字段拆分案例分享
需求背景
数据集中有字段结构为用分隔符连接起来的字符串,使用时需要拆分开只提取固定位置的字符串,或者整体拆分为多列。
案例场景
案例一:新建计算字段,使用字符串截取函数,定位分隔符位置从而进行拆分
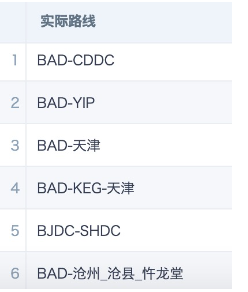
- 实际路线起始点:取第一个横杠之前字符串。
写法一:SUBSTR([实际路线],0,INSTR([实际路线],'-')-1)
写法二:LEFT([实际路线],INSTR([实际路线],'-')-1)
写法三:SUBSTRING_INDEX([实际路线],'-',1)
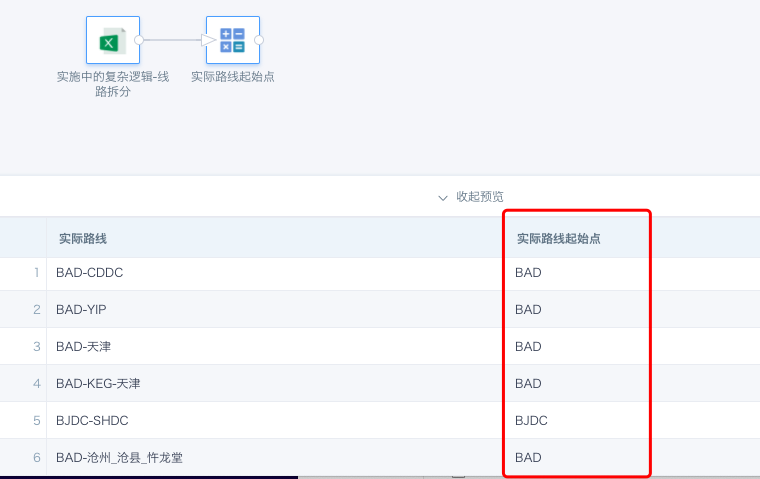
- 实际路线剩余部分:1和2能够拼接回完整的路线。
SUBSTR([实际路线],INSTR([实际路线],'-')+1)
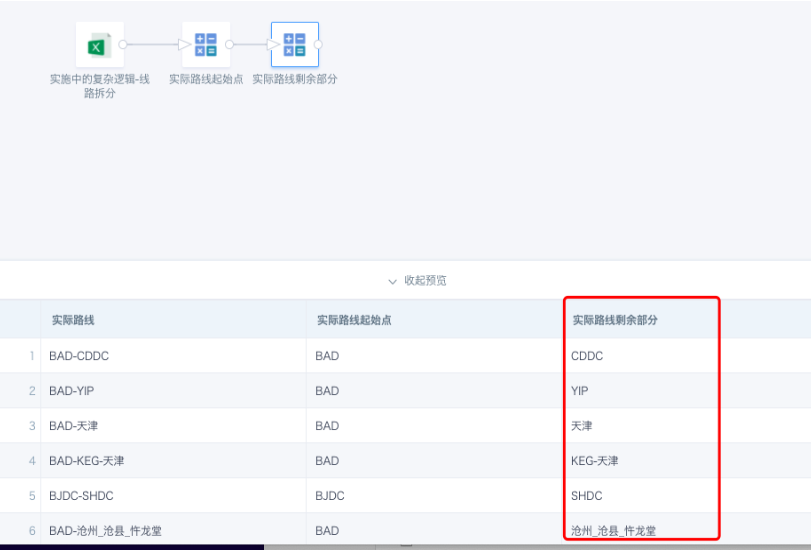
- 实际路线到达点
写法一:right([实际路线],instr(REVERSE([实际路线]),'-')-1)
写法二:SUBSTRING_INDEX([实际路线],'-',-1)
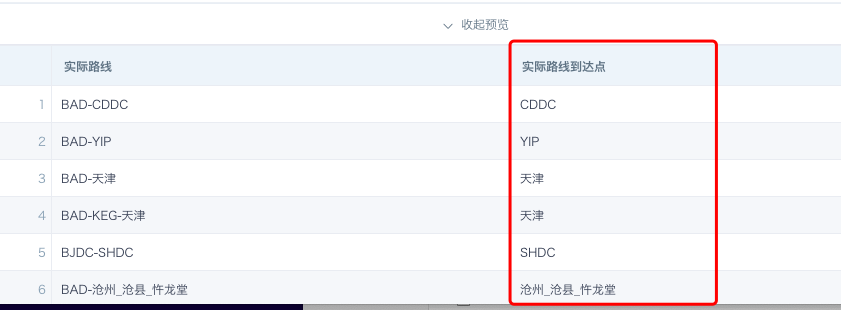
- 实际路线剩余前半部分:3和4能够拼接回完整的路线。
REGEXP_EXTRACT([实际路线],'(.+)(-{1}.+)',1)

