Spark SQL文本函数及应用
1. 基本字符串操作
用途 | 函数 | 举例 | 结果 |
判断是否为null值 | isnull() | true/false | |
判断是否非null值 | isnotnull() | true/false | |
判断null值并替换null值 | ifnull(expr1, expr2) | ifnull(null,0) | 0 |
返回第一个非null值的值 | coalesce(expr1, expr2, ...) | coalesce(NULL, 1, NULL) | 1 |
返回字符串的长度 | length() | length('ABC DE') | 6 |
将英文字符串转为首字母大写 | initcap() | initcap('ABC DE') | Abc De |
将英文字符串转为小写 | lcase()/lower() | lcase('ABC'); lower('ABC') | abc |
将英文字符串转为大写 | ucase()/upper() | ucase('abc'); upper('abc') | ABC |
将字符串反转 | reverse() | reverse('abc') | cba |
将其他类型转换为字符串 | string() | string(123) | 123 |
cast( expr as string) | cast(123 as string) | 123 |
2. 字符串查找
用途 | 函数 | 举例 | 结果 |
返回第一次匹配到的字符串所在位置 | locate(substr, str[, pos]) [, pos]用来指定起始查询位置,可省略。 | locate('n','Ann',3) | 3 |
instr(str, substr) | instr('Ann','n') | 2 | |
find_in_set(str, str_array) 被查询字符串是以逗号隔开的字符串。 | find_in_set('ab','abc,b,ab,c,def') | 3 | |
返回正则匹配到的第一个子串 | regexp_extract(str, regexp[, idx]) | regexp_extract('*A1B2*C3**','[A-Z]+',0) | A |
模糊匹配指定模式的字符串,返回 true/false。需结合通配符使用。 | like | 'A&B' like '%&%'; 'A&B' like '&%' | true; false |
模糊匹配指定模式的字符串,返回 true/false。需结合正则表达式使用。 | rlike | 'PURE&MILD' rlike '[A-Z]+\&[A-Z]+' | true |
3. 字符串截取
| 用途 | 函数 | 举例 | 结果 |
| 字符串截取,截取长度[, len]省略时截取指定位置开始的所有字符 | substr(str, pos[, len]) ; substring(str, pos[, len]) | substring('123abcABC', 2, 3); substr('Spark SQL', -3) | 23a; SQL |
| 返回字符串中在第 n 个出现的分隔符之前的子串。n 是负数时,返回从右边开始第 -n 个分隔符到右边所有字符。 | substring_index(str, delim, n) | substring_index('a.b.c.d.e', '.', 2); substring_index('a.b.c.d.e', '.', -2) | a.b; d.e |
| 从左侧开头处截取固定长度字符串 | left(str, len) | left('Spark SQL', 3) | Spa |
| 从右侧结尾处截取固定长度字符串 | right(str, len) | right('Spark SQL', 3) | SQL |
| 移除字符串开头(左侧)的空格 | ltrim(str) ; trim(LEADING FROM str) | ltrim(' Spark SQL') | Spark SQL |
| 移除字符串结尾(右侧)的空格 | rtrim(str) ; trim(TRAILING FROM str) | rtrim('Spark SQL ') | Spark SQL |
| 移除字符串开头和结尾(左右两侧)的空格 | trim(str) ; trim(BOTH FROM str) | trim(' Spark SQL ') | Spark SQL |
| 移除字符串开头和结尾(左右两侧)的指定字符 | trim(trimStr FROM str) 移除两侧; trim(LEADING trimStr FROM str) 移除左侧; trim(TRAILING trimStr FROM str) 移除右侧 | trim('*' from 'ABC**') | AB*C |
4. 字符串替换
| 用途 | 函数 | 举例 | 结果 |
| 替换所有匹配到的字符。[, replace]省略时移除所有匹配到的字符。 | replace(str, search[, replace]) | replace('ABCabc', 'abc', 'DEF') | ABCDEF |
| 多字符替换。针对input,将from中的每个字符替换为to中相应字符。若from比to字符串长,在from中比to中多出的字符将会被删除。 | translate(input, from, to) | translate('AaBbCc', 'abc', '123'); translate('AaBbCc', 'abc', '12') | A1B2C3; A1B2C |
| 替换固定位置字符,可指定替换长度 | overlay(input, replace, pos[, len]) | overlay('Spark SQL' ,'tructured' ,2,4);overlay('Spark SQL' PLACING 'tructured' FROM 2 FOR 4) | Structured SQL |
| 正则匹配替换所有匹配到的字符 | regexp_replace(str, regexp, rep) | REGEXP_REPLACE('A1B2C3**','[\\d\]','') 把所有数字和去除 | ABC |
5. 字符串分割和拼接
用途 | 函数 | 举例 | 结果 |
以单个或多个字符分割字符串, 返回数组。分隔符支持正则表达式,limit控制分割后元素数,省略时代表全部分割 | split(str, regex, limit) | split('A1B2C','\\d'); split('A1B2C','\\d',2); split('A-B-C','-') | [A, B, C]; [A, B2C]; [A, B, C] |
字符串拼接 | concat | concat('Spark', 'SQL') | SparkSQL |
expr1 || expr2 | 'Spark' || 'SQL' | SparkSQL | |
用分隔符拼接字符串或数组 | concat_ws(sep[, str | array(str)]+) | concat_ws('-', 'Spark', 'SQL') | Spark-SQL |
返回字符串重复对应数值次数后的新字符串 | repeat(str, n) | repeat('ABC', 2) | ABCABC |
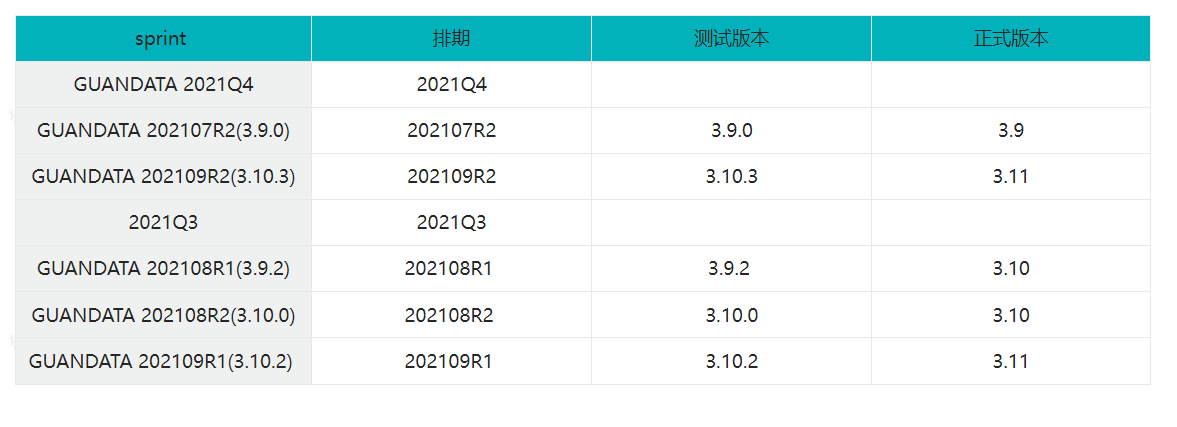
应用案例
【需求】文本字段“Sprint”,需要分别提取出:
①中间部分“排期”,由数字和字母组成的6至8位字符串;
②括号里的内容“测试版本”;
③基于“测试版本”推算出“正式版本”;
【逻辑】最后一个小数点后数字为小版本号,为0时前面部分即为正式版本号,不为0时中间数字加1。
【最终效果】
①"排期"实现方式(任选其一):
1. substr([Sprint],8,8)
2. left(replace([Sprint],'GUANDATA'),8)
3. regexp_extract([Sprint], '(\\d{4,6}\\w{2})', 1)
4. element_at(flatten(sentences([Sprint])),2)
②提取括号里内容“测试版本”实现方式(任选其一):
1. regexp_extract([Sprint], '(\\d\\.\\d{1,2}\\.\\d)', 1)
2. case when instr([Sprint],'(')>0 then replace(substr([Sprint],instr([Sprint],'(')+1),')') end
3. case when [Sprint] like '%(%' then substring_index(translate([Sprint],'()','-'),'-',-1) end
4. element_at(flatten(sentences([Sprint])),3)
③基于“测试版本”推算出“正式版本”实现方式:
case when right([测试版本],1)=0 then substring_index([测试版本],'.',2)
else concat(left([测试版本],2),int(substr(substring_index([测试版本],'.',2),3)+1))
end