GuanOps运维服务平台
概述
GuanOps 是一个智能运维平台,旨在简化 BI 系统的日常运维操作,提升运维效率和安全性。无需登录服务器,即可通过统一、安全的 Web 界面完成数据清理、日志采集、故障分析、健康检查、网络检测等一系列核心运维任务,从而高效管理和维护观远 BI 系统。
前提条件
-
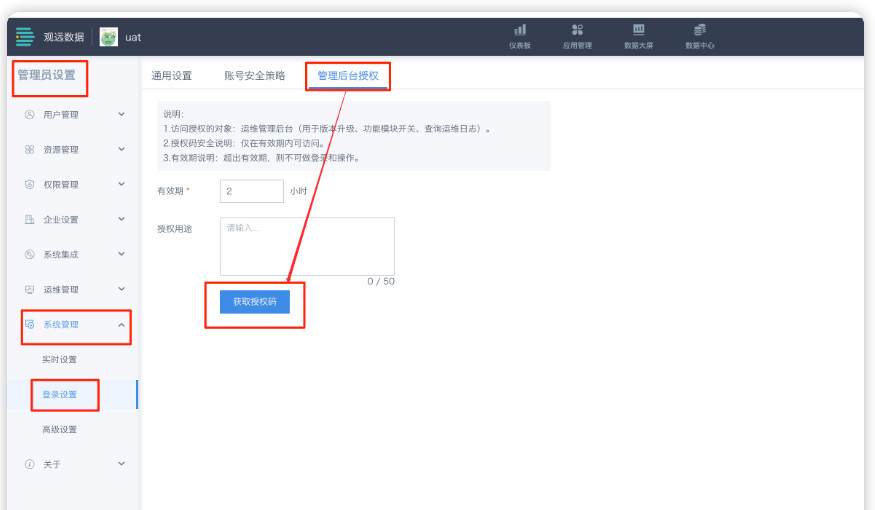
获取授权码:「管理中心 > 系统设置 > 登录设置 > 管理后台授权」。
-
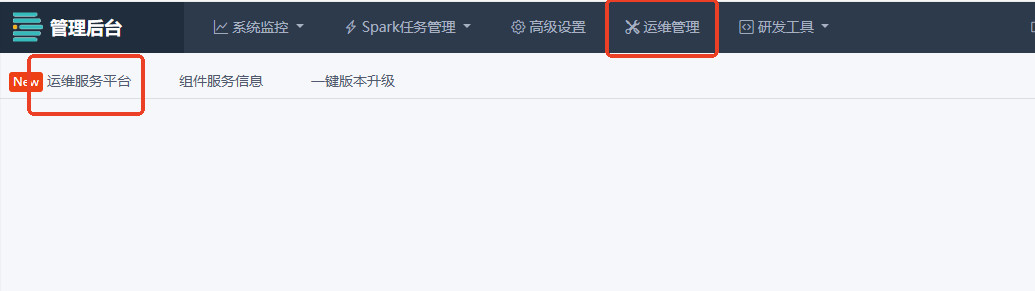
浏览器输入
域名/system-backend,进入管理后台。GuanOps 入口如图所示:
使用指导
数据清理
核心价值: 帮助解决磁盘空间占用过高的问题,根据业务影响风险提供不同力度的清理策略。
-
使用场景识别: 当系统监控或告警提示磁盘使用率较高时。
-
通用操作流程:
- 选择所需清理类型(轻度清理、深度清理)或分析功能(数据目录分析)。
- 点击对应功能的执行按钮。
- 页面实时显示执行日志,便于跟踪进度和结果。
- 操作完成后,查看清理结果。
轻度清理
- 适用场景: 磁盘使用率偏高(例如 >85%)但服务运行正常时,用于温和释放空间。
- 执行规则:
- 清理缓存数据。
- 保留最新 3 个镜像版本。
- 保留近 3 天备份。
- 轻度清理临时数据。
- 执行 Spark 清理脚本。
- 风险与影响(低风险):操作对当前运行的服务无直接影响,任务可正常执行。
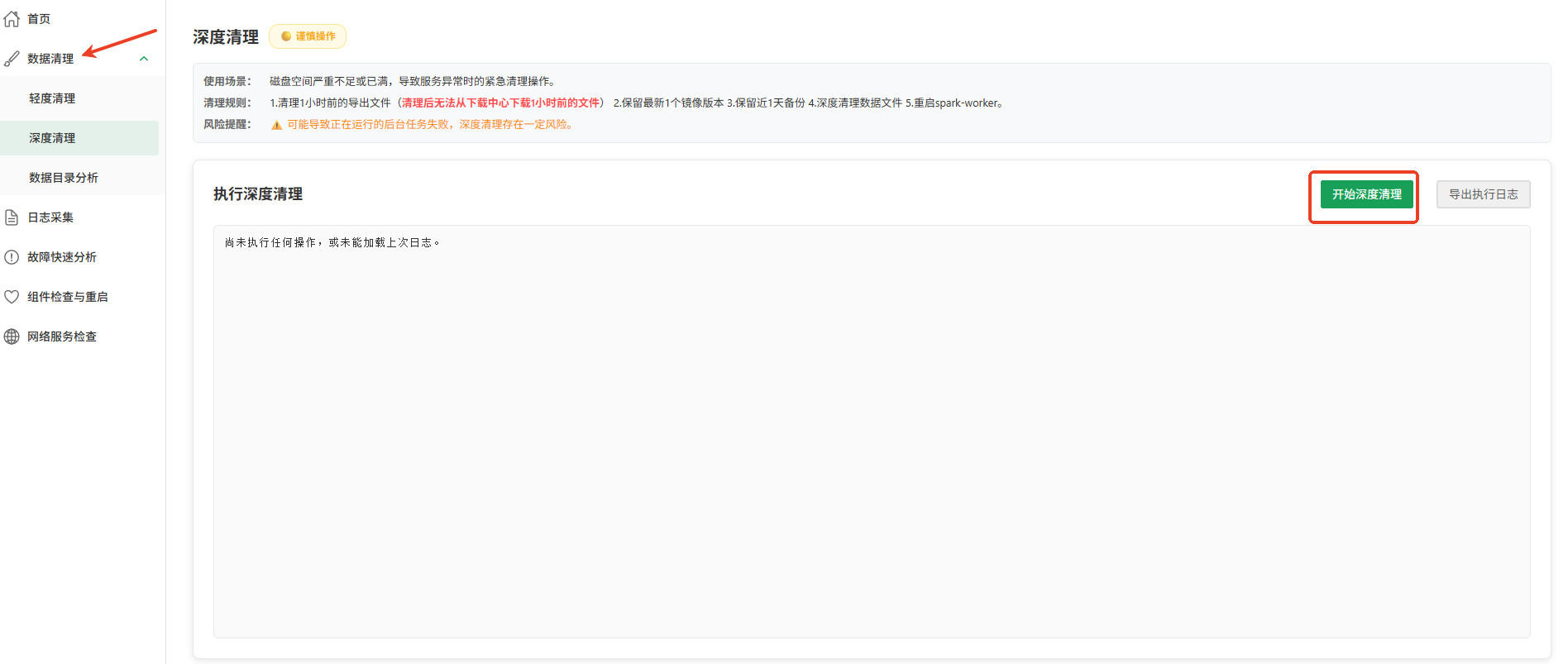
深度清理
-
适用场景: 磁盘空间严重不足或已满(例如 >95%),可能导致服务异常,需进行紧急清理以恢复基础服务。
-
执行规则:
-
清理 1 小时前的导出文件
注意清理后无法从下载中心下载 1 小时前的文件。
-
保留最新 1 个镜像版本。
-
保留近 1 天备份。
-
深度清理数据缓存文件
-
重启 Spark-worker 服务
注意重启可能导致任务中断。
-
-
风险与影响(高风险):
- 可能导致清理期间正在运行的后台计算任务失败。
- 属于紧急恢复操作,仅在服务异常或严重告警时使用。
数据目录分析
- 功能说明: 深入分析磁盘空间占用详情,定位主要空间消耗者及异常占用情况。
- 分析内容:
- 各目录/文件的磁盘占用大小及排名。
- 识别异常增长的大文件或目录。
- 提供可视化或详细报告展示空间分布。
- 使用建议:
- 建议在业务低峰期执行(扫描大量文件会消耗 I/O 资源)。
- 执行时间与数据量大小直接相关。
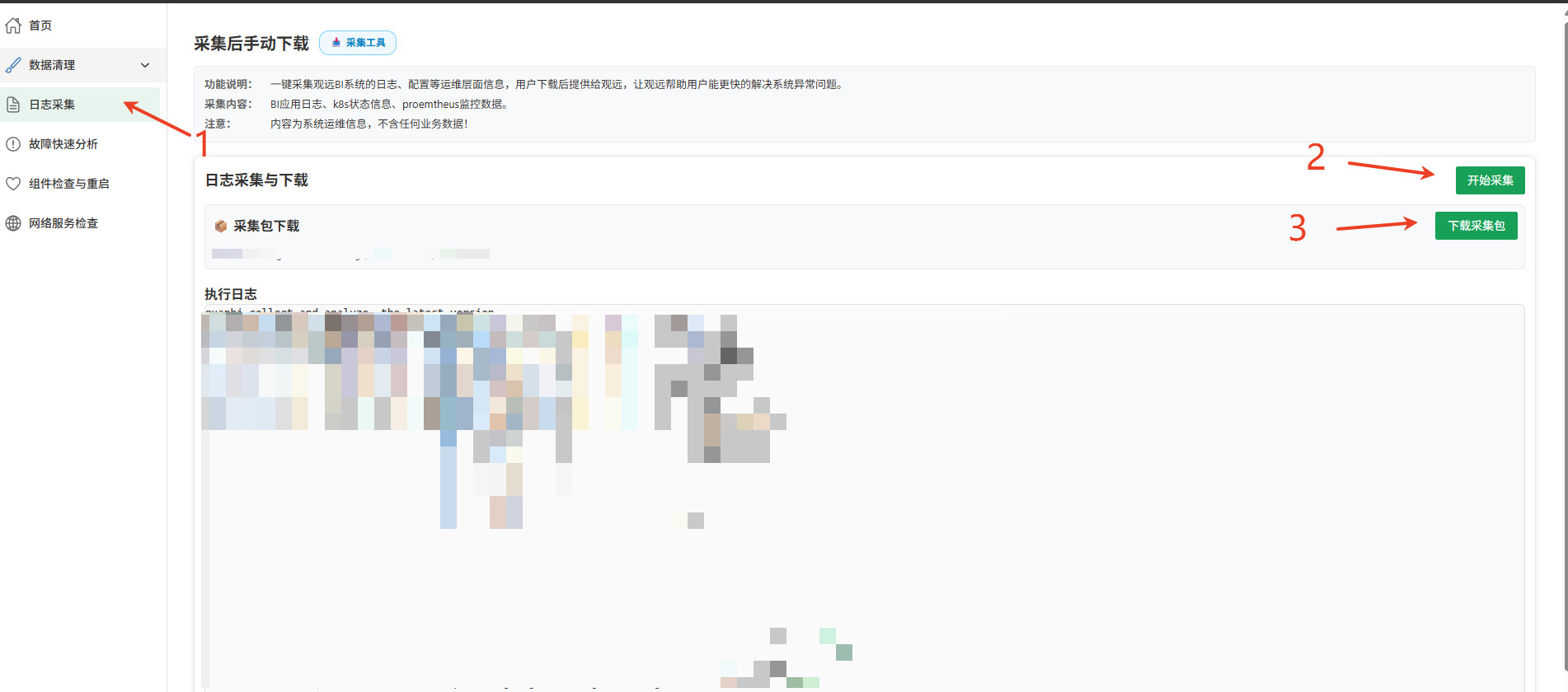
日志采集
