ETL常见报错
1.ETL运行失败报错为“Job Cancelled due to shuffle bytes limit, the threshold is 200G”
【原因】:如果涉及到关联、聚合以及开窗函数等操作,Spark需要对数据根据键值进行分片处理,这个时候会产生Shuffle数据并且写入磁盘中。如果数据量很大,大量的shuffle数据会对服务器的磁盘产生比较大的压力。所以,在观远自己的计算引擎中,加入对于Shuffle使用量的检测。如果发现单个ETL的输出任务写入的Shuffle数据超出200G(默认配置),那job engine就会主动杀掉这个任务,并返回相关的错误。
【解决方案】:
-
对于磁盘充裕的客户,可以根据磁盘大小来调节Shuffle的上限。可以按照客户BI总磁盘的60%来设置上限,同时推最大的磁盘使用量尽量满足<85%的这个条件。需要联系观远方来操作。
-
升级到最新的job engine私有化版本(1.1.0+),我们在1.1.0中增加了对于磁盘容量的判断。只有磁盘使用量大于85%时,才会触发对于Shuffle使用的检测。
-
如果磁盘使用量已经很高了,一般不建议调整Shuffle上限,推荐优化ETL(例如拆分)。这样既能控制磁盘的使用量,又能满足Shuffle的限制。
2. 报错信息:org.apache.spark.SparkException: Could not execute broadcast in 300 secs. You can increase the timeout for broadcasts via spark.sql.broadcastTimeout or disable broadcast join by setting spark.sql.autoBroadcastJoinThreshold to –1
问题表象:两个不同的ETL(之前近一个月都是稳定运行)报同样的错误,重新点击运行后也能正常运行;
【原因】进入环境,排查相应ETL,join后的数据帧较大,需要耗费较长时间,而程序默认spark.sql.broadcastTimeout配置属性默认值为5 * 60秒,即300sec,这个远远不够,随着ETL复杂度越来越高,这个报错会很频繁。
【解决方案】所以建议设置一下spark.sql.broadcastTimeout参数,将它调大:如config("spark.sql.broadcastTimeout", "3600")
3. ETL分组聚合节点提示丢失字段,但实际上并没有丢失该字段
【原因】:大概率是这个字段id或者字段类型发生了改变,比如输入数据集字段做了变动(可能是把这个字段删除又重新建了一个,导致字段id变化),但是ETL里保留的是原先的字段,两个id对不上就会报丢失字段的错误。
【解决方案】:重新拖下字段。
4. ETL里值替换报错的可能原因是什么?
【原因】:可能是字段类型的问题,比如数值字段如果替换为文本字段,那么就会报错。
【解决方案】:这种情况下可以在替换之前加一个新建字段的节点,转换下字段格式。
5. ETL更新报错 Cannot broadcast the table that is larger than 8GB: * GB
