通用设置
概述
通用设置为系统管理员提供全局性的配置管理能力,涵盖系统运行规则设置、运行参数设置、导出设置、驱动与连接器设置及管理员联系人设置,确保系统在满足企业安全规范的同时保持最优运行状态。
系统规则设置
针对企业数据的差异化安全性规范,产品提供多类开关,允许管理员按需进行开启或者停用:
页面
管理员可自行选择是否开启相应页面功能。

数据集
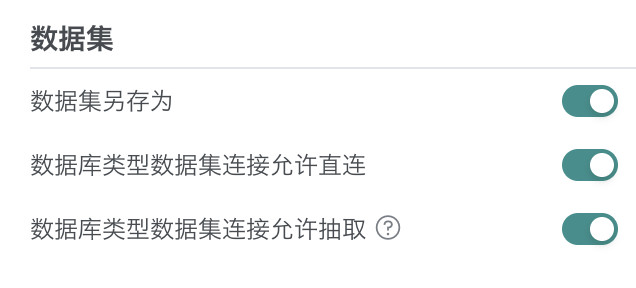
- 是否允许数据集另存为;
- 数据库类型数据集连接是否允许直连;
- 数据库类型数据集连接是否允许抽取。
- 对于仅支持抽取类型的数据库类型(MongoDB、SAP BW、DLI、Spark 和 Access 类型),不受「数据库类型数据集连接是否允许抽取」开关控制影响。
- 「数据库类型数据集连接是否允许直连」与「数据库类型数据集连接是否允许抽取」开关无法同时关闭。
智能 ETL
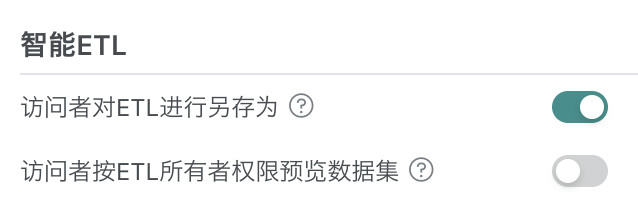
- 是否允许 ETL 访问者对 ETL 进行另存为;
- 是否允许访问者按 ETL 所有者权限预览数据;
数据格式批量设置
为了减少跨卡片、页面重复设置百分比格式的问题,支持在管理后台统一配置数据格式。
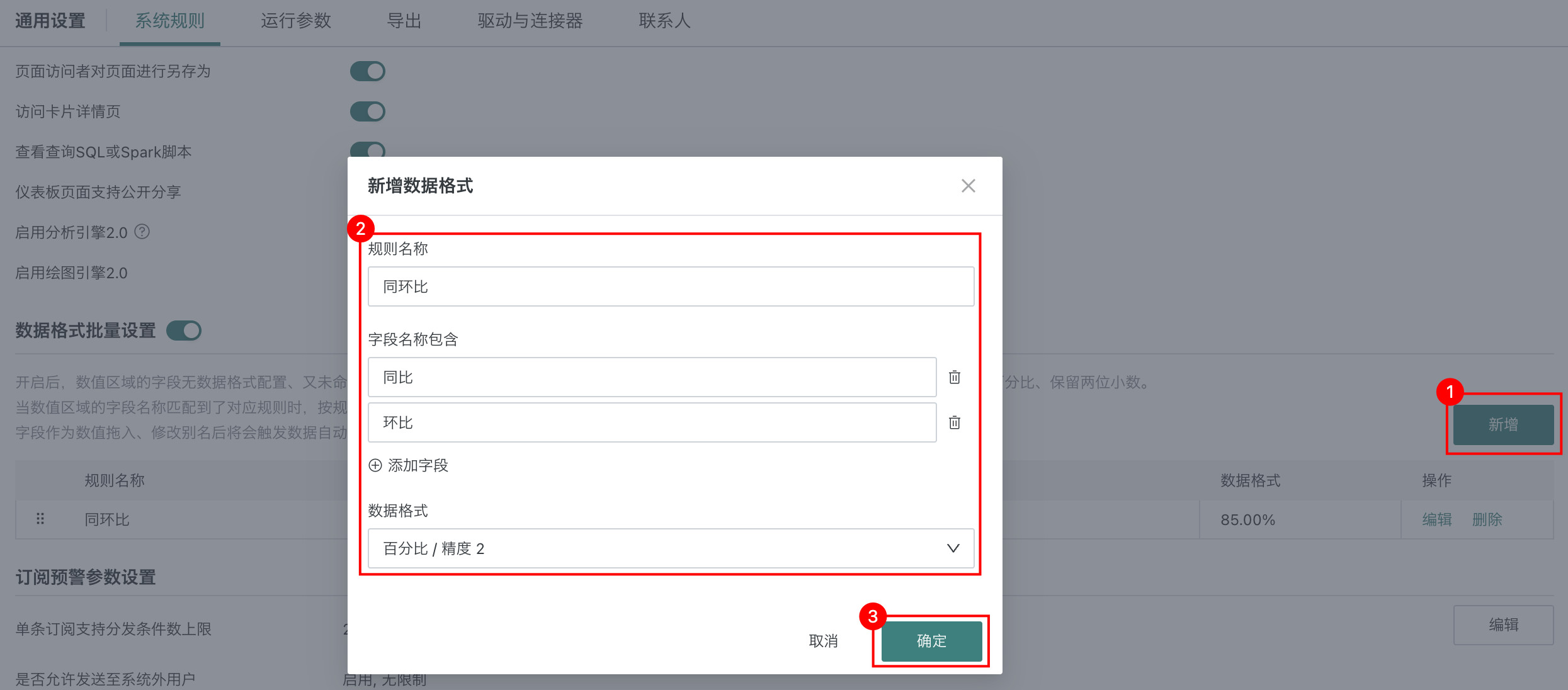
新增数据格式
点击「数据格式批量设置」区域右侧「新增」,按下图配置完成后点击「确定」。新增的数据格式支持编辑、拖拽排序与删除。
最多支持添加10条数据格式。
数据格式匹配规则
- 默认为关闭状态。开启后,数值区域的字段无数据格式配置、又未命中设置的匹配规则时,对该字段设置高级计算(同环比-增长率、占比、重复率)后,会自动将数据格式设置为百分比、保留两位小数。
- 当数值区域的字段名称匹配到了对应规则时,按规则中设置的数据格式生效;若匹配到了多条,则按其列表顺序取第一条生效。
- 字段作为数值拖入、修改别名后将会触发数据自动匹配规则;已有数据格式配置的字段不适用。
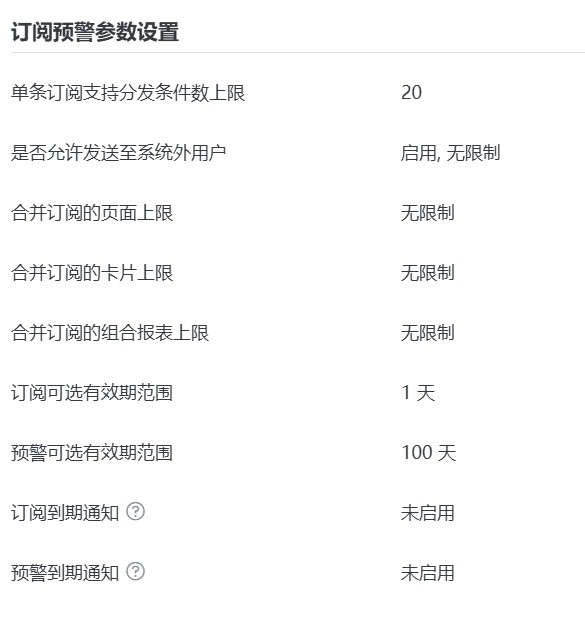
订阅预警参数设置
-
单条订阅支持分发条件数上限:配置单条订阅支持分发的条件数限制,此处配置上限为 100。
-
是否允许发送至系统外用户:启用后,订阅预警支持通过邮箱发送至系统外用户,若指定邮箱后缀则配置外部邮箱后缀校验,不指定邮箱后缀则勾选「无限制」。
-
合并订阅的页面/卡片/组合报表上限:配置单次创建合并订阅的页面/卡片/组合报表数量,默认无限制,可修改。
说明若配置了合并订阅的数量上限,在创建合并订阅时,添加的页面/卡片/组合报表达到了上限,则不允许添加,保存时也会进行校验,若到达上限则提示(以页面为例):已达到合并订阅支持添加页面数量的上限,不允许添加。
-
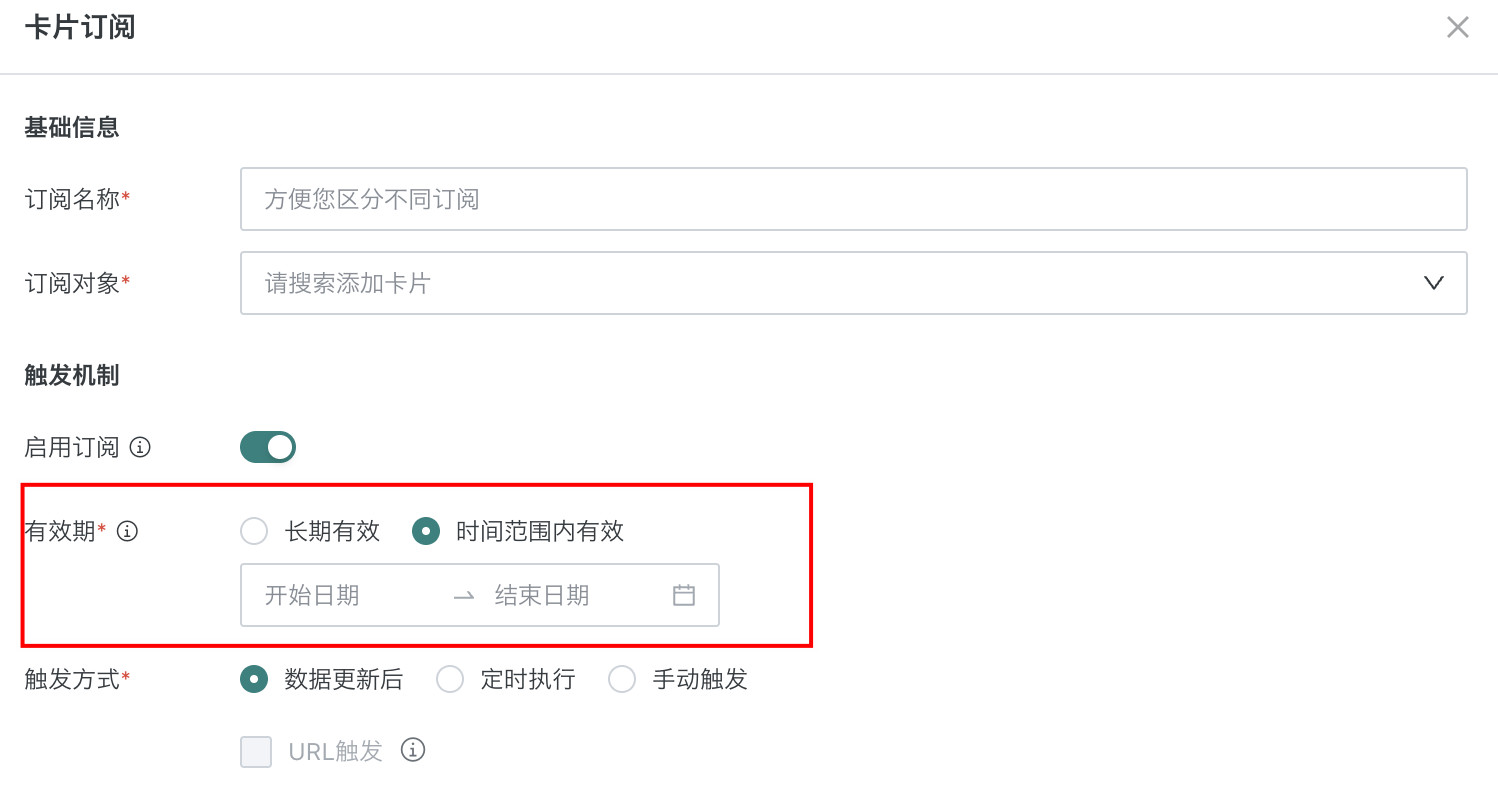
订阅/预警可选有效期范围:默认为长期有效,若设置了有效期天数,则以设置的有效期为准。

系统设置有效期后,在订阅预警配置页面的有效期可选范围不可超过系统设置的上限。
