去重计数函数实现开窗
问题描述
常规的去重计数函数为 count(distinct ()),在SQL语句中必须配合 group by 一起使用才能计算出结果。在观远BI里,如果去重计算结果要参与二次计算或者使用时,对 count(distinct ()) 进行开窗计算会报错。
常见报错
未开窗—— Grouping expressions sequence is empty
开窗—— Distinct window functions are not supported
产生原因
在Spark语法中不支持 count(distinct()) 的开窗
解决方案
方案1:ETL里通过「分组聚合+自关联方式」进行去重计数
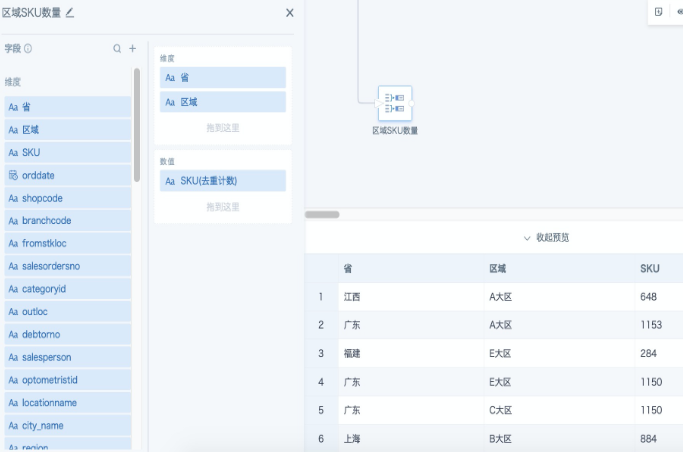
步骤1:添加「分组聚合」节点,维度栏拖入分组字段,把要计算的字段拖入数值栏,聚合方式选“去重计数”。以下图为例,统计每个省每个区域的商品SKU数量。
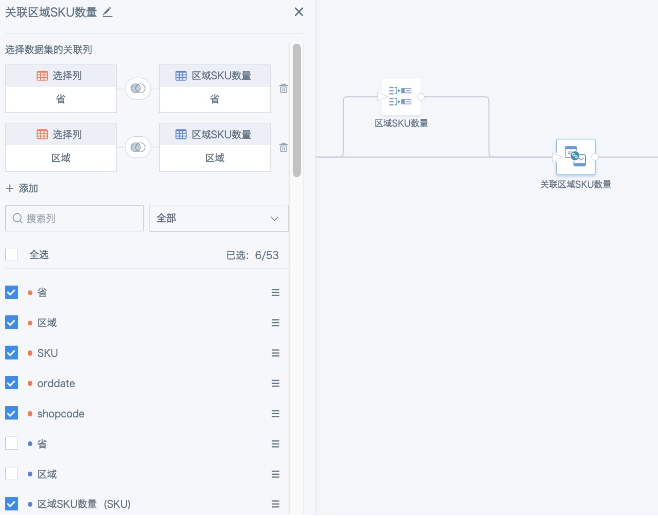
步骤2:添加「关联数据」节点,把原表和上一步分组聚合得到的临时表用维度字段左关联起来。本文案例里关联字段使用“省”和“区域”,把上一步去重计数结果字段改为合适的名字,即得到指定维度的去重计数结果。
注意:「分组聚合+自关联方式」在ETL可以使用SQL节点代替(一般不推荐);SQL语句同时也适用于视图数据集,视图数据集里需要把必要的字段或者筛选条件替换为全局参数使用。SQL写法大致参考以下语句。
SELECT input2.*, t.`区域SKU数量`
FROM input2
LEFT JOIN
(SELECT input1.`省`, input1.`区域`, COUNT(DISTINCT input1.`SKU`) AS `区域SKU数量`
FROM input1
GROUP BY input1.`省`,input1.`区域`) t
ON input2.`省`=t.`省` AND input2.`区域`=t.`区域`
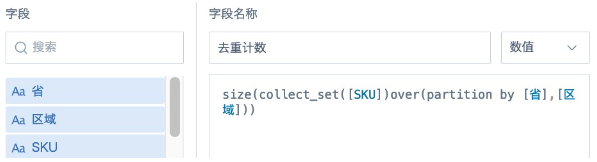
方案2:新建计算字段,使用替代窗口函数
去重计数: size(collect_set([计数字段])over(partition by [分组字段]))
不去重计数:count([分组字段])over(partition by [分组字段])
注意:collect_set()over(partition by ) 函数是用来生成数组 (array) 的窗口函数,要对多行数据按照分组去重然后合并为一行,处理完成后再用 size() 函数统计数组内元素的数量。在数据量大的时候,这个处理过程比较耗资源,耗时也较长。
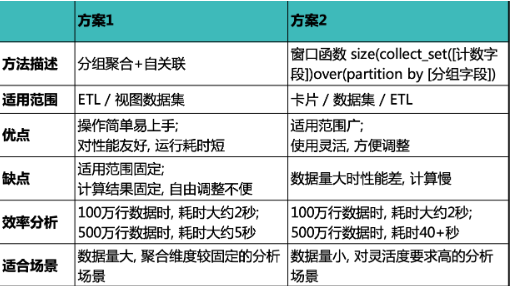
两种方案使用对比如下,请根据自己使用场景和数据量选择合适的方案。