按比例快速排序出数值的 Top N%
需求背景
想要查看某数值在指定维度下聚合后的 Top N%。例如,得到每月销售额总和位于整体排名前 15% 的门店列表,本文将基于该场景介绍实现方法。
关键函数
cume_dist()over(partition by [分组维度] order by [排序维度])
- cume_dist 计算逻辑:小于等于当前排序维度值的行数 除以 对应分组下的总行数。
- 默认升序排列,"order by [排序维度] desc " 实现降序排列。
- 优点:
a. 可直观看到每行数据在分组下排序的具体百分比;
b. 如果改变想要的百分比数值,无需修改数据,只修改筛选条件即可。
- 注意点:由于计算受数据行数影响,建议用 ETL 把数据聚合到适合颗粒度后再使用该窗口函数计算。
实现步骤
1. 在 ETL 里使用“分组聚合”,把数据聚合到需要的颗粒度。本案例里,按“门店名”和“月份”分组聚合,对销售金额求和,确保每个门店每个月只有一行数据。

2. 新建计算字段,分组字段和分组聚合的维度相对应,每月各个门店金额汇总降序排列并计算百分位。
cume_dist()over(partition by [年月] order by [金额] desc)
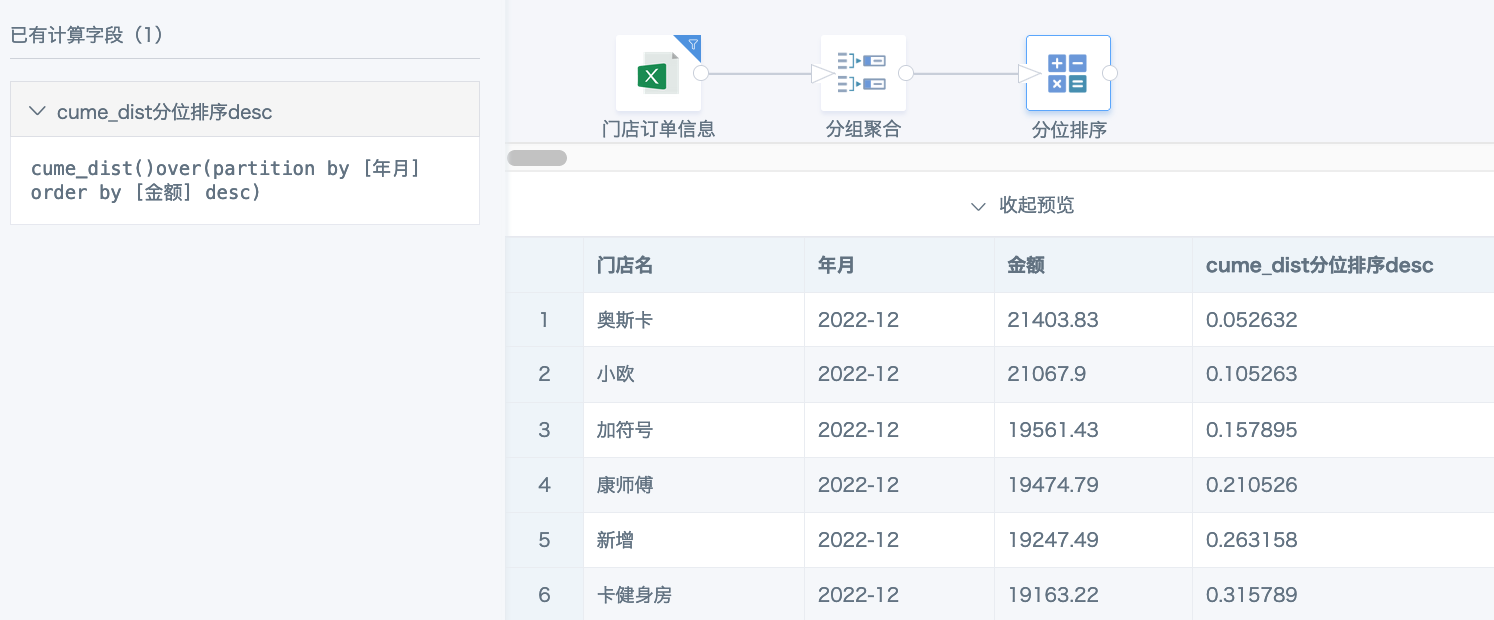
3.制作卡片,数值栏要使用“分位排序”字段时,聚合方式要选择无处理,根据需求筛选数值小于等于 0.15 即可,参考下图。

说明
当某个分组里的 15% 不是整数时,比如以上图中的 2022 年 12 月的门店数是 19 个,19*15%=2.85,向下取整(即 19 个门店中想保留 2 个)则筛选条件设置为小于等于 0.15;如果需要向上取整(即 19 中保留 3 个),筛选前 15% 的条件改为小于 0.16 或者 0.159999,反之后 15% 也是如此。
其他实现函数
分位数 percentile
percentile([金额],0.85)over(partition by [年月])
--返回这个分组下的真正分位数
等频划分的分位点 percentile_approx
percentile_approx([金额],0.85)over(partition by [年月])
--返回最接近这个分组下真正分位数的字段值
ntile 函数
ntile(n) over(partition by [分组字段] order by [排序字段])
--
a. n是将当前有序数据集平均分为n个桶,为每行按排序分配一个适当的桶序号(即切片值,第几个切片,第几个分区等概念)。它可用于将数据划分为相等的小切片,为每一行分配该小切片的数字序号。
b. n可根据前N%判断:比如想看前25%,切片数记为4;想看前10%,切片数记为10。
c. 如果切⽚不均匀,默认增加第⼀个切⽚的分布:当无法均分时,按顺序从第一个桶开始依次增加切片分布。比如一共10行数据,①分3个组,那么第一个组4行,其他两个组里都是3行;②分4个组,那么第一、二个组里3行,其他组里都是2行。

以上几个函数使用效果对比如上图。在本案例中,计算 Top 15% 时,percentile、ntile 只能向上取整(19 中取 3 个),cume_dist 和 percentile_approx 向上、下取整都可以实现。如果要改为计算 Top 10% 或者其他百分比,只有 cume_dist 可以不修改 ETL 公式,只修改卡片里筛选条件,其他 3 个函数都需要修改 ETL。请根据实际场景选择合适的函数。