-
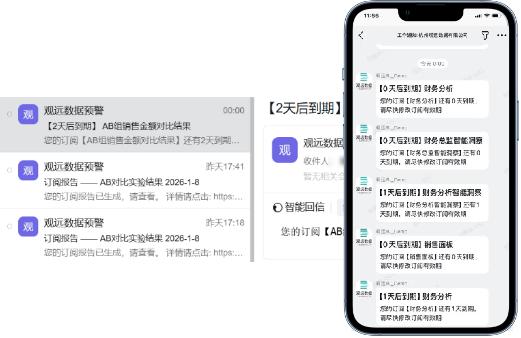
订阅/预警到期通知:默认关闭,手动开启后,需要设置开始通知时间。
说明- 仅当触发方式为「数据更新后」与「定时执行」的订阅预警才需要发送到期通知。
- 仅启用的订阅预警在截止到需要提示的当天开始,使用订阅渠道通知(邮件/各渠道的消息通知)订阅的创建人。

到期通知效果如下:
离线开发参数设置
当离线开发实例的不活动时间达到或超过设定的天数(默认为 180 天)时,系统将自动对其进行清理操作。

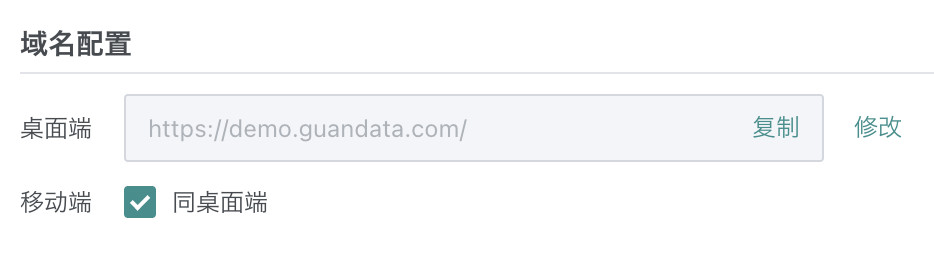
域名配置
支持配置环境域名,将影响轻应用链接、订阅预警、第三方集成中应用主页链接等自动生成链接的功能。
如为移动端、PC 端域名不一致的客户,支持在这里分别为两个端口设置对应域名。
该设置为环境级别的,如多域环境,任一一个域的修改会影响到其它域。当前仅主域可以配置。
地图服务配置
系统支持在管理中心统一配置图表地图服务地址,满足企业对地图服务合规性、私有化部署或统一服务的管理需求。
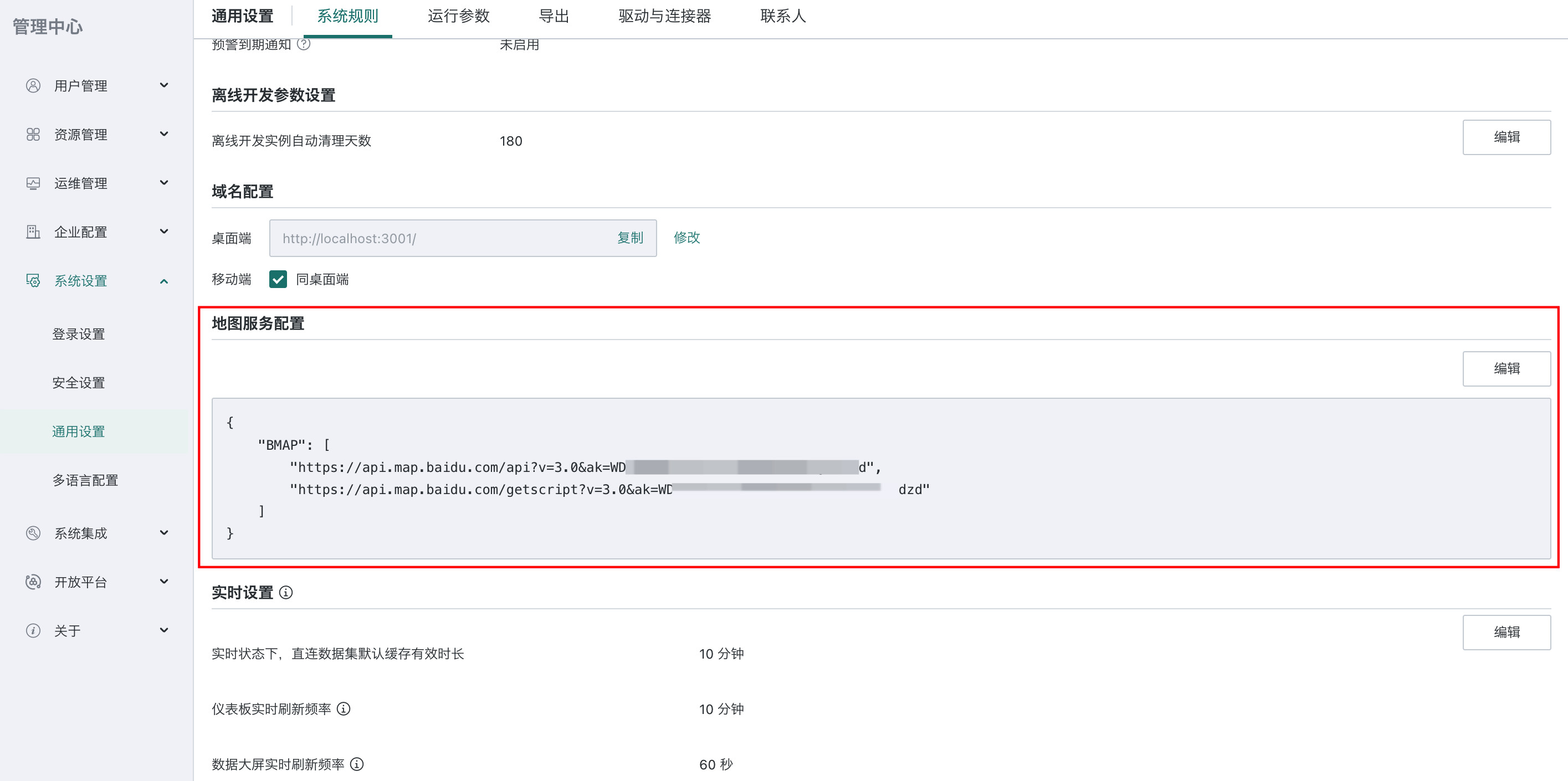
- 默认地图服务:图表属性区域的「地图显示设置」中默认提供高德地图服务。
- 自定义地图服务:如需使用自定义地图服务(如替换为自有部署的地图服务),管理员可在「地图服务配置」区域填写自定义服务地址。
配置方式与优先级
自定义地图服务支持以下两种方式,二者同时存在时优先使用管理中心配置。
| 配置方式 | 生效范围 | 操作路径 | 适用场景 |
|---|---|---|---|
| 管理中心配置 | 仅对当前域生效 | 管理中心 > 系统设置 > 通用设置 > 地图服务配置 | 需按域独立配置地图服务 |
| 运维配置 | 平台全局生效 | 由运维人员修改服务器端配置文件 | 需平台级统一部署地图服务 |
百度地图配置
7.4及以上版本,图表属性区域的「地图显示设置」中默认仅支持高德地图。
若需使用百度地图,管理员可在「地图服务配置」中补充配置百度地图服务地址,具体地址获取方式参考 百度地图配置指南。
影响说明
- 7.4以下版本已创建且使用百度地图的图表卡片,升级版本后若未进行自定义配置,默认将切换为高德地图展示;若仍需使用百度地图,需管理员在「地图服务配置」中补充配置百度地图服务地址。
- 高德地图不受影响。
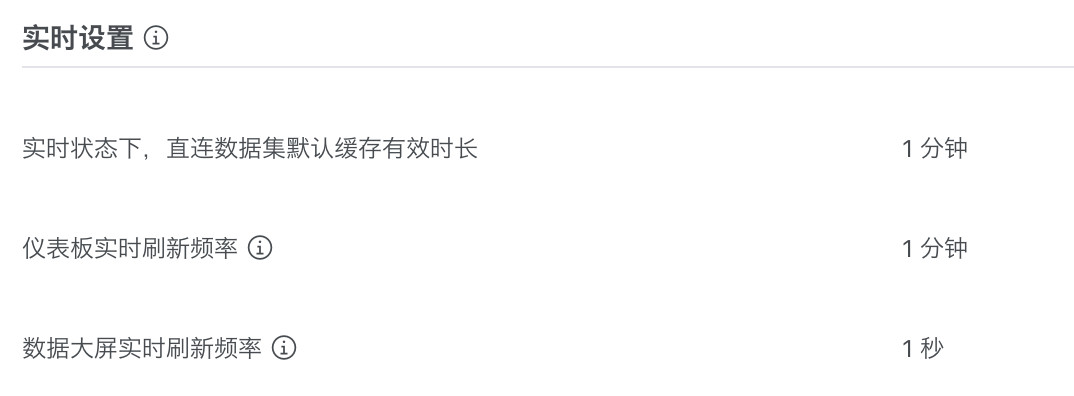
实时设置
实时设置,可对「实时状态下的直连数据集默认缓存有效时长」、「仪表板实时刷新频率」、「数据大屏实时刷新频率」进行设置。实时状态下的直连数据集,默认缓存有效时长可进行分钟级的设置,仪表板实时状态下刷新频率与直连数据集的默认缓存有效时长一致,数据大屏实时刷新频率可进行秒级的设置。
运行参数设置
运行参数配置包括 ETL 参数配置、Spark 参数配置和卡片参数设置、数据集参数配置、数据库参数设置、回收站参数设置、线程池优化、离线开发参数设置和数据回写参数设置。
