主键」:“<xxx 资产明细表>的主键是
-
计算口径说明(对衍生指标计算规则、负责指标计算口径进行说明)。
- 举例:“转化率 = 转化人数 / 跟进人数,跟进率 = 跟进人数 / 触发人数。”
- 举例:“购买件数:SUM(
销售数量) ,购买人数:COUNT(DISTINCT消费者唯一标识),客件数: 购买件数 / 购买人数。” - 举例:“门店数量 = COUNT(DISTINCT
门店ID),毛利率 = SUM(销售毛利)/SUM(销售金额),客单价 = SUM(销售金额)/SUM(销售订单个数)。” - 举例:“亏损”、“损益”都是指代相同指标:
亏损金额= SUM(门店总成本)-SUM(毛利额),净利润= SUM(毛利额)-SUM(门店总成本)。”
-
可视化图表说明(某些问句下需要固定展示/不展示哪些字段)。
- 举例:“查询涉及门店详情、门店列表时默认都显示
门店名称,但不显示门店编码,除非提问中明确需要显示门店编码。” - 举例:“提问涉及 ofc、dm、zm、督导、战区负责人中任意一个时,所有查询必须显示对应的
大战区和小战区。” - 举例:“提问涉及“亏损”、“损益”,或“成本”、“利润”时,除了统计相关指标,还要同时统计成本明细项供用户参考:
房租成本、人工成本、水电成本、购物袋费成本、渠道手续成本、杂项成本和物流成本等。”
- 举例:“查询涉及门店详情、门店列表时默认都显示
-
业务逻辑说明(判断条件、业务关联关系等)
- 举例:当…时,需筛选“判断条件”,所有涉及订单的查询,都需筛选“
订单有效性= 1”) - 举例:映射关系:xxx:
字段名称,或 xxx:“判断条件” - 举例:「字段映射」销售金额:
支付金额,销售数量:商品数量 - 举例:「概念映射」 赠品:
是否赠品= 1 AND支付金额= 0 - 举例:「概念映射」品牌 A:
产品编号以 1 开头,品牌 B:产品编号以 2 开头 - 举例:「专业词映射」“小紫瓶”:
商品编码IN ("001", "002", "003")
- 举例:当…时,需筛选“判断条件”,所有涉及订单的查询,都需筛选“
-
指标计算逻辑说明(指标计算公式、计算口径等)
- 举例:折扣率 = 销售金额 / 吊牌金额
- 举例:呆滞率 = 呆滞期库存 / 库存总数
- 举例:剩余可用天数 = 产品离过期还有多少天
- 举例:当未明确问哪个月份的库存时,默认回答当前月非限制库存数量和冻结及质检库存的总和。
- 举例:新品销售额:
商品上线时间距今≤3 个月的 SKU,计算销售额总和。 - 举例:含 Axxx 指标:
品类代码= A 对应编码,计算包含 A 类商品的 xxx 指标,例如“2023 年含鞋配的销售额”,指一个小票中同时包含“鞋”和“配件”,且不包含其他大类的商品。 - 举例:当时间为每月 1 日,提问当月数据时,则回答:“1 日尚未同步,明天才能更新当月数据~”
- 举例:当提问中出现“产品”字眼时,需要先询问:“请问您是否需要查询产品编码第 2 位是 X 的数据?”
-
SQL 语法说明(对于一些特殊情况,可以说明请使用某某语法)。
按使用频次分类
| 通用知识 | 业务知识 | |
|---|---|---|
| 优势 | 每次提问都会学习/参考的知识内容 | 只有当提问与业务知识有一定相似度,或一些字眼匹配时,大模型才会学习/参考的知识内容 |
| 劣势 | 每次都占用 prompt 长度,内容过多后会被截断 | 匹配可能不够精准,导致遗漏应该学习到的知识 |
知识应用案例
以门店销售数据为例, 目标是进行零售四大抓手分析, 四大抓手为:小票数、折扣、连带率、客单价。由于最终客户问题中是维度、指标的排列组合,理论上有无限的可能性,所以我们需要构建一个多层次的维度、指标体系,系统性的将业务知识精炼、压缩给到大模型。一般来说,我们按照先指标、后维度; 先简单、后复杂的顺序来构建业务知识。 通常来说, 指标可以分为基础指标体系、复合指标体系和派生指标体系。
例如:
- 基础指标: 销售金额、营业天数、吊牌价格、销售数量、小票数、退货票数、客单量等等
- 复合指标: 件单价、销售平均牌价、折扣、客单价、单件单数占比等等
- 派生指标: XX 销售金额、XX 吊牌金额、XX 小票数、XX 商品数量、不含赠品 XX 指标等等
案例一:基础指标查询
这是基础指标相关的业务问题,需要维护的动作是,明确销售金额的计算方式。
一般来讲, 金额类的相关列名在数据表中可能存在多列, 数据分析师需要在业务知识中,维护业务通常口语话的提问方式与数据表列名之间的关系,例如:销售金额使用 RMB结算金额 这个字段来计算,及 SUM(RMB结算金额)。
案例二:维度关联指标查询
这是维度关联指标的业务问题,需要明确维度间的关联关系,只有符合这个条件的数据才是有效的数据。
需要数据集智能体(原主题)管理员,在通用知识中维护,任何查询默认增加过滤条件 是否有效商品标识 = 1 以获得有效数据, 即使提问中包含了类似‘不要其他限制条件’的语句,也一定要加上 是否有效商品标识 = 1 的限制。
样例集(原错题集)的管理与配置
为什么需要样例集(原错题集)
针对极小范围,处理逻辑复杂、条件繁多(业务知识难以清晰维护)的情况,业务知识效果不好的,可以添加至样例集(原错题集),来提升问答稳定性。
如何添加样例集(原错题集)
步骤和时机
- 在数据集符合上述规范,并且维护了业务知识、通用知识后,如效果依旧不理想、不稳定,进入「智能体管理 > 智能体详情配置 > 样例集」页面,点击「新建」按钮。
- 在样例集编辑窗口中,录入提问的语料、对应的正确 SQL 等内容,最后将启用状态置为「有效」即可。
基本规范
- 避免添加过于简单,或非长期有效的内容。
- 如果「过于简单」可以通过业务知识库高效维护,例如:「提问」2025 年 2 月 xxx 商品的销售金额是多少?
- 如果「非长期有效」,例如提问是相对日期,SQL 条件是绝对日期,例如:「提问」昨天的销售金额是多少?「样例集 SQL」的条件日期= "2025-03-01"
- 针对动态时间的表述计算需要用时间函数,如昨天、近 7 天、上个自然周,不要使用写死的时间日期。
操作页面
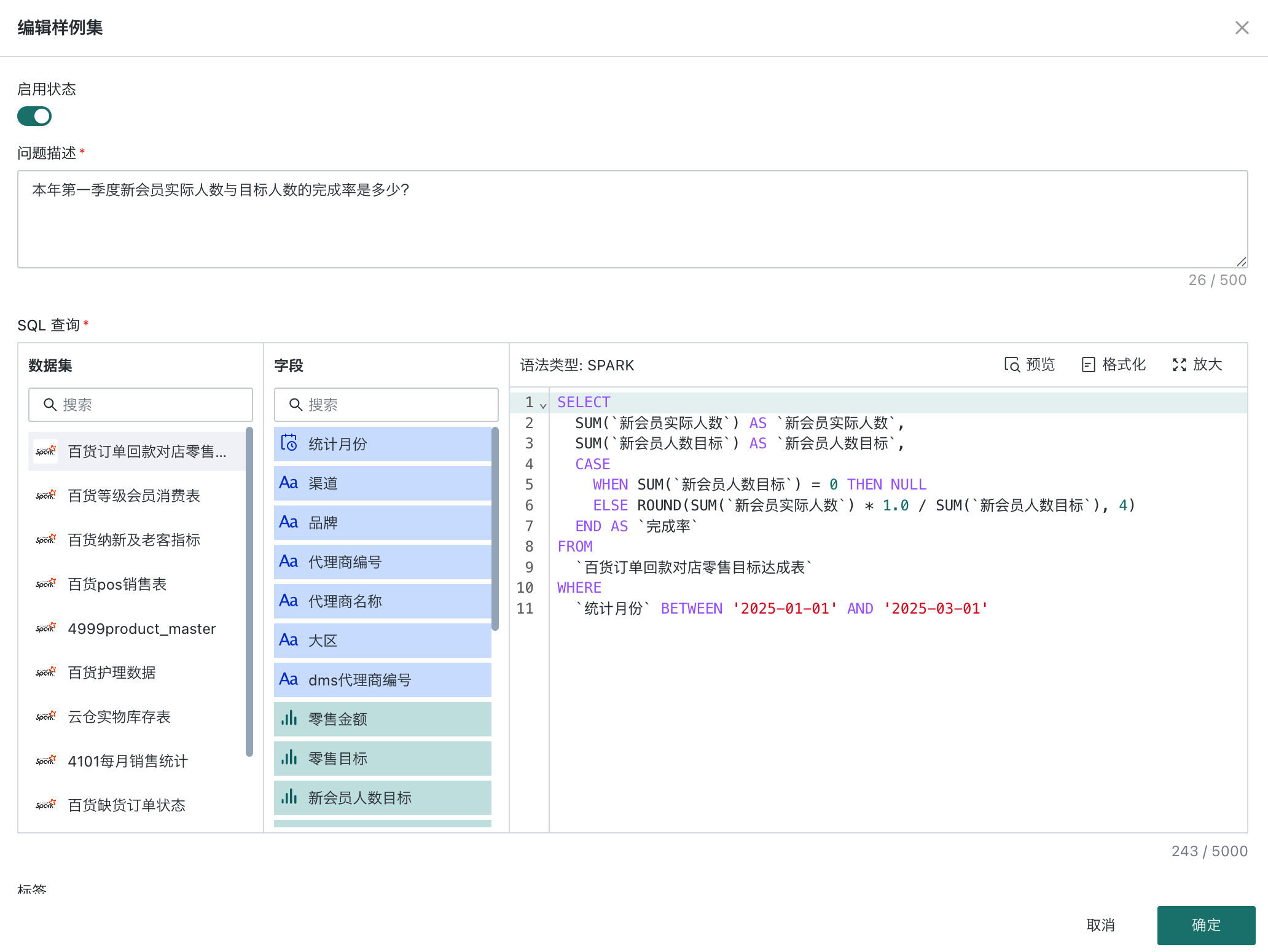
样例集(原错题集)应用案例
- 当根据“长尾商品”定义,进行查询涉及窗口函数等复杂逻辑时,可以添加样例集(原错题集):
WITH `store_goods` AS (
SELECT `商品编码`, `商品名称`, SUM(`销售金额`) AS `销售额`
FROM `@CHatBI_全国门店商品销售数据_按天`
WHERE `业务日期` >= '2025-04-01'
AND `业务日期` <= '2025-04-30'
AND `门店名称` LIKE '%德昌%'
AND `门店名称` LIKE '%育才%'
AND `门店名称` LIKE '%路%'
AND NOT `销售金额` IS NULL
GROUP BY `商品编码`, `商品名称`
),
`total_sales` AS (
SELECT SUM(`销售额`) AS `总销售额`
FROM `store_goods`
),
`ranked_goods` AS (
SELECT `商品编码`, `商品名称`, `销售额`
, SUM(`销售额`) OVER (ORDER BY `销售额` ASC ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS `累计销售额`
FROM `store_goods`
)
SELECT `商品编码`, `商品名称`, `销售额`
, ROUND(`累计销售额` / `总销售额`, 4) AS `累计占比`
FROM `ranked_goods`, `total_sales`
WHERE `累计销售额` / `总销售额` <= 0.2
ORDER BY `销售额` ASC
- 当本周的周度环比,需要限制上周相同天数时,可以添加样例集(原错题集):
WITH `date_ref` AS (
SELECT DATE_SUB(CURRENT_DATE, INTERVAL (DAYOFWEEK(CURRENT_DATE) + 5) % 7 DAY) AS `本周起始`
, DATE_SUB(DATE_SUB(CURRENT_DATE, INTERVAL (DAYOFWEEK(CURRENT_DATE) + 5) % 7 DAY), INTERVAL '7' DAY) AS `上周起始`
),
`cur` AS (
SELECT SUM(`销售金额`) AS `本周销售额`
FROM `@CHatBI_全国门店销售数据_按天`, `date_ref`
WHERE `大战区` LIKE '% 川东南%'
AND `业务日期` >= `date_ref`.`本周起始`
AND `业务日期` <= DATE_SUB(CURRENT_DATE, INTERVAL '1' DAY)
AND NOT `销售金额` IS NULL
),
`pre` AS (
SELECT SUM(`销售金额`) AS `上周销售额`
FROM `@CHatBI_全国门店销售数据_按天`, `date_ref`
WHERE `大战区` LIKE '% 川东南%'
AND `业务日期` >= `date_ref`.`上周起始`
AND `业务日期` < DATE_ADD(`date_ref`.`上周起始`, INTERVAL DATE_DIFF('DAY', DATE_SUB(CURRENT_DATE, INTERVAL '1' DAY), `date_ref`.`本周起始`) DAY)
AND NOT `销售金额` IS NULL
)
SELECT `cur`.`本周销售额`, `pre`.`上周销售额`, `cur`.`本周销售额` - `pre`.`上周销售额` AS `环比变化`
, CASE
WHEN `pre`.`上周销售额` = 0
OR `pre`.`上周销售额` IS NULL
THEN NULL
ELSE ROUND((`cur`.`本周销售额` - `pre`.`上周销售额`) / `pre`.`上周销售额`, 4)
END AS `环比变化率`
FROM `cur`, `pre`
- 当本月的月度同环比,即 MTD 业务指标同环比的上月同期、去年同期也需要限制相同天数时,可以添加样例集(原错题集):
WITH `cur_month` AS (
SELECT SUM(`销售金额`) AS `本月销售额`
FROM `@CHatBI_全国门店销售数据_按天`
WHERE `城市` LIKE '% 成都%'
AND `业务日期` >= DATE_FORMAT(CURRENT_DATE, '%Y-%m-01')
AND `业务日期` <= DATE_SUB(CURRENT_DATE, INTERVAL '1' DAY)
AND NOT `销售金额` IS NULL
),
`last_month` AS (
SELECT SUM(`销售金额`) AS `上月同期销售额`
FROM `@CHatBI_全国门店销售数据_按天`
WHERE `城市` LIKE '% 成都%'
AND `业务日期` >= DATE_SUB(DATE_FORMAT(CURRENT_DATE, '%Y-%m-01'), INTERVAL '1' MONTH)
AND `业务日期` <= DATE_SUB(DATE_SUB(CURRENT_DATE, INTERVAL '1' DAY), INTERVAL '1' MONTH)
AND NOT `销售金额` IS NULL
),
`last_year` AS (
SELECT SUM(`销售金额`) AS `去年同期销售额`
FROM `@CHatBI_全国门店销售数据_按天`
WHERE `城市` LIKE '% 成都%'
AND `业务日期` >= DATE_SUB(DATE_FORMAT(CURRENT_DATE, '%Y-%m-01'), INTERVAL '1' YEAR)
AND `业务日期` <= DATE_SUB(DATE_SUB(CURRENT_DATE, INTERVAL '1' DAY), INTERVAL '1' YEAR)
AND NOT `销售金额` IS NULL
)
SELECT `c`.`本月销售额`, `l`.`上月同期销售额`, `y`.`去年同期销售额`, `c`.`本月销售额` - `l`.`上月同期销售额` AS `环比变化`
, CASE
WHEN `l`.`上月同期销售额` = 0
OR `l`.`上月同期销售额` IS NULL
THEN NULL
ELSE ROUND((`c`.`本月销售额` - `l`.`上月同期销售额`) / `l`.`上月同期销售额`, 4)
END AS `环比变化率`, `c`.`本月销售额` - `y`.`去年同期销售额` AS `同比变化`
, CASE
WHEN `y`.`去年同期销售额` = 0
OR `y`.`去年同期销售额` IS NULL
THEN NULL
ELSE ROUND((`c`.`本月销售额` - `y`.`去年同期销售额`) / `y`.`去年同期销售额`, 4)
END AS `同比变化率`
FROM `cur_month` `c`, `last_month` `l`, `last_year` `y`
准确率测试
为什么需要准确率测试
作为数据集智能体(原主题)管理员,应该也是数据集智能体(原主题)的第一个用户,您需要仔细检查你配置的数据集、业务知识、样例集(原错题集)是否生效,该数据集智能体(原主题)能否准确回答普通用户的提问。
如果 ChatBI 误解了数据、问题或业务术语,您可以通过纠正大模型生成的 SQL 后加入样例集(原错题集)、或修正其他业务知识来进行干预。
如何进行准确率测试
步骤和时机
在数据集、业务知识等都配置完成后,数据集智能体(原主题)正式投产上线前,可以进行准确率验证。建议准确率达到 90% 及以上后,再将数据集智能体(原主题)正式开放给业务用户使用。
基本规范
- 测试步骤:① 添加问题/批量导入 → ② 判断数据结果是否正确 → ③ 判断 SQL 是否正确 → ④ 新增/修改知识 → ⑤ 重新测试。
- 测试原则:提问语料要符合有效提问结构(不要发散、超出数据集智能体(原主题)范围),时间/条件/指标清晰明确、避免歧义。
- SQL 有效性不通过:建议勾选后重新测试,如频繁出现该问题需联系观远进行排查。
操作页面
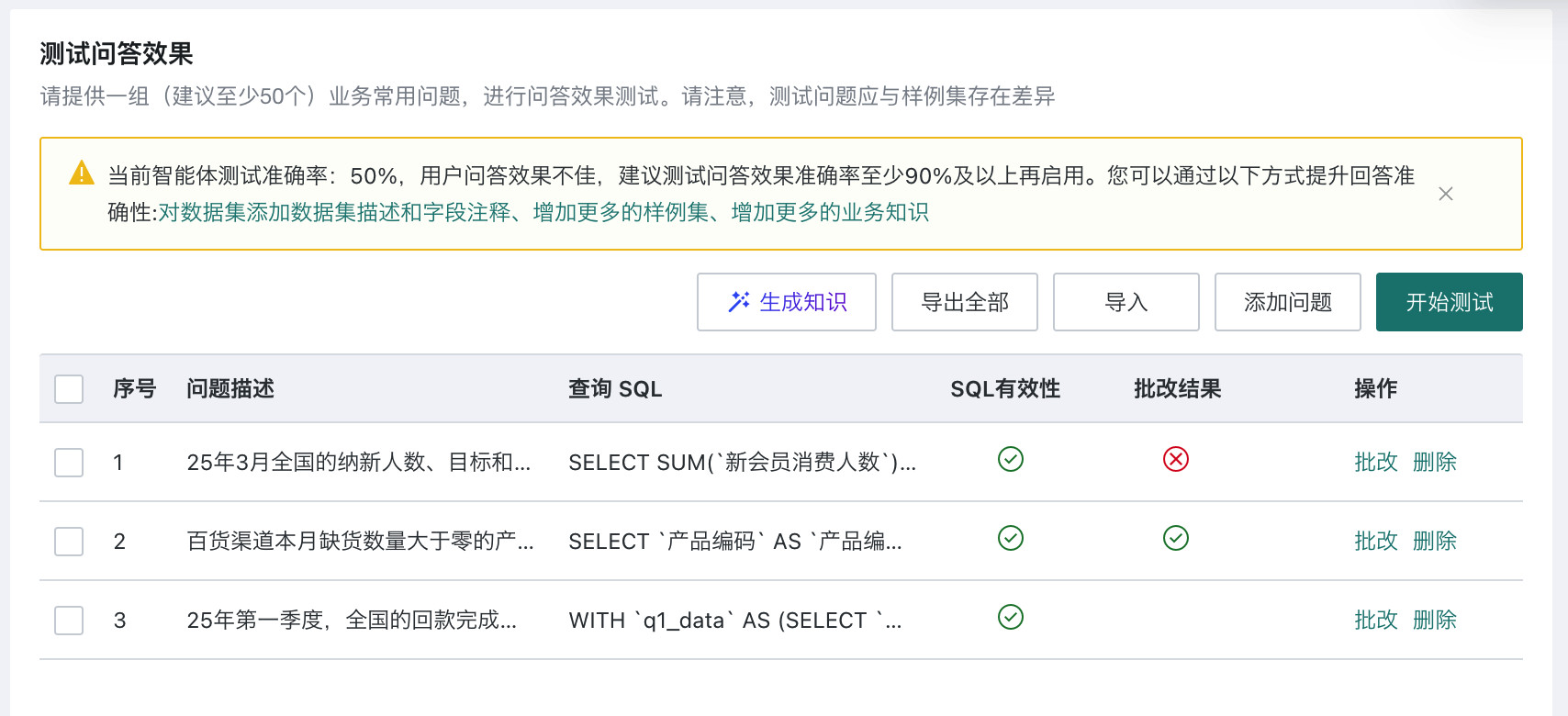
测试功能应用案例
适用场景
需要批量验证问题回答准确性,确认大模型生成结果,查询数据是否正确。
前置条件
提前准备好测试评估集(问题列表推荐 50-100 个)与答案(SQL 形式),保存在 Excel 中,通过 Excel 导入的方式,导入到 ChatBI 测试功能内。
操作步骤
-
明确测试目标:
- 本次测试对准确率的预期是多少?——用于后续评判需要维护到多少准确率可交付。
- 本次测试目标为业务 POC 测试导向还是产品功能测试导向?
