视图数据集使用方法及案例分享
视图数据集,是基于Spark SQL的可参数化执行的动态数据集,可将非直连数据集进行动态关联与计算,提供更灵活的数据分析方式,解决即席分析场景下的复杂分析问题, 典型应用场景如零售稼动PSD计算。
作用
在卡片和数据集中间增加一层计算,类似于一个subquery。视图数据集先根据定义和源数据集计算出一个中间结果,再用以卡片的展现。具体的作用包括:
-
在视图数据集中添加全局参数,就可以基于参数的值做不同筛选条件下的动态计算。
-
通过视图数据集,同一个源数据集可以在不同颗粒度做聚合计算,从而实现一个源数据集作多个源表来使用。
-
在视图数据集中可以关联多个源数据集,从而实现多表融合,但不占用存储空间。
适用场景
动态筛选:会员标签、销量排名
多表融合:铺店率、欠品率
需要补全日期(拉链表): 售罄率、动销率、消化率
使用前提
-
产品内嵌的免费功能,默认关闭,须联系观远相关人员打开;
-
使用Spark SQL的语法查询非直连数据集 , 使用者需要掌握Spark SQL的基本使用。
使用步骤
- 进入数据中心的数据集界面,点击右上角的“新建数据集”,选择“视图数据集”。
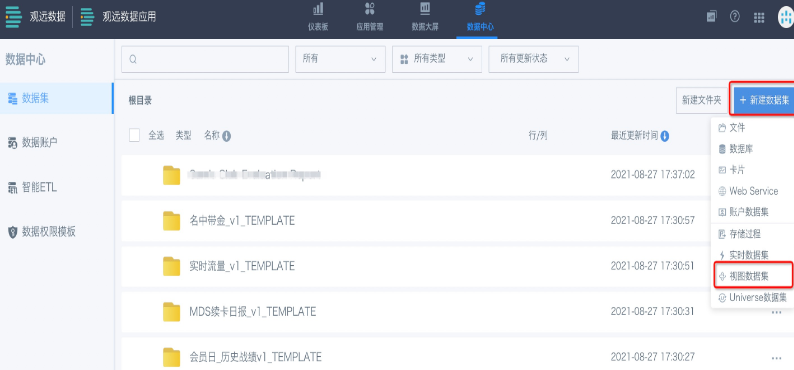
- 进入数据集详情页,点击添加数据集,添加1个或者多个非直连数据集(建议尽量不超过2个)。
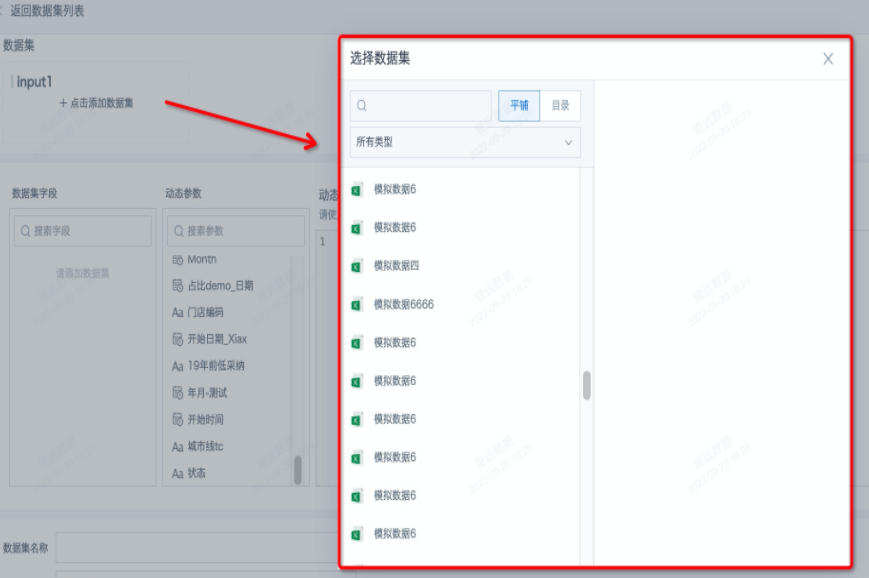
