ETL数据膨胀优化
【问题表现】
-
任务运行很慢,数据量越大执行时间就越长,可能会报错 job time out、OOM。
-
不恰当的关联使用导致数据膨胀超出数据限制,目前行数限制是50亿行 ,数据大小限制是200G。此时会报错:Job Cancelled due to numRows limit 、Job Cancelled due to data size limit。
【触发场景】
-
不恰当的关联方式,例如全关联、或者交叉关联(笛卡尔积);
-
不恰当的关联字段导致的数据膨胀;
-
不恰当的聚合操作例如 collect_list、collect_set、median,计算时需要把全量中间数据都保留下来,在配合其他聚合用法时,可能会产生数据膨胀;
【解决方案】
一、不恰当的关联方式
-
尽量使用左关联,非必要避免使用全关联。
-
非必要避免使用交叉关联(ETL不直接支持,必要情况下间接实现请参考 ETL补齐数据方法 )。交叉关联的数据量是笛卡尔积的形式,比如两张表的数据分别是20w、5w那么full join出来的数据就是100亿(20w*5w)的数据
二、不恰当的关联字段
1. 使用任意关联方式时,要避免关联字段的一对多关系
例如60万的数据 左关联(left join) 2万数据时,SQL逻辑如下,当每个table2中的srcid对应100条desid时,则最终数据量60w*100=6000w。
select sid,nums,desid
from
(select sid,nums
from table1
