高性能查询表(高级选项)
概述
功能说明
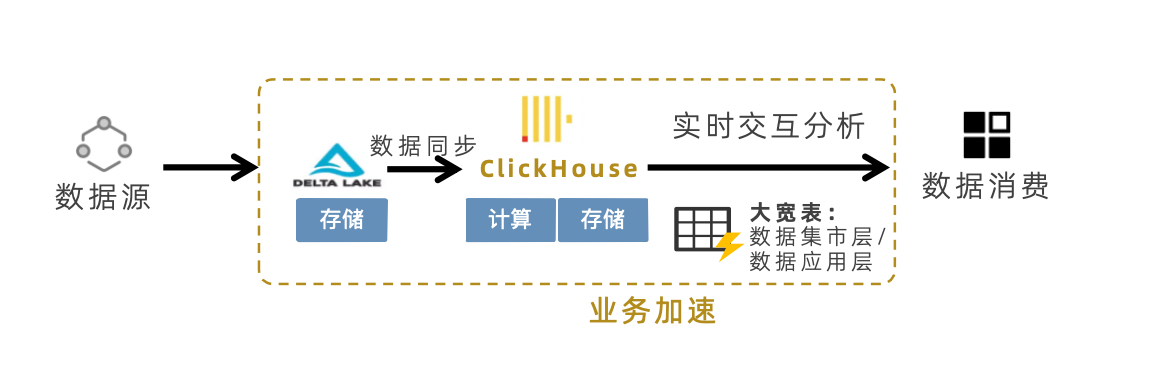
高性能查询表,是观远BI提供的一种数据计算与存储的加速服务,将Guan-Index数据集、文件数据集、ETL输出数据集转换为高性能查询表,可以实现数据分析与查询加速,达到亿级数据秒级计算的效果。高性能查询表具有如下优势:
- 极致的查询性能:高性能查询表以分布式计算,来实现高扩展性能,特别适合海量数据下的OLAP查询,适合在大宽表上做任意维度的数据聚合、切片(筛选),也可做明细数据的查询。相比直接使用Spark作为计算引擎,可提供更好的即席查询体验。
- 简单的使用方式:通过界面化的方式,简单点选,即可配置分区字段,进行模式切换。整体使用过程零代码、低门槛,无须具备技术背景。支持完善的SQL,功能简单,操作灵活强大。
- 高效的存储方案:高效的数据压缩技术,提供10倍压缩比,提升了单机存储能力和计算能力,满足高并发、高吞吐的数据查询与分析场景。
高性能数据集为付费增值服务,具体使用详情可联系您的观远顾问。
应用场景
当「抽取、ETL数据集」面对以下的问题时,建议用户使用「观远极速引擎」,实现数据集一键切换至「高性能查询表」。
- 交易报表:对于零售的订单和财务数据,查询时需要多表关联和大量的精确计算,大宽表或关联表查询性能堪忧,海量数据报表难以实时,会面临复杂的查询情况;
- 大促分析:大促期间的数据大屏需要实时计算和呈现各类核心指标,SQL多并发较大,数据可用性有待验证;
