Druid 数据接入
1. 概述
Apache Druid 是一个实时分析型数据库,旨在对大型数据集进行快速查询和分析。Druid 最常被当做数据库,用以支持实时摄取、高查询性能和高稳定运行的应用场景。例如,Druid 通常被用来作为图形分析工具的数据源来提供数据,或当有需要高聚和高并发的后端 API。同时 Druid 也非常适合针对面向事件类型的数据。观远数据针对 Druid 专门开发了数据连接器,本文将介绍如何连接 Druid 数据库。
2. 准备工作
在连接数据库之前,请收集以下信息:
-
数据库的版本(版本要求: Druid ≥ 1.9.0);
-
数据库所在服务器的 IP 地址和端口号;
-
数据库的名称;
-
数据库的用户名和密码;
-
需要连接的数据库方式。
3. 连接步骤
3.1 创建数据连接账户
登录观远BI ,点击「数据中心>数据账户」,点击「新建数据账户」,在添加账户弹窗中,账户平台框选择「Druid」,如下图所示:
.png)
3.2 创建数据集
3.2.1 选择连接器
点击「数据中心>数据集」,点击“+新建数据集”,选择“数据库”。在“选择连接器”中选中“Druid”,点击下一步。
.png)
3.2.2 选择数据表
下拉选择已有数据账户,选择数据表。用户还可以根据自己的需要在中间“SQL 查询”区域填写查询语句。
.png)
