用ETL补齐数据
需求背景
由于同环比计算都是基于当期维度字段来取同期的数据进行对比,如果当期和同期的维度字段内容不一致,同环比计算后,会出现每一行同环比计算结果正确,总计结果不正确。
例如今年有10个SKU,去年有12个,那同环比只能对今年的10个SKU进行对比,今年少的的SKU就会被遗漏。如果要对所有SKU进行对比计算,则需要提前在ETL里把数据补齐,保证每个SKU每个日期区间内都有数据。
注意事项:数据补齐会使数据膨胀,需要计算好数据量,酌情使用。
实现方法
案例数据集包含3年销售数据,原始颗粒度到“日”,要按照“月”计算月环比、年同比,需要补齐数据使每个商品分类每个月都有销售数据。
- 第一条支线:输入数据集后,添加“分组聚合”节点,把字段“商品分类”拖入维度栏,得到数据集里去重后的所有商品分类列表。
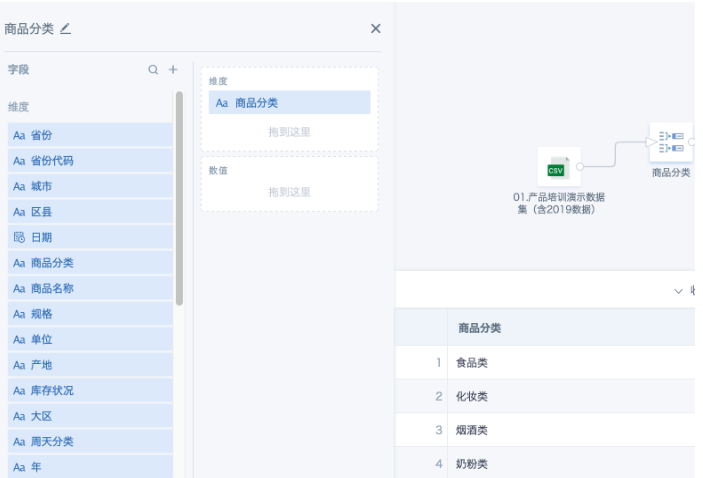
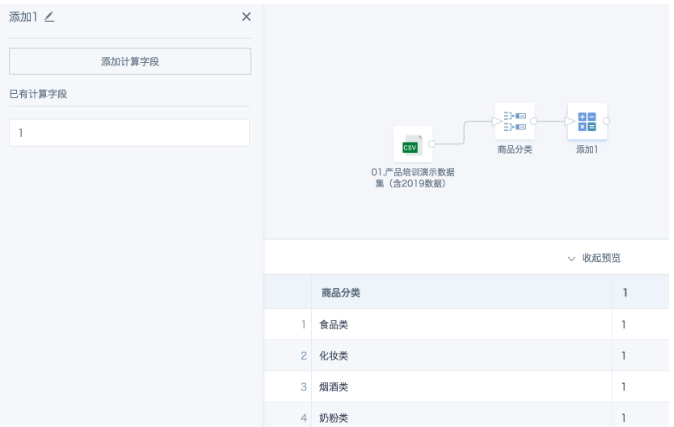
- 增加“添加计算列”,添加一个常量字段,比如【1】。
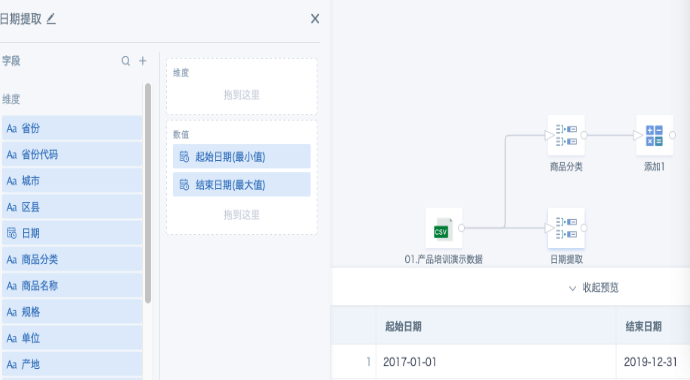