【原因】超出了spark表broadcast join的限制,常见的情况可能是关联节点有无法匹配到数据的错误关联,导致关联后的值出现大量Null(这时数据会大量膨胀,容易超出了spark的broadcast join限制-8GB)
【解决方案】修改关联字段,确保字段类型一致,关联有效。
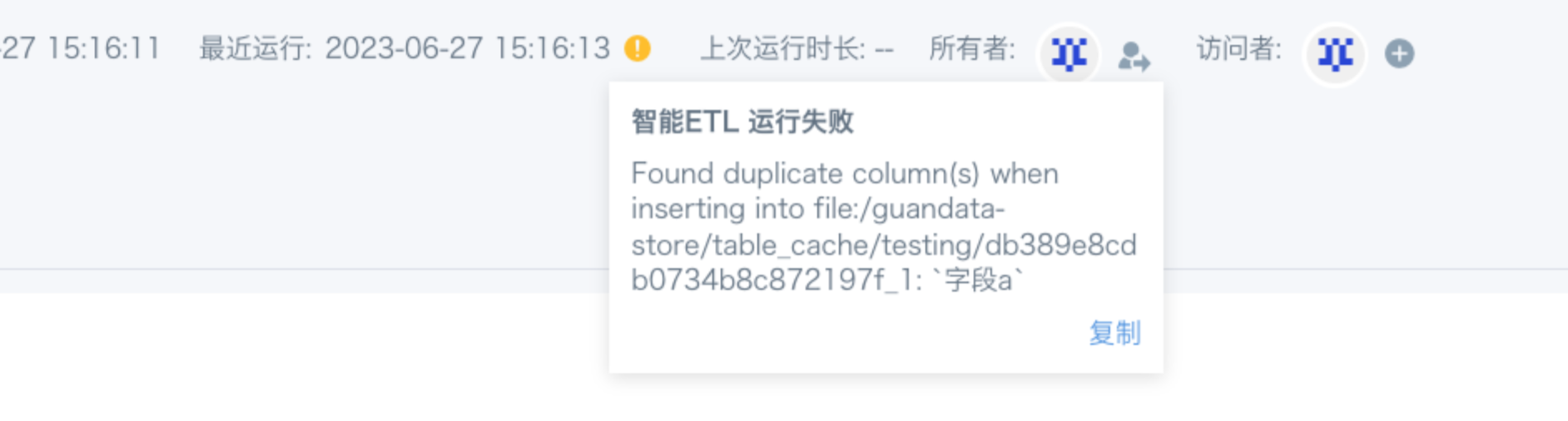
6. ETL提示有重复字段(Found duplicate column(s) ...,如图),实际上是没有一样的字段
【原因】spark对字段名称大小写不敏感,在sql里面写大写和小写是没有区别的(如“字段A”和“字段a”就算是一样的)。
【解决方案】检查是否有报错字段相似的字段名,修改后重新运行。
7. ETL中关联节点报错:[message] = Reference 'id_1666072244947.truck_id' is ambiguous, could be id_1666072244947.truck_id, id_1666072244947.truck_id.; line 1 pos 0
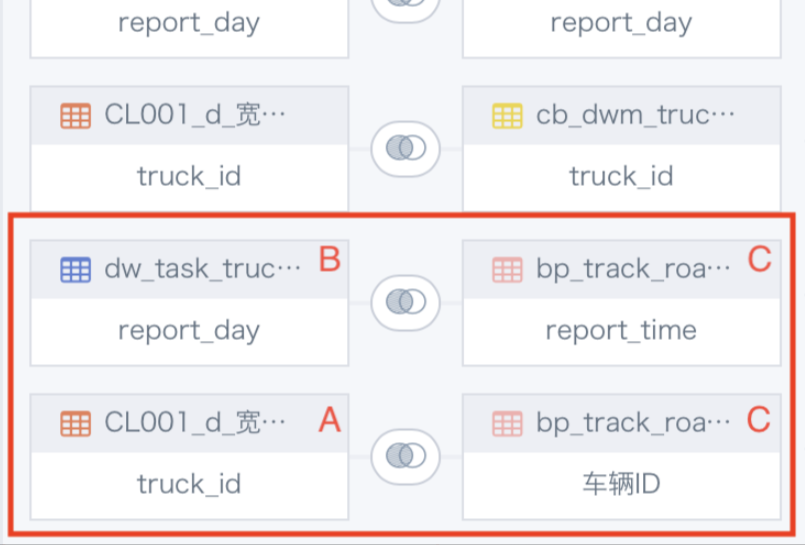
【原因】多表交叉循环关联。已上图为例,因为A、B数据表上面已经join过了,所以不能存在B join C的情况下,再让A join C。
【解决方案】仅指定一张表当做关联的主表,避免多表交叉循环关联;复杂情况下建议拆分为多个关联节点。
8. ETL运行报错 Job timed out
【原因】ETL对应的Spark job运行超时。
【解决方案】管理员可以从「管理员设置-运维管理-参数配置」里修改ETL「任务最大运行时长」和「Spark单 job超时时间」;运行时间过长建议优化或者拆分ETL。
9. ETL运行报错:Job 2632 cancelled because SparkContext was shut down 、engine lost
【原因】多个大的ETL同时运行,导致磁盘使用率过高,导致job engine重启;内存溢出导致job engine重启
【解决方案】清理磁盘空间,检查资源配置;把运行时间较长(CPU占用时长)的ETL运行时间错开;具体问题具体分析。
10. ETL所有节点都预览成功,但是运行报错:Parquet data source does not support void data type
【原因】用null值新建的字段,选择的字段类型无效
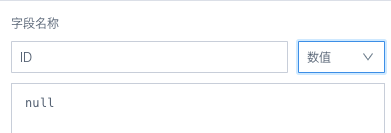
【解决方案】用函数为null指定类型,例如 cast(null as int)
11. ETL运行失败,报错 Illegal sequence boundaries: 19662 to 19606 by 1
【原因】ETL里用了sequence 函数来实现两个日期之间按天(或按月)扩充,起始日期应该小于等于结束日期。如果起始日期大于结束日期,预览运行都会报错。19662和19606分别代表开始日期和结束日期的unixdate。
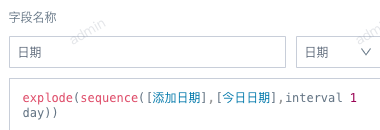
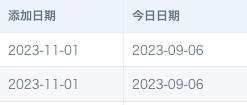
【解决方案】检查结束日期,确保结束日期总是大于等于开始日期。