- 输入动态查询SQL,可以从左侧选择“数据集字段”与“动态参数”,完成“动态查询SQL”并预览。动态参数即全局参数,需要提前在管理员设置里添加好。
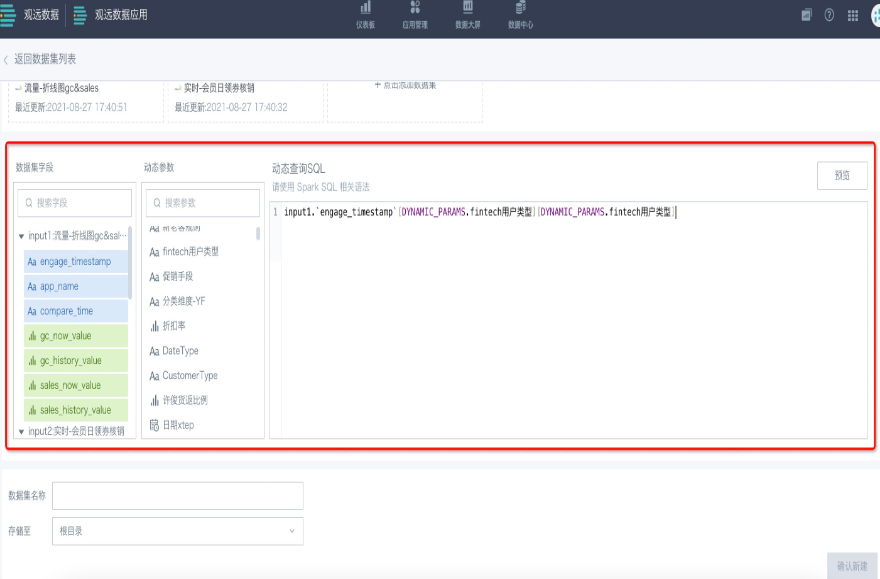
- 指定数据集的名称以及保存位置。点击“确认新建”后,数据集创建成功。在对应的文件夹目录下即可找到该数据集。
注意事项
视图数据集和前端卡片都是基于观远内置的计算引擎,在进行同样计算的时候,需要的时间没有差别。 以下几点有助于保证视图数据集的性能:
1. Smart ETL 提供了非常方便的后端计算功能,所以视图数据集应该仅用于做必须的计算;
2. 前端筛选器的作用发生在视图数据集的计算之后,所以如果不认为这种情况是必须的,那应该尽量通过参数把筛选前置到视图数据集内。
案例
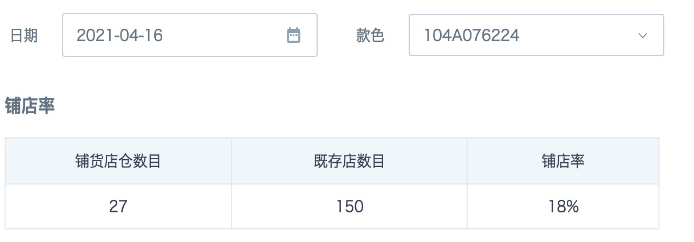
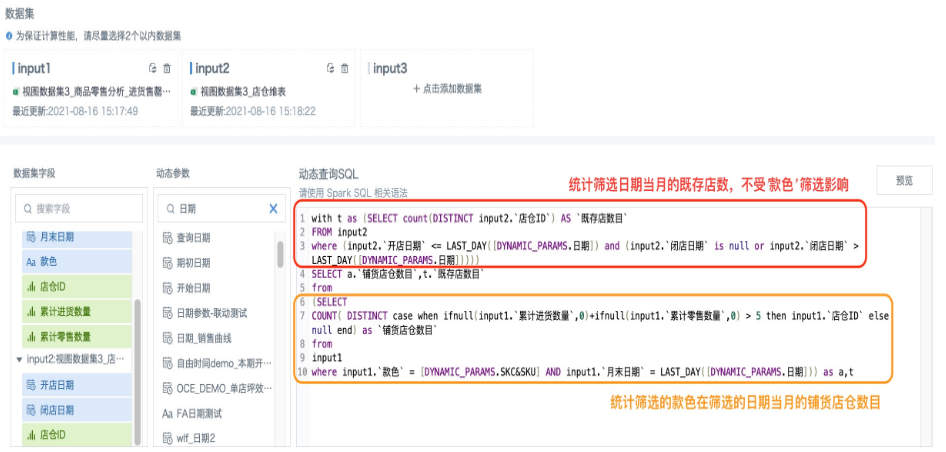
案例一:通过筛选日期、款色计算该款色在所选日期所在月的铺店率
铺店率 = 累计铺货店铺数/既存店数。
场景分析
累计铺货店铺数来源于进货表和零售表,而既存店数需要通过店仓维表来算。
如果不使用视图数据集,需要以店仓维表为主表左关联进货表和零售表,数据会剧烈膨胀。使用视图数据集融合多个数据源,是更为合理的数据组织。
实现方法:
- 创建视图数据集,模型结构如下。
此场景使用了公共表表达式(CTE)定义一个临时结果集t, 用来保存统计得到的筛选日期当月的既存店数,然后在后面SQL语句内引用该结果集。这里既存店数目只受日期筛选影响,铺货店仓数目要受日期筛选和款色筛选同时影响。
