如何向下拆分数据源中的指标?
场景介绍
当数据源中包含的两个指标不在同一个统计维度,又需要做四则运算时,我们需要将指标向下拆分或者向上聚合使得两个指标在同一个统计维度。
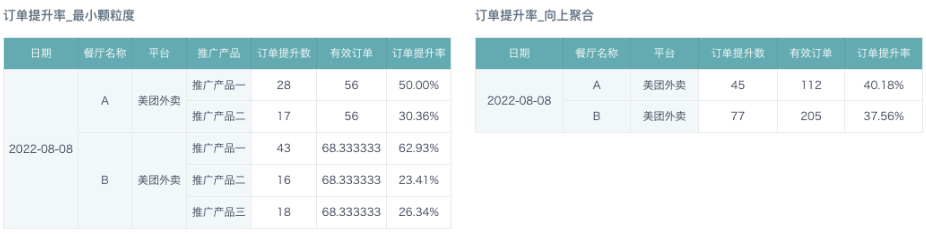
例如,样例数据源中的订单提升数的统计维度是日期、餐厅、平台、推广产品,而有效订单的统计维度是日期、餐厅、平台。有效订单数在多个推广产品上是重复的。当我们计算订单提升率时 ,需要先将分子(订单提升数)和分母(有效订单)统一到同一个统计维度。
常用的方法是将订单提升数向上聚合到日期、餐厅、平台层级。但当数据向上聚合后,就无法继续在推广产品维度做分析。因此,有时候业务要求按照一定的拆分逻辑,将有效订单向下拆分到日期、餐厅、平台、推广产品层级。至于具体采用怎样的拆分逻辑,主要是从业务角度考虑,可以平均拆分,也可以按照一定的权重拆分。
本案例介绍平均拆分的方法。
步骤:
-
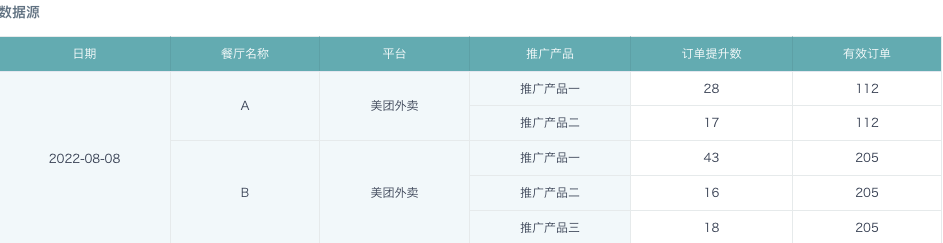
在ETL中对数据源进行处理;
-
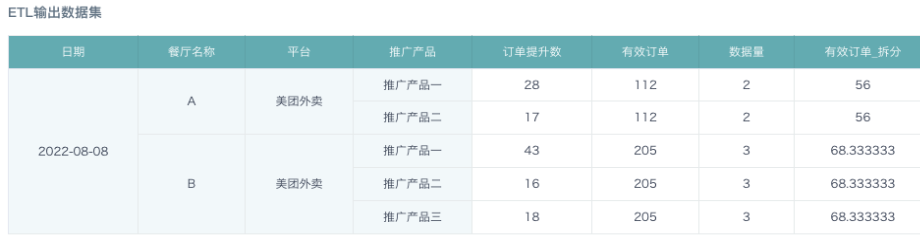
添加计算列:数据量。计算在日期、餐厅、平台层级有几行数据,也就是有几个推广产品。
COUNT([推广产品]) OVER(PARTITION BY [门店编码],[日期],[平台])
- 添加计算列:有效订单_拆分。将有效订单按照推广产品的个数平均拆分。
[有效订单]/[数据量]
-
使用ETL输出数据集新建卡片;
-
将【有效订单_拆分】添加到卡片中,并重命名为有效订单。
-
计算订单提升率。将有效订单拆分后,在最小颗粒度(日期、餐厅、平台、推广产品)计算订单提升率,或者向上聚合计算订单提升率都没有问题。
SUM([订单提升数])/SUM([有效订单_拆分])