系统性能边界之参数配置
一、系统性能边界的由来
产品系统边界主要是为了找到能标识观远系统在一定计算资源情况下的处理能力的极限。将这些边界参数暴露在产品中方便管理员管控,我们也会根据用户的计算资源推荐默认合理的配置。
能解决的部分常见异常场景:
-
使用BI过程中,突然出现系统不可用,报错502或者504,且用户无法登陆;
-
卡片页面加载慢,大量报错socket hang up,查看任务管理界面发现任务大量排队;
-
数据集更新运行了好几个小时,抽不到数也不会失败,导致其他数据集没办法更新;
-
大数据量卡片编辑时加载特别慢。
二、操作入口
管理员设置-运维管理-参数配置 (不同BI版本的参数配置可能会有差别,如发现没有上面的参数但是需要用到,可联系观远进行版本升级~)
三、具体参数配置及解释
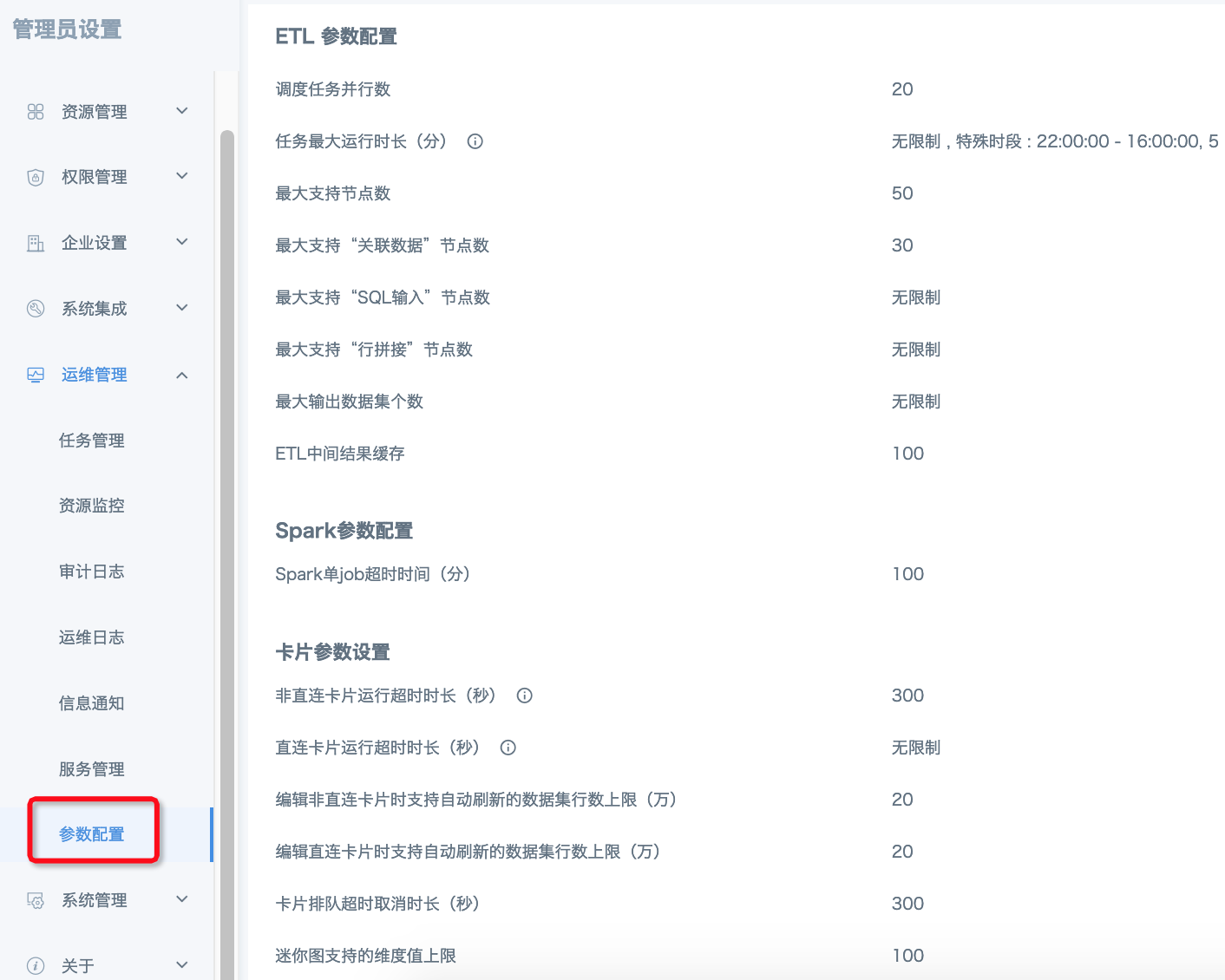
1、ETL 参数配置
① ETL调度任务并行数:定时和级联(勾选的数据集更新后)更新触发的ETL任务的并行数,范围1~20,注意只在单域环境下可配置,多域环境无此配置;
② 任务最大运行时长(分):单个ETL任务的最大运行时长,超出后任务将被中断,范围5~120分钟,4.7.0及更新版本支持特殊时段的设置;