通常在企业中,用户在白天更多会关注在查数,因此对于超时任务的控制需要更严格,为了避免白天的 ETL 运行占用性能,则需要对白天的时间段进行参数管控(如大于 5 分钟 kill)。到了夜晚,用户通常不再进行高频率的数据分析等工作,因此 BI 平台的使用人数较少,适合另外设置参数(如大于 120 分钟再 kill)。
ETL 参数配置

- 调用任务并行数:控制系统同时执行的 ETL 调度任务数量,当前设置为 20,用于平衡系统负载和处理效率。
- 任务最大运行时长:可勾选特殊时段,勾选之后即进入到特殊时段的参数设置页面,可以根据业务需要对运行时长进行配置。
- 最大支持节点数:定义 ETL 流程中允许使用的最大节点总数,可以输入具体限制值,也可以勾选「无限制」选项。
- 最大支持「关联数据」节点数:限制 ETL 流程中可使用的「关联数据」类型节点的最大数量,可以输入具体限制值,也可以勾选「无限制」选项。
- 最大支持「SQL 输入」节点数:限制 ETL 流程中可使用的「SQL 输入」类型节点的最大数量,可以输入具体限制值,也可以勾选「无限制」选项。
- 最大支持「行拼接」节点数:限制 ETL 流程中可使用的「行拼接」类型节点的最大数量,可以输入具体限制值,也可以勾选「无限制」选项。
- 最大输出数据集个数:控制单个 ETL 任务可生成的输出数据集的最大数量,可以输入具体限制值,也可以勾选「无限制」选项。
- ETL 中间结果缓存:控制系统是否保留 ETL 处理过程中的中间结果,当前已启用,可输入范围为 50-999,用于优化重复计算和调试需求。
- ETL 历史版本个数:控制系统保留的 ETL 流程历史版本数量,当前设置为 10,方便追踪变更和版本回滚。
Spark 参数配置

Spark 单 job 超时时间:限制单个 Spark 作业的最长执行时间,支持设置需要额外处理的特殊时段。最大设置为 120 分钟。
卡片限制参数设置

-
非直连卡片运行超时时长(秒):限制非直连卡片单次运行的最长时间。
此项设置仅作用于 Guan-Index 类型的卡片,运行时长不包含排队时间,实际运行超时后将自动失败 -
直连卡片运行超时时长(秒):当存在直连卡片运行时长超过设置时,系统将自动取消本次运行。
此项设置仅作用于部分数据库:MYSQL, POSTGRESQL, GREENPLUM, SQLSERVER, MAXCOMPUTE, IMPALA -
编辑非直连卡片时支持自动刷新的数据集行数上限(万):控制编辑非直连卡片时系统自动刷新的数据量上限。
-
编辑直连卡片时支持自动刷新的数据集行数上限(万):控制编辑直连卡片时系统自动刷新的数据量上限。
-
卡片排队超时取消时长(秒):定义卡片在执行队列中等待的最长时间,超过此时间将自动取消。
-
迷你图支持的维度值上限:限制迷你图组件可展示的维度值数量。
-
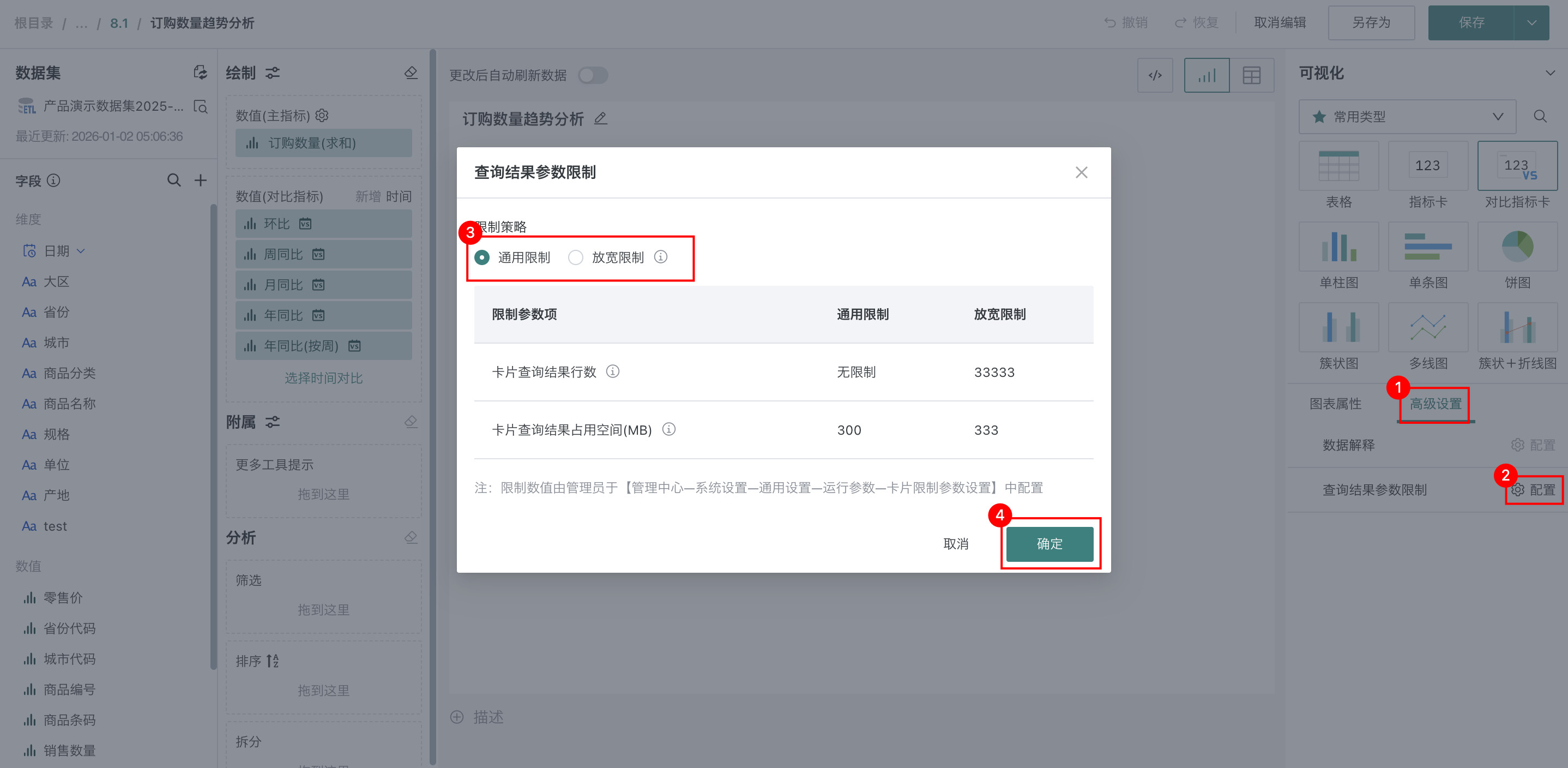
卡片查询结果行数:控制卡片查询时返回结果的最大行数限制。
- 通用限制:可直接输入数值,或勾选「无限制」。若勾选「无限制」,「放宽限制」会自动关闭且无法开启。