- 用户分析:在分析场景涉及到像留存率、转化漏斗等计复杂的数据计算模型,分析维度并不固定因此也无法做预计算,分析覆盖的数据周期较长,明细数据的大查询较多。
前提准备
由于高性能查询表是利用了ClickHouse的OLAP分析能力,因此除了部署BI系统主服务外,还需要采购观远极速引擎模块,并为用户独立部署ClickHouse。
配置要求:一般建议ClickHouse进行独立部署,配置不低于8核64G内存,磁盘空间不少于300G。具体部署与配置将由观远数据工作人员为您完成,详情请咨询观远数据工作人员。
使用指导
数据集发布为高性能查询表
使用ClickHouse进行查询加速的数据集我们都称之为「高性能查询表」。所有Guan-Index数据集、文件数据集、ETL输出数据集都可以支持「高性能查询表」的加速功能。
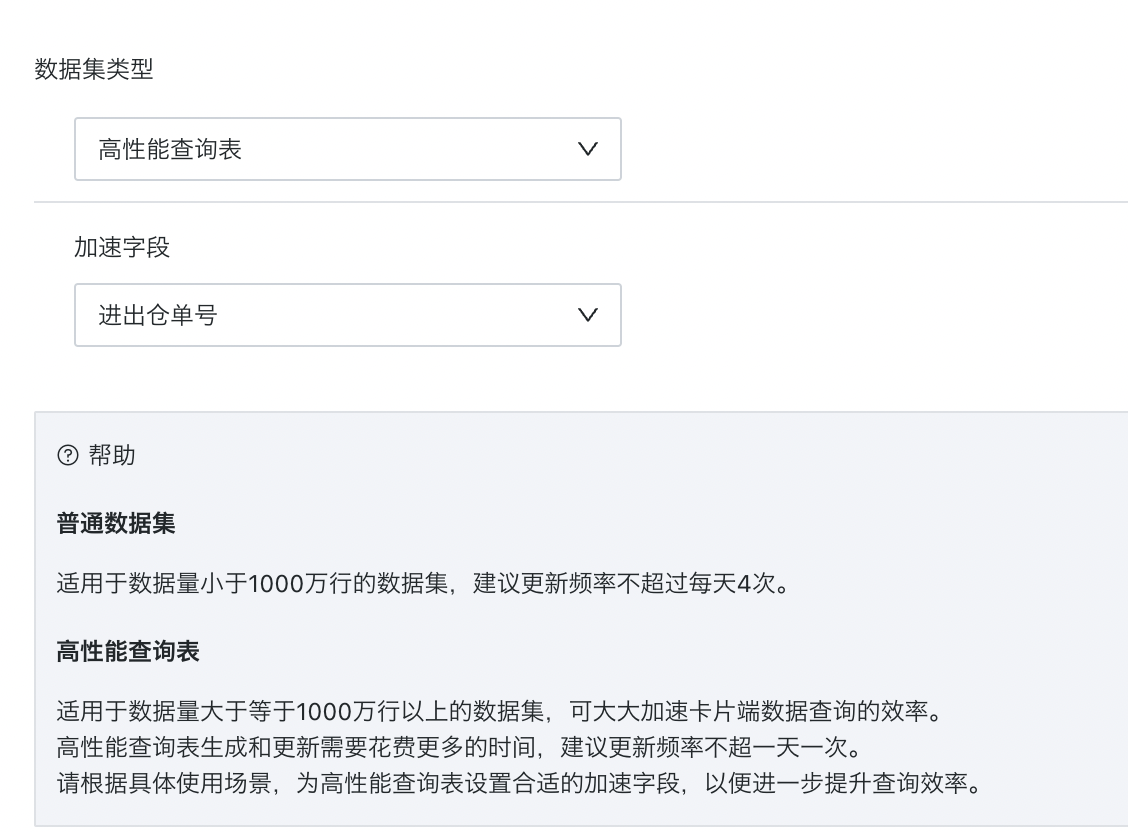
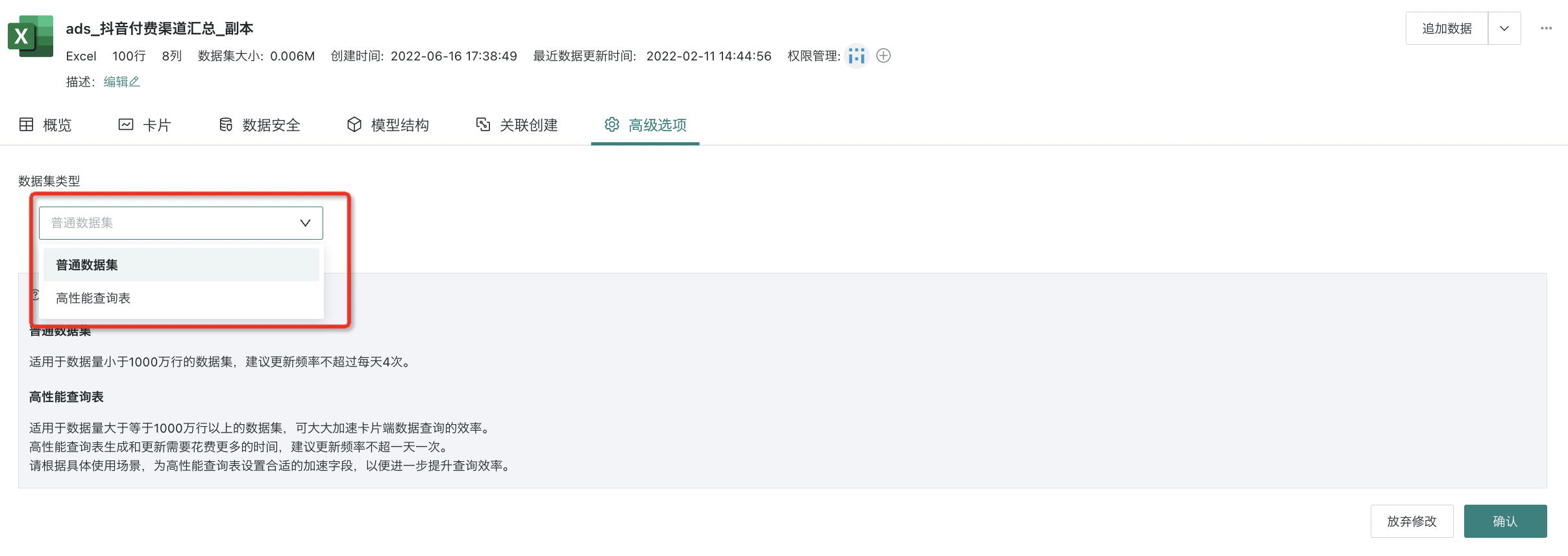
- 进入数据集详情页,选择「高级选项」,点击右上角「编辑」按钮,用户就可将普通数据集切换为「高性能查询表」。这样数据就会被导入ClickHouse内,卡片端进行数据查询计算时就会直连ClickHouse进行加速查询。普通数据集和高性能查询表的介绍如下:
-
普通数据集:适用于数据量小于 1000 万行的数据集,建议更新频率不超过每天4次。
-