- 如为业务 POC 测试,请检查提供的问题表述,是否符合业务提问习惯(例如,业务一般不会写出「2025 年的销售额是多少,按门店维度进行聚合」这种表达)。
- 如为产品功能测试,建议按照要求验证的能力项,每个能力项提供 5 个样例问题。
-
选取以下资料:
- 数据源(n 个数据集)
- 测试分级样例(每个分级 5 个问题最佳)
- 测试答案(nice to have)
测试问题和答案均需考虑到通用性,尽可能不包含时间相关条件。如必须包含,则问题中尽可能用绝对时间、SQL 中同样写死绝对时间,保障数据集更新始终包含该时间段;如问题中采用相对时间,则 SQL 中同样需采用相对时间进行计算,否则答案过期无效。
-
进入「Data Agent > 智能体管理 > 智能体详情配置 > 基础信息」页面,确认数据知识是否已学习完成,以及必要枚举值字段是否已经勾选学习。
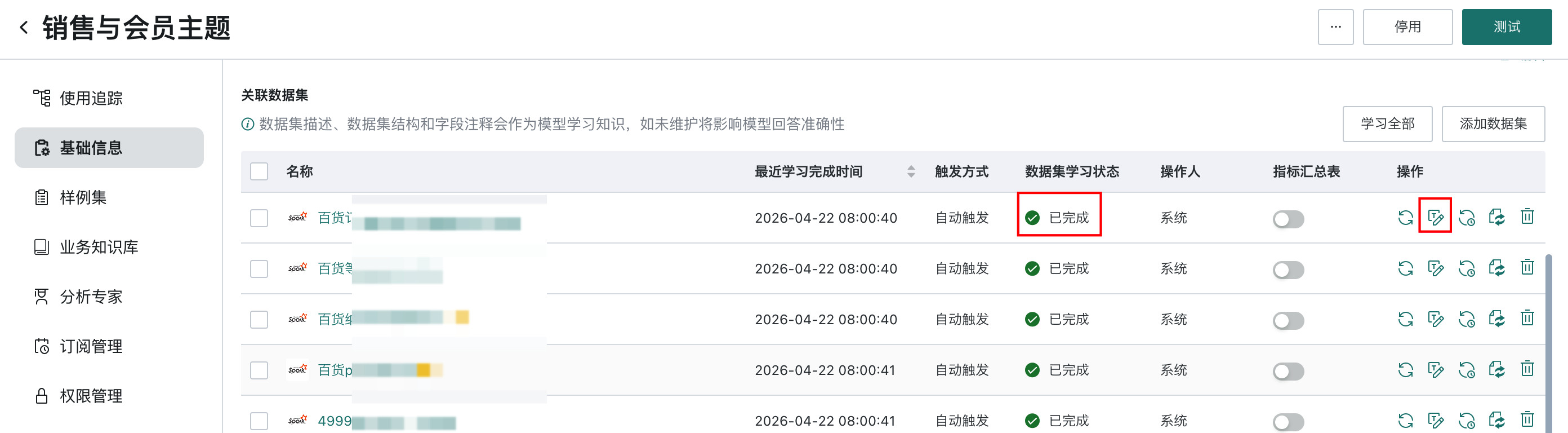
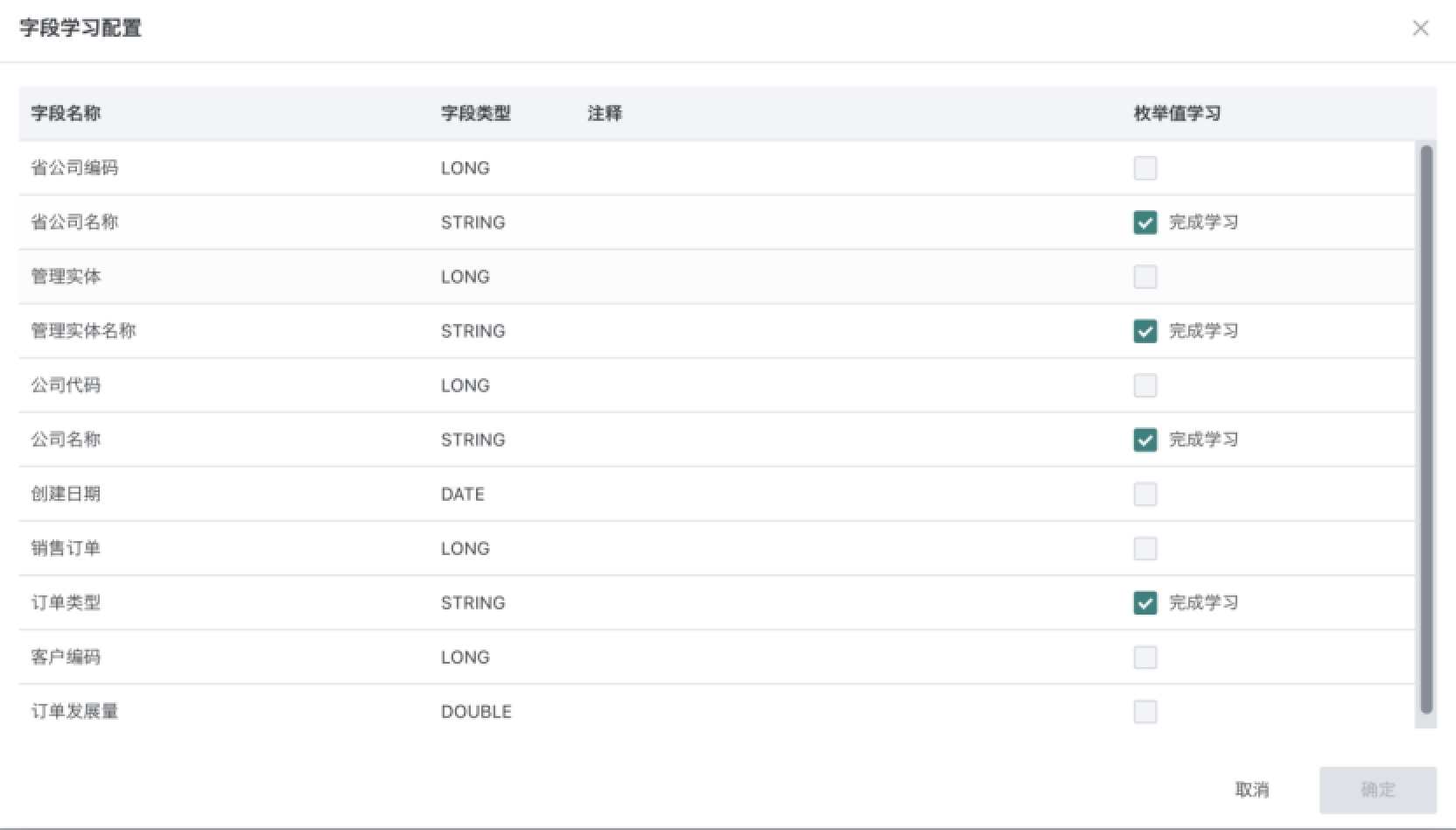
-
数据集学习完成后,点击「测试」按钮,进入测试界面。
-
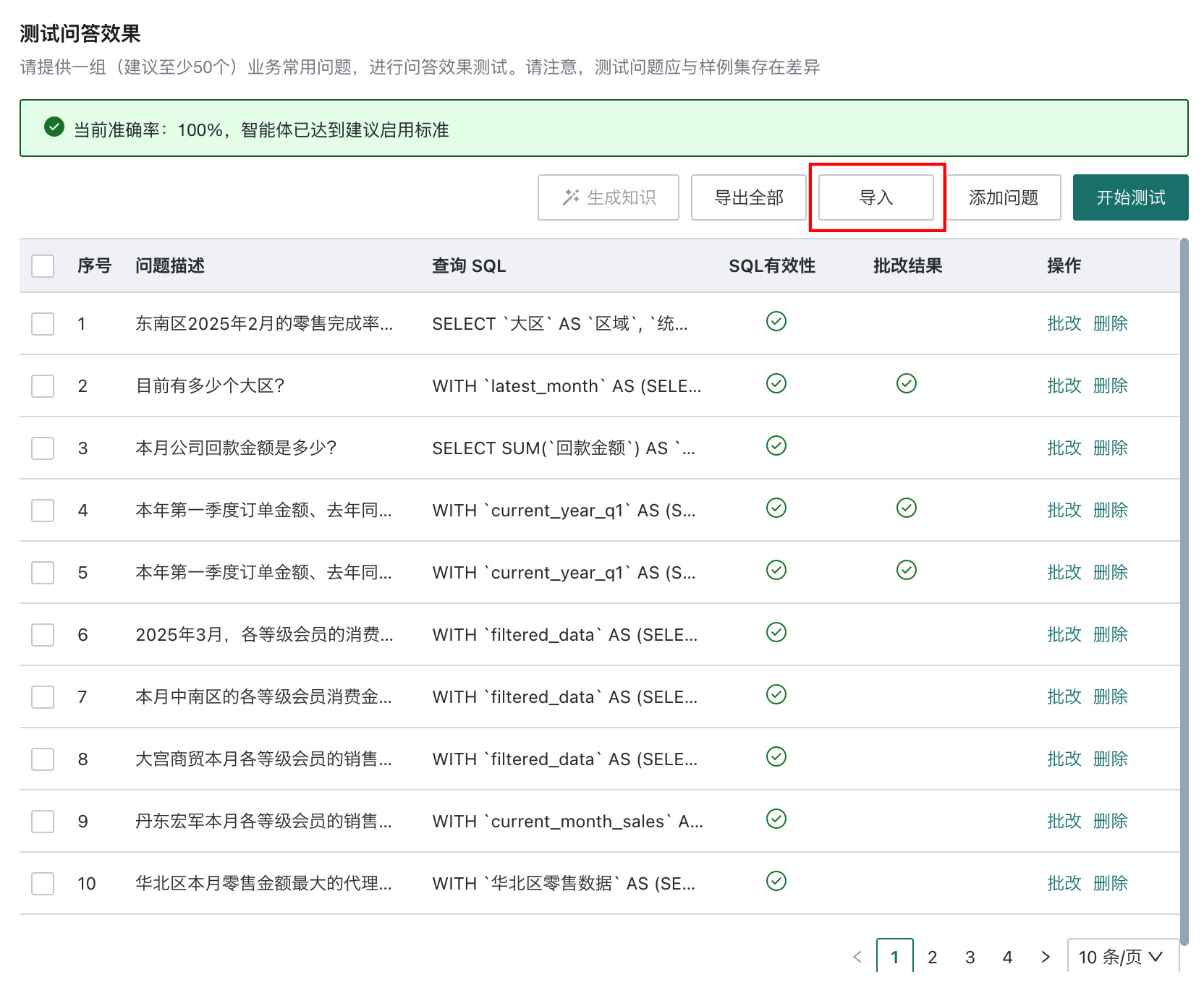
点击「导入」,将准备好的评估集(问题 + SQL)同时导入到系统中,等待测试及批改自动完成。通常 1 个问题的测试需要 1 分钟,可以按问题总量预估测试完成时间,等待测试完成后进行查看。
-