- 放宽限制:若已开启放宽限制,调整通用限制数值时,当通用限制数值>放宽限制数值,放宽限制会自动替换为系统最大值。
说明控制卡片查询的最终展示行数,仅作用于卡片查询,不影响卡片导出和数据集查询。设置行数限制后,卡片仍基于全量数据计算,仅前端展示设定的有限行数,数值范围:10000 ~ 无限。
-
卡片查询结果占用空间(MB):卡片查询通过数据量(单位为 M)控制,并支持按照业务需求调整上限。默认限制为 50MB,超出最大值 1024M 限制后,具体表现如下:
- 卡片查看:当参与计算的数据量超出限制时,前端卡片数据不加载,卡片提示报错 「卡片查询数据量已达 xxMB,超出 50MB 限制,请减少数据量或联系管理员进行处理」,此时,管理员可在「管理中心 > 运维管理 > 参数配置 > 卡片参数设置处」,对「卡片查询结果占用空间(MB)」参数调整上限。
- 卡片导出:卡片导出不受该配置影响,在导出上限内,即使卡片查询报错超出上限,仍可以正常导出全量数据。
用户可在「卡片编辑页 > 高级设置 > 查询结果参数限制」页面,选择使用「通用限制/放宽限制」。可视化图表、指标分析、自定义图表、表格填报支持选择此参数限制。
-
卡片数据默认精度值:定义卡片中数值数据的默认显示精度,可配置的数据精度上限为 15 位。
-
卡片中数值区域可拖入的最大字段个数:限制在卡片数值展示区域中可添加的字段数量上限。生效范围:普通卡片中普通表格、表格填报、中国式报表 pro、自定义图表。
-
页面卡片数量限制:限制单个页面中可添加的卡片数量上限,防止因卡片过多导致页面性能下降。默认值为 600,可输入范围为 100-9999。若输入值小于 100,失焦后自动修正为 100;若输入值大于 9999,失焦后自动修正为 9999。当页面中已有卡片数量达到或超过该限制时,用户将无法新建卡片。
数据集参数设置
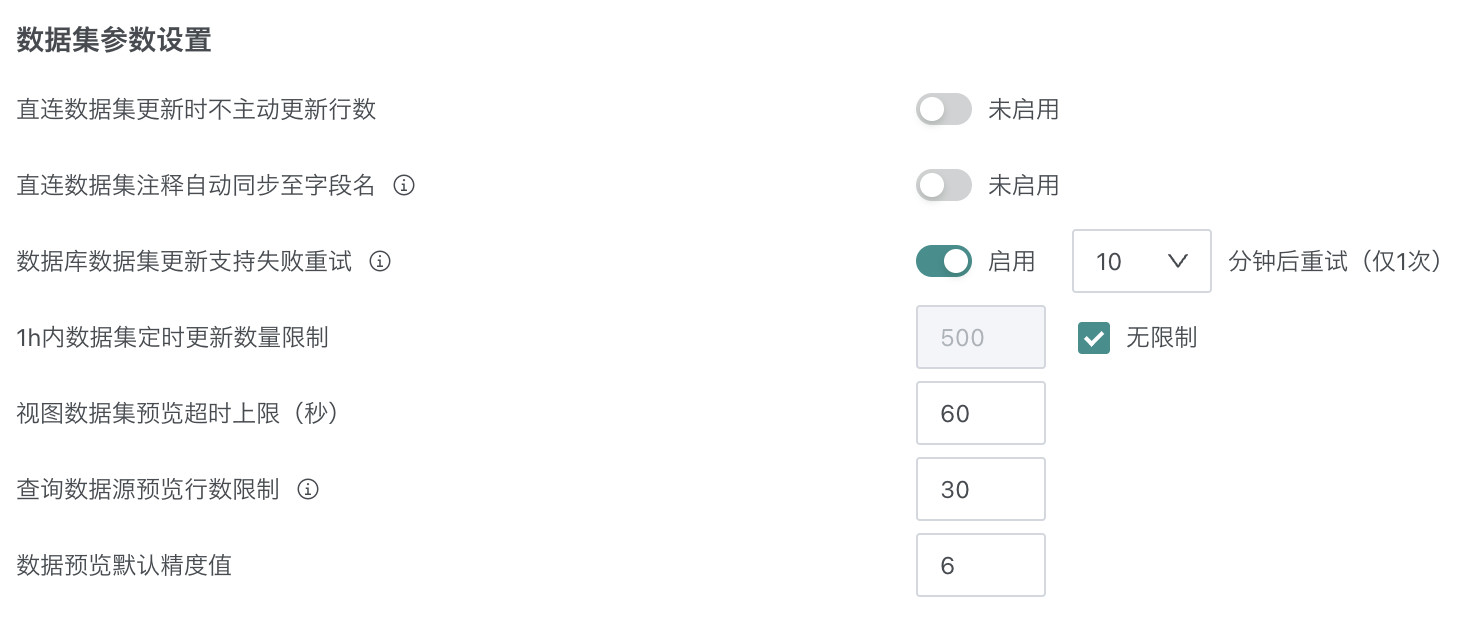
- 直连数据集更新时不主动更新行数:控制直连数据集更新时是否主动更新显示的行数信息。
- 直连数据集注释自动同步至字段名:设置直连数据集的注释信息是否自动同步到对应的字段名称中。
- 数据库数据集更新支持失败重试:配置数据库数据集更新失败后是否进行自动重试。
- 1h 内数据集定时更新数量限制:限制系统在一小时内可以进行的数据集定时更新操作次数。
- 视图数据集预览超时上限(秒):定义视图数据集预览操作的最长允许时间。
- 查询数据源预览行数限制:控制查询数据源时预览结果显示的最大行数。
- 数据预览默认精度值:设置数据预览时数值类型数据的默认显示精度,可配置的数据精度上限为 15 位。
数据库参数设置

- 单个直连数据库连接池上限默认值:设置每个直连数据库连接池可维护的最大连接数。
- 数据库连接超时 (Socket timeout)(分):设置数据库连接在无响应情况下的最长等待时间。
回收站参数设置

自动清理周期(天):设置系统自动清理回收站中已删除数据的时间间隔,每天 23:59 执行清空任务
线程池优化设置

独立管理运行线程池的数据账户:设置用于独立管理和调度系统线程池资源的数据账户。