输入框下方有“时间宏”供您选择,为数据更新与动态分析设置时间要求。观远数据的动态时间宏,可以帮助您根据当前日期生成动态SQL,高效实现定时刷新数据与增量更新。例如我们可以输入这样的SQL语句:
.png)
更多使用方式可查看《动态时间宏》。点击“时间宏”下方的“添加参数”功能,可以使用参数来实现数据分析维度的切换。更多使用方式可查看《全局参数》。
.png)
数据预览成功后,可进入到下一步。
3.2.3 数据连接及更新设置
观远数据支持“直连数据库”与“Guan-Index”两种数据库连接方式。点击数据库连接方式的选择框,选择“直连数据库”或“Guan-Index”,并进行相关设置。
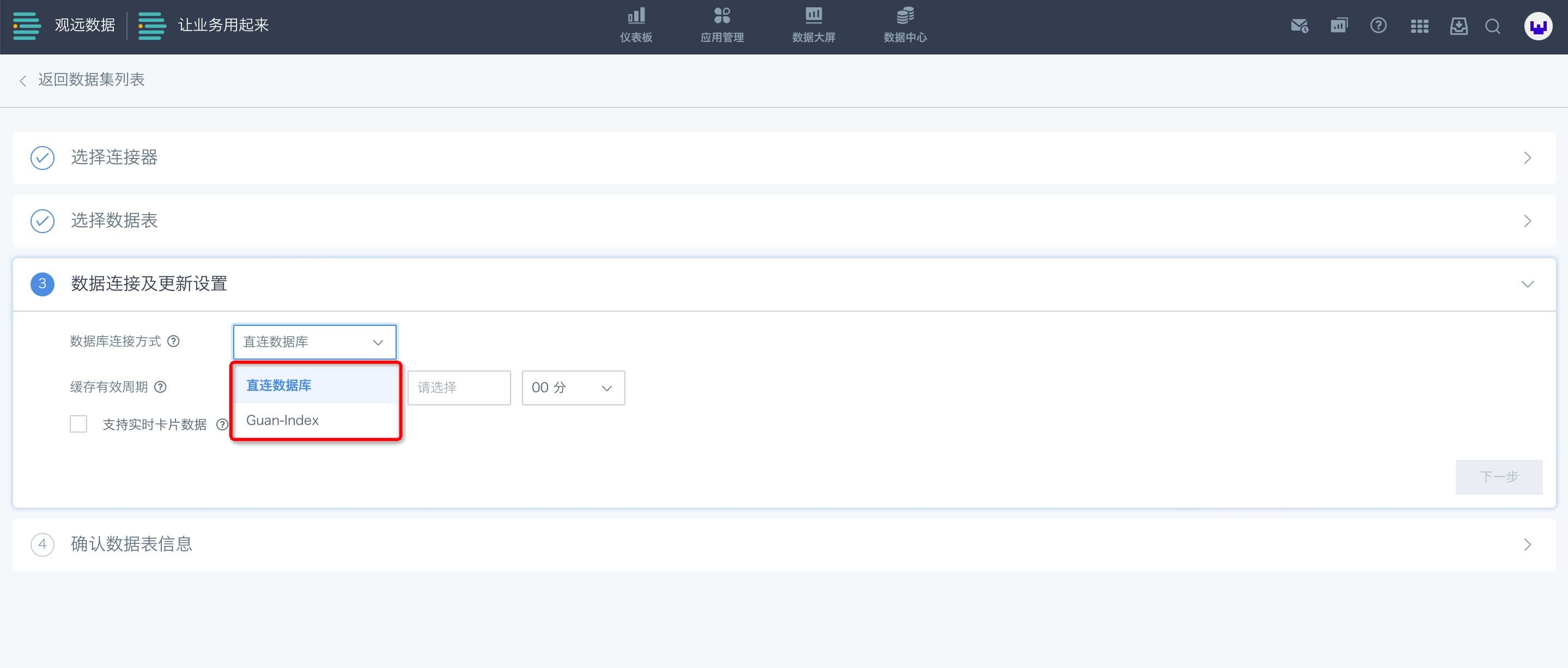
方式一: 直连数据库
直连数据库,是指选择“直连数据库”时,卡片数据将直接从数据库获得。用户需要设置“缓存有效周期”和“支持实时卡片数据”。
-
“缓存有效周期”即“数据更新周期”,作用是定时更新与该数据集相关的所有卡片、卡片数据集、ETL、JOIN等数据。
-
“支持实时卡片数据”是指建在该数据集上的卡片,可支持更短周期的数据更新,当前默认为1分钟。
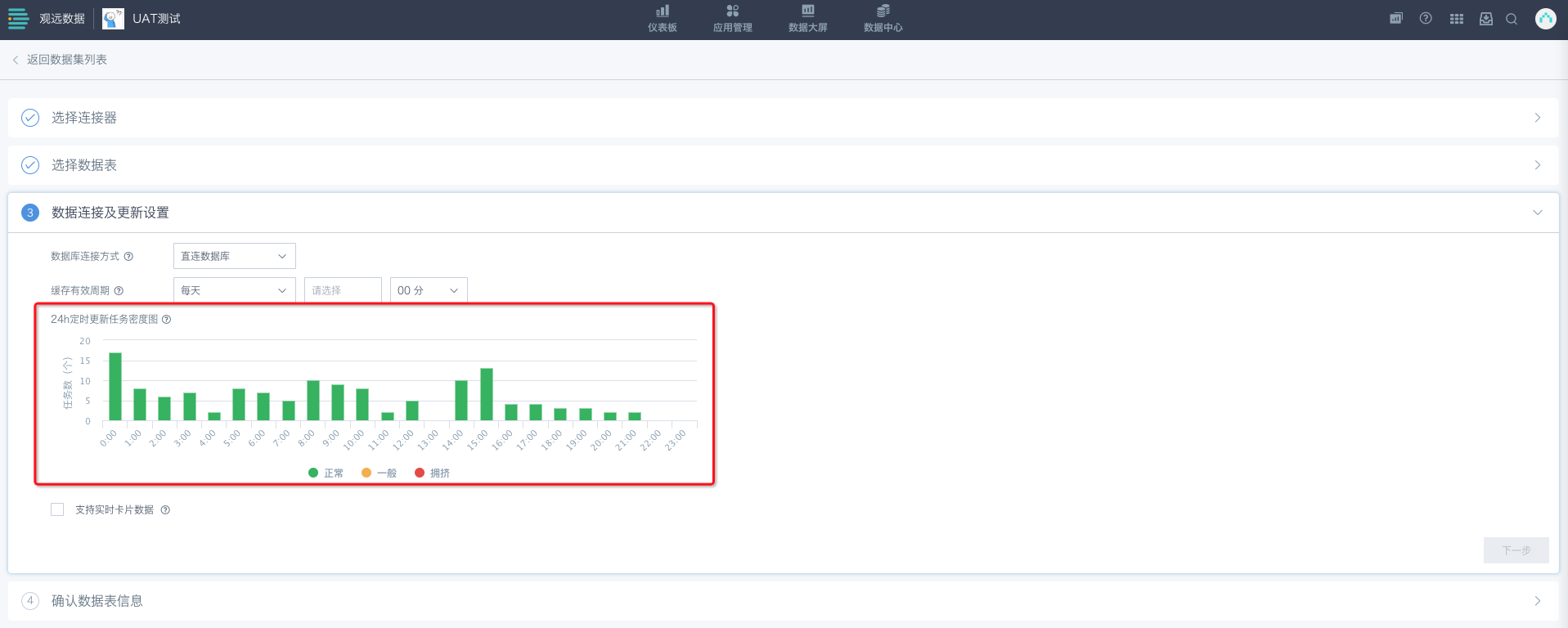
如果开通了“24h定时更新任务密度图功能”,功能开启后,缓存有效周期选择每天/每周/每月,则会展示定时更新任务密度图(如需使用该功能,请联系观远人员协助开启)。