测试完成后,点击「生成知识」按钮,系统会自动针对回答错误的问题,进行对数 - 知识生成流程。通常来说,单个问题的知识生成时间在 1 分钟左右,可以参考系统给出的预估时间,等待知识生成完成后进行结果审查。
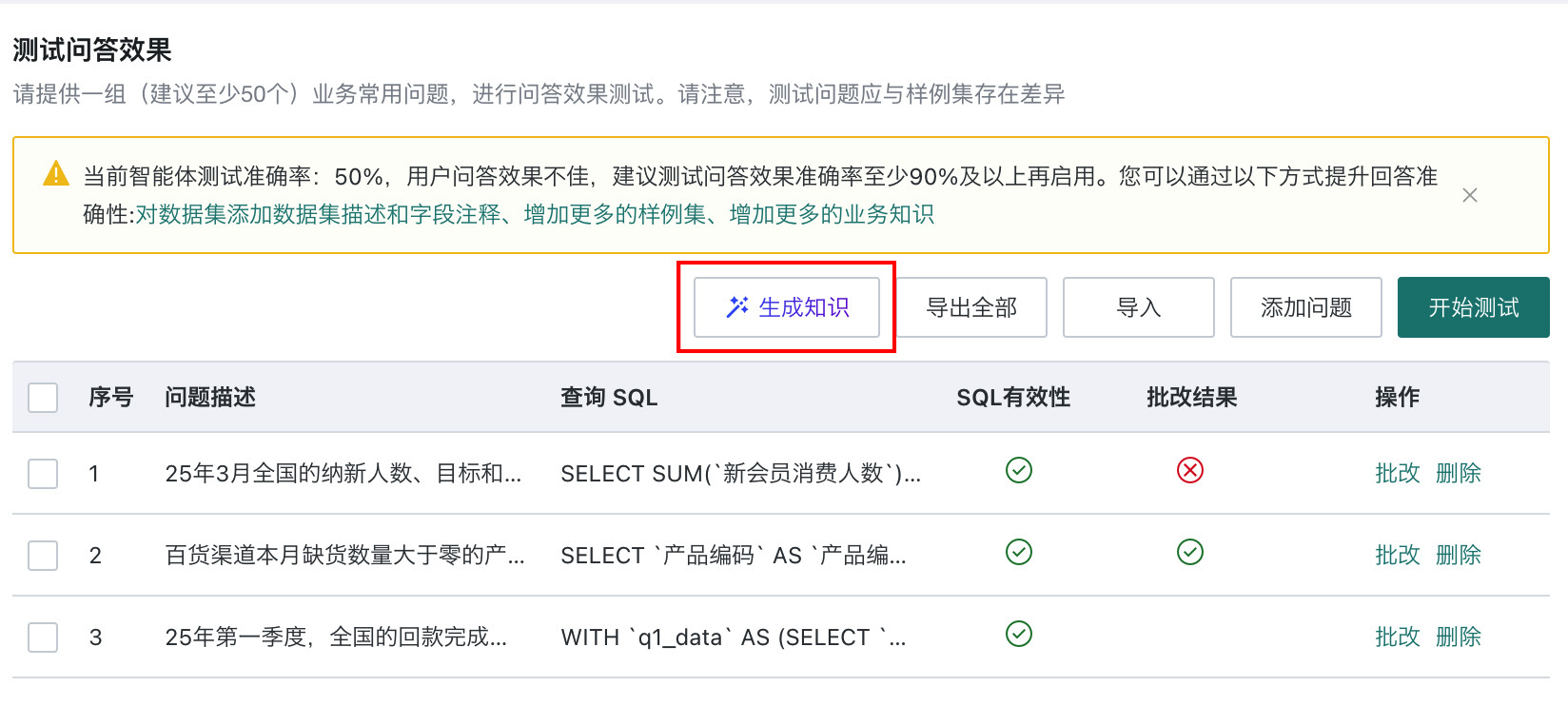
-
知识全部生成完成后,在弹窗内进行知识结果审查,点击「确认修改」按钮,保留本次系统生成知识的结果。如果认为系统生成的某条知识需要修改,可以确认修改后,在知识库中筛选「系统生成」标签,找到该知识进行修正。
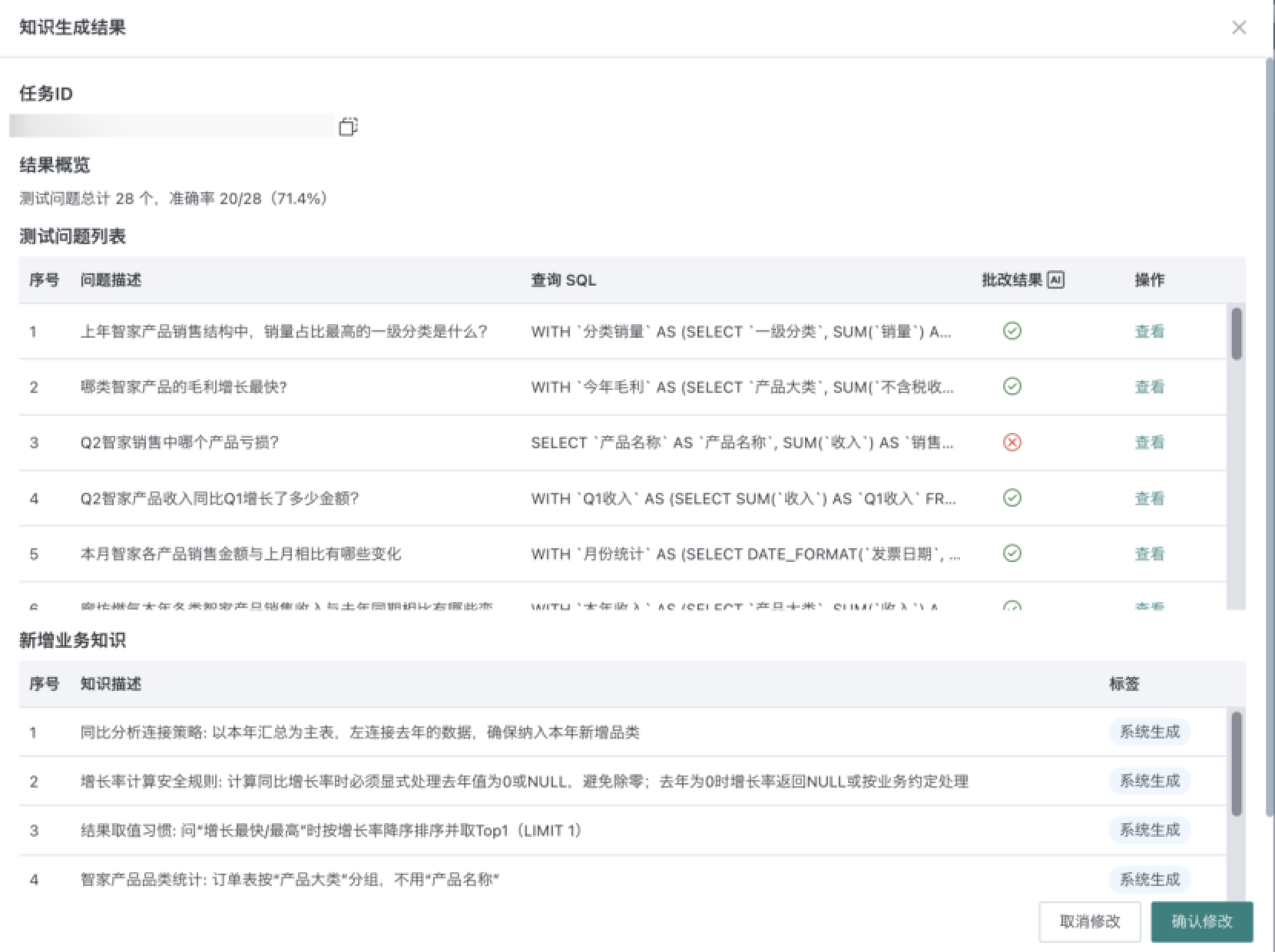
-
结果审查完成后,返回测试界面,全选当前所有问题,点击「开始测试」按钮进行重新测试(用于验证生成知识的有效性)。

-
重测后,查看测试结果中的准确率统计:
- 若准确率达到预期目标(≥ 90%),即可将数据集智能体(原主题)投入生产使用。
- 若准确率未达标,则重复「生成知识 → 批量重测」的流程,直到准确性满足需求。
- 注意:每次测试完成后,测试结果仍然需要人工核对准确性并进行修正。
结果验证
测试完成后,可通过以下方式验证准确率:
- 在测试界面查看「准确率」统计卡片,确认整体准确率是否达到 90% 及以上。
- 点击「查看详情」,逐条检查回答错误的问题,确认错误类型(数据错误 / SQL 错误 / 理解错误)。
- 对于回答错误的问题,点击「查看 SQL」对比系统生成的 SQL 与预期 SQL 的差异。