离线开发参数设置

- 支持运行任务的最大并发数:限制系统中可同时运行的离线开发任务数量。
- 支持运行节点的最大并发数:限制系统中可同时运行的离线开发节点数量。
数据回写参数设置

SR 高性能模式提交间隔(秒):设置 SR 高性能模式下数据提交操作之间的时间间隔。
导出设置
开启「导出控制」后,可配置相关卡片以及数据集导出的配置参数。
- 开关不启用时:在功能权限与资源权限层面均不做额外导出控制,允许用户导出其可以查看的页面与数据集等资源。
- 开关启用时:所有用户默认无法导出相应资源,可以按需给特定用户与用户组配置导出权限;
- 在「角色权限配置」中分配相关功能模块的导出权限;
- 在「资源权限管理」或者各类资源的权限管理窗口中分配「可导出」权限。

导出配置参数如下:
-
卡片数据导出任务时长(秒):编辑启用后可设置任务时长,用于控制抽取数据场景下的数据集的数据导出任务时长
-
卡片导出数据为 Excel 最大行数:设置卡片数据导出为 Excel 格式时的最大允许行数。数值范围:1~1,000,000
-
卡片导出数据为 CSV 最大行数:设置卡片数据导出为 CSV 格式时的最大允许行数。数值范围:1~5,000,000
-
卡片导出表格数据最大行数:设置卡片表格数据导出时的最大允许行数。数值范围:1~1,000,000
-
数据集数据导出任务时长(秒):编辑启用后可设置任务时长,用于控制抽取数据场景下的卡片的数据导出任务时长
-
数据集导出为CSV最大行数:设置数据集导出为CSV格式时的最大允许行数。数值范围:1~5,000,000
-
数据集导出为 CSV 最大行数:设置数据集导出为 CSV 格式时的最大允许行数。数值范围:1~5,000,000
-
数据集导出为 Excel 最大行数:设置数据集导出为 Excel 格式时的最大允许行数。数值范围:1~1,000,000
-
数据集导出最大单元格数:设置数据集导出时的最大允许单元格数量。数值范围:1~50,000,000
-
直连数据集和高性能数据集的导出最大行数:设置直连和高性能数据集导出时的最大允许行数。数值范围:1~100,000
-
数据集订阅 CSV 最大行数:设置数据集订阅为 CSV 格式时的最大允许行数。数值范围:1~50,000,000
-
数据集订阅 Excel 最大行数:设置数据集订阅为 Excel 格式时的最大允许行数。数值范围:1~1,000,000
-
数据集订阅最大单元格数:设置数据集订阅时的最大允许单元格数量。数值范围:1~100,000,000
-
导出pdf是否允许复制:可选择默认允许复制;或用户导出时选择,用户在触发导出PDF操作时,需要手动选择导出的PDF文本是否允许复制
-
页面导出图片清晰度:设置页面导出为图片时的清晰度选项。
注意设置后,导出图片会按照对应清晰度进行导出,调整为更高的清晰度后,图片像素更高数据能展示得更清楚;订阅预警的图片尺寸配置,会直接叠加此处的配置;如果页面卡片数量过多/页面较长,又配置了一个较高的清晰度,可能会导致订阅预警的图片发送失败,请谨慎调整!