where date = '20221030'
) a
left join
(select srcid,desid
from table2
where date = '20221030'
) b
on a.sid = b.srcid
【解决方案】
建议如果不是业务强需求,尽量改成一对一的关系后再进行关联。在ETL中可以使用“分组聚合”、“去重”节点进行处理。
--------建议修改成以下这种(聚合方式可以选择max/min/sum/avg等)--------
select sid,nums,des
from
(select sid,nums
from table1
where date = '20221030'
) a
left join
(select srcid,max(desid) as des
from table2
where date = '20221030'
group by srcid
) b
on a.sid = b.srcid
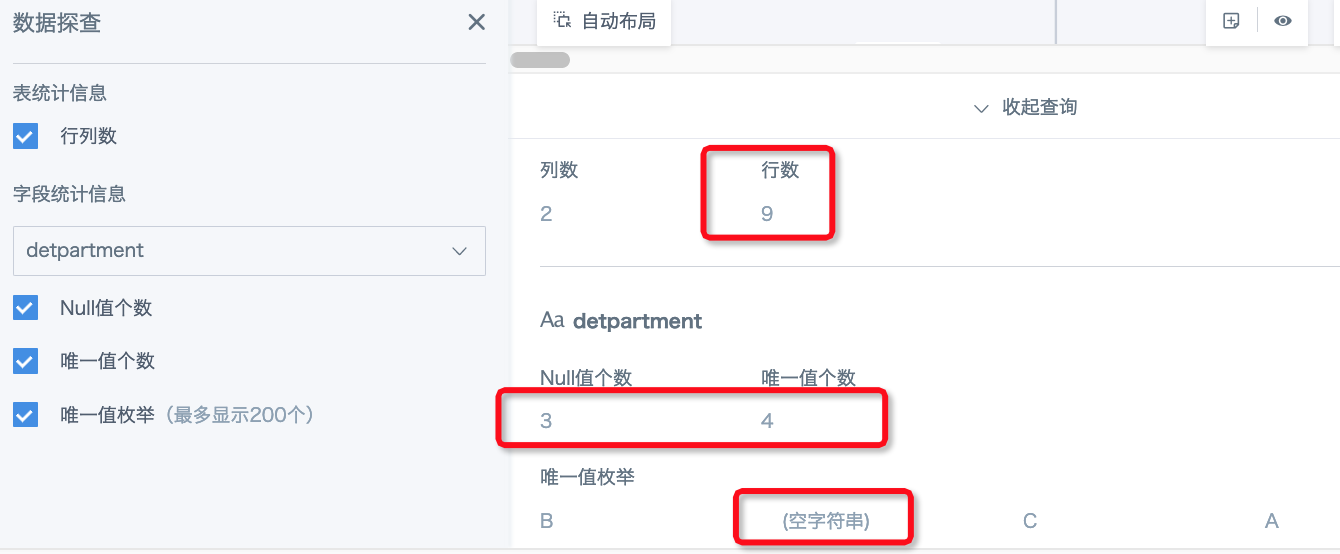
2. 当关联字段中里面有重复的空字符串,在关联时会产生膨胀
例如左表有2行空字符串,右表有3行空字符串,则使用任意方式关联之后都会产生数据膨胀(2*3=6)。这个也相当于是关联字段一对多。
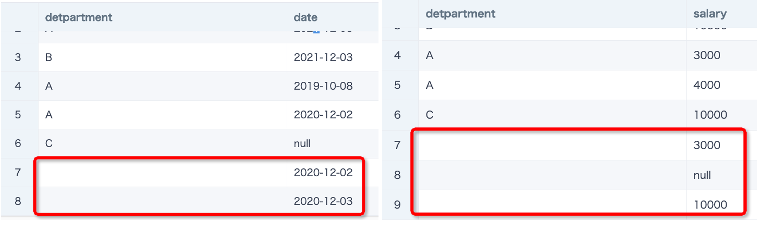
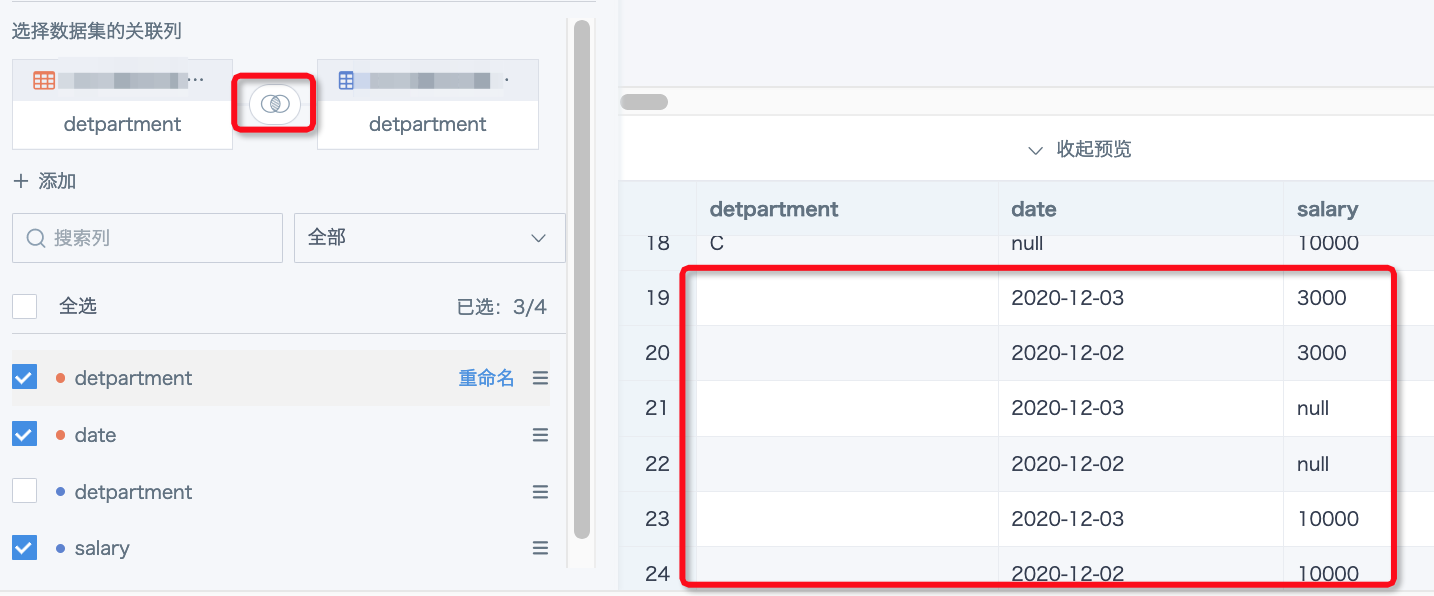
【解决方案】
-