- 第二条支线:输入数据集后添加“分组聚合”节点,把日期字段拖入数值栏两次,聚合方式一个选“最小值”,一个选“最大值”,系统会提示字段重名,需要给字段设置别名。如果时间范围直接要用指定范围代替从数据集取,这一步使用“添加计算列”节点,添加两个日期型常量字段作为起始日期和结束日期。
- 增加“添加计算列”。
-
-
添加一个常量字段,比如【1】。
-
再添加一个字段,使用组合函数 explode(sequence([起始日期],[结束日期],interval 1 month)) 来补齐日历,得到区间内每个月1号的日期。其中的interval 1 month也可以根据需求替换为interval 1 week/day等等。
-
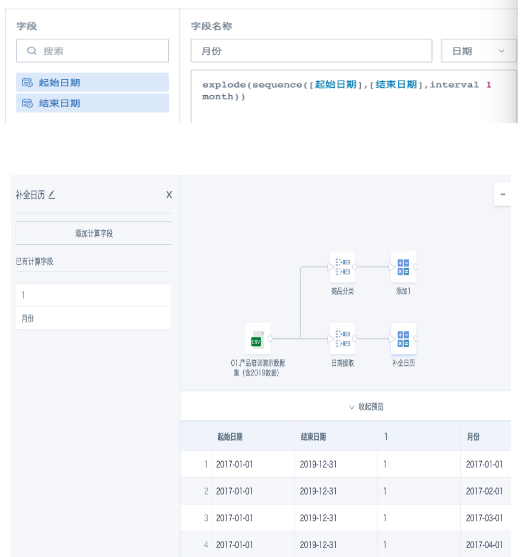
- 添加“关联数据”节点,用常量字段1把步骤2和步骤4的两个临时数据集关联起来,关联方式任选一种即可(因为月份字段和商品分类字段之前已经去重过),勾选需要保留的字段“商品分类”和“月份”,得到这两个字段补齐后的完整列表。
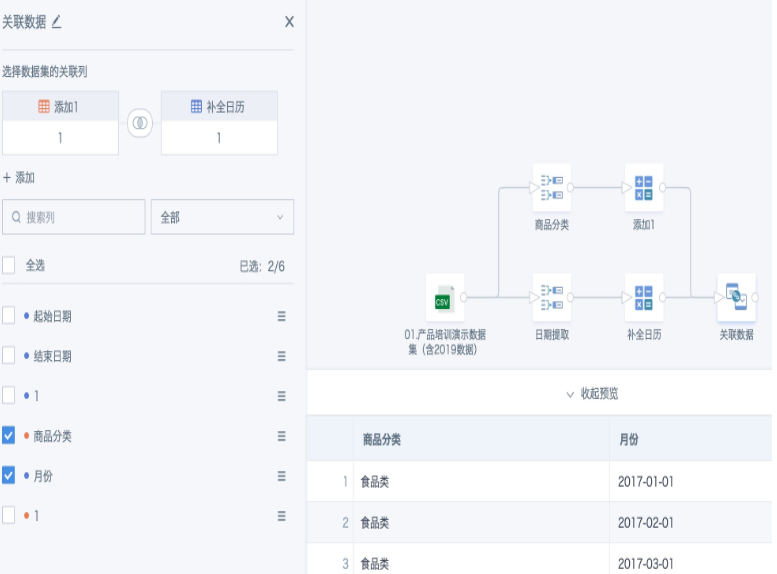
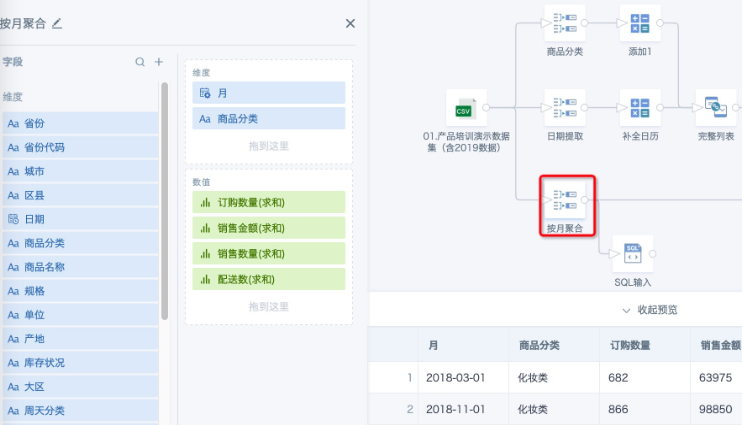
- 第三条支线:原始输入数据集用“分组聚合”把数据颗粒度聚合到“商品分类”和“月份”。