核心价值: 当系统发生异常时,快速收集关键的运维诊断信息,打包供下载,便于观远技术支持团队高效定位问题根源。
-
适用场景: 系统出现故障、报错或性能异常时,需要分析原因。
-
操作流程:
- 点击「开始采集」按钮。
- 采集过程通常持续几分钟,请稍作等待。
- 页面显示采集完成后,点击 「下载安装包」 按钮,获取压缩文件。
- 将采集包提供给观远技术支持人员进行分析。
-
采集内容:
- 观远 BI 应用日志(关键报错信息)。
- Kubernetes (k8s) 集群状态信息(Pods, Events 等)。
- Prometheus 监控指标(部分系统状态数据)。
-
安全说明:采集内容仅包含系统运维层面的日志、配置及服务状态信息,不包含任何具体的业务数据。
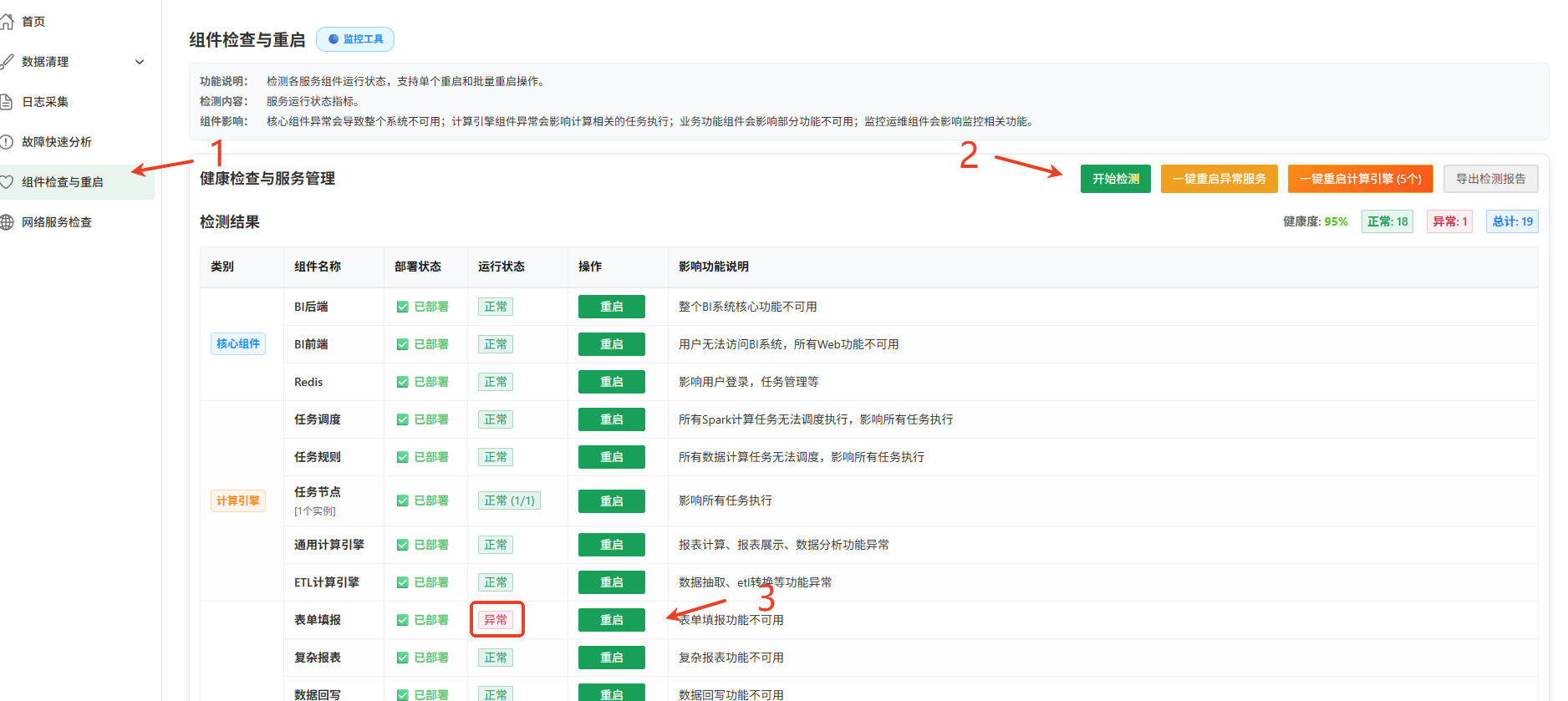
组件检查与重启