高性能查询表:适用于数据量大于等于 1000 万行以上的数据集,可大大加速卡片端数据查询的效率,但在功能层面会有所限制,比如不能使用窗口函数。高性能查询表生成和更新需要花费更多的时间,建议更新频率不超一天一次。需要根据具体使用场景,为高性能查询表设置合适的加速字段,以便进一步优化查询效率。一般我们建议以日期字段作为加速字段。
-
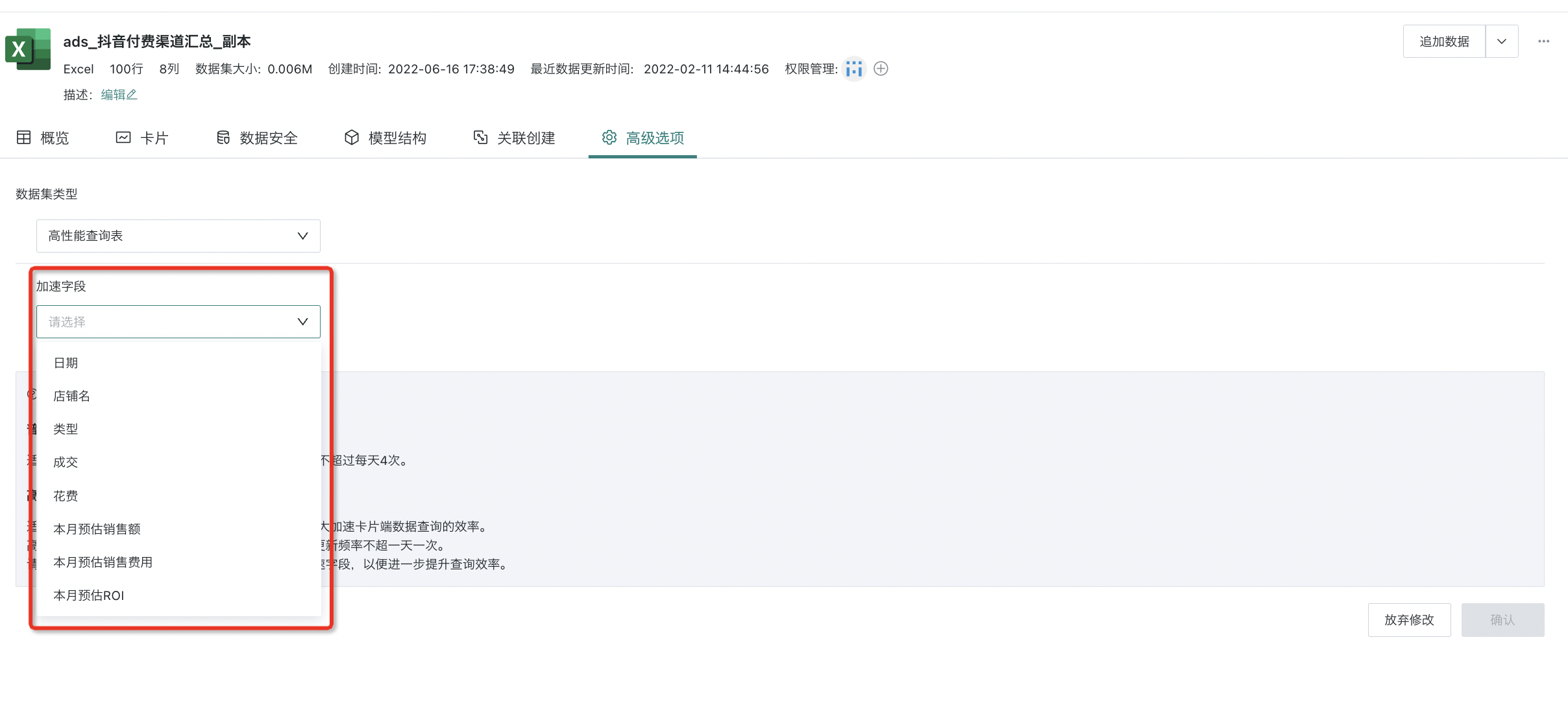
在配置「高性能查询表」模式时,用户需要设置加速字段:设置加速字段是为了数据在ClickHouse内存储时能更好地分片,合理的分区可以大量减少数据查询时的全表扫描。一般建议使用日期字段来做分区,分区方式建议设置为「月」或者「日」。使用日期字段做分区,可以有效地控制分区数量,不至于把分区做得过粗或者过细。如果没有日期字段,也可以谨慎选择其他字段进行分析,此时请务必控制分区字段的枚举数量,请勿选择类似订单ID之类的流水号,或者数值类字段作为加速字段。
-
配置完加速字段后,点击「确认」即可开始模式切换。数据集数据量大的时候,数据导入到ClickHouse可能需要花费一定的时间,请耐心等候。经观远BI内部测试,1000万行20列的数据集导入ClickHouse耗时约2min。数据集更新也会触发ClickHouse内的数据重新导入,建议「高性能查询表」的更新频率不超过一天一次。
以下为配置了查询加速功能的Hive数据库数据集,从表面来看它似乎与一般的Hive数据库数据集并无二异。但我们在使用它创建卡片时,则是利用ClickHouse来作为查询引擎,能够提供飞一般的急速体验。