注意:维度字段要和前两条支线保持一致。如果要添加其他会影响数据行数的维度字段,这个维度字段必须像上述第一二条支线一样,单独做一条支线并且参加关联进行数据补齐。
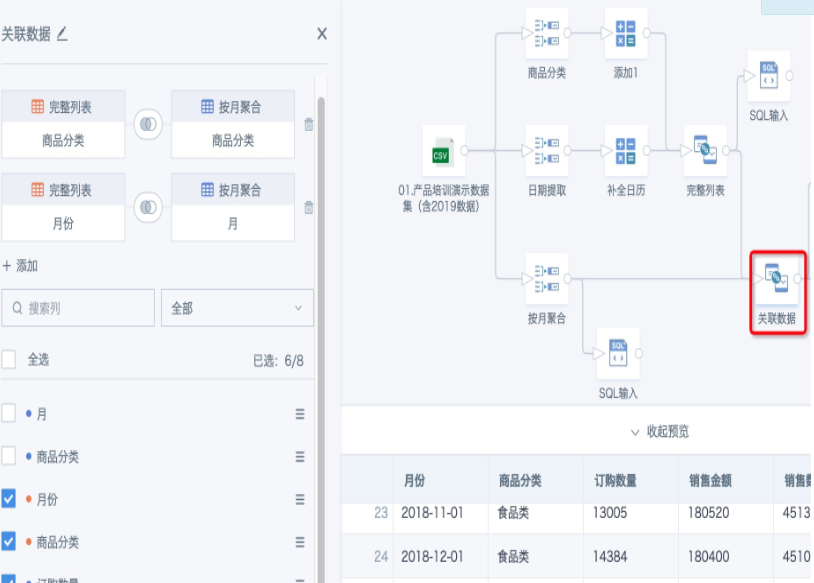
- 添加“关联数据”节点,以步骤5得到的完整列表为基础表,用字段“商品分类”和“月份”左关联步骤6得到的表。下面勾选保留字段的时候,字段“商品分类”和“月份”要选左侧基础表的字段。
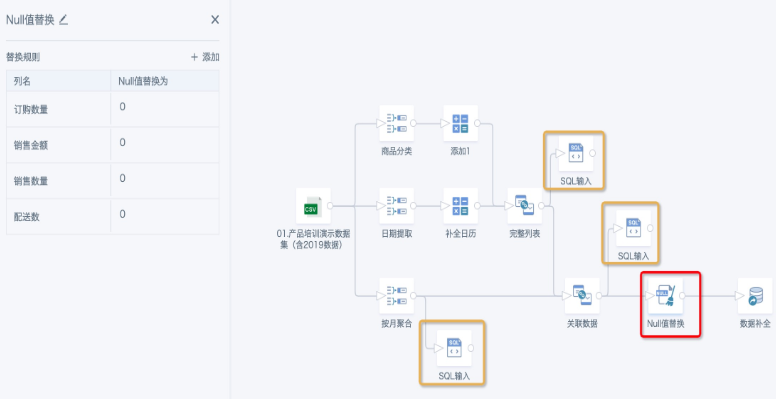
- 添加“Null值替换”节点,把所有需要参与统计的数值字段里的null值都替换为0。因为数据补齐时会产生大量null值,替换为0后续才能参与计算。根据需要添加其他节点处理数据,直至ETL完成保存运行。
注意事项
-
建议多用【数据探查】节点或者SQL来检查关联后的数据量,从而判断数据量是否是合理膨胀。
-
如果ETL节点预览或者运行失败报错 "message":"java.util.NoSuchElementException: key not found: numPartitions",那就说明数据不合理膨胀超出系统限制被强制终止运行,需要及时检查数据并修改两张表的关联方式。