核心价值:集中监控观远 BI 系统各服务组件的运行状态,并提供安全、可控的重启操作能力,用于恢复异常组件或进行日常维护。
- 功能要点:
- 点击「开始检测」 按钮,平台自动检查所有组件的实时状态。
- 检测完成后,在列表中清晰展示各组件的健康状态。
- 对于状态异常的组件:
- 可选中组件。
- 点击「重启」按钮。
- 也可主动选中状态正常的组件进行重启(例如任务堵塞想重启释放)。
- 组件影响说明:
- 核心组件: 异常将导致整个 BI 系统不可访问
- 计算引擎组件:异常会影响数据准备、ETL、卡片等任务执行。
- 业务功能组件:异常会影响特定功能模块。
- 监控运维组件:异常主要影响监控数据的收集和展示。
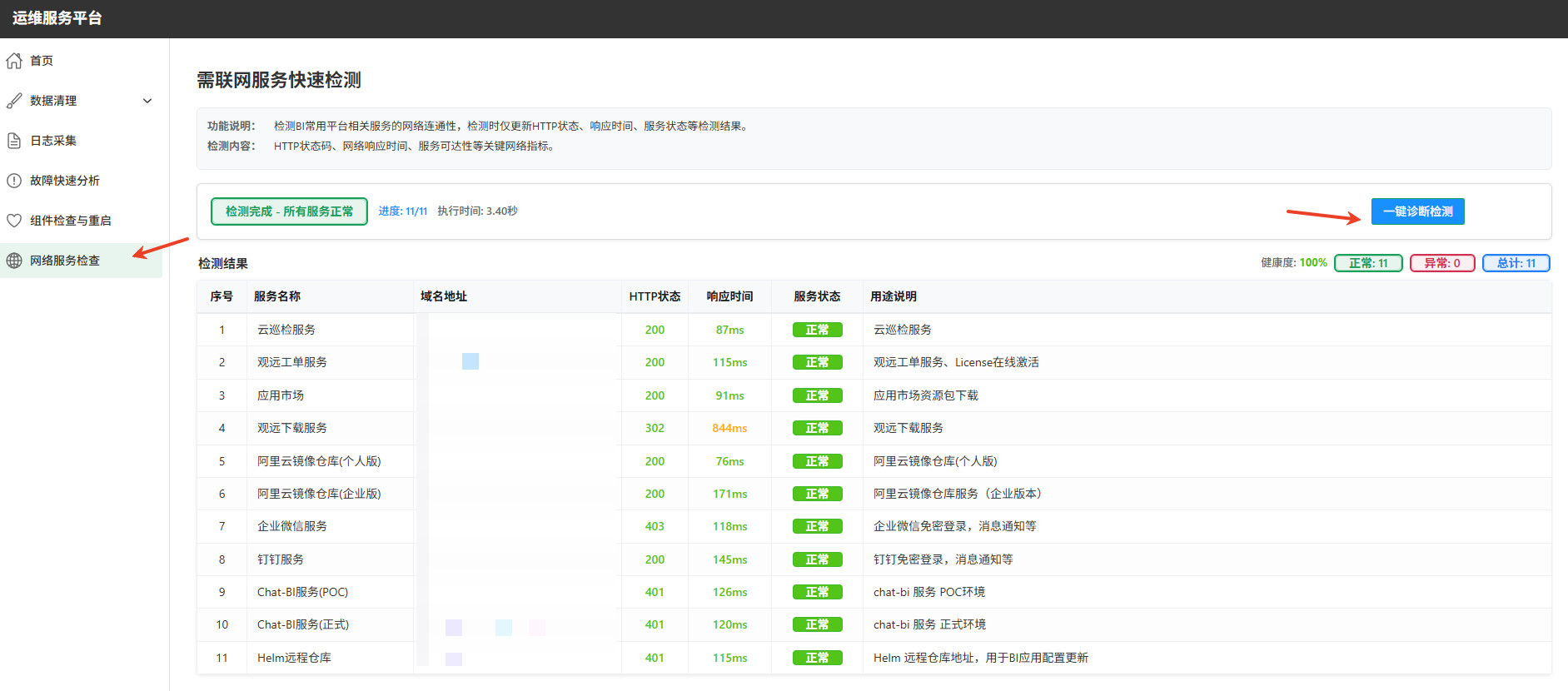
网络服务检查
核心价值:快速验证 BI 系统常用依赖服务或外部接口的网络连通性与可用性,缩小网络故障排查范围。