-
卡片导出图片清晰度:设置卡片导出为图片时的清晰度选项。
注意设置后,导出图片会按照对应清晰度进行导出,调整为更高的清晰度后,图片像素更高数据能展示得更清楚;订阅预警的图片尺寸配置,会直接叠加此处的配置;如果页面卡片数量过多/页面较长,又配置了一个较高的清晰度,可能会导致订阅预警的图片发送失败,请谨慎调整!订阅时所有卡片都生效;但手动导出图片时,仅对杜邦分析图生效。
-
表格导出自动换行:控制表格数据导出时是否启用自动换行功能。
不自动换行时,即使卡片设置了自动换行,导出时也不做换行处理;自动换行时,卡片设置了自动换行,导出时也需要自动换行。 -
中国式报表 Pro 卡片分页导出模式:设置中国式报表 Pro 卡片分页导出的模式选择。
此开关适用于所有启用分页功能的中国式报表 pro 卡片。 默认为多 Sheet 导出模式,即导出后每个分页的内容将自动分配至独立的 Sheet 中; 若选择单 Sheet 导出模式,则所有分页的内容将被合并至同一个 Sheet 中导出。
驱动与连接器设置
用于集中管理和配置所有与硬件设备通信及物理接口功能相关的参数,确保设备能够被系统正确识别、稳定驱动,并通过相应的物理端口(连接器)实现高效的数据传输与功能控制。
新建配置驱动
-
进入「管理中心 > 系统设置 > 通用设置 > 驱动与连接器」页面。
-
点击「驱动管理 > 新增驱动」按钮,编辑驱动名称,点击「保存」即可完成新建驱动。
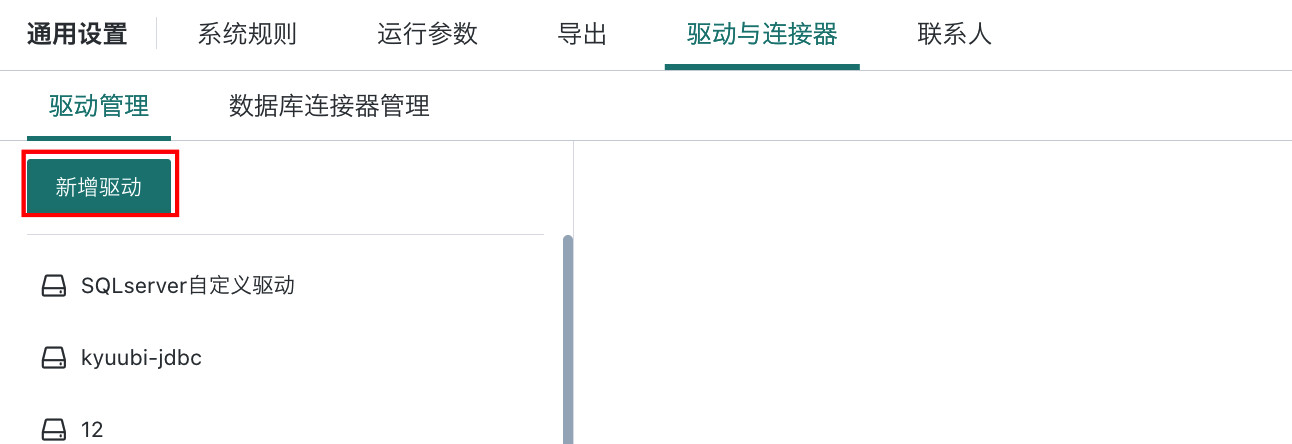
-
点击刚才新建的驱动,上传经过观远认证的驱动 Jar 包及可用的 Driver Class,点击「应用」即可完成驱动配置。
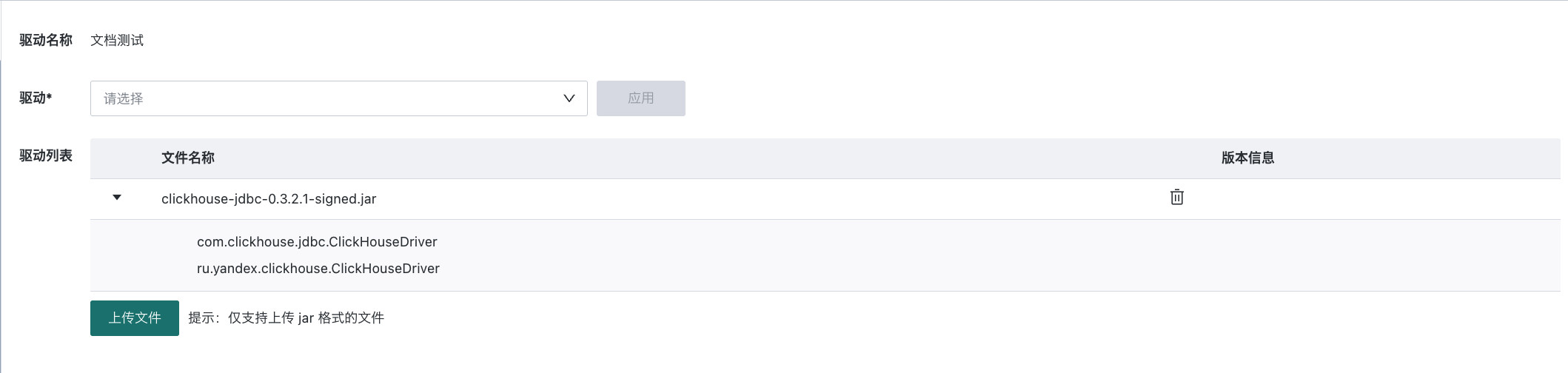 注意
注意系统会自动检测上传的驱动是否为观远认证版本。若上传未认证驱动,系统将提示「自定义驱动jar包不合法,请使用经过签名的驱动包」,此时请前往此处下载认证版本或联系观远技术支持获取认证驱动。
新建配置数据库连接
点击「数据库连接器管理 > 新建数据库连接器」,开始新建数据连接器,如下图所示:
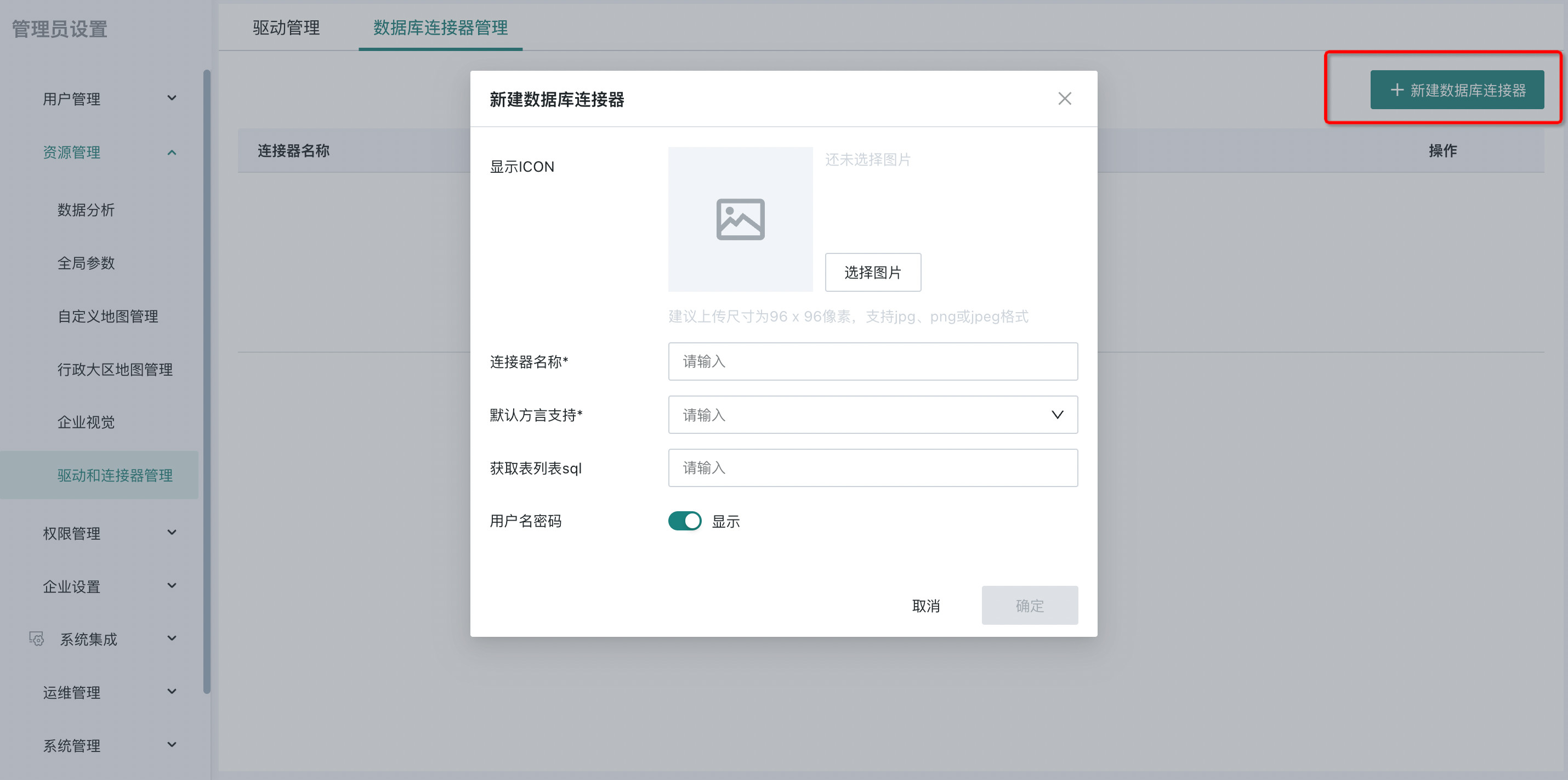
- 参数 1: 显示 ICON,设置自定义数据连接的图片 ICON,用于在数据账户以及数据库数据集新建环节的展示。
- 参数 2: 连接器名称,按照用户习惯自行定义,不支持特殊字符。
- 参数 3: 默认方言支持,目前开放支持的方言有 MySQL、Oracle、POSTGRES,已经验证支持的数据库如下:
| 方言 | 已验证支持的数据库 |
|---|---|
| MySQL | OceanBase(MySQL)、Azure DataBricks、云器 LakeHouse、ByteHouse |
| Oracle | 人大金仓 KES、Oceanbase(Oracle)、Aloudata Air Engine |
| POSTGRES | GaussDB(DWS)、Aws Athena、CnosDB |
- 参数 4: 获取表列表 SQL,不同数据库在表列表获取逻辑上和方言数据库会出现不一致的情况,该功能支持用户按照对应的数据库自定义获取逻辑,指定表列表获取的 SQL 以及返回结果集中表名所在列的 index,已验证的数据库参考如下:
| 序号 | 数据库 | 驱动下载地址 | 表列表获取 SQL |
|---|---|---|---|
| 1 | 人大金仓 KES | 官网kingbaseES下载中心 注:在官网 kingbaseES 下载中心中选择 kingbaseES,根据数据库部署对应机器架构选择下载相应 JDBC 驱动 | {"sql": "SHOW TABLES from |database|", "tableNameIdx": 1} |
| 2 | Azure DataBircks | 官方下载地址 | {"sql": "SHOW TABLES", "tableNameIdx": 2} 会默认查询名为 default schema 下的表 |
| 3 | {"sql": "SHOW TABLES IN |schema|", "tableNamfeIdx": 2},需要在创建账号时候有额外表单项 schema,查询指定 schema 下表 | ||
| 4 | 云器 LakeHouse | 官方下载地址 | 若 JDBC URL 中指定了 schema(例如:schema=public),则语句为:{"sql":"SHOW TABLES", "tableNameIdx": 2} |
| 5 | 如果没有指定,则为:{"sql": "SHOW TABLES IN |schema|", "tableNameIdx": 2},并在创建账号时候有额外表单项 schema | ||
| 6 | OceanBase(MySQL) | 官方下载地址 注:根据 CPU 架构选择下载 | {"sql": "SHOW TABLES", "tableNameIdx": 1} |