使用高性能查询表构建可视化分析
使用高性能查询表创建卡片时,需要遵守ClickHouse的SQL语法。目前ClickHouse已支持窗口函数。
同时,若需要在高性能查询表上应用行列权限,那么行列权限的表示也需要使用ClickHouse的SQL语法进行编写,例如用户属性中门店的内容为当前用户所管辖的门店编号,并以逗号分割,则行列权限可设置为:
has(splitByChar(',',[CURRENT_USER.门店]),[店铺编号])
注意事项
(1)「高性能查询表」适用的数据量一般为单表1000万行以上,可大大加速卡片端数据查询的效率。数据量小于1000万行的数据集,本身基于Spark计算已经能提供较好的响应体验,一般不建议使用「高性能查询表」。
(2)建议尽量不在细粒度的维度上进行聚合运算,若明确知道查询的就是明细数据,那么直接使用「明细表」来查询将获得更好的性能体验。
(3)建议查询时带上分区字段相关的筛选条件,这样查询效率将大幅提升,与此同时,分区字段也请基于常用的查询筛选条件进行设计。
(4)建议在下述环境条件下运行极速引擎:
运行的软件环境:
-
Windows操作系统下,建议使用Chrome或Firefox浏览器;
-
iOS操作系统下,建议使用Safari浏览器;
运行的硬件环境:
-
CPU:Intel处理器八核1.9GHz或同等及以上处理能力;
-
内存:RAM64GB或以上;
-
硬盘:300GB或以上。