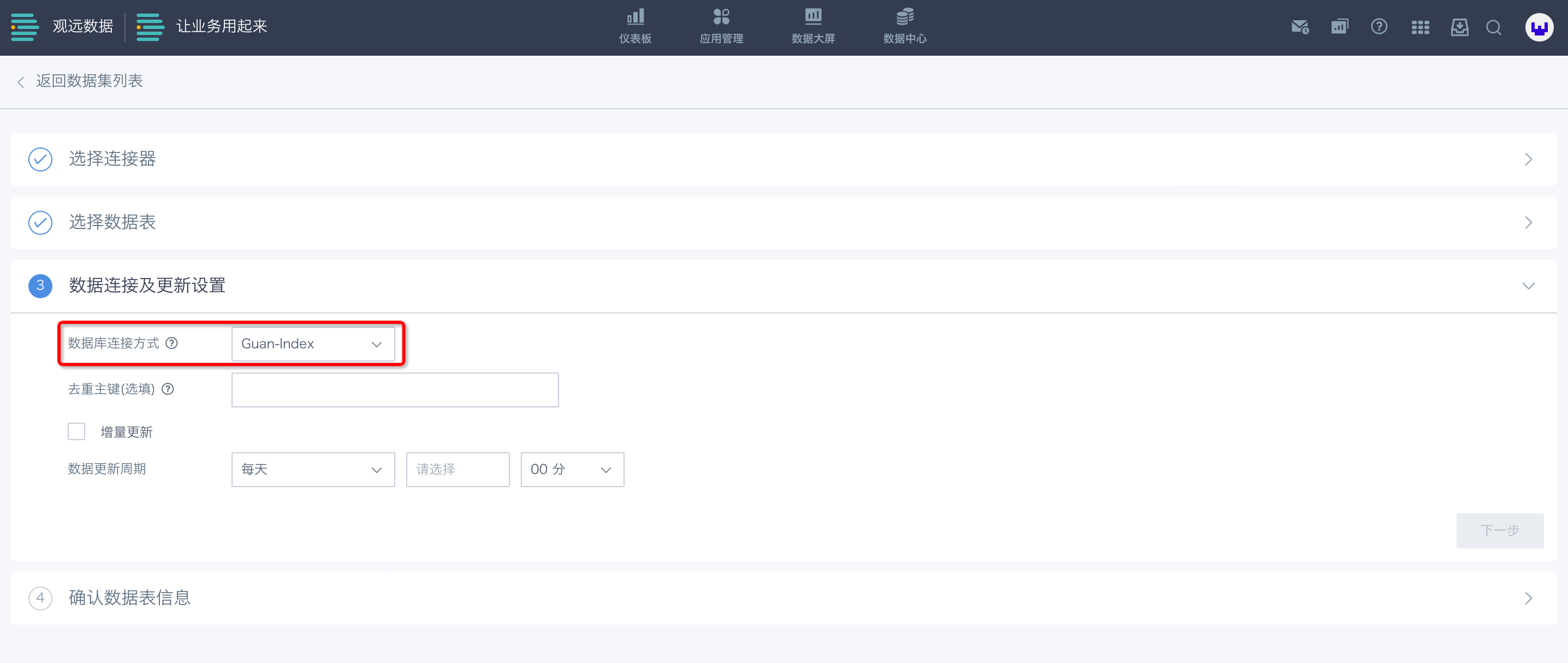
方式二: Guan-Index
Guan-Index,是指数据被抽取到观远服务器后将构建物理数据集,支持增量更新。具体使用步骤如下:
-
首先,当您选择Guan-Index模式时,在上一步的“数据库查询”中,不能选择“添加参数”。
-
其次,若您要对数据集进行增量更新或未来有设置增量更新的可能,可以通过点击选择“去重主键”,对未来需要增量更新的字段进行设置。
-
再次,如点击“增量更新”,您可以填写SQL来设置增量更新的条件,通常与时间宏参数配合进行。
-
最后,设置数据更新周期,即可进入“下一步”。
3.2.4 确认数据表信息
在确认数据表信息阶段,观远数据支持确定数据集名称与保存位置、支持字段重命名。
信息一:确定数据集名称与保存位置
为您的数据集提供一个方便辨识的名字,以及指定保存位置。点击确认后,数据集创建成功,可以在“数据中心”-“数据集”中找到它。需要注意的是,若创建的是Guan-Index数据集,您可能需要等待一段时间,等数据抽取完成后可以在“数据中心”看到正确的数据集信息。
信息二:支持字段重命名
当字段名需要修改时,点击字段名右侧的小箭头,即可打开下拉框,修改字段名。
.png)
3.3 使用数据集
在数据集创建完后,可以直接使用数据集制作可视化图表等操作,您还可以对数据集进行其他设置操作,具体操作可查看《数据集》相关文档。