| 7 | OceanBase(Oracle) | 官方下载地址 注:根据 CPU 架构选择下载 | {"sql": "SHOW TABLES from |database|", "tableNameIdx": 1} |
| 8 | Aloudata Air Engine | 联系官方支持获取 | {"sql": "SHOW TABLES IN |schema|", "tableNameIdx": 1} |
| 9 | CnosDB | 联系官方支持获取 | {"sql": "SHOW TABLES", "tableNameIdx": 2, "withSchemaPrepend": true, "schemaOrDatabaseNameIdx": 1} |
| 10 | GaussDB-DWS | 联系官方支持获取 | {"sql": "SHOW TABLES from |database|", "tableNameIdx": 1} |
| 11 | Aws-Athena | 官方下载地址 | {"sql": "select "table_name" from "information_schema"."tables" where (lower(cast("table_catalog" as varchar)) = |catalog| and lower(cast("table_schema" as varchar)) = |database|) order by "TABLE_NAME"", "tableNameIdx": 1} |
| 12 | ByteHouse 云数仓 | 官方下载地址 注:官方驱动 github 仓库有直接下载链接 | {"sql": "SHOW TABLES from |database|", "tableNameIdx": 1} 注意:ByteHouse 企业版不能使用云数仓接入,可以直接使用 ClickHouse 连接接入。 |
若表列表获取 SQL 中指定了||schema||参数后,在创建数据账户时候动态展示 schema 选项,由用户输入。
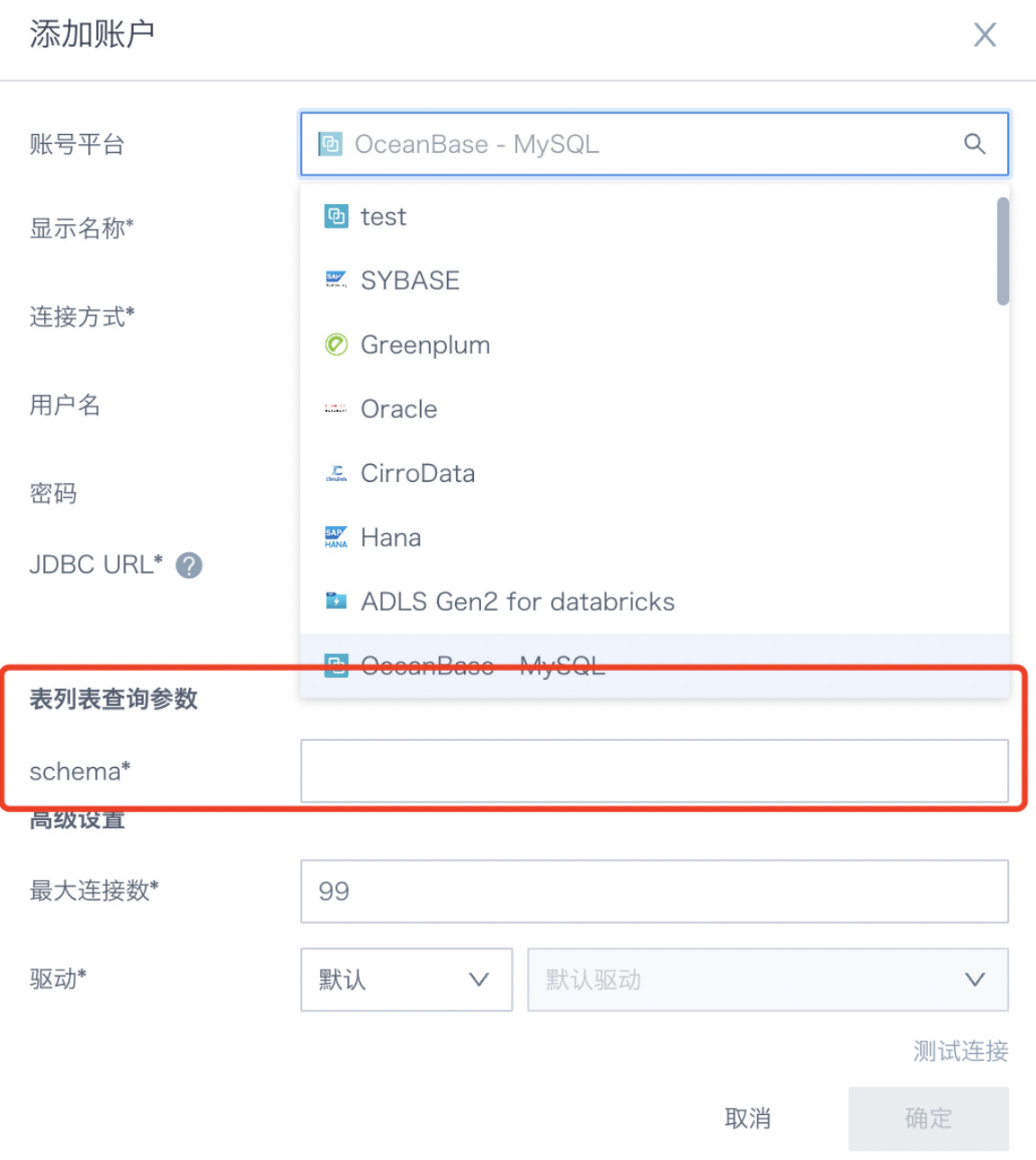
- 参数 5: 用户名密码显示开关,例如 Azure DataBricks 的认证方式中用户名/密码是包含在 URL 中,不支持传统的传参方式,可以通过开关控制是否显示。
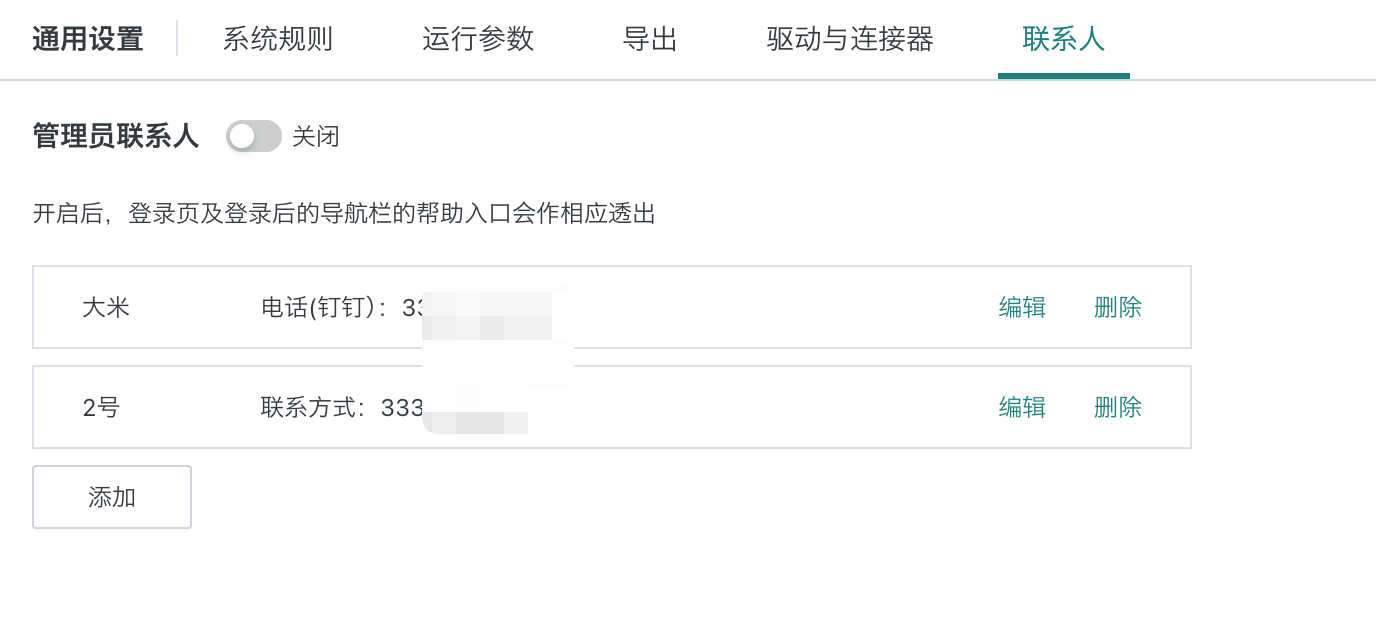
管理员联系人设置
开启后,登录页及登录后的导航栏的帮助入口会做出相应透出,此处可以进行编辑、删除与添加操作。