- 操作流程: 点击「一键诊断」按钮,启动检测。
- 检测结果展示: 平台自动刷新并显示以下关键指标:
- 服务名称: 被检测的服务/URL。
- HTTP 状态码: 如 200(成功)、403(禁止)、502(网关错误)、超时 (无响应)。
- 网络响应时间: 从发起请求到收到第一个响应字节的延迟(ms)。
- 服务状态: 总结性标识:「正常」、「异常」。
- 特性:每次点击诊断仅执行一轮检测并更新结果,不进行持续监控。主要用于主动探测。
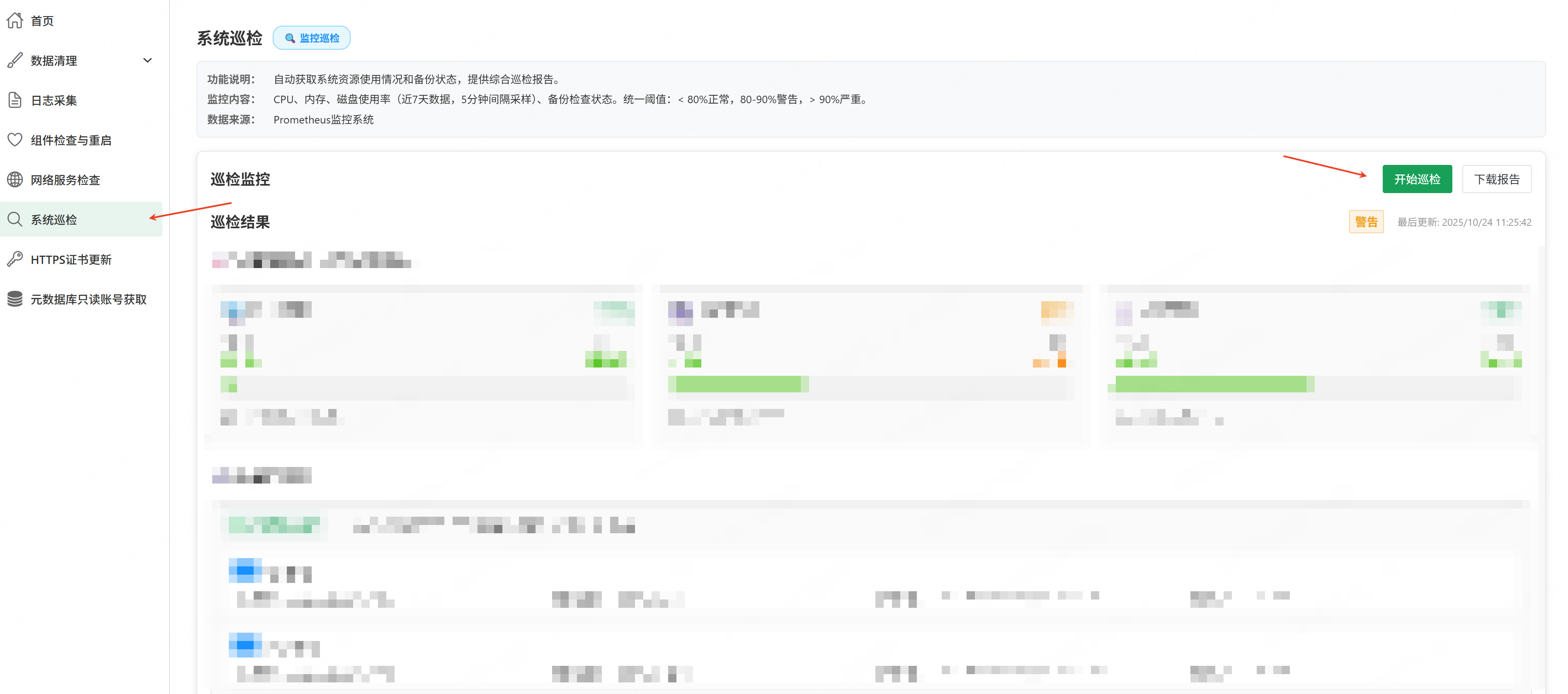
系统巡检
核心价值:自动获取近 7 天资源使用率、备份检查状态,一键生成巡检报告(Word),提供综合健康结论与整改建议。
-
巡检内容:
- 资源使用率:CPU/内存/磁盘(5 分钟间隔采样;阈值:<80% 正常、80–90% 警告、>90% 严重)。