with t as (SELECT count(DISTINCT input2.`店仓ID`) AS `既存店数目`
FROM input2
where (input2.`开店日期` LAST_DAY([DYNAMIC_PARAMS.日期]))))
SELECT a.`铺货店仓数目`,t.`既存店数目`
from
(SELECT
COUNT( DISTINCT case when ifnull(input1.`累计进货数量`,0)+ifnull(input1.`累计零售数量`,0) > 5 then input1.`店仓ID` else null end) as `铺货店仓数目`
from
input1
where input1.`款色` = [DYNAMIC_PARAMS.SKC&SKU] AND input1.`月末日期` = LAST_DAY([DYNAMIC_PARAMS.日期])) as a,
t
- 制作卡片,新建计算字段“铺店率”,拖入数值栏,保存卡片。如果预览无数据,可在卡片编辑页面右侧“参数默认值”里暂时输入有效的参数来确保制作时有数据可预览。

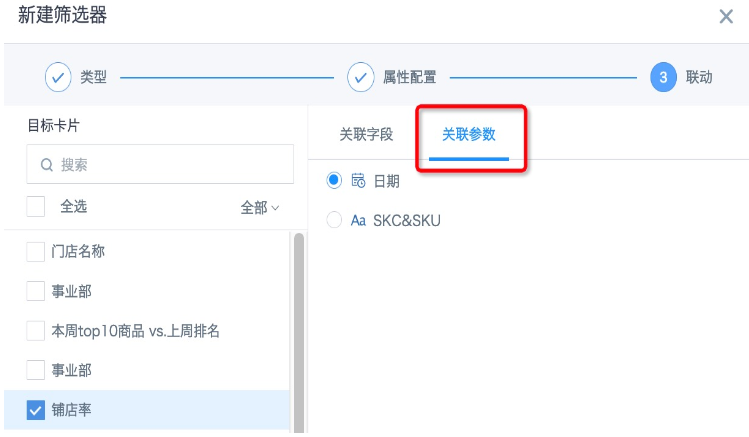
- 回到页面上,新建参数筛选器,选择视图数据集里使用的日期类型参数,保存后可以自动关联上一步新建的卡片;或者新建日期筛选器,联动界面勾选数据集里使用的日期类型参数。同理,为“款色”新建参数筛选器或者选择筛选器并联动。
- 最终效果如下图: