报错说明
概述
本文将介绍观远BI多源数据接入、数据准备、数据分析与可视化等模块的报错。
多源数据接入
数据集
/guandata-store/table_cache/guanbi/XXX doesn't exist
问题描述:
连接Hive数据库创建数据集的时候,代码是可以跑出数的,预览也都正常,但是报错:/guandata-store/table_cache/guanbi/XXX doesn't exist。
报错原因:
数据集创建后还在排队,没有运行完。
解决方案:
等任务结束就好了,用户往往会在数据集没有运行完的时候就去点击预览等操作。
Field SKU is not unique in Record
问题描述:
在Oracle能正常跑的数据库,但在观远里创建数据集时报错:Field SKU is not unique in Record。
报错原因:
观远数据不支持同名字段。 在Oracle 的Client里,只是做查询跟显示, 但在观远这里是要做存储的,需要不同的名称。
解决方案:
重命名字段。
Prepared statement needs to be re-prepared
问题描述:
数据集新建概览时提示“数据库异常,请联系数据库管理员,错误详情:Prepared statement needs to be re-prepared”。
报错原因:
这是本地数据库自身的报错,数据库缓存大小设置有关。
解决方案:
通过修改以下参数来解决
set global table_open_cache=16384;
set global table_definition_cache=16384;
column ambiguously defined
问题描述:
创建数据集时,数据库预览报错,"column ambiguously defined"
报错原因:
1)未明确定义列。如:select 查询的字段在from的两张表中都存在,导致数据库无法区别需要查询的字段来自于哪张表。
2)查询中有重复字段。如:select a.name,a.name
No such file or directory
问题描述:
情况 1:数据集更新任务取消之后马上对同一个数据集进行更新,出现报错No such file or directory。
情况 2:自动更新失败报这个错误且自动更新的时间设置在凌晨一点。
报错原因:
情况 1 原因:用户在取消更新任务之后 马上进行了重新更新的任务,此时取消更新任务之后,正在删除目录下的所有东西,但是此时任务展示结束,其实还是在删除中,我们重新更新的时候,会下发一个新的任务,创建文件夹和文件,但是这个文件夹和文件 会被没有完成的取消了的任务给删掉,就导致报No such file or directory 错误。
情况 2 原因:BI系统每天凌晨一点会自动删除空的文件夹,而与此同时数据集更新的时候也是会新建一个新的文件夹随后新建avro文件,此时有小概率的可能出现刚新建好一个空的文件夹,就会被定时清理任务自动删除。那么就会出现No such file or directory的报错。
解决方案:
情况 1 解决方案:
-
用户取消任务之后不要马上更新数据集 等待几分钟后再更新。
-
出现该报错后,过一会重新更新。
情况 2 解决方案:
-
设置自动更新的时间避开凌晨一点。
-
配置失败重试功能,只要过了一点重试就能自动更新而文件夹不会被删除。
Cannot call methods on a stopped SparkContext
问题描述:
任务执行失败,报错:Cannot call methods on a stopped SparkContext。数据集更新、ETL运行大批量报错。
报错原因:
磁盘使用率高。
解决方案:
检查方法:资源监控。
联系运维运维介入处理,看是否可以清理磁盘,若无效果,可评估磁盘扩容方案。
java.io.IOException: org.apache.hadoop.hive.ql.metadata.HiveException: java.lang.ClassCastException
问题描述:
数据集更新报错:java.io.IOException: org.apache.hadoop.hive.ql.metadata.HiveException: java.lang.ClassCastException。
报错原因:
类型转换异常,原来的字段类型和新的字段类型不一致。
解决方案:
可以看下数据集预览是不是成功的,预览的数据有没有看起来明显是不符合预期的字段。
total length XXX
问题描述:
新建TIDB数据集预览成功,更新报错,报错信息为整段 SQL 语句后加total length XXX。
报错原因:
注释不能被忽略造成的语法错误。检查日志真正是报错是:You have an error in your SQL syntax; check the manual that corresponds to your TiDB version for the right syntax to use line XXX 。
解决方案:
根据此报错,删除SQL中的注释后数据集能正常更新。
数据量超出允许阈值
问题描述:
Web Service数据集更新时报错:数据量超出允许阈值。
报错原因:
为了保证数据更新的成功率以及BI性能的问题,对web service数据集更新时,系统限制的最大是19M(即单次更新,数据量不能超过19M)。
解决方案:
修改字段,减少内容。
Disk I/O error: Failed to open HDFS file
问题描述:
直连数据集更新报错提示Disk I/O error: Failed to open HDFS file。
报错原因:
数据库找不到相关文件。
解决方案:
确认数据库连接信息。先去源数据库内确认数据库信息是否变化,尝试在源库内执行更新SQL,建议联系内部数据库管理员处理。
Error getting connection from data source HikariDataSource(HikariPool-10)
问题描述:
数据集更新报错:Error getting connection from data source HikariDataSource(HikariPool-10)
报错原因:
这个报错通常是因为数据库连接池满导致的,可能之前的任务连接没有被完全释放导致的这个报错。通常这样的错误只要数据账号和网络环境没有问题,手动更新就可以更新成功;如果手动更新也是失败,需要查看数据账号的测试连接是否正常,如果测试连接正常,那说明BI和客户端数据库的连通性是没问题的,大概率是BI的连接池满了。需要查看报错时间段具体日志信息。
解决方案:
(1)业务要看实时数据,不希望有任何缓存: 可以在数据集上开一下支持实时卡片数据-无缓存
(不过要提醒的是这样每次业务使用报表,都会直接向数据集发出请求,会增加数据库压力)
(2)数据集大量更新失败,更新时间太集中了,可以错开一下设置的更新时间。
Packet for query is too large
问题描述:
数据集更新/抽取时报错:Packet for query is too large。
报错原因:
BI内置的mysql 配置的参数太低。
解决方案:
需要观远运维修改BI内置mysql的配置,详情联系观远售后工作人员协助。
/guandata-store/table_cache/guanbi/*********` is not a Delta table
问题描述:
配置数据抽取,sql预览是正常的,但是配置完成后去概览看就报这个错:`/guandata-store/table_cache/guanbi/*********` is not a Delta table。
报错原因:
配置完成后数据还没完全抽上来,任务还在运行,所以会弹出这个报错。
解决方案:
待任务运行完成后再查看就可以了。
java.nio.channels.UnresolvedAddressException
问题描述:
预览正常 但是抽取数据集的时候报java.nio.channels.UnresolvedAddressException。
报错原因:
hdfs某个地址解析不了。预览其实只访问1-2个节点就行,但抽全量数据, 要访问很多节点机器。
解决方案:
排查步骤:
- 查看这个源数据库的类型是不是impala和hive。
2.抽取或者预览的时候是不是报java.nio.channels.UnresolvedAddressException (预览可能正常 但是抽取肯定会报错)。
联系开发人员检查配置。
Error retrieving next row
问题描述:
数据集更新报错:Error retrieving next row。
报错原因:
超时或者网络波动导致无法获取到下一行数据。
解决方案:
-
进入任务管理-查看任务详情,如果没有fetch记录 则说明超时 ,如果fetch到一半出现失败则说明是网络波动。
-
进入数据集打开失败重试功能,失败就自动重试 。
empty.max
问题描述:
上传文件报错:empty.max。
报错原因:
文件内行列属性不兼容/不标准。
解决方案:
修改文件。上传的只是能行列纯数据,不要带有excel的样式(比如合并单元格等)。
“非法转换”
问题描述:
修改了数据集的字段类型后更新报错“非法转换”。
报错原因:
不建议直接在数据结构中转换数据类型。比如不支持STRING直接改成了TIMESTAMP。
解决方案:
将某种数据类型的表达式转换为另一种数据类型,需要用函数对数据库进行转换,常用CAST函数。
Query exceeded distributed user memory limit of XXX
问题描述:
在添加日期区间比较大,数据量比较多的数据集时,报错: Query exceeded distributed user memory limit of XXX 。
报错原因:
一般是sql太复杂了,运行内存不够了。
解决方案:
如果数据量减少不了的话,看看能不能优化sql减少运行内存:
-
不用的字段不要select 出来,这样能减少内存压力。
-
建议涉及到partion by, group by, order, join等的sql,在berserker上生成表方式,或者做宽表,然后在BI里面查,这样会更快,也容易保障。
Exception: Memory limit (total) exceeded: would use xx GiB
问题描述:
一般情况出现在数据集偶尔报错,如Exception: Memory limit (total) exceeded: would use xx GiB。
报错原因:
内存/空间不足。
解决方案:
-
优化查询:检查您的查询语句,尽量减少不必要的计算和数据加载,使用更简洁高效的查询方式。
-
减少数据量:如果您的数据量过大,可以考虑缩小查询范围或者分批处理数据,以减少内存占用。
-
增加内存:如果您的服务器配置允许,可以尝试增加内存大小,以满足更大的数据处理需求。
-
联系观远客服:如果以上方法无法解决问题,建议您联系观远售后工作人员为您提供更详细的技术支持和解决方案。
Incorrect syntax near ";"/missing right parenthesis\n
问题描述:
同样的SQL在本地执行正常,BI中预览报错:Incorrect syntax near ";"/missing right parenthesis\n。
报错原因:
预览是先将输入的SQL查询结果存入临时表中,再从临时表中取最终结果的。所以在SQL后面以分号结尾会报语法错误。
解决方案:
去掉结尾的分号即可。
The maximum length of cell contents (text) is 32,767 characters
问题描述:
数据集导出的时候报错:The maximum length of cell contents (text) is 32,767 characters。
报错原因:
excel自身的特性。因为Excel单元格的字符只能是32,767以内。
解决方案:
建议处理数据以后再次重试,参考文档:https://blog.csdn.net/weixin_43957211/article/details/109077959。
null, message from server: "Host 'xxx.xxx.x.xxx'
问题描述:
创建数据账号,测试连接报错:null, message from server: "Host 'xxx.xxx.x.xxx' 。
报错原因:
同一个ip在短时间内产生太多(超过mysql数据库max_connect_errors的最大值)中断的数据库连接导致的阻塞。
解决方案:
联系本地的数据库管理员执行:flush hosts 清理缓存。
域名无法解析,请服务器管理员确认DNS配置:xxxx
问题描述:
数据中心添加账户时报错“域名无法解析,请服务器管理员确认DNS配置”。
报错原因:
网络不通。
解决方案:
修改网络配置。
找不到相关连接器
问题描述:
数据账户列表出现未知类型 且报错找不到相关连接器。
部分数据账户无法编辑,无法查看血缘。
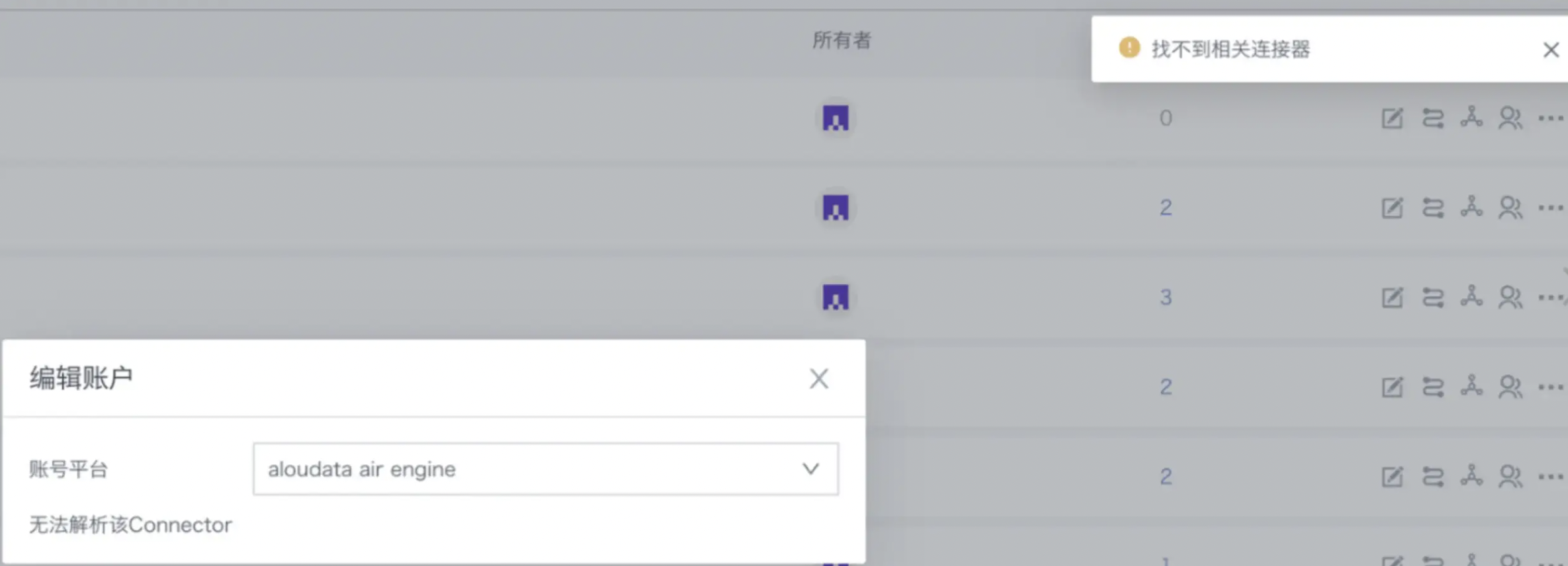
报错原因:
自定义链接出问题了。
解决方案:
重启开关自定义链接的开关,如果依然解决不了,可以联系观远售后人员进一步协助跟进处理。
账号验证错误Custom driver path:/guandata-store/jdbcdrivers/XXX does not exist
问题描述:
在数据账户中,选择了自定义驱动,输入相关信息后点击测试链接 马上出现以下错误:Custom driver path:/guandata-store/jdbcdrivers/XXX does not exist。
报错原因:
没有开启MinIO 导致自定义驱动路径找不到。
解决方案:
联系观远运维开启MinIO,随后再重新上传下自定义驱动即可。具体可连续观远售后工作人员。
Cannot reserve XXX MiB, not enough space
问题描述:
高性能数据集报错:Cannot reserve XXX MiB, not enough space。
报错原因:
ck(clickhouse)所在的存储数据盘满了。需要加大磁盘容量、清理不需要的数据或者挂载在其他大的容量的盘下面。
解决方案:
扩容,可能需要结合实际制定解决方案,如果有需要可以联系观远运维协助。
Connect to xxx.xx.xxx.xxx:xxxx [/xxx.xx.xxx.xxx] failed: Connection refused
问题描述:
Connect to xxx.xx.xxx.xxx:xxxx [/xxx.xx.xxx.xxx] failed: Connection refused
报错原因:
加速数据集一般数据量较大,过大的数据量(例如几亿至几十亿)转换可能会超出系统分配给Clickhouse的内存而导致Clickhouse重启,从而导致后续的数据集加速任务在链接Click house时Connection refused。
解决方案:
联系观远运维同学进服务器提高 Clickhouse配置的内存。
ClickHouse exception, code: 241, host: 10.250.156.78, port: 8123; Code: 241, e.displayText() = DB::Exception: Memory limit (for query) exceeded: would use 9.32 GiB (attempt to allocate chunk of 4718592 bytes), maximum: 9.31 GiB (version 20.4.5.36 (official build))
问题描述:
ClickHouse exception, code: 241, host: 10.250.156.78, port: 8123; Code: 241, e.displayText() = DB::Exception: Memory limit (for query) exceeded: would use 9.32 GiB (attempt to allocate chunk of 4718592 bytes), maximum: 9.31 GiB (version 20.4.5.36 (official build))
报错原因:
数据量过大,超出系统默认的9.31G。
解决方案:
联系观远运维同学进服务器提高 Clickhouse配置的内存。
ClickHouse exception, code: 60, host: 172.16.171.254, port: 8123; Code: 60, e.displayText() = DB::Exception: Table guandata.f957aeedb2dcd4313812bad7_new doesn't exist. (version 20.4.5.36 (official build))
问题描述:
ClickHouse exception, code: 60, host: 172.16.171.254, port: 8123; Code: 60, e.displayText() = DB::Exception: Table guandata.f957aeedb2dcd4313812bad7_new doesn't exist. (version 20.4.5.36 (official build))
报错原因:
删除了原临时表,创建了一个新临时表,再将新数据插入该表中。
两个对同一资源的更新任务并发时,可能会出现当前一个任务在进行插入新数据操作时,后一个任务刚好执行到删除原临时表的操作,此时就会报错表不存在。

解决方案:
需要保证同一资源同时只有一个更新任务。
用户调整数据集或者ETL的更新频率,避免出现两次数据更新相隔时间太近的情况。
高性能数据集如果分区超过100个是不是就不能切换了,若分区参数不选,对数据集的性能会有影响吗?
问题描述:
高性能数据集如果分区超过100个是不是就不能切换了,若分区参数不选,对数据集的性能会有影响吗?
报错原因:
1)普通数据集转换高性能数据集的时候是必须要选择分区的(分区也是构成高性能数据集能够高速查询底层框架)
2)同时分区太多也会影响查询速度,所以高性能数据集做了100个分区的限制,超过这个限制是不允许切换成高性能数据集的。
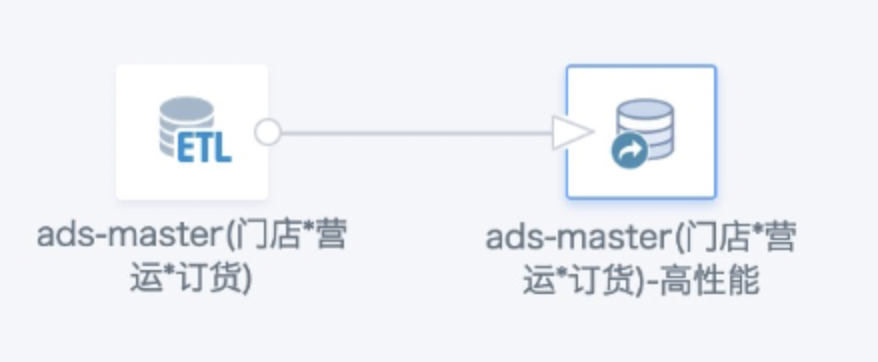
把数据集转换为高性能数据集后,为什么关联的ETL都运行失败了?
问题描述:
把数据集转换为高性能数据集后,为什么关联的ETL都运行失败了?
报错原因:
数据集转换为高性能数据集后,视同为 Clickhouse直连数据集,一旦作为ETL输入数据集使用,CK函数和spark函数会有冲突,ETL里无法识别数据集里用CK函数创建的字段和行列权限,从而导致ETL报错。仅在数据集没有行列权限,没有新建字段时可参与ETL。
解决方案:
仅建议把最后制作卡片用的大数据量数据集转换为高性能数据集,还要参与ETL处理的数据集不转换。如果数据集同时用于卡片和ETL,建议前一个ETL先输出ETL用的数据集,再多建一个ETL,输出转高性能用的数据集),一个转高性能用于卡片,一个用于ETL。参考下图。
ru.yandex.clickhouse.except.ClickHouseException: ClickHouse exception, code: 210, host: xx, port: 8123; Connect to xx failed
问题描述:
进行高性能数据集更新/转换/抽取的时候报错:ru.yandex.clickhouse.except.ClickHouseException: ClickHouse exception, code: 210, host: 10.x.x.138, port: xxxx; Connect to 10.x.x.138:xxxx [/10.x.x.138] failed: connect timed out。
报错原因:
超时或者配置被修改。
解决方案:
先看看历史上有没有运行成功的记录,如果有就检查配置以后重试,如果依然不能解决,联系观远售后进一步排查处理。
数据集更新失败 unknown error
问题描述:
unknown error是更新成功后,写历史任务的时候出错了。 导致认为更新失败了。这是一个偶现的问题,我们会考虑进一步的优化方案。
数据准备
智能ETL
Job Cancelled due to shuffle bytes limit, the threshold is XXX
问题描述:
ETL运行失败报错为“Job Cancelled due to shuffle bytes limit, the threshold is XXX”。
报错原因:
如果涉及到关联、聚合以及开窗函数等操作,Spark需要对数据根据键值进行分片处理,这个时候会产生Shuffle数据并且写入磁盘中。如果数据量很大,大量的shuffle数据会对服务器的磁盘产生比较大的压力。所以,在观远自己的计算引擎中,加入对于Shuffle使用量的检测。如果发现单个ETL的输出任务写入的Shuffle数据超出200G(默认配置),那job engine就会主动杀掉这个任务,并返回相关的错误。
解决方案:
-
对于磁盘充裕的用户,可以根据磁盘大小来调节Shuffle的上限。可以按照用户BI总磁盘的60%来设置上限,同时推最大的磁盘使用量尽量满足<85%的这个条件。需要联系观远方来操作。
-
升级到最新的job engine私有化版本(1.1.0+),我们在1.1.0中增加了对于磁盘容量的判断。只有磁盘使用量大于85%时,才会触发对于Shuffle使用的检测。
-
如果磁盘使用量已经很高了,一般不建议调整Shuffle上限,推荐优化ETL(例如拆分)。这样既能控制磁盘的使用量,又能满足Shuffle的限制。
org.apache.spark.SparkException: Could not execute broadcast in 300 secs. You can increase the timeout for broadcasts via spark.sql.broadcastTimeout or disable broadcast join by setting spark.sql.autoBroadcastJoinThreshold to –1
问题描述:
报错信息:org.apache.spark.SparkException: Could not execute broadcast in 300 secs. You can increase the timeout for broadcasts via spark.sql.broadcastTimeout or disable broadcast join by setting spark.sql.autoBroadcastJoinThreshold to –1。
报错原因:
join后的数据帧较大,需要耗费较长时间,而程序默认spark.sql.broadcastTimeout配置属性默认值为5 * 60秒,即300sec,这个远远不够,随着ETL复杂度越来越高,这个报错会很频繁。
解决方案:
设置一下spark.sql.broadcastTimeout参数,将它调大:如config("spark.sql.broadcastTimeout", "3600")。
Found duplicate column(s) ...
问题描述:
ETL提示有重复字段(Found duplicate column(s) ...,如图),实际上是没有一样的字段。
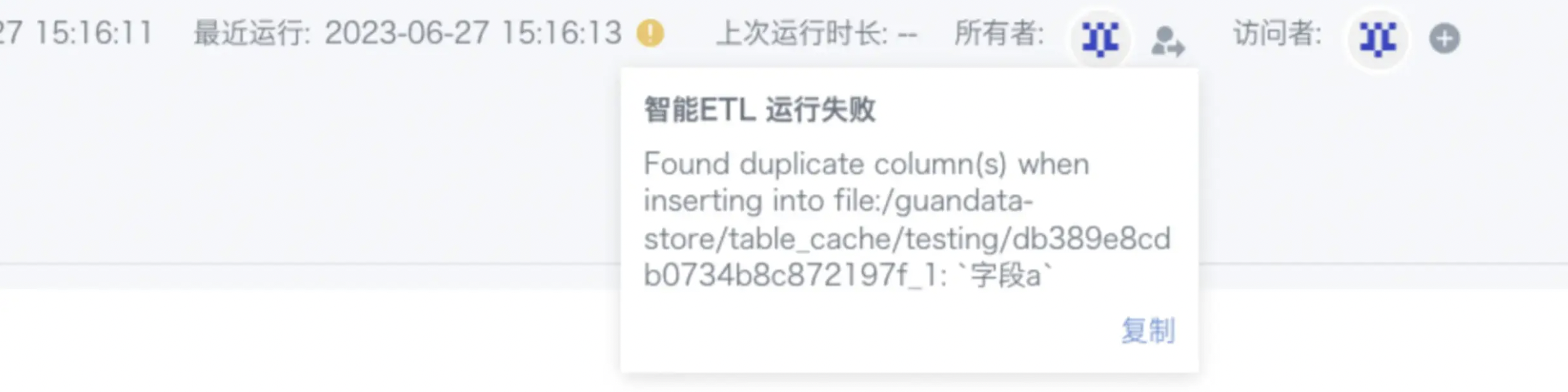
报错原因:
spark对字段名称大小写不敏感,在sql里面写大写和小写是没有区别的(如“字段A”和“字段a”就算是一样的)。
解决方案:
检查是否有报错字段相似的字段名,修改后重新运行。
Job 2632 cancelled because SparkContext was shut down 、engine lost
问题描述:
ETL运行报错:Job 2632 cancelled because SparkContext was shut down 、engine lost。
报错原因:
多个大的ETL同时运行,导致磁盘使用率过高,导致job engine重启;内存溢出导致job engine重启。
解决方案:
清理磁盘空间,检查资源配置;把运行时间较长(CPU占用时长)的ETL运行时间错开;具体问题具体分析。
Parquet data source does not support void data type
问题描述:
ETL所有节点都预览成功,但是运行报错:Parquet data source does not support void data type 。
报错原因:
用null值新建的字段,选择的字段类型无效 。
解决方案:
用函数为null指定类型,例如 cast(null as int)。

Illegal sequence boundaries: 19662 to 19606 by 1
问题描述:
ETL运行失败,报错 Illegal sequence boundaries: 19662 to 19606 by 1。
报错原因:
ETL里用了sequence 函数来实现两个日期之间按天(或按月)扩充,起始日期应该小于等于结束日期。如果起始日期大于结束日期,预览运行都会报错。19662和19606分别代表开始日期和结束日期的unixdate。
解决方案:
检查结束日期,确保结束日期总是大于等于开始日期。

Illegal sequence boundaries
问题描述:
ETL运行失败,报错 Illegal sequence boundaries: XXX to XXX by 1 。偶尔出现预览正常,但是运行就报错。
报错原因:
预览只会展示前200行,因为异常数据不在前200行,所以不能及时发现错误。通常是ETL里用了sequence 函数来实现两个日期之间按天(或按月)扩充,起始日期应该小于等于结束日期,只要有一条数据的开始日期大于结束日期,就会报错。
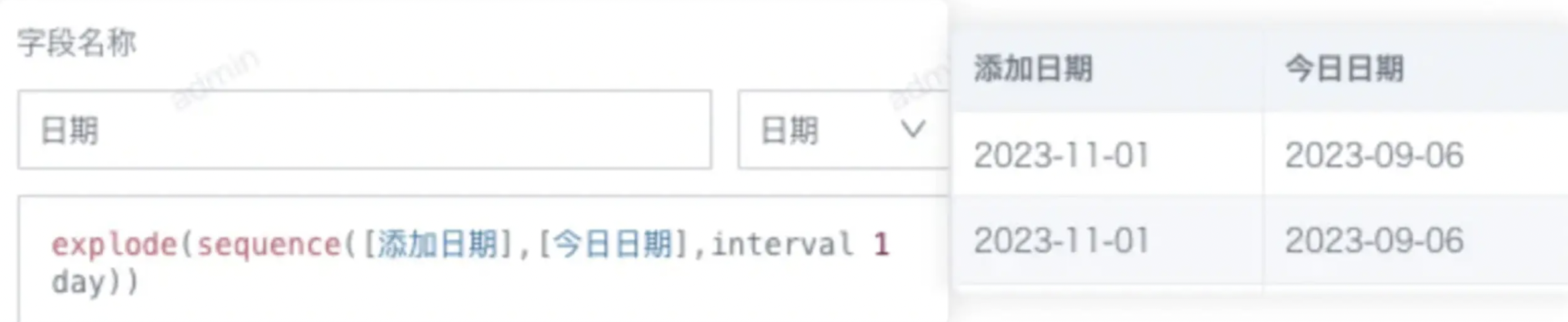
解决方案:
检查检查结束日期,确保结束日期总是大于等于开始日期。
Job aborted due to stage failure
问题描述:
ETL运行报错:Job aborted due to stage failure: Total size of serialized results of 2700 tasks (1024.2 MiB) is bigger than spark.driver.maxResultSize (1024.0 MiB)。
报错原因:
spark.driver.maxResultSize默认大小为1G,指的是每个Spark action(如collect)所有分区的序列化结果的总大小限制,就是说,executor给driver返回的结果过大,超过了限制。
解决方案:
修改spark.driver.maxResultSize这个参数,从1G改成2G。如果修改后还是不够用,可以在etl中新增一个输出节点,先把能合并的数据集输出,然后ETL会复用这个节点结果进行后续的逻辑。
cancelled because SparkContext was shut down
问题描述:
ETL运行报错:Job *** cancelled because SparkContext was shut down。
报错原因:
一般是任务运行时,导致磁盘过高,job engine被重启了。
解决方案:
磁盘进行清理,尽量保证有较为充足的使用空间;如果无法清理,建议客户进行磁盘扩容。
类型不匹配字段
问题描述:
运行/预览ETL时,分组聚合算子报错“类型不匹配字段:XXX”。
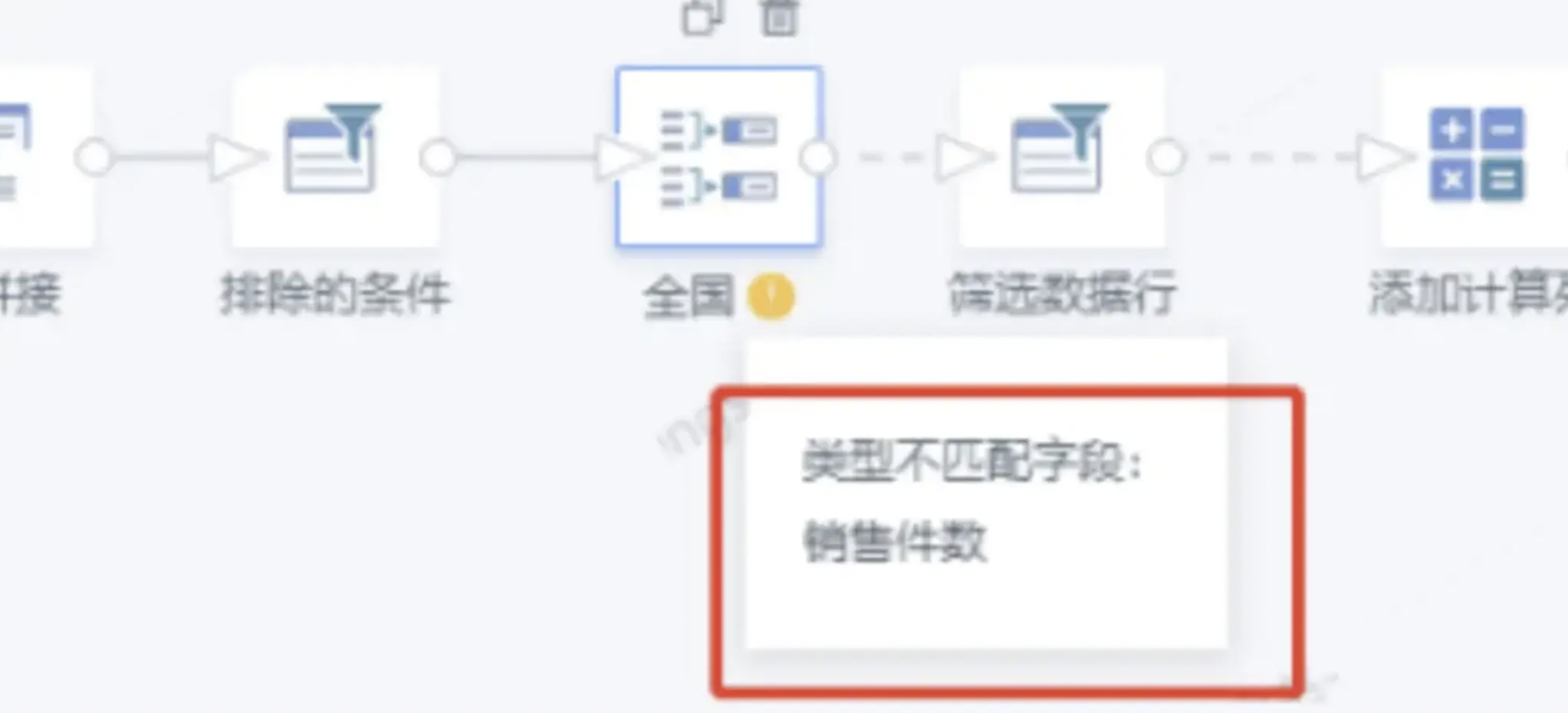
报错原因:
一般情况是字段类型被修改了。如上面的例子 报的是 销售件数 不匹配,最早的时候 该节点的前面四个sql输入的“销售件数”字段是long类型 因此传递到分组聚合字段的时候,也是long类型,随后修改了sql输入,或者原始数据集的类型发生了变化 导致“销售件数”的类型变成了double ,此时的确出现了类型不匹配的情况。
解决方案:
进入分组聚合算子,移除有问题的字段,再重新拖进来。
Cannot broadcast the table that is larger than XXX
问题描述:
ETL更新报错 Cannot broadcast the table that is larger than XXX。
报错原因:
超出了spark表broadcast join的限制,常见的情况可能是关联节点有无法匹配到数据的错误关联,导致关联后的值出现大量Null(这时数据会大量膨胀,容易超出了spark的broadcast join限制-8GB)。
解决方案:
修改关联字段,确保字段类型一致,关联有效。
[message] = Reference 'id_1666072244947.truck_id' is ambiguous, could be id_1666072244947.truck_id, id_1666072244947.truck_id.; line 1 pos 0
问题描述:
ETL中关联节点报错:[message] = Reference 'id_1666072244947.truck_id' is ambiguous, could be id_1666072244947.truck_id, id_1666072244947.truck_id.; line 1 pos 0。
报错原因:
多表交叉循环关联。已上图为例,因为A、B数据表上面已经join过了,所以不能存在B join C的情况下,再让A join C。
解决方案:
仅指定一张表当做关联的主表,避免多表交叉循环关联;复杂情况下建议拆分为多个关联节点。
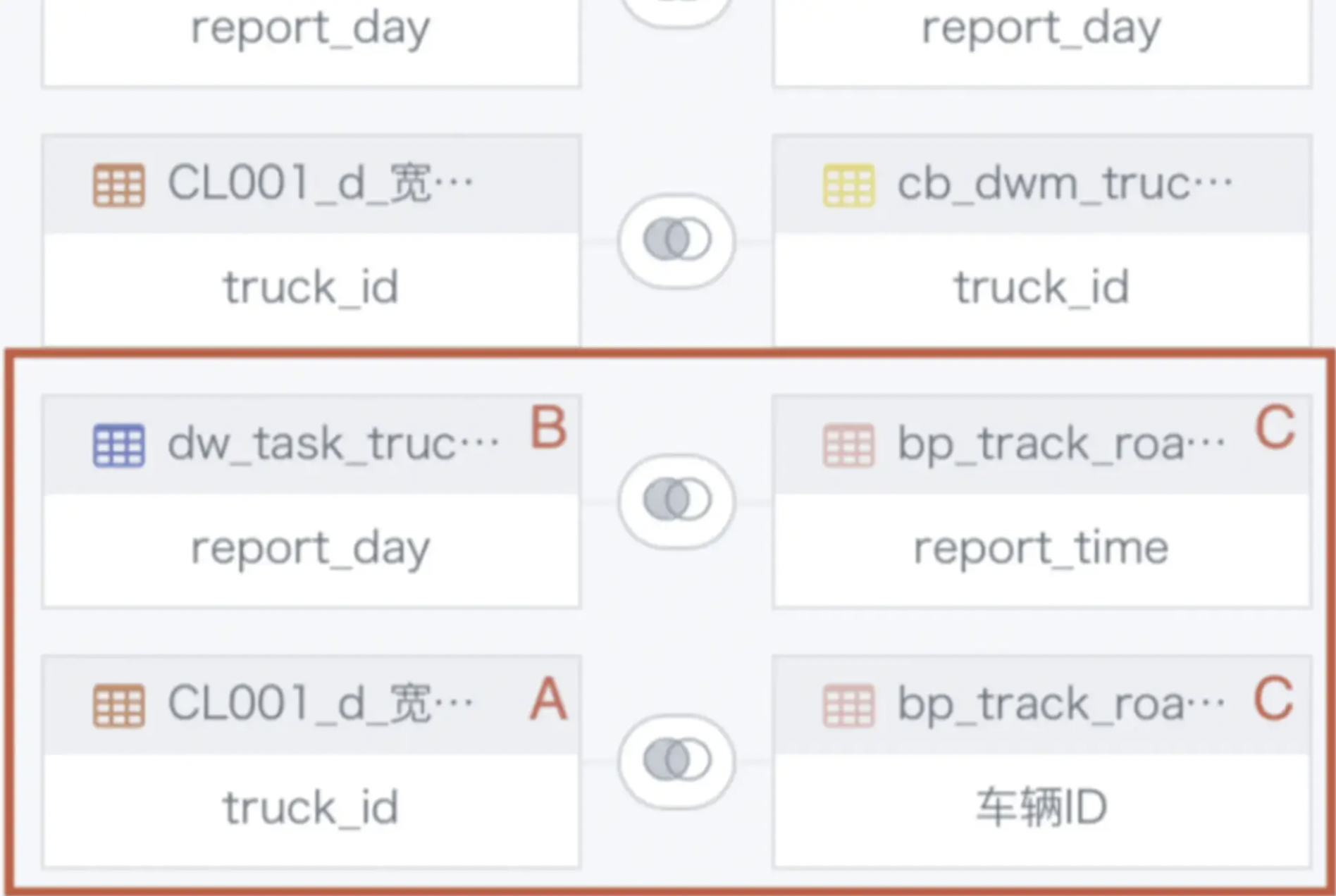
问题描述:
ETL中关联节点报错:[message] = Reference 'id_1666072244947.truck_id' is ambiguous, could be id_1666072244947.truck_id, id_1666072244947.truck_id.; line 1 pos 0。
报错原因:
多表交叉循环关联。已上图为例,因为A、B数据表上面已经join过了,所以不能存在B join C的情况下,再让A join C。
解决方案:
仅指定一张表当做关联的主表,避免多表交叉循环关联;复杂情况下建议拆分为多个关联节点。
ETL里值替换报错
问题描述:
ETL里值替换报错的可能原因是什么?
报错原因:
可能是字段类型的问题,比如数值字段如果替换为文本字段,那么就会报错。
解决方案:
这种情况下可以在替换之前加一个新建字段的节点,转换下字段格式。
ETL分组聚合节点提示丢失字段,但实际上并没有丢失该字段
问题描述:
ETL分组聚合节点提示丢失字段,但实际上并没有丢失该字段
报错原因:
大概率是这个字段id或者字段类型发生了改变,比如输入数据集字段做了变动(可能是把这个字段删除又重新建了一个,导致字段id变化),但是ETL里保留的是原先的字段,两个id对不上就会报丢失字段的错误。
解决方案:
重新拖下字段。
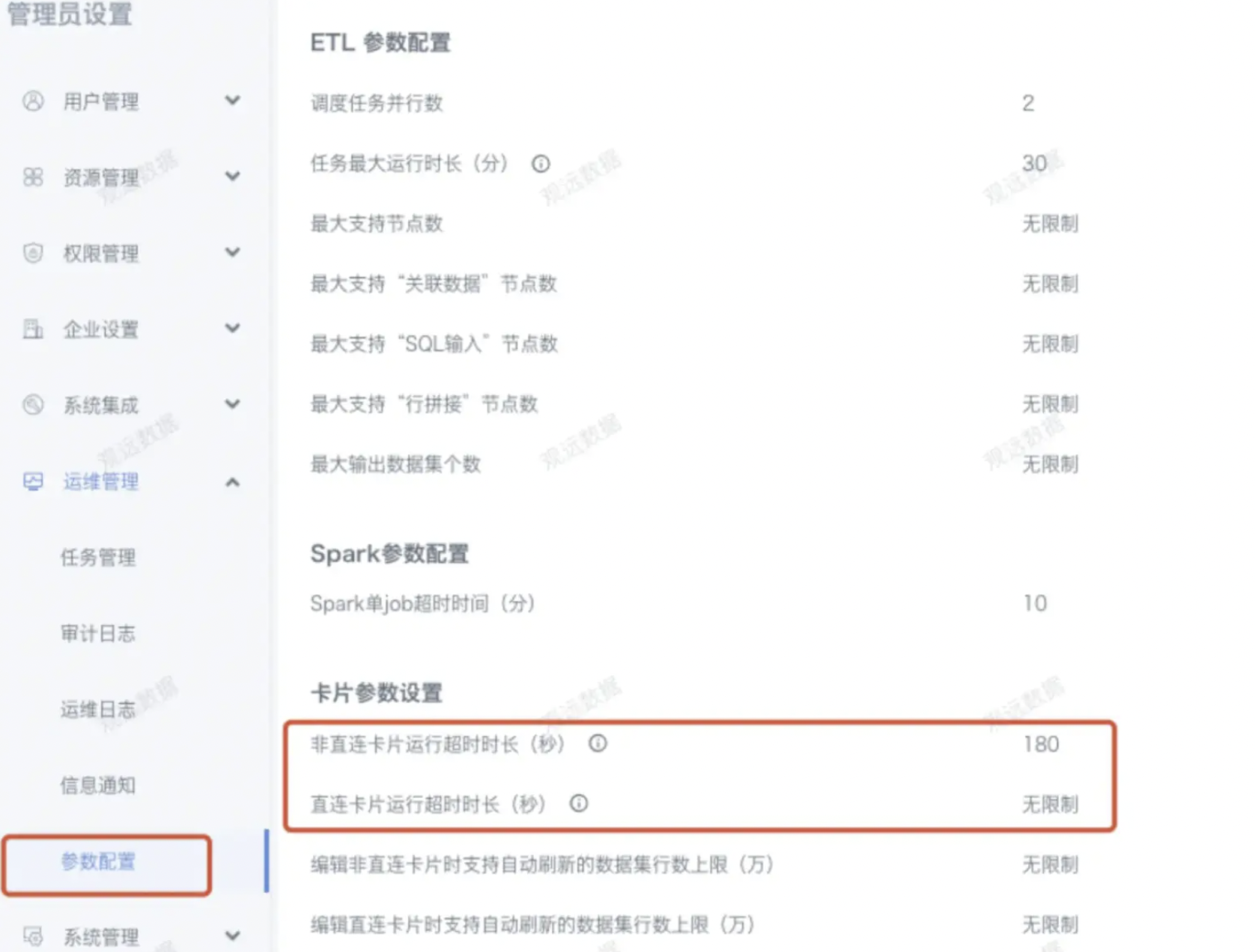
ETL运行报错 Job timed out
问题描述:
ETL运行报错 Job timed out。
报错原因:
ETL对应的Spark job运行超时。
解决方案:
管理员可以从 管理员设置 > 运维管理 > 参数配置 里修改ETL 任务最大运行时长 和 Spark单 job超时时间 ;运行时间过长建议优化或者拆分ETL。
数据分析与可视化
卡片
“当前任务已被取消,卡片:[xxx] 可能存在超时问题,请优化该卡片或稍后再试”
问题描述:
“当前任务已被取消,卡片:[xxx] 可能存在超时问题,请优化该卡片或稍后再试”。
报错原因:
当卡片运行时长超过阈值,系统里会认为卡片的设计不合理就停止运行了,避免因为一个很耗性能的卡片把系统资源吃完。
解决方案:
-
可以先看是个别卡片有问题还是大量卡片有问题。
-
如果是大量卡片都报这个错了,先考虑的是任务是否有堆积,在管理员设置那边看任务运行情况,确定系统所有任务都比以前慢或者有严重堆积排队的情况可以联系观远售后协助。
-
如果单个报错,看下卡片层面是否有合理,比如使用了很耗性能的函数/高级计算等,看是否有调优空间;另一方面看下数据量级是否很大,是否需要在etl层面做一些预处理提高性能,在卡片没有调整空间的时候考虑卡片参数设置的时间是否合理需要调大;一些预处理提高性能,在卡片没有调整空间的时候考虑卡片参数设置的时间是否合理需要调大。
Index xx out of bounds for length xx
问题描述:
卡片经常报错 Index xx out of bounds for length xx。
报错原因:
表头计算或者是二次计算存在并发,当卡片访问并发较高时会出现。
解决方案:
升级至5.9.0及以上版本可避免。
复杂报表
Index 0 out of bounds for length 0
问题描述:
复杂报表2.0,兼容LOOKUPEXP间隔扩展没有配置的数据。
报错原因:
模板公式中,存在勾选了间隔扩展,但是没有配置间隔扩展的视图名及字段名。
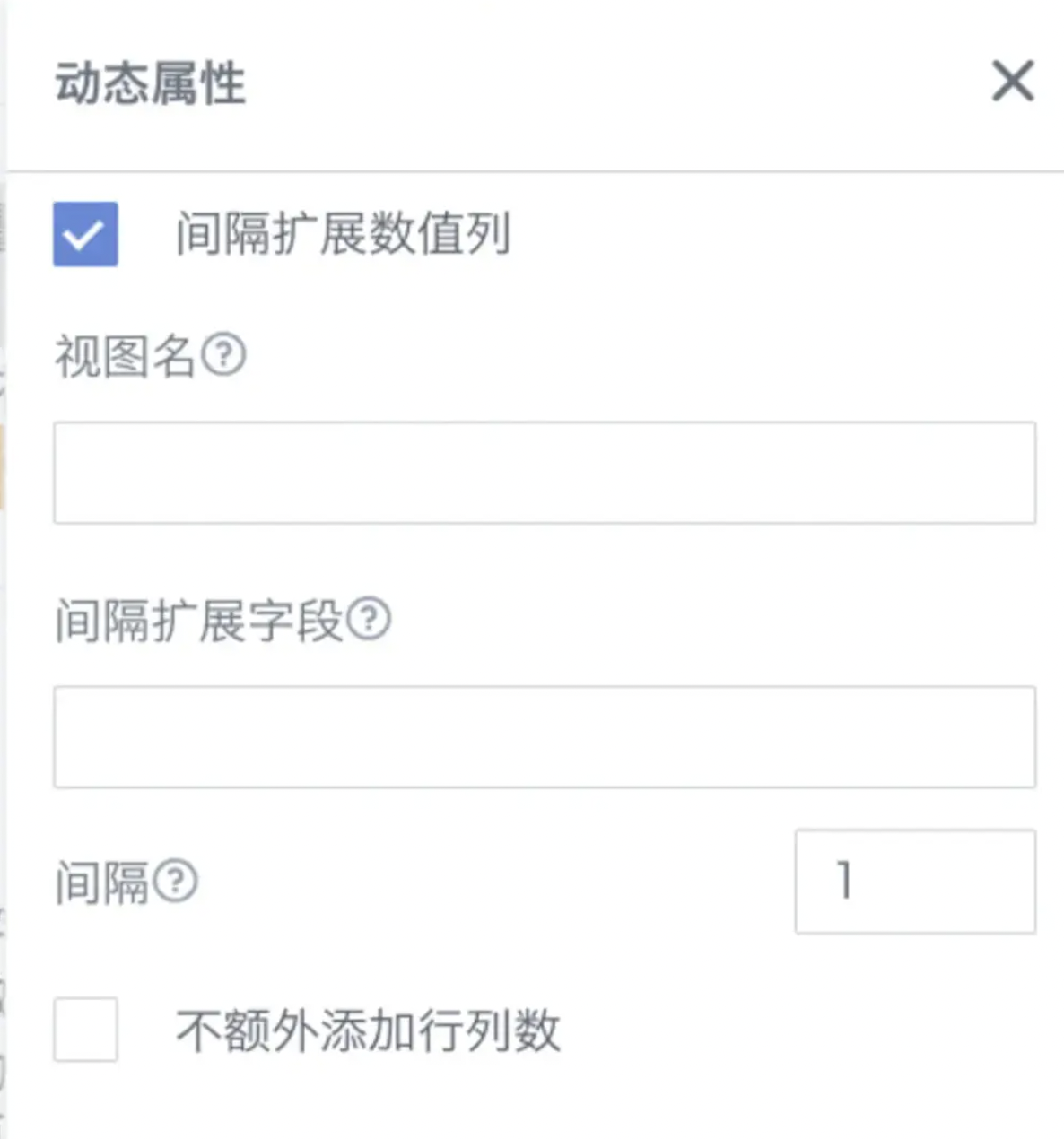
解决方案:
间隔扩展的视图名&扩展字段都配置上。
订阅分发与预警
订阅
“出错了”
问题描述:
移动端打开订阅链接提示“出错了”。
报错原因:
该用户对应的卡片、页面无权限。
解决方案:
需要赋予其对应资源的访问者或者所有者权限【5.6以上版本已优化】。
key not found: scanAppld
问题描述:
订阅发送至钉钉报错:key not found: scanAppld。
报错原因:
扫码登录应用信息未配置。
解决方案:
扫码登录应用信息以及微应用信息均需配置好。目前bi发送钉钉消息主要依赖于微应用的配置信息,但是其中的跳转链接需要使用扫码登录的配置信息来实现免密登录。
订阅发出的图片宽度与页面不一致
问题描述:
订阅发出的图片宽度与页面不一致。
报错原因:
订阅的页面导出逻辑和手动导出是一致的,与导出视图设置有关。
解决方案:
需要看导出视图的显示。
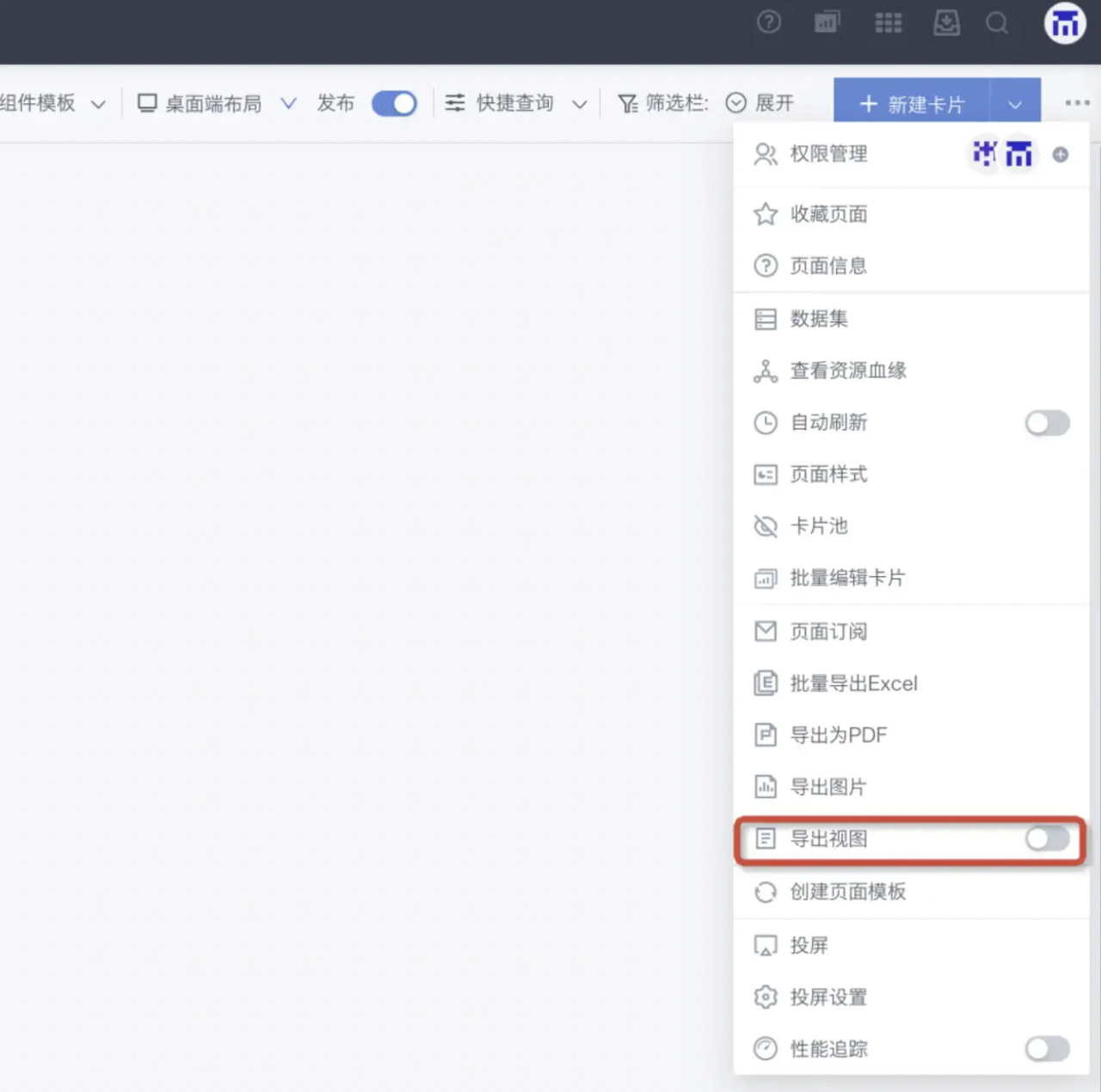
偶现Export CARD/PAGE FAILED
问题描述:
此类问题的报错形式包含但不限于Export CARD FAILED/Export PAGE FAILED、export failed due to load page 300000ms timeout: Timeout exceeded while waiting for event。
报错原因:
导出失败导致的订阅失败。卡片、页面获取数据超时/pdf服务超时/仪表板的卡片、页面存在异常。
解决方案:
调整参数。当前情况建议直接联系观远售后工作人员协助评估和做具体的调整。
预警
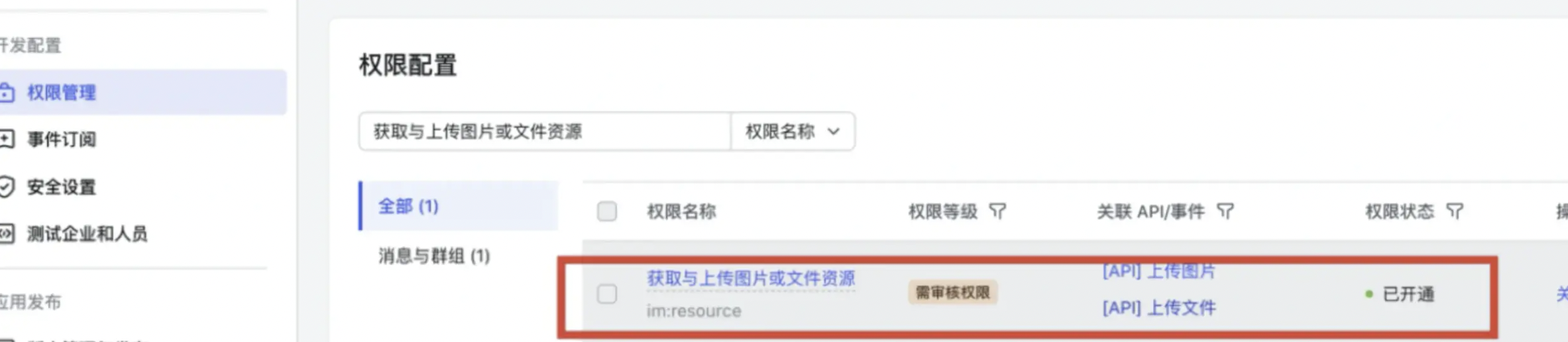
Failed to upload image : errCode = 99991672, errMsg = Access denied
问题描述:
预警到飞书失败,报错:Failed to upload image : errCode =。
报错原因:
飞书应用权限缺失。
解决方案:
飞书后台配置好权限。
开放与集成
OA集成
请求非法,请联系应用开发者
问题描述:
飞书集成报错:请求非法,请联系应用开发者。
报错原因:
飞书免密登陆会校验请求来源的地址是不是和后台配置的回调地址相同,如果不同则会报这个错误。
解决方案:
-
检查bi上面的管理员设置-系统管理-高级设置-域名配置是否正确。
-
在飞书后台看下这个应用的开发配置-安全设置-重定向url 是否配置的是bi的域名。
-
如果是从飞书的工作台打开应用时报的这个错,那就看下飞书应用配置里的 应用能力-网页应用-网页应用配置里的桌面端主页和移动端主页地址里,redirect_url是否正确(如果bi上域名配置正确,那可以直接复制bi上飞书配置最下方的链接)。
签名时间戳参数超时
问题描述:
钉钉登录失败:签名时间戳参数超时。
报错原因:
server登陆钉钉时生成的时间戳的时间和钉钉服务器时间相差1分钟以上。
解决方案:
调整server服务器时间。
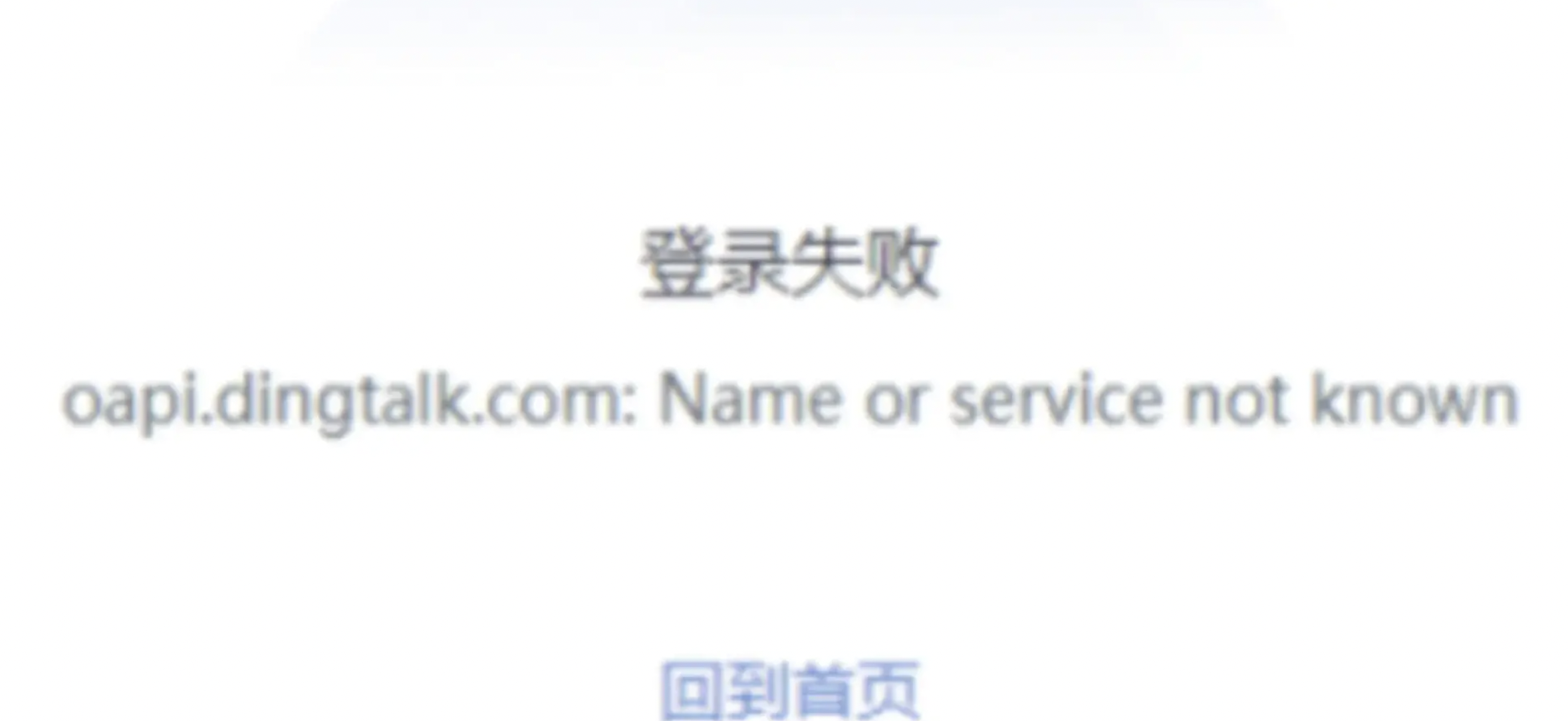
oapi.dingtalk.com: Name or service not known
问题描述:
钉钉集成报错:oapi.dingtalk.com: Name or service not known。
报错原因:
服务器出口ip变动导致实际出口ip与钉钉应用后台配置的出口ip不一致。
解决方案:
修改钉钉应用后台配置的 “基础信息-开发管理-服务器出口ip” 为实际出口ip即可。
你暂无权限登陆此应用,可联系公司管理员
问题描述:
企微应用登录提示:你暂无权限登陆此应用,可联系公司管理员。
报错原因:
1.账号不在应用的可见范围内 。
2.扫码的时候企业选择错误,要登录的账号不在选择的企业下。
解决方案:
先检查企业微信后台应用的可见范围,确认登陆的账号在这个可见范围内;然后确认扫码时选择的企业是自己要登陆的企业即可。

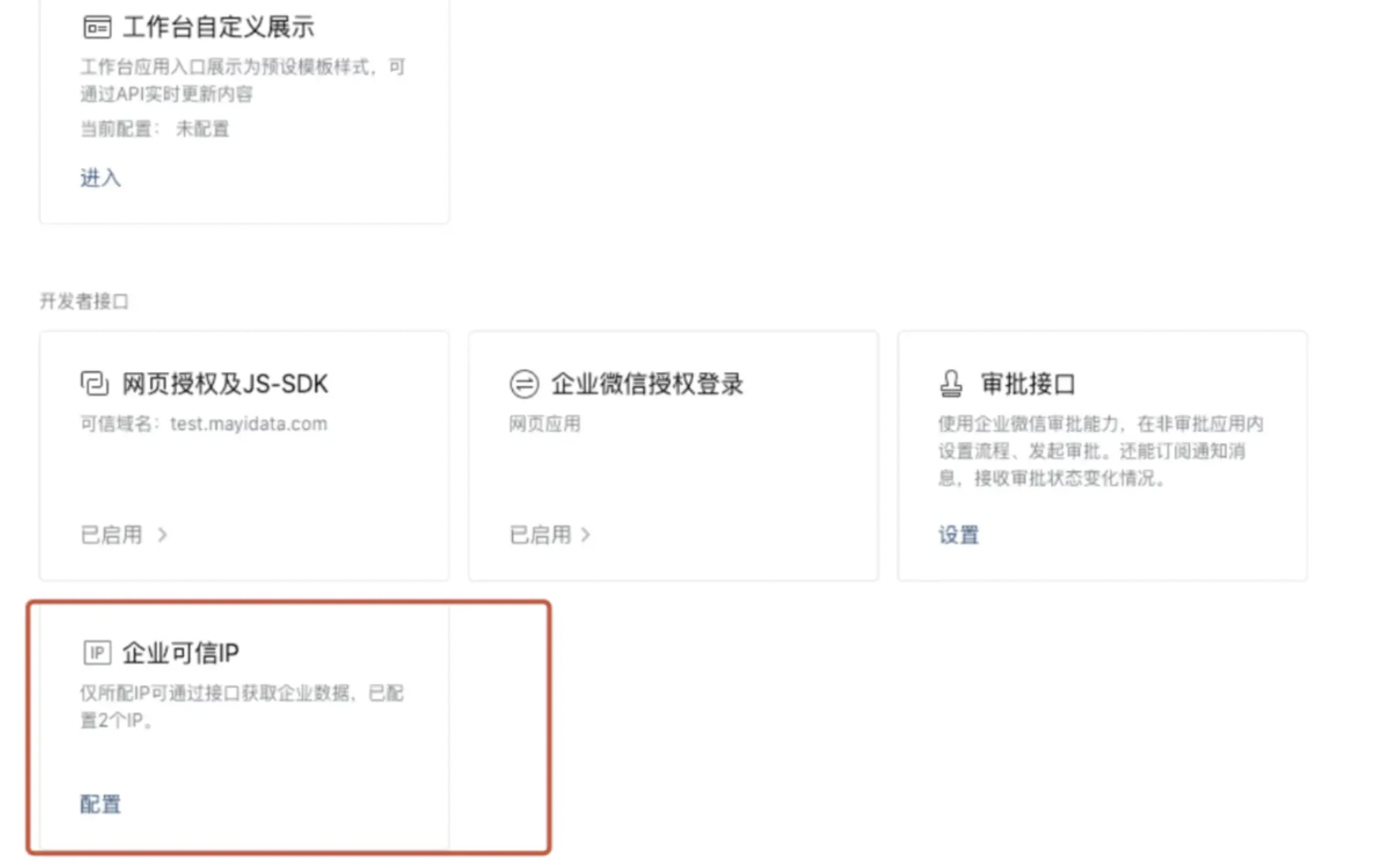
no allow to access from your ip
问题描述:
企微应用登录报错:no allow to access from your ip。
报错原因:
企微后台应用配置中,新应用会有一个企业可信IP配置,该配置没有填或者不包含BI服务器的IP。
解决方案:
需要把bi服务器的ip填进去(如果多台服务器都要填)。