- 备份检查:是否有备份、记录数、主机数、最新备份时间。
- 巡检建议:根据资源与备份情况生成等级化建议;结合故障分析结果为优先级问题给出建议。
-
报告样式(Word):
- 资源状态:正常标绿、警告标黄、严重标红。
- 备份状态:有备份标绿、无备份标红。
- 故障项优先级:High 红、Medium 黄、Low 绿(页面同样着色显示)。
-
操作流程:
- 点击「开始巡检」按钮。
- 等待完成后,可在页面查看巡检信息,或者点击「下载报告」获取 Word 文档。
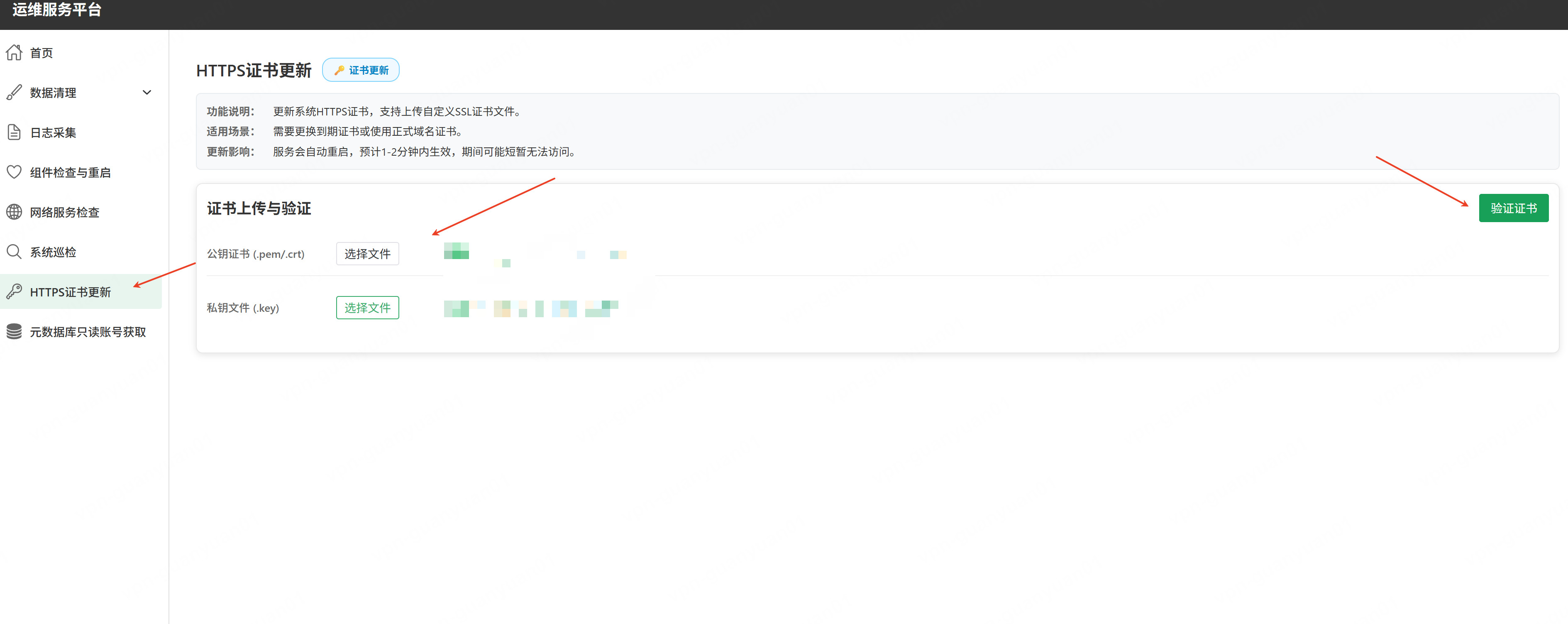
HTTPS 证书更新
核心价值:通过 Web 界面安全更新平台 HTTPS 证书。
-
使用场景:证书即将过期或需要更换新的证书。
-
操作流程:
- 在证书管理页面上传新的证书与私钥。
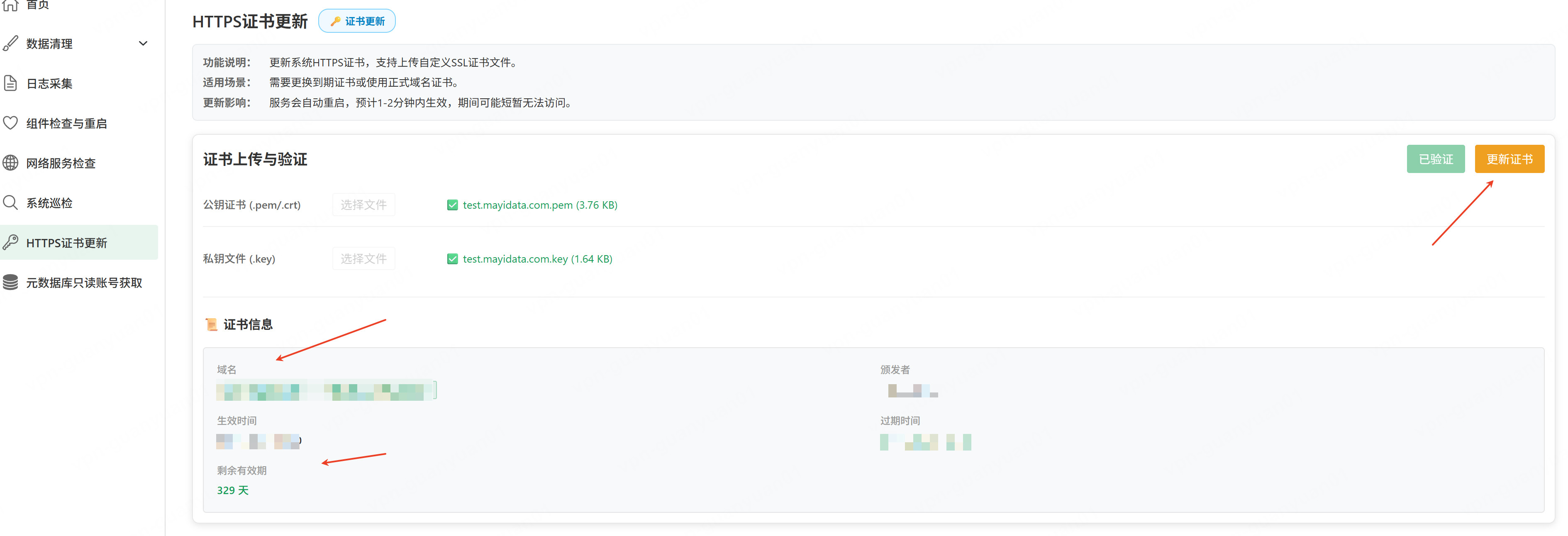