空字符串如果是无效数据,则建议先使用“筛选数据行”过滤掉这部分数据,或者用“值替换”替换为null值。一般null值在ETL的中使用关联节点来做数据集关联时是不会产生膨胀的,因为spark里null = null的结果不是true,是null。
-
对左右关联的两张表的主键使用“分组聚合”或者“去重”节点,尽量实现主键为一对一的关系,可以避免数据膨胀。
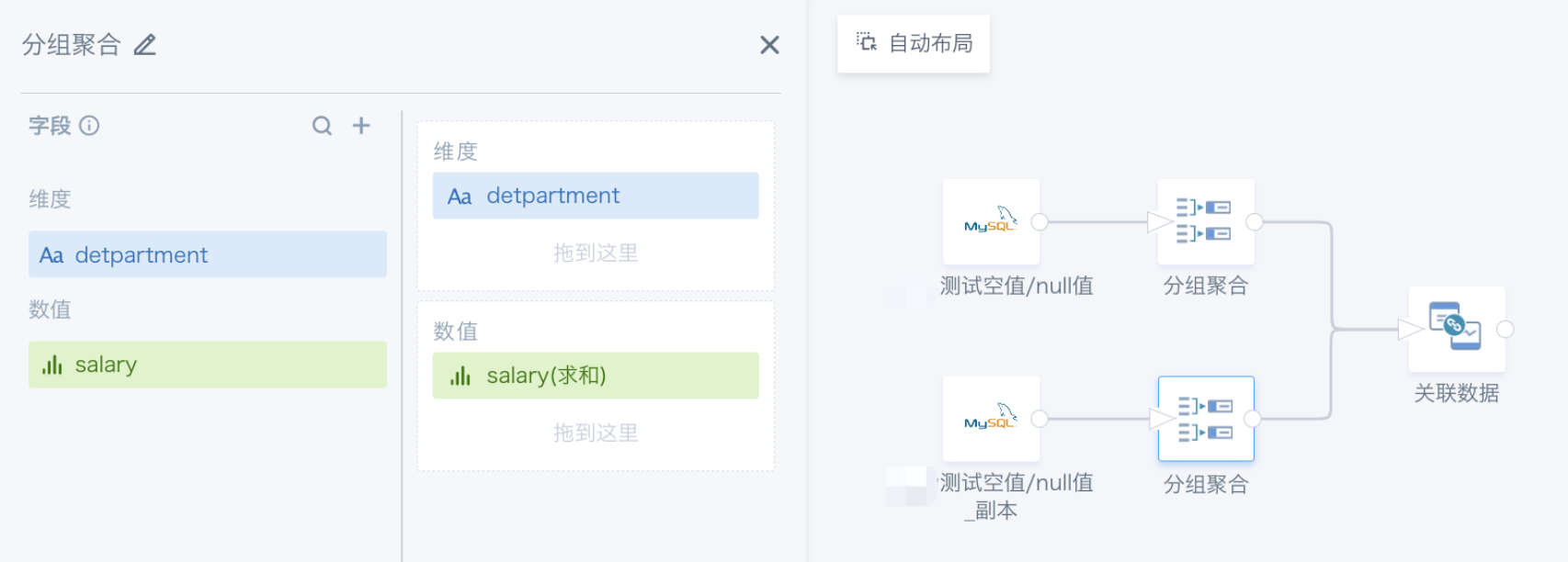
三、不恰当的聚合操作
例如collect_list、collect_set、median,计算时需要把全量中间数据都保留下来,在配合其他聚合用法(例如开窗)时,可能会产生数据膨胀(主要是数据大小膨胀)。目前限制参与collect_list、collect_set计算的行数上限为50万行,超过会报错:Too many elements in collect_set or collect_list. The threshold is 500000.
【解决方案】
ETL里通过「分组聚合+自关联方式」进行计算。即把需要开窗计算的数据用分组聚合节点计算得到,然后再和原来的数据表关联起来。具体请参考 去重计数函数实现开窗。
【预防及检查】
-
ETL里每个节点都确保能预览成功再进行下一步;
-
预览加载慢的时候,特别是关联节点,使用SQL节点( select count() from input1 *)来检查关联前后的行数变化,可以及时发现数据膨胀;
-
借助“数据探查”或者“分组聚合”节点,查看关联用的右表主键是否存在空字符串、是否存在一对多的情况。