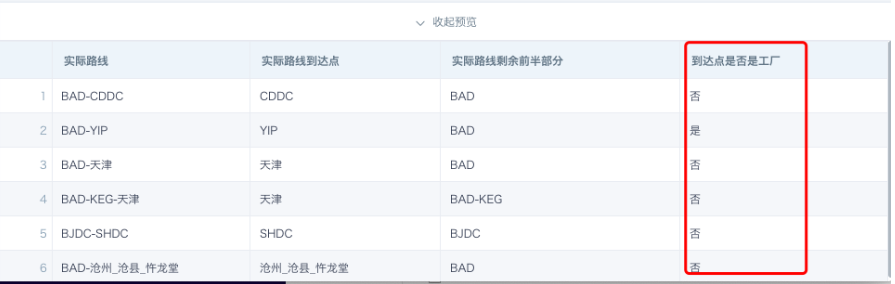
- 到达点是否是工厂:工厂的判断规则是纯字母,且结尾不是DC。
when SUBSTR([实际路线到达点],-2)<>'DC' and (SUBSTR([实际路线到达点],0,1) <='Z' AND 'A'<= SUBSTR([实际路线到达点],0,1))
then '是'
when [实际路线到达点] is null or [实际路线到达点] = ''
then '否'
else '否'
end
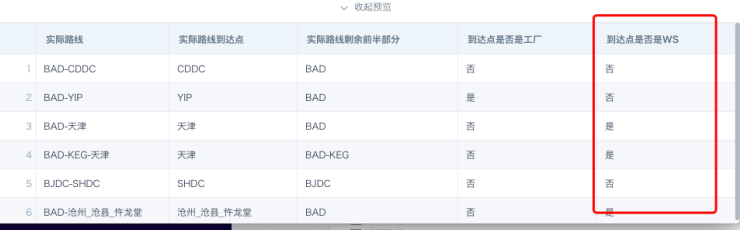
- 到达点是否是WS:WS的判断标准是纯汉字,无其他字母、数字。
when SUBSTR([实际路线到达点],-2)='DC' or (SUBSTR([实际路线到达点],0,1) <='Z' AND 'A'<= SUBSTR([实际路线到达点],0,1))
then '否'
when [实际路线到达点] is null or [实际路线到达点] = ''
then '否'
else '是'
end
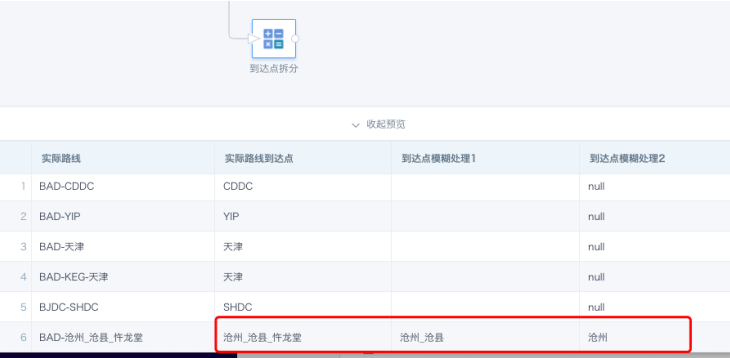
- 到达点拆分
示例:
实际路线=BAD-沧州_沧县_忤龙堂
实际路线到达点=沧州_沧县_忤龙堂
到达点模糊处理1=沧州_沧县
到达点模糊处理2=沧州
-- 到达点模糊处理1
REGEXP_EXTRACT([实际路线到达点],'(.+)(_{1}.+)',1)
-- 到达点模糊处理2
case when INSTR([实际路线到达点],'_')>0 then SUBSTR([实际路线到达点],0,INSTR([实际路线到达点],'_')-1) end
案例二:新建计算字段,把原字段用分隔符拆分为数组,定位数组元素位置从而进行拆分
- 拆分为 array:split([字段],'-')**
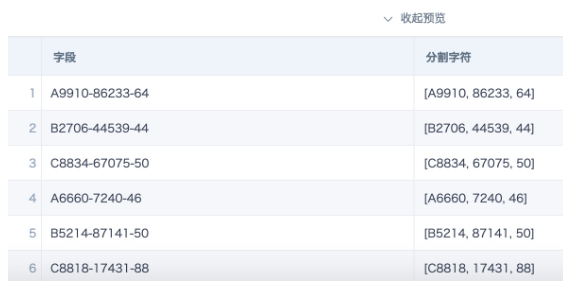
- 去除结尾部分:array_join(slice([分割字符],1,size([分割字符])-1),'-')
拆分字段 1:[分割字符][0]
拆分字段 2:[分割字符][1]
结尾部分:array_join(slice([分割字符],size([分割字符]),1),'')

案例三:截取字符串中文/英文部分
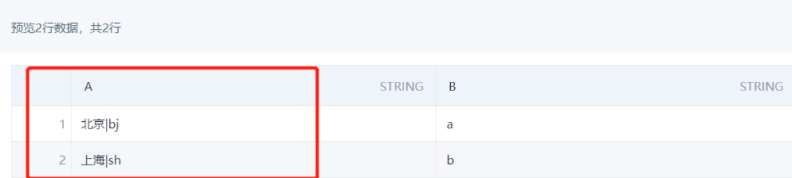
实现方法:可以通过新建字段使用正则表达式来实现。
- 保留中文:

- 保留英文:

最终结果:

【注意】:以上函数可以用于 ETL 和非直连非加速数据集,直连数据集请使用对应数据库函数,高性能(加速)数据集需要使用 Clickhouse函数。更多文本处理函数和案例请参考Spark SQL文本函数及应用。