- 点击「验证证书」按钮,确认域名和过期时间是否正确
- 若无误,则点击「更新证书」,平台自动完成替换与服务重启。
- 页面显示更新进度与结果(含等待服务重启提示)。
-
风险提示:更新过程可能短暂影响外部访问,建议在业务低峰期进行。
若检测到非标部署则会提示「未检测到 nginx-proxy 服务,无法使用证书更新功能」。
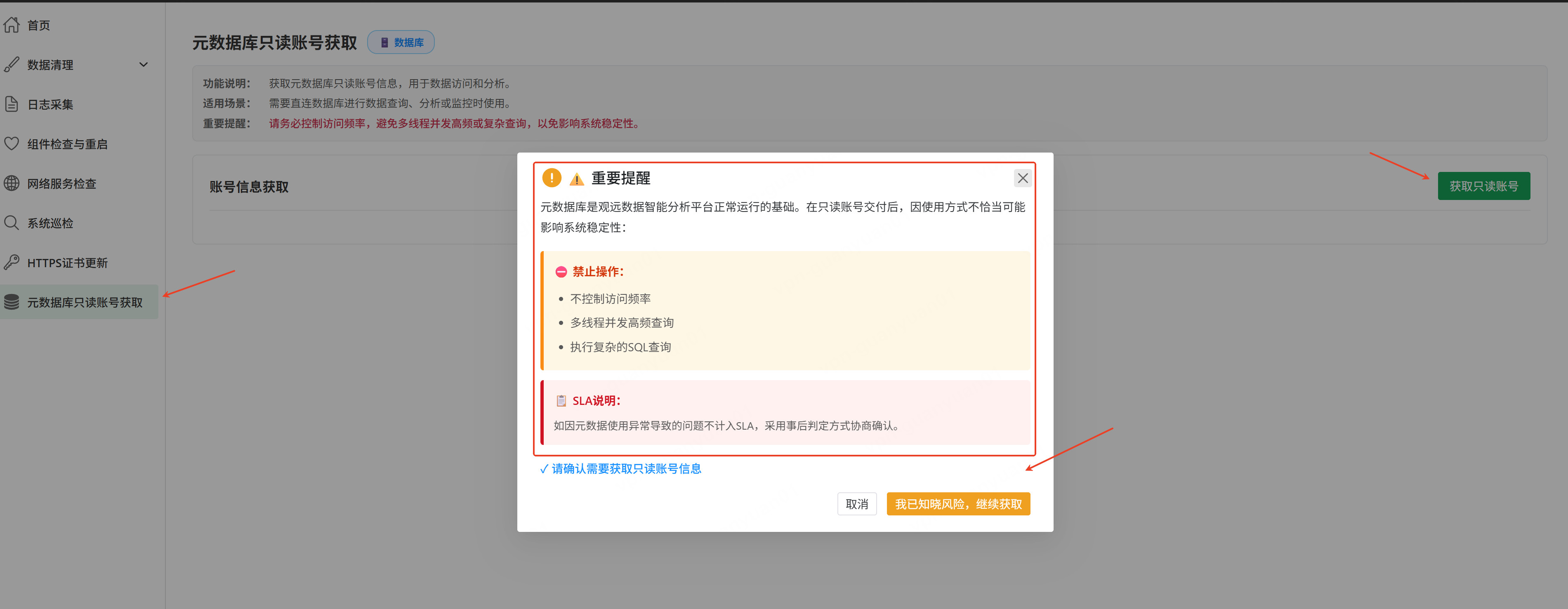
元数据库只读账号获取
核心价值:为只读分析使用提供安全合规的数据库账号。
-
使用场景:需要查询系统元数据用于分析和诊断,但不进行写操作。
-
操作流程:
- 打开「只读账号」页面,点击「获取只读账号」按钮。
- 仔细查看风险提示,确认无误,点击「获取」按钮。
-
安全说明:请务必控制访问频率,避免多线程并发高频或复杂查询,以免影响系统稳定性。