③ 最大支持节点数:达到阈值后将无法拖入新的算子节点,范围10~200;
④ 最大支持“关联数据”节点数:达到阈值后将无法拖入新的“关联数据”节点,范围1~50;
⑤ 最大支持“SQL输入”节点数:达到阈值后将无法拖入新的“SQL输入”节点,范围1~50;
⑥ 最大支持“行拼接”节点数:达到阈值后将无法拖入新的“关联数据”节点,范围1~50;
⑦ 最大输出数据集个数:达到阈值后将无法拖入新的“输出数据集”节点,范围1~20;
⑧ ETL中间结果缓存:当一个ETL有多个输出时,系统将缓存一个中间节点的运行结果以提升运行效率。默认 ETL 复杂度为 100,一般不建议修改默认值。
上面③~⑦对导入的ETL不做判断。决定ETL运行需要耗用多少资源的主要因素有:节点数、“关联数据”节点数、“SQL输入”节点数和输出数据集个数。数据量大的情况下,多一个“关联数据”、“SQL输入”或者输出数据集,需要耗用的资源都会大幅增长甚至翻倍。这样服务器CPU、内存、磁盘任一项资源使用率太高(阈值一般为90%)都会导致系统宕机或者重启,这样其他正在排队或者运行的任务都会失败或被取消,影响极大。所以需要根据自己系统使用状况调整这些参数。
⑧ ETL中间结果缓存,这里是全局设置,同时观远 BI 允许对单个 ETL 设置是否启用该设置,路径为:ETL 界面--高级设置。自定义设置生效优先级高于全局。
2、Spark参数配置
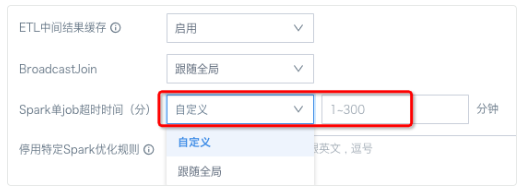
① Spark单job超时时间(分):Spark单个Job的最大运行时长,超出后任务将被中断,范围5~120分钟。
注意:spark job可以是 ETL也可以是卡片,一个ETL的运行或者一个卡片的查询,根据不同情况可能会由多个spark job组成。观远 BI 允许对单个 ETL 进行自定义设置,可定义范围为1-300分钟区间,路径为:ETL 界面--高级设置。
3、卡片参数设置
① 非直连卡片运行超时时长(秒):仅作用于Guan-Index类型的卡片,运行时长不包含排队时间,实际运行超时后将自动失败,范围1~600sec;
② 直连卡片运行超时时长(秒):同上,适用于直连卡片;
③ 编辑非直连卡片时支持自动刷新的数据集行数上限(万):达到阈值后,卡片编辑页无法打开自动刷新,提示如下;
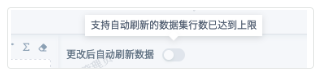
④ 编辑直连卡片时支持自动刷新的数据集行数上限(万):达到阈值后,卡片编辑页无法打开自动刷新,提示如③;
⑤ 卡片排队超时取消时长(秒):达到阈值后,卡片排队任务将被取消,范围1~600。
⑥ 迷你图支持的维度值上限:达到阈值后将无法生成迷你图(5.1 版本上线),范围12~200;
4、数据集参数设置

① 直连数据集更新时不主动更新行数:直连数据库情况下,数据集更新后数据集行数可以支持不自动更新,减少不必要的数据库查询,启用/未启用。
② 数据库数据集更新支持失败重试:仅支持自动更新(包括:定时更新、URL触发)失败后重试 1 次,不支持手动更新;重试时间范围为 5~15 分钟;默认关闭。
③ 1h内数据集定时更新数量限制:用于调整时间段内定时更新数据集的任务数和拥挤程度,做出合理的规划。具体请参考 数据集:支持定时更新任务密度图 (5.3 版本功能)
④ 视图数据集预览超时上限(秒):默认值 60 秒,达到阈值后将停止预览任务。
5、数据库参数设置

① 单个直连数据库连接池上限默认值:单个数据库的连接池上线,超过将无法连接,范围:1~999;设置该参数可以部分缓解数据集因为连接池满而导致数据集更新失败的现象,
② 数据库连接超时(Socket timeout)(分):抽取数据时连接数据库的Socket-timeout。设置该参数后,抽取数据集更新时,超过该时间后依然没有连接到数据库的话,数据集更新任务会自动取消。可以帮助缓解数据集更新时间过长,抽取不到数据的现象,防止任务堆积。
6、回收站参数设置
① 自动清理周期(天):每天23:59执行清空任务,回收站的页面和卡片资源保存时间范围为 1~90 天。
7、订阅预警参数设置
① 单条订阅支持分发条件数上限:5.8 版本订阅支持分发,默认每个订阅支持最多设置10个规则(上限100)。通过配置分发条件限制订阅接收者的可见范围,从而实现数据隔离,分发条件会作为筛选条件,筛选数据涉及订阅发送的url、图片、附件。比如,订阅销售数据,华南销售只看见华南的销售数据,华北只看华北的。

8、线程池优化
① 独立管理运行线程池的数据账户:输入搜索关键词选择目标数据账户,最多支持3个独立管理线程池的账户。

大量使用直连数据集的场景下,容易出现由于查询请求并发过多导致用户数据库无法访问造成BI服务不稳定的问题,由于目前BI所有的数据连接是统一线程池,一个直连账户的问题蔓延会导致其他数据账户的查询请求也受到影响,导致BI整体服务不可用。对重点数据账户进行隔离,有助于提升直连并发较